dbt ist für viele Datenteams zum festen Bestandteil geworden: modulare, konsistente Workflows zur Datenaufbereitung bilden die Grundlage für BI- und ML-Produkte. Sobald dbt-Projekte auf Hunderte oder gar Tausende Modelle anwachsen, werden effiziente Builds entscheidend, um Kosten niedrig und Performance hoch zu halten. Es gibt zahlreiche Hebel, um dbt-Projekte schlank zu halten – von Optimierungen auf Modellebene bis zu Architekturentscheidungen, die effiziente Builds fördern. Dies ist der erste Teil einer dreiteiligen Serie, die sich vertieft mit Letzterem beschäftigt: konkret mit Strategien für "schlanke" dbt-Builds. In diesem Beitrag stellen wir zunächst die übergeordneten Konzepte vor und gehen anschließend anhand praxisnaher Beispiele auf die effiziente lokale dbt-Entwicklung ein.
Was sind dbt Slim Builds?
Bei "schlanken" dbt-Builds geht es darum, redundante, unnötige oder fehlerhafte Modellaufrufe innerhalb der Grenzen Ihrer Ausführungsumgebung so konsequent wie möglich zu reduzieren. Den Begriff "Slim CI" hat dbt selbst 2021 geprägt, als der Node-Selector state:modified eingeführt wurde. Dieser Selector ist eine wirkungsvolle Methode, um unnötige Node-Aufrufe zu eliminieren – heute gibt es jedoch zahlreiche weitere Optionen, mit denen Sie Ihr dbt-Projekt schlank und performant halten.
Die folgende Abbildung veranschaulicht das Kernkonzept hinter Slim Builds: Anhand selbst gewählter Auswahlkriterien wird bei einem dbt-Aufruf nur eine Teilmenge aller Modelle neu gebaut. Das können Modelle sein, deren Code geändert wurde, deren Quellen aktualisiert wurden oder die andere Kriterien erfüllen.
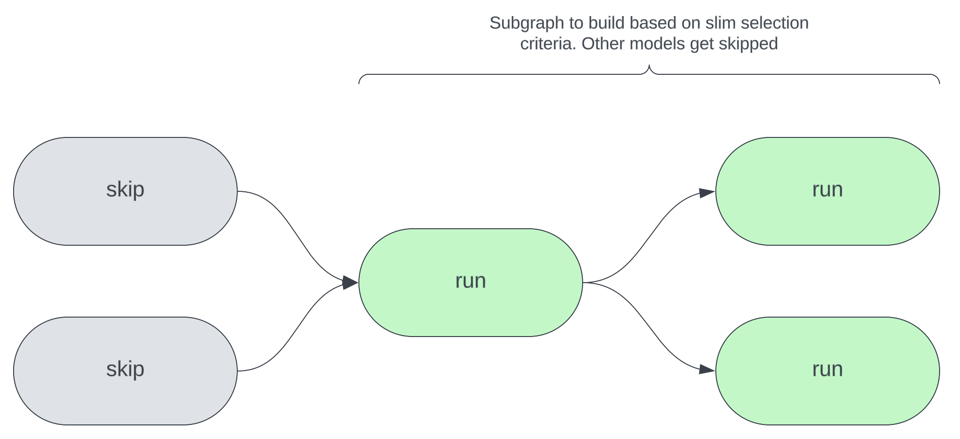
Warum die Orchestrierung im Fokus stehen sollte
In Diskussionen rund um Performance und Kostenprofil von dbt-Projekten beobachte ich häufig einen Fokus auf "Low-Level"-Optimierungen. Typische Beispiele sind Query-Profile einzelner Modelle, Clustering Keys, Warehouse Right-Sizing oder die Inkrementalisierung von Modellen. All das sind wichtige Aspekte für ein performantes und kosteneffizientes dbt-Projekt.
Ein Punkt wird aus meiner Sicht jedoch häufig übersehen: die Orchestrierung rund um die Ausführung von dbt-Modellen. Konkret die Frage, unter welchen Bedingungen und wie oft Modelle gebaut bzw. neu gebaut werden. Im Idealfall werden Modelle so selten wie möglich neu gebaut, und redundante oder unnötige Modellaufrufe werden entweder ganz eliminiert oder so angepasst, dass Laufzeit und Compute-Kosten minimal bleiben.
Wenn Ihre dbt-Compute-Kosten aus dem Ruder laufen, liegt das nicht zwangsläufig daran, dass Ihre Modelle nicht performant sind. Vielleicht bauen Sie sie schlicht zu oft neu!
Bevor wir konkrete Strategien für Slim Builds angehen, werfen wir einen Blick auf einige Annahmen und mögliche Architekturen, die für die Konzepte dieser Serie relevant sind.
