Snowflake独自のストレージ形式のおかげで、データを高い効率と低コストで保存できます。多くのSnowflakeユーザーにとって、ストレージコストが総支出に占める割合は通常20%未満です。とはいえ、無駄な使用量を減らすための最適化の余地は数多く残されています。
本記事では、Snowflakeのストレージコストの構造と料金体系、最適化のポイント、そしてコストをモニタリングする方法を掘り下げて解説します。なお、Snowflakeの外部にデータを保存・クエリできる外部テーブル機能は本記事では取り上げません。
Snowflakeアーキテクチャのおさらい
以前のSnowflakeアーキテクチャの記事で紹介したとおり、Snowflakeはストレージとコンピュートをそれぞれ独立して管理・スケールします。
ストレージ層のすべてのテーブルは、Snowflake独自のマイクロパーティションファイル形式を採用しています。マイクロパーティションは、ヘッダーにメタデータを保持する小さなイミュータブル(変更不可)のデータファイル(圧縮後16MB未満)です。ファイルがイミュータブルであるため、マイクロパーティション内の1行を更新するだけでも、新しいマイクロパーティションを丸ごと作り直す必要があります。これが頻繁かつ大規模に行われると、後述するとおりコストへの影響は無視できません。
コンピュートとストレージばかりが注目されがちですが、Cloud Services層も各テーブルに紐づくメタデータを管理する重要な役割を担っており、Time Travel、Fail-Safe、Zero Copy Cloningといった特徴的なストレージ機能を支えています。
Snowflakeストレージの主要な概念
先日のSnowflakeのマージに関する記事でも触れたように、Snowflakeがストレージとクラウドサービスを分離したことで、テーブルバージョンという概念が生まれました。各テーブルは、作成時のタイムスタンプ、紐づくマイクロパーティションの集合、そして各マイクロパーティションについて事前計算された統計情報によって定義されます。つまりテーブルは、自身を定義するメタデータのポインタ群とみなすことができます。
下図はこの概念を示したものです。テーブルと物理データ(マイクロパーティション)の関係が表現されています。テーブルAとテーブルB(Aのクローン)はまったく同じパーティションを共有しています。同じくクローンであるテーブルCは、同じマイクロパーティションに加え、データ変更(新規レコードの挿入など)によって生まれた新しいマイクロパーティションも保持しています。
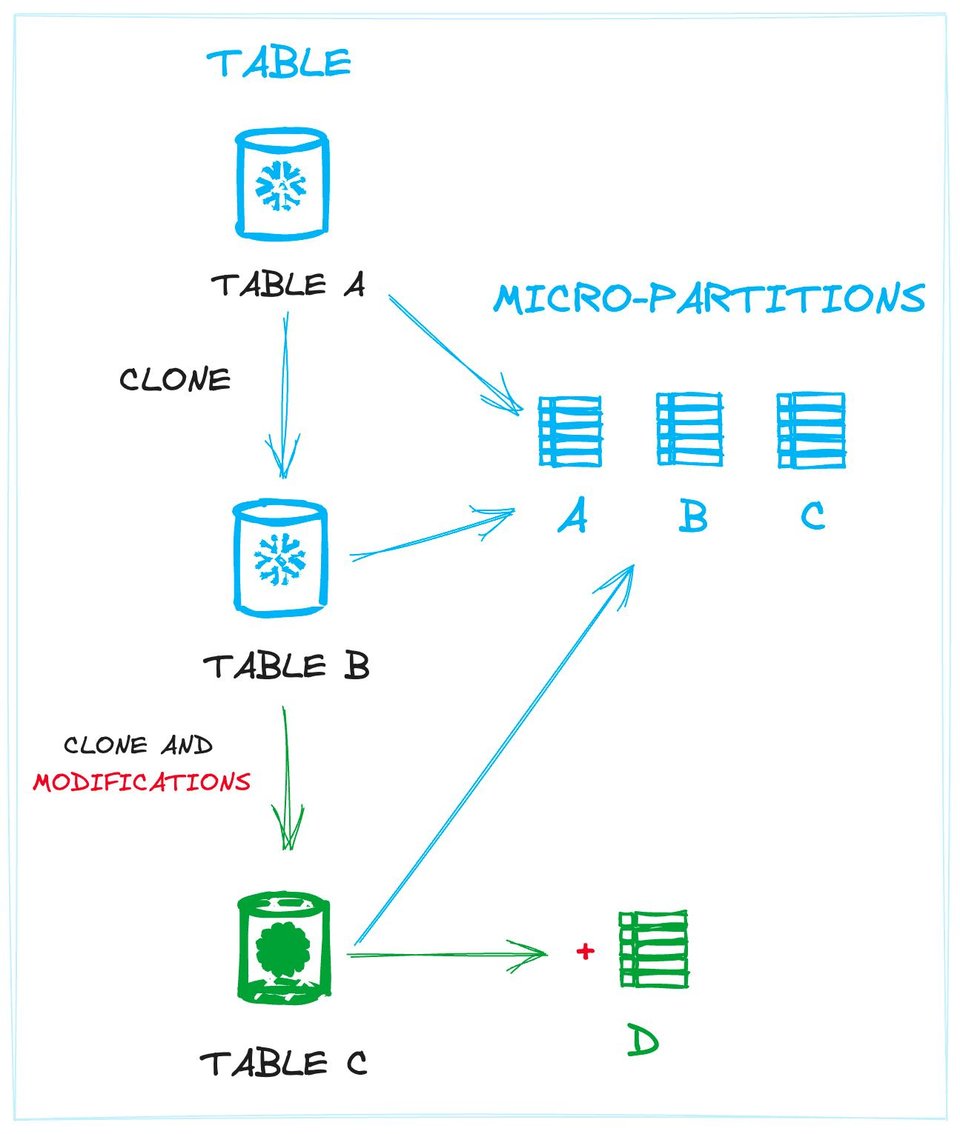
テーブルをマイクロパーティションの集合として定義することで、新規テーブルを可能な限り既存のマイクロパーティションにリンクでき、ディスク上の無駄な操作を回避できます。この分離により、同一の物理ファイル群を共有する複数のテーブルを作ることも可能になります。これがゼロコピークローンの裏側で起きていることです。
このストレージ構造のおかげで、Snowflakeはすべての顧客が利用できるContinuous Data Protection(CDP)機能を多彩に提供しています。CDPはTime Travel、Fail-Safe、Zero-Copy Cloningで構成されており、次にそれぞれを詳しく見ていきます。
Time Travel
Time Travel(「データ保持」とも呼ばれます)は、ユーザーがデータを保護するための機能です。主な役割は、一定期間データ(より厳密にはマイクロパーティション)をバックアップすることです。副次的な効果として、特定時点のデータを使って過去にさかのぼり、オブジェクトをクエリしたり、再作成したり、削除を取り消したりできます。
Time Travelはデフォルトで1日に設定されており、Snowflakeのエディションを問わずすべての顧客が利用できます。Snowflake Standardエディションでは0(無効)かデフォルトの1日のどちらかを選択でき、Snowflake Enterprise Editionでは永続オブジェクトの保持期間を最大90日まで延長できます。transientテーブルとtemporaryテーブルは、すべての顧客で最長1日に制限されます。
Time TravelはDATA_RETENTION_TIME_IN_DAYSパラメータで設定します。詳しくは後述の最適化セクションで取り上げます。
特定時点のテーブルをクエリする
AT OR BEFOREは、指定した時点のデータを復元しながら過去にさかのぼれる構文です。履歴時点を指定するためのオプションが豊富に用意されているため、正しい使い方は公式ドキュメントをご確認ください。以下はクエリの一例です。
select
user_name,
feature_enabled_status
from users at(timestamp => 'Fri, 01 May 2023 17:20:00 -0700'::timestamp)
where
user_id = 5
;
誤って削除したテーブルを復元する
Time Travelがあれば、重要なテーブル・スキーマ・データベースを誤って削除してしまうというデータエンジニアの悪夢に怯える必要はもうありません。保持期間内であれば簡単に復元できます。機能の詳細はこちらをご覧ください。誤って削除したusersテーブルを復元する簡単な例を以下に示します。
1undrop table db.analytics.users
Time Travelの設定方法
Time Travelはアカウント、データベース、スキーマ、テーブルといった複数のレベルで設定できます。階層的にネストされており、テーブルレベルで定義されている場合は、スキーマ、データベース、アカウントレベルの設定よりも優先されます。
Time Travelの動作を制御するパラメータがDATA_RETENTION_TIME_IN_DAYSです。現在のTime Travel設定を把握するには、まずアカウント・データベース・スキーマレベルのデフォルト値を確認しましょう。
1show parameters like '%DATA_RETENTION_TIME_IN_DAYS%' in {account, database, schema, table}
では実際に、プロジェクトで保持期間を設定してみましょう。
-- global config, account level
alter account set data_retention_time_in_days = 0;
-- unless stated downstream (schema or table),
-- all tables in the dbs have 1-day window
create or replace database staging_db data_retention_time_in_days=1;
use database staging_db;
-- unless stated downstream (table),
-- time travel is disabled for the tables in the schema
create or replace schema staging_schema data_retention_time_in_days=0;
use schema staging_schema;
-- create a table with time-travel of 1 day
create table test_table_zero (
Expand Code
前述のとおり、明示的な設定は常に暗黙的な設定に優先するため、特定のオブジェクトを個別に制御したいときはcreate文でパラメータを指定し、それ以外はグローバル設定に任せるのが基本です。
Fail Safe
Fail-Safeストレージは、いわば最後の砦です。Snowflakeのみがアクセスでき、Time Travelの保持期間が終わってから初めて有効になります。データが完全に削除されアクセスできなくなる、その直前のフェーズにあたるものです。設定は変更できず、期間は7日間に固定されています。ただしtransientテーブルやtemporaryテーブルでは、Fail Safeはまったく機能しません。
Fail-Safeはあくまで最終手段として位置づけられています。Snowflakeの公式ドキュメントには次のように記されています。
Fail-safeは、Time Travelの保持期間が終わった後に履歴データへアクセスするための手段ではありません。極端な運用障害によって失われたり破損したりした可能性のあるデータを、Snowflakeが復旧するためにのみ使用するものです。
Zero Copy Cloning
Zero-Copy Cloningを使えば、サイズに関係なく数秒でオブジェクトのコピーを作成できます。Snowflakeでのテーブルのクローンは、ディスク上に新たなデータを書き出すデータベースファイルの作成処理ではありません。実際にはCloud Services上で行われるメタデータ操作にすぎず、クローン元テーブルの既存マイクロパーティションを指すポインタを持った新しいオブジェクトが定義されるだけです。
テーブルをクローンした直後は、親テーブルとクローン側がまったく同じマイクロパーティション群を参照しているため、追加のストレージコストは発生しません。しかし、親テーブルのレコードがすべて更新された場合、クローン側は更新前の古いマイクロパーティションファイルを参照し続け、それらを残しておく必要があるため、ストレージコストは実質的に2倍になります。
Snowflakeにおけるテーブルのライフサイクル
Time TravelとFail Safeという重要な概念を紹介したところで、permanentテーブルがデフォルト設定でどのようなライフサイクルをたどるのか、Time TravelとFail Safeの期間にフォーカスして見ていきましょう。
下図にこの流れを示しました。デフォルトの1日のTime Travelと7日のFail Safeが有効な、10 TBのデータを持つpermanentテーブルを想定します。10日間の期間と、1日ごとに課金されるストレージ量を表しています。
1日目に、テーブル内のすべてのレコードを更新する操作を実行すると、結果的にすべてのマイクロパーティションが作り直されます。古い10 TB分のマイクロパーティションは「Time Travel」ストレージに移り、そこから24時間はユーザーがアクセスできます。
翌日には、その10 TBはTime Travelから抜け、次の7日間はFail Safeストレージに置かれます。
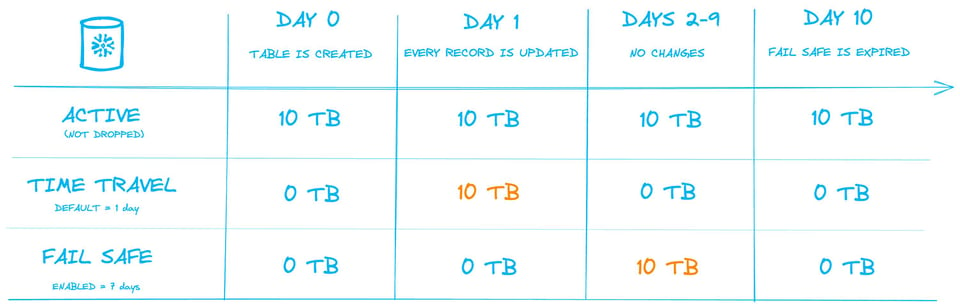
ここでのポイントは、テーブルに格納されているデータ量自体は変わっていないにもかかわらず、10日間の1日平均ストレージ消費量が18 TBにまで膨らんでいるという点です。
SQLの例
この挙動を自分で検証したい場合は、以下のSQLを参考にしてください。
-- Create a permanent table
CREATE TABLE db.public.orders AS
SELECT *
FROM snowflake_sample_data.tpch_sf1.orders
;
CREATE OR REPLACE TEMPORARY TABLE db.public.stg AS (
SELECT
o_orderkey
, o_totalprice
FROM db.public.orders SAMPLE BLOCK (1) -- ensure all micro-partitions invloved
)
;
-- We run this code 15 times to update a sufficient number of micro-partitions
Expand Code
0日目: 変更された各テーブルバージョンはすべてTime Travelに移動し、アクティブなテーブルサイズは変わらない

1〜8日目: Time Travelが終了し、データはFail Safeへ移動
まとめと示唆
各Snowflakeテーブルを構成するマイクロパーティションは、「アクティブ」「Time Travel中」「Fail Safe中」のいずれかの状態にあると考えられます。テーブルへの書き込みが発生すると、内部で「新しいテーブルバージョン」が作成され、前のバージョンに紐づく古いマイクロパーティションはTime TravelとFail Safeの期間を順に進んでいきます。
上で見たとおり、permanentテーブルで大量のレコードを変更したり、少数のレコードを高頻度で更新したりすると、古いマイクロパーティションが完全に削除されるまでにTime TravelとFail Safeのストレージを順に通過するため、ストレージコストが大きく跳ね上がる可能性があります。
Snowflakeのストレージ課金のしくみ
Snowflakeでは、保存しているデータ量に比例して料金が発生します。具体的には、アカウント内に保存された圧縮後の1日平均データ量(TB)に対して、月次で課金されます。保存対象となるデータは主に次の4種類です。
- Snowflake内部ステージ上のファイル(圧縮済み/非圧縮)
- 各データベースのテーブル(対応するTime Travel期間も含む)
- permanentテーブルのFail-Safeストレージ
- すでに変更されたテーブルのファイルを参照しているクローンテーブル
前回のSnowflakeアーキテクチャ記事でも述べたように、Snowflakeはユーザーのデータを基盤となるクラウドプロバイダのストレージサービス(AWSならS3、AzureならBlobなど)に保存しています。料金面では基本的にパススルー方式を採用しており、基盤クラウドプロバイダがSnowflakeに請求するコストをそのままユーザーに請求します。通常のクラウド料金を上回るプレミアムが上乗せされることはありません。
Snowflake独自のマイクロパーティションファイル形式により、少なくとも3:1の圧縮率を実現できるため、自前でデータを保存するよりもストレージコストを大幅に抑えられます。
Snowflakeのストレージ料金はテラバイトあたりいくら?
Snowflakeのテラバイトあたりの料金は、オンデマンド利用か、キャパシティを事前購入しているかによって変わります。たとえばAWSの米国東部(バージニア北部)では、オンデマンドで$40/TB、事前購入キャパシティで$23/TBです。実際には、クラウドプロバイダのマルチリージョン構成を反映したパススルー価格のため、リージョンやプラットフォームによって若干の差があり、平均すると太平洋地域と南米地域がもっとも高めです。料金プランの一覧はこちらからご確認いただけます。
月間のストレージ費用を見積もるには?
ストレージ費用の計算方法を示すため、30日間でストレージ量が徐々に増えていくケースを考えてみましょう。コストの概算は次のとおりです。
1Day – Total Storage
2Day 1 – 1 Tb
3Day 2 – 2 Tb
4Day 3 – 10 Tb
5Day 5 – 20 Tb
6...
7Day 30 – 20 Tb
8
9Average Daily Storage Calculation = (1 + 2 + 10 * 2 + 20 * (30 - 5)) / 30 ~ 17.4 Tb per day
10
11Based on US East AWS prices:
121. On-Demand = 40$/Tb * 17.4Tb = 696$
132. Contract = 23$/Tb * 17.4Tb = 400$
この例では、オンデマンドから有償契約に切り替えるだけで、AWS米国東部におけるストレージコストを74%もカットできます。
頻繁な更新が招くストレージコストの落とし穴
アクティブなデータ量が変わっていないのに、頻繁なデータ変更によってストレージコストが急に跳ね上がることがあります。テーブルが更新されると、古いバージョンは保持期間に移され、新しくアクティブになったバージョンに置き換わります。マイクロパーティションの大半に影響を与えるような更新を1時間ごと、あるいはそれ以上の頻度で行うと、ストレージコストは大きく膨らみます。ここでは極端な例を使って、無駄なコストがどこで発生し得るかを確認してみましょう。
合計1 TBのpermanentテーブルが、1日に3回フルアップデートされると仮定します。Time TravelとFail Safeはデフォルトのままで、それぞれ1日と7日に設定されています。
これは1日あたりのストレージ消費量、ひいては総コストにどのような影響を及ぼすでしょうか?
Input:
- Active storage, 1Tb
- Time-travel: 1 day
- Fail-Safe: 7 days
- Full data update 3 times per day
Formula:
Time-Travel = Modified * Times per day
Fail-Safe = Time-Travel * 7 days
Total Storage = Active + Time-Travel + Fail-safe
Calculations:
Time-Travel = (1Tb * 3 daily updates) = 3Tb
Fail-Safe = 3 Tb * 7 days = 21Tb
Total Storage = 1Tb + 3Tb + 21Tb = **25Tb (!)**
アクティブなストレージは1 TBしかないのに、このテーブルは25 TB分のストレージを消費し、そのぶん課金されてしまうのです。データを再シャッフルする際にマイクロパーティションを頻繁に作り直すAutomatic Clusteringのようなサービスを使っている場合は、この倍率がさらに大きくなることもあります。
permanentテーブルでマイクロパーティションの多くに影響を与えるような頻繁な更新は、できる限り避けましょう。どうしても避けられない場合は、transientテーブルを使ったり、Time Travel(保持)期間を短くしたりして、不要なコストの発生を抑えることを検討してください。データがすでにクラウドストレージや他のシステムにバックアップされているなら、Snowflake側にさらにバックアップを保持する費用を払う必要が本当にあるか、見直してみる価値はあります。
ストレージコストの最適化と削減
Snowflakeにおけるデータの保存方法と課金のしくみを押さえたところで、ストレージコストを最適化し、突発的なスパイクを防ぐための具体的なアプローチを見ていきましょう。
データ保持期間を最小限にする
データ保持(Time Travel)期間を短くするのは、ストレージコストを下げる手軽な手段です。
まず強くおすすめしたいのは、すべてのtransientテーブルとtemporaryテーブルでTime Travelを無効化(0に設定)することです。これらのテーブルは定期的に削除・再作成されるものであり、多くのユースケースではバックアップを取る必要がありません。データを別の場所にバックアップしている場合は、permanentテーブルをtransientテーブルに変更し、Fail SafeとTime Travelのバックアップに不要な費用をかけずに済むかを検討してみてください。
次に、Time Travelの保持期間はできる限り短く保ちましょう。削除済みのデータに90日後にアクセスできる必要が本当にあるでしょうか?7日間で十分なケースも多いはずです。
更新頻度を抑える
やや誇張した例ではありますが、高頻度の更新がTime TravelとFail Safeの挙動にどれほどの影響を与えるかを見てきました。いずれにしても、頻繁なテーブル更新とデフォルトの保持設定が組み合わさると、膨大な量のデータが保存されることになります。元データのコピーが何重にも蓄積され、ストレージ要件は桁違いに膨らんでしまうのです。
使われていないテーブルを削除する
もっとも当たり前ながら、おそらくもっとも効果的な手段のひとつが、不要なデータを処分することです。「将来使うかもしれない」と思ってウェアハウスにロードしたものの、結局そのまま放置されているデータは、誰しも心当たりがあるはずです。Snowflakeで未使用テーブルを特定する方法をIanが詳しく解説していますので、ぜひそちらも参考にしてみてください。
クローンは慎重に使う
テーブルをクローンした直後は、追加のストレージコストは発生しません。しかし、元のテーブルが削除されたり更新されたりすると、クローン側は削除/更新されたマイクロパーティションを参照し続け、
set clone_group_id = (
select distinct clone_group_id
from snowflake.account_usage.table_storage_metrics
where table_name = 'TEST_TABLE'
and table_catalog = 'STAGING'
)
;
select
id,
table_catalog || '.' || table_schema || '.' || table_name as fully_qualified_table_name,
id != clone_group_id as is_cloned
from snowflake.account_usage.table_storage_metrics
where clone_group_id = $clone_group_id
;
そのぶんのストレージコストが発生し続けます。
テーブルを削除する際は、クローンが存在するか、それらも一緒に削除すべきかを確認しておく価値があります。これを実現するには、table_storage_metricsビューのclone_group_idフィールドが役立ちます。このフィールドには元テーブルとクローンの関係が反映されており、たとえば次のスクリプトであるテーブルのすべてのクローンを一覧表示できます。
Snowflakeのストレージコストをモニタリングするには?
Snowflakeでは、アカウント利用状況やSnowflakeオブジェクトに関するさまざまな情報を把握できるシステムビューが多数用意されています。これらのビューはaccount_usageスキーマに格納されています。
テーブル単位のストレージコストをモニタリングする
table_storage_metricsビューをクエリすることで、テーブルごとのストレージコストを把握できます。各テーブルの現在の状態、バイトサイズ、クローン状況、スキーマ、テーブルタイプといった情報をエンドユーザーが取得可能です。本記事の冒頭で示したとおり、アクティブ、Time Travel中、Fail Safe中、クローン保持用といったバイト数を、このビューを使って個別に追跡・分解できます。
Ianは以前、未使用テーブルの特定とtable_storage_metricsのストレージコストを組み合わせることが、無駄なストレージコストの洗い出しに大きく役立つと解説しています。
table_storage_metricsの使用例を以下に示します。
use role accountadmin;
select
id as table_id, -- unique table identifier
id != clone_group_id as is_cloned -- if table is a clone
table_catalog || '.' || table_schema || '.' || table_name as fully_qualified_table_name, -- full name
active_bytes,
time_travel_bytes,
failsafe_bytes,
retained_for_clone_bytes,
(active_bytes + time_travel_bytes + failsafe_bytes + retained_for_clone_bytes) / power(1024, 4) as total_storage_tb, -- storage in tbs
Expand Code
table_storage_metricsのスナップショットを残す
table_storage_metricsビューは現在のテーブル利用状況のレコードで構成されているため、テーブルを完全に削除するとそのレコードも残りません。テーブルのストレージメトリクスを時系列で追いたい場合は、1時間または1日単位でスナップショットを取得し、その上に独自のロジックを構築する必要があります。
集計ベースのストレージコストを時系列でモニタリングする
シンプルな方法として、内部ステージで使用されるデータも含めてすべてを追跡できるアプローチがあります。一方で、データの粒度はアカウント単位に限られるため、細かいレポートは作れません。
storage_usageビューを使えば、アカウント単位の日次ストレージコストをモニタリングできます。詳しくはこちらをご覧ください。
select
reader_account_name,
usage_date,
storage_bytes, -- all storage including time travel
stage_bytes, -- internal stages bytes
failsafe_bytes
from snowflake.account_usage.database_storage_usage_history
アカウントのストレージコストをもう一段細かく把握したい場合は、データベース単位でストレージコストを示すdatabase_storage_usage_historyビューを使うのが有効です。なお、内部ステージの消費量はこのビューには含まれていない点に注意してください。詳しくはSnowflakeの公式ドキュメントをご参照ください。
select
usage_date,
database_id,
database_name,
deleted, -- if database is active
average_database_bytes, -- all storage including time travel
average_failsafe_bytes
from snowflake.account_usage.database_storage_usage_history
Andrey Bystrov・Analytics Engineer at Deliveroo
AndreyはDeliverooでAnalytics Engineerを務める、経験豊富なデータ実務者です。データモデリングとSQL最適化に強いこだわりを持ち、Snowflakeプラットフォームへの深い理解を活かして、チームが高パフォーマンスかつコスト効率の高いデータパイプラインを構築できるよう支援しています。この分野への情熱は人一倍で、得られた知見をコミュニティへ積極的に還元しています。