Le format de stockage propre à Snowflake permet de conserver les données de manière particulièrement efficace et économique. Pour la plupart des clients Snowflake, les coûts de stockage représentent généralement moins de 20 % de la dépense totale. Pour autant, il existe souvent d'importantes opportunités d'optimisation à saisir pour réduire les usages superflus.
Dans cet article, nous explorons en détail la structure des coûts et la tarification du stockage Snowflake, les techniques d'optimisation et la manière de suivre ces coûts. Nous n'abordons pas l'offre external tables de Snowflake, qui permet de stocker et d'interroger des données en dehors de la plateforme.
Rappel sur l'architecture Snowflake
Comme nous l'avons vu dans notre précédent article sur l'architecture de Snowflake, la plateforme gère et met à l'échelle les ressources de stockage et de calcul de façon indépendante.
Toutes les tables de la couche de stockage s'appuient sur le format de fichier propriétaire des micro-partitions Snowflake. Les micro-partitions sont de petits fichiers de données immuables (moins de 16 Mo compressés) dont les métadonnées sont stockées dans l'en-tête. Ces fichiers étant immuables, la mise à jour d'une seule ligne d'une micro-partition impose la création d'une nouvelle micro-partition complète. Réalisée fréquemment et à grande échelle, cette opération peut avoir des conséquences importantes sur les coûts, comme nous le verrons plus loin.
Même si le calcul et le stockage concentrent l'essentiel de l'attention, la couche Cloud Services joue elle aussi un rôle clé dans la gestion des métadonnées associées à chaque table : elle rend possibles des fonctionnalités de stockage notables comme Time Travel, Fail-Safe et Zero Copy Cloning.
Les concepts de stockage Snowflake
Comme le souligne notre récent article sur les commandes merge dans Snowflake, le découplage entre le stockage et les services cloud a ouvert la voie au concept de version de table. Chaque table est ainsi définie par un horodatage de création associé, un ensemble de micro-partitions liées et des statistiques pré-calculées pour chacune d'elles. Une table peut donc être vue comme un ensemble de pointeurs de métadonnées qui la décrivent.
L'image ci-dessous illustre ce concept. Elle représente les liens entre les tables et les données physiques (micro-partitions). La table A et la table B (un clone de A) partagent exactement les mêmes partitions. La table C, également un clone, partage les mêmes micro-partitions, auxquelles s'ajoute une nouvelle micro-partition créée par une modification de données (par exemple, l'insertion de nouveaux enregistrements).
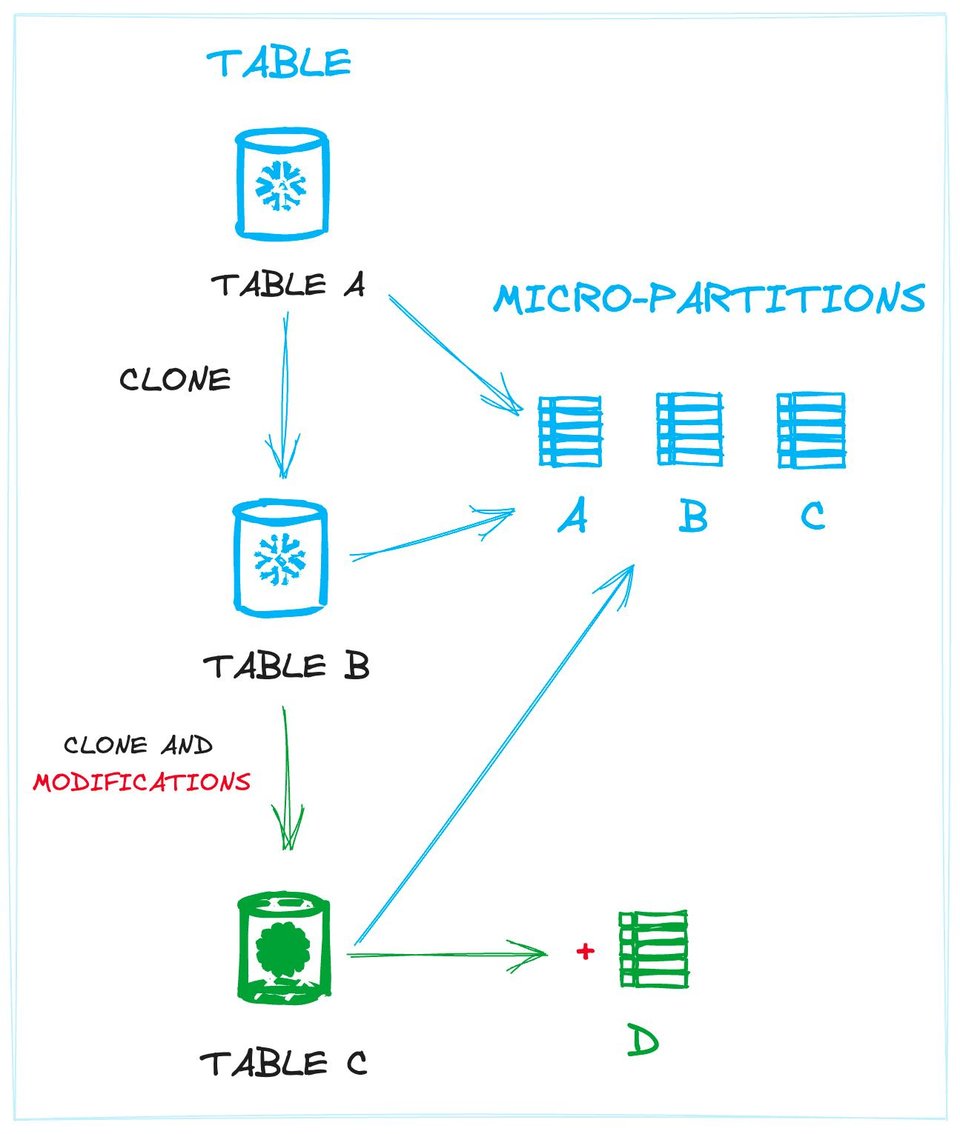
Définir les tables comme une collection de micro-partitions permet à Snowflake d'éviter des opérations inutiles sur disque, puisque les nouvelles tables peuvent être liées à des micro-partitions préexistantes chaque fois que possible. Ce découplage permet de créer plusieurs tables uniques qui partagent un ensemble identique de fichiers physiques, ce qui est précisément le cas lors d'un zero-copy cloning.
La structure de stockage de Snowflake lui permet de proposer toute une palette de fonctionnalités de Continuous Data Protection (CDP), accessibles à tous les clients. La CDP regroupe Time-Travel, Fail-Safe et Zero-Copy Cloning, que nous allons détailler ci-dessous.
Time Travel
Time Travel, aussi appelé rétention des données, aide les utilisateurs à protéger leurs données. Sa fonction principale est de sauvegarder les données (plus précisément, les micro-partitions) pendant une période donnée. En effet secondaire, il permet de remonter dans le temps pour interroger, recréer ou restaurer des objets, à partir des données telles qu'elles étaient à un moment précis.
Time Travel est défini à 1 jour par défaut et est disponible pour tous les clients, quelle que soit l'édition Snowflake utilisée. Pour l'édition Snowflake Standard, Time Travel peut être réglé sur 0 (désactivé) ou maintenu à la valeur par défaut de 1 jour. Pour l'édition Snowflake Enterprise, la période de rétention peut être étendue jusqu'à 90 jours pour les objets permanents. Les tables transient et temporary sont limitées à 1 jour pour tous les clients.
Time Travel se configure via le paramètre DATA_RETENTION_TIME_IN_DAYS. Nous y revenons plus en détail dans la section consacrée à l'optimisation.
Interroger une table à un instant donné
AT OR BEFORE est une abstraction syntaxique qui permet de remonter dans le passé pour retrouver les données telles qu'elles étaient à une période donnée. De nombreuses options existent pour déterminer le point historique recherché : consultez la documentation officielle pour savoir comment utiliser correctement ces opérateurs. Voici un exemple de requête :
select
user_name,
feature_enabled_status
from users at(timestamp => 'Fri, 01 May 2023 17:20:00 -0700'::timestamp)
where
user_id = 5
;
Restaurer une table supprimée par erreur
Avec Time Travel, supprimer accidentellement une table, un schéma ou une base de données importante n'est plus le cauchemar du data engineer. La restauration est simple tant que l'objet se trouve encore dans la période de rétention. Vous trouverez plus de détails ici sur cette fonctionnalité ; voici toutefois un exemple rapide pour restaurer une table users hypothétique qui aurait été supprimée par erreur :
1undrop table db.analytics.users
Configurer Time Travel
Time Travel se configure à différents niveaux : compte, base de données, schéma ou table. La configuration suit une logique hiérarchique : si elle est définie au niveau de la table, elle prime sur les réglages effectués au niveau du schéma, de la base ou du compte.
DATA_RETENTION_TIME_IN_DAYS est le paramètre qui régit le comportement de Time Travel. Pour bien comprendre vos réglages, commencez par examiner les valeurs par défaut aux niveaux compte, base et schéma.
1show parameters like '%DATA_RETENTION_TIME_IN_DAYS%' in {account, database, schema, table}
Voyons maintenant comment gérer la configuration de la rétention dans notre projet :
-- global config, account level
alter account set data_retention_time_in_days = 0;
-- unless stated downstream (schema or table),
-- all tables in the dbs have 1-day window
create or replace database staging_db data_retention_time_in_days=1;
use database staging_db;
-- unless stated downstream (table),
-- time travel is disabled for the tables in the schema
create or replace schema staging_schema data_retention_time_in_days=0;
use schema staging_schema;
-- create a table with time-travel of 1 day
create table test_table_zero (
Développer le code
Comme indiqué plus haut, l'explicite l'emporte toujours sur l'implicite. Si vous devez piloter ce paramètre pour un objet précis, utilisez-le dans l'instruction create. Sinon, laissez la configuration globale s'appliquer.
Fail Safe
Le stockage Fail-Safe est la dernière ligne de défense. Il n'est accessible qu'à Snowflake et n'entre en jeu qu'une fois la période de rétention écoulée. C'est l'ultime étape avant que les données ne soient totalement supprimées et inaccessibles. Il n'est pas configurable et dure 7 jours, sauf pour les tables transient ou temporary, pour lesquelles Fail-Safe n'est tout simplement pas utilisé.
Fail-Safe est conçu comme un ultime recours. Selon la documentation Snowflake :
Fail-Safe n'est pas un moyen d'accéder aux données historiques une fois la période de rétention Time Travel terminée. Il est réservé à un usage interne par Snowflake pour récupérer des données qui auraient pu être perdues ou endommagées à la suite de défaillances opérationnelles majeures.
Zero Copy Cloning
Zero-Copy Cloning permet de copier des objets en quelques secondes, quelle que soit leur taille. Cloner une table dans Snowflake n'est pas une opération de création de fichier de base de données qui stocke de nouvelles données sur disque. C'est une simple opération de métadonnées exécutée dans Cloud Services : elle définit un nouvel objet pointant vers les micro-partitions existantes de la table clonée.
Juste après le clonage, aucun coût de stockage supplémentaire n'est facturé, car la table parente et la table clonée pointent exactement vers le même ensemble de micro-partitions. En revanche, si tous les enregistrements de la table parente sont mis à jour, les coûts de stockage doublent : la table clonée continue de pointer vers les anciennes micro-partitions (celles qui viennent d'être mises à jour) et impose leur conservation, ce qui génère des frais de stockage.
Le cycle de vie d'une table dans Snowflake
Maintenant que nous avons posé les concepts clés de stockage comme Time Travel et Fail Safe, voyons comment une table permanente traverse son cycle de vie par défaut, en mettant en évidence les différentes périodes de time-travel et de fail-safe.
L'image ci-dessous illustre ce processus. Prenons une table permanente de 10 To avec la valeur Time Travel par défaut (1 jour) et un Fail-Safe de 7 jours. Un intervalle de 10 jours est représenté, avec les volumes de stockage facturés chaque jour.
Au jour 1, une opération met à jour chaque enregistrement de la table, ce qui revient à recréer l'ensemble des micro-partitions. Les 10 To d'anciennes micro-partitions basculent en stockage Time Travel, où les utilisateurs peuvent encore accéder aux données pendant 24 heures.
Le lendemain, ces 10 To sortent de Time Travel et passent en stockage Fail-Safe pour les 7 jours suivants.
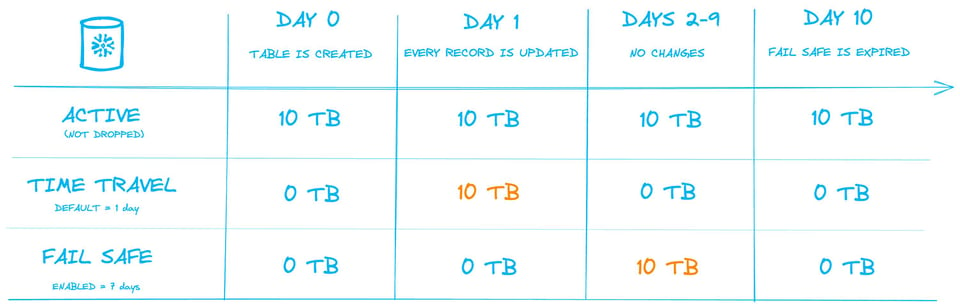
L'enseignement principal : alors même que le volume de données stockées dans la table ne change pas, la consommation moyenne quotidienne de stockage sur cette période de 10 jours grimpe à 18 To.
Exemple SQL
Si vous souhaitez vérifier ce comportement par vous-même, vous pouvez vous appuyer sur le SQL ci-dessous :
-- Create a permanent table
CREATE TABLE db.public.orders AS
SELECT *
FROM snowflake_sample_data.tpch_sf1.orders
;
CREATE OR REPLACE TEMPORARY TABLE db.public.stg AS (
SELECT
o_orderkey
, o_totalprice
FROM db.public.orders SAMPLE BLOCK (1) -- ensure all micro-partitions invloved
)
;
-- We run this code 15 times to update a sufficient number of micro-partitions
Développer le code
Jour 0 : toutes les versions de table modifiées passent en Time Travel, la taille de la table active reste identique

Jours 1-8 : Time Travel est terminé et les données passent en Fail-Safe
Synthèse et implications
Les micro-partitions sous-jacentes de chaque table Snowflake peuvent être qualifiées d'actives, en time-travel ou en fail-safe. Les opérations d'écriture sur la table déclenchent la création d'une nouvelle version de table en arrière-plan, ce qui fait passer les anciennes micro-partitions associées à la version précédente par les périodes time-travel puis fail-safe.
Comme illustré ci-dessus, modifier un grand nombre d'enregistrements ou mettre fréquemment à jour un petit nombre d'enregistrements dans une table permanente peut entraîner des coûts de stockage nettement plus élevés : les micro-partitions obsolètes doivent traverser les périodes time-travel et fail-safe avant d'être totalement supprimées.
Comment Snowflake facture-t-il le stockage ?
Snowflake facture proportionnellement au volume de données stockées. Les clients sont facturés mensuellement sur la base du volume moyen quotidien de données compressées (To) stocké dans leur compte. Les données stockées proviennent de quatre sources principales :
- Les fichiers placés dans les stages internes de Snowflake (compressés ou non)
- Les tables, toutes bases confondues, y compris leur période Time Travel
- Le stockage Fail-Safe pour les tables permanentes
- Les tables clonées qui référencent les fichiers d'une table modifiée depuis
Comme expliqué dans notre précédent article sur l'architecture Snowflake, Snowflake stocke vos données dans le service de stockage du fournisseur cloud sous-jacent (S3 pour AWS, Blob pour Azure, etc.). Snowflake pratique en réalité un pass-through pricing : il vous facture ce que le fournisseur cloud lui facture pour stocker les données. Les utilisateurs ne paient aucune prime par rapport à ce qu'ils paieraient normalement.
Grâce à son format de fichier propriétaire de micro-partition, Snowflake atteint des taux de compression d'au moins 3:1, ce qui rend le stockage nettement plus économique que si vous gériez vos données vous-même.
Combien coûte le stockage Snowflake au téraoctet ?
Le prix au téraoctet pour Snowflake varie selon que vous utilisez Snowflake on-demand ou que vous avez payé une capacité à l'avance. Par exemple, sur AWS dans la région US East (Northern Virginia), il vous en coûtera 40 $/To en on-demand et 23 $/To en capacité pré-achetée. Dans les faits, il existe de légères différences de prix entre les régions et les plateformes, liées à l'architecture multi-régions des fournisseurs cloud et au pass-through pricing : le Pacifique et l'Amérique du Sud sont en moyenne les plus chers. Vous pouvez consulter les plans tarifaires de stockage ici.
Comment estimer les dépenses mensuelles de stockage ?
Pour illustrer le calcul des dépenses de stockage, prenons un volume qui croît progressivement sur une période de 30 jours. Voici une estimation approximative des coûts :
1Day – Total Storage
2Day 1 – 1 Tb
3Day 2 – 2 Tb
4Day 3 – 10 Tb
5Day 5 – 20 Tb
6...
7Day 30 – 20 Tb
8
9Average Daily Storage Calculation = (1 + 2 + 10 * 2 + 20 * (30 - 5)) / 30 ~ 17.4 Tb per day
10
11Based on US East AWS prices:
121. On-Demand = 40$/Tb * 17.4Tb = 696$
132. Contract = 23$/Tb * 17.4Tb = 400$
En passant de l'on-demand à un contrat payé d'avance, vous pouvez immédiatement réduire vos coûts de stockage de 74 % dans cet exemple sur AWS en US East !
Modifications fréquentes et pièges des coûts de stockage
Des modifications fréquentes des données peuvent provoquer une variation soudaine des coûts de stockage, même si le volume de données actives reste identique. Dès qu'une table est mise à jour, l'ancienne version bascule en période de rétention et est remplacée par celle désormais active. Des mises à jour horaires, ou plus fréquentes encore, qui touchent une part importante des micro-partitions font grimper fortement les coûts de stockage. Prenons un cas extrême pour illustrer les sources potentielles de coûts inutiles.
Supposons que nous ayons 1 To de tables permanentes entièrement mises à jour 3 fois par jour. Les périodes Time Travel et Fail-Safe sont fixées à leurs valeurs par défaut : 1 jour et 7 jours respectivement.
Quel impact sur le volume quotidien de stockage et, par conséquent, sur le coût total ?
Input:
- Active storage, 1Tb
- Time-travel: 1 day
- Fail-Safe: 7 days
- Full data update 3 times per day
Formula:
Time-Travel = Modified * Times per day
Fail-Safe = Time-Travel * 7 days
Total Storage = Active + Time-Travel + Fail-safe
Calculations:
Time-Travel = (1Tb * 3 daily updates) = 3Tb
Fail-Safe = 3 Tb * 7 days = 21Tb
Total Storage = 1Tb + 3Tb + 21Tb = **25Tb (!)**
Même si nous ne détenons que 1 To de stockage actif, notre table consomme — et donc se voit facturer — 25 To de stockage ! Si vous utilisez un service comme l'Automatic Clustering, qui crée fréquemment de nouvelles micro-partitions à mesure qu'il réorganise vos données, ce multiplicateur peut grimper encore plus haut.
Dans la mesure du possible, évitez les mises à jour fréquentes qui touchent un grand nombre de micro-partitions dans des tables permanentes. Si vous ne pouvez pas, envisagez d'utiliser des tables transient ou de réduire votre période Time Travel (rétention) pour éviter des coûts inutiles. Si vos données sont déjà sauvegardées dans un stockage cloud ou un autre système, avez-vous vraiment besoin de payer pour des copies de sauvegarde supplémentaires dans Snowflake ?
Optimiser et réduire les coûts de stockage
Maintenant que nous avons posé les bases de la manière dont les données sont stockées dans Snowflake et de la façon dont vous êtes facturé, voyons quelques pistes pour optimiser vos coûts de stockage et éviter les mauvaises surprises liées à des pics soudains.
Réduire les périodes de rétention des données
Diminuer votre période de rétention (time travel) est un moyen simple de réduire les coûts de stockage.
Avant tout, nous recommandons fortement de désactiver Time-Travel (en le réglant à 0) pour toutes les tables transient et temporary. Ces tables sont régulièrement supprimées puis recréées : sauvegarder leurs données n'a généralement pas de sens. Si vos données sont sauvegardées ailleurs, envisagez aussi de convertir vos tables permanentes en tables transient pour éviter des dépenses inutiles en sauvegardes Fail-Safe et Time Travel.
Ensuite, conservez votre période Time Travel aussi courte que possible. Avez-vous vraiment besoin d'accéder à des données supprimées 90 jours plus tard ? Ou suffit-il de garder un accès pendant 7 jours ?
Limiter la fréquence des mises à jour
Nous avons illustré l'impact potentiel de mises à jour très fréquentes sur le comportement time-travel et fail-safe, certes de façon un peu caricaturale. Il n'en reste pas moins que des mises à jour répétées, combinées à la configuration de rétention par défaut, conduisent à stocker des volumes énormes de données. Conserver plusieurs copies des enregistrements d'origine fait exploser les besoins de stockage de plusieurs ordres de grandeur.
Supprimer les tables inutilisées
La stratégie la plus évidente — et probablement l'une des plus efficaces — consiste à se débarrasser des données inutiles. Nous avons tous connu ces situations où des données sont chargées dans le warehouse pour un usage futur… et n'en sortent jamais. Ian a expliqué en détail comment identifier les tables inutilisées dans Snowflake : je vous recommande vivement de lire cet article pour découvrir les meilleures approches.
Utiliser le clonage avec précaution
Dès qu'une table est clonée, aucun coût de stockage supplémentaire n'est généré. En revanche, si la table d'origine est supprimée ou mise à jour, la version clonée continuera de référencer les micro-partitions supprimées ou mises à jour, et
set clone_group_id = (
select distinct clone_group_id
from snowflake.account_usage.table_storage_metrics
where table_name = 'TEST_TABLE'
and table_catalog = 'STAGING'
)
;
select
id,
table_catalog || '.' || table_schema || '.' || table_name as fully_qualified_table_name,
id != clone_group_id as is_cloned
from snowflake.account_usage.table_storage_metrics
where clone_group_id = $clone_group_id
;
générera des coûts de stockage.
Lorsque vous supprimez une table, il est utile de vérifier l'existence de clones et de décider s'il faut également les supprimer. Pour cela, vous pouvez vous appuyer sur le champ clone_group_id de la vue table_storage_metrics. Ce champ reflète la relation entre tables originales et tables clonées. Par exemple, vous pouvez lister tous les clones d'une table avec le script suivant :
Comment suivre les coûts de stockage Snowflake ?
Les clients Snowflake disposent de plusieurs vues système qui couvrent divers aspects de l'utilisation du compte et des objets Snowflake. Ces vues se trouvent dans le schéma account_usage.
Suivre les coûts de stockage par table
La vue table_storage_metrics peut être interrogée pour connaître vos coûts de stockage par table. L'état actuel de chaque table, sa taille en octets, son statut de clonage, son schéma, son type et bien d'autres informations sont accessibles. Cette vue permet de décomposer et de suivre individuellement les octets actifs, en time-travel, en fail-safe ou retenus pour le clonage, comme illustré plus haut dans l'article.
Ian a déjà expliqué comment l'identification des tables inutilisées, combinée aux coûts de stockage issus de table_storage_metrics, joue un rôle majeur dans la détection des coûts de stockage superflus.
Voici un exemple de requête montrant comment exploiter table_storage_metrics :
use role accountadmin;
select
id as table_id, -- unique table identifier
id != clone_group_id as is_cloned -- if table is a clone
table_catalog || '.' || table_schema || '.' || table_name as fully_qualified_table_name, -- full name
active_bytes,
time_travel_bytes,
failsafe_bytes,
retained_for_clone_bytes,
(active_bytes + time_travel_bytes + failsafe_bytes + retained_for_clone_bytes) / power(1024, 4) as total_storage_tb, -- storage in tbs
Développer le code
Snapshoter table_storage_metrics
La vue table_storage_metrics ne contient que les enregistrements d'usage actuel des tables : si vous supprimez correctement une table, ses enregistrements disparaissent. Pour suivre l'évolution des métriques de stockage dans le temps, il faut prendre un snapshot de la table à un rythme horaire ou quotidien, puis construire votre propre logique d'analyse par-dessus.
Suivre les coûts de stockage agrégés dans le temps
Approche simplifiée qui permet de suivre l'ensemble des données, y compris celles utilisées par les stages internes. Revers de la médaille : la granularité se limite au niveau du compte, vous ne pouvez donc pas obtenir de rapports plus détaillés.
Les clients peuvent utiliser la vue storage_usage pour suivre les coûts de stockage quotidiens au niveau du compte. Plus de détails ici.
select
reader_account_name,
usage_date,
storage_bytes, -- all storage including time travel
stage_bytes, -- internal stages bytes
failsafe_bytes
from snowflake.account_usage.database_storage_usage_history
Pour une approche plus granulaire des coûts de stockage de votre compte, utilisez la vue database_storage_usage_history, qui présente les coûts de stockage au niveau de la base de données. À noter : la consommation des stages internes n'apparaît pas dans cette vue. Plus de détails dans la documentation Snowflake.
select
usage_date,
database_id,
database_name,
deleted, -- if database is active
average_database_bytes, -- all storage including time travel
average_failsafe_bytes
from snowflake.account_usage.database_storage_usage_history
Andrey Bystrov · Analytics Engineer chez Deliveroo
Andrey est un praticien de la donnée expérimenté, actuellement Analytics Engineer chez Deliveroo. Il est passionné par la modélisation des données et l'optimisation SQL. Il maîtrise en profondeur la plateforme Snowflake et met cette expertise au service de son équipe pour bâtir des data pipelines performants et économiques. Andrey est passionné par le sujet et partage régulièrement ses apprentissages avec la communauté.