Annahmen
Für die Konsistenz in dieser Serie gehen wir von Folgendem aus:
- Einsatz von
dbt corestattdbt cloud - Warehouses sind passend dimensioniert, d. h. keine unterdimensionierten Warehouses für große Modelle, die Laufzeiten in die Länge ziehen
- Klassische Batch-Pipelines mit täglichen, wöchentlichen oder monatlichen Aktualisierungen. Seltenere Muster wie Microbatches, Streams oder Dynamic Tables lassen wir außen vor
- Isolation auf Datenbankebene zwischen unterschiedlichen dbt-Aufrufkontexten
dbt-Aufrufkontexte
Die meisten Organisationen betreiben dbt in drei verschiedenen "Aufrufkontexten":
- Lokale Entwicklung (z. B. dbt-Ausführung vom Laptop aus)
- CI/CD-Pipelines (z. B. GitHub-Actions-Jobs, die Codeänderungen vor dem Push in die Produktion testen)
- Geplante Builds, üblicherweise orchestriert mit Tools wie Airflow, Dagster oder Prefect
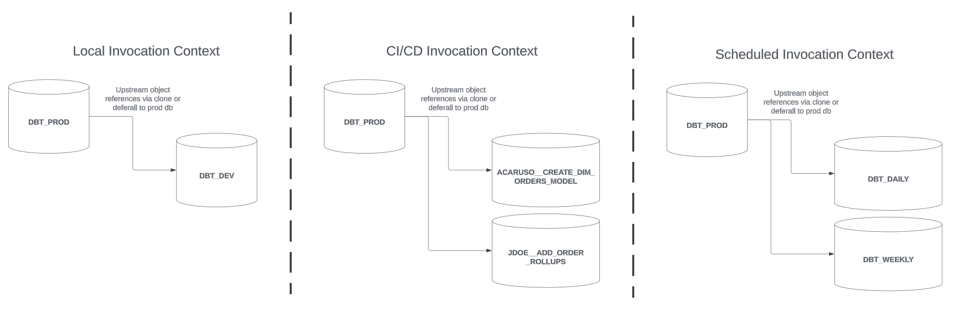
Jeder dieser Aufrufkontexte verfügt in der Regel über eine oder mehrere dedizierte Datenbanken oder Schemas, in denen Modelle isoliert gebaut werden. Die in dieser Serie beschriebenen Slim-Build-Strategien zahlen in jedem dieser Kontexte ein. Der Einfachheit halber gehen wir von folgender Architektur aus:
- Lokale dbt-Aufrufe werden in einer dedizierten
DBT_DEV-Datenbank gebaut – mit einem Schema pro Entwicklerin bzw. Entwickler - CI/CD-Aufrufe werden in einer dedizierten Datenbank
<GIT BRANCH NAME>gebaut, benannt nach dem Git-Branch des Changesets bzw. PRs, z. B.ACARUSO__CREATE_DIM_ORDERS_MODEL - Geplante Aufrufe laufen in einer dedizierten Datenbank, benannt nach dem Zeitplan, z. B.
DBT_DAILY
Vorgelagerte Abhängigkeiten der in diesen Kontexten gebauten Modelle lassen sich entweder als Clones referenzieren oder per Deferral einbinden. Für CI/CD- und geplante Produktions-Builds nehmen wir an, dass Modelle nach einem erfolgreichen dbt-Aufruf im Blue-Green-Verfahren in eine Produktionsdatenbank überführt werden.
Beispielaufbau: dbt-Artefakte persistieren
Bevor wir uns konkrete Slim-Auswahlkriterien und Build-Techniken ansehen, gehen wir kurz einen einfachen Ansatz durch, um dbt-Artefakte zu persistieren – für einige Slim-Auswahltechniken brauchen wir das. Konkret geht es um die Dateien manifest.json und sources.json. Diese werden bei verschiedenen dbt-Befehlen wie dbt run, dbt build oder dbt source freshness automatisch unter target/<artifact>.json erzeugt.
In einem CI/CD-Aufrufkontext laufen Jobs in der Regel nicht auf Maschinen mit persistentem Speicher über Builds hinweg. Ich speichere Artefakte deshalb gerne in externem Object Storage wie AWS S3.
(nach einem erfolgreichen Produktions-Aufruf von dbt run oder dbt build):
cd target
aws s3 cp manifest.json s3://dbt-artifacts/manifest.json
(nach einem erfolgreichen Produktions-Aufruf von dbt source freshness):
cd target
aws s3 cp sources.json s3://dbt-artifacts/sources.json
Anschließend können Sie diese Dateien vor jedem dbt-Aufruf, der State-basierte Selectors nutzt, in ein Verzeichnis namens .state herunterladen.
1aws s3 sync s3://dbt-artifacts .state
Damit hat dbt alle Informationen zur Hand, um bei einer bestimmten Kombination von State-Selectors zu entscheiden, welche Nodes ausgeführt werden.
Slim Local Builds
Schauen wir uns nun die Optionen an, mit denen Sie dbt-Builds lokal effizient ausführen.
CLI-Flag --defer: bereits gebaute Produktionsobjekte wiederverwenden
Statt vorgelagerte Abhängigkeiten bei jedem lokalen dbt-Aufruf von Grund auf neu zu bauen, können Sie Referenzen mit dem CLI-Flag --defer auf eine andere Datenbank umleiten. Das erspart Ihnen das Warten auf lange laufende, teure Builds in der lokalen Entwicklung. Wenn die Upstreams der Modelle, an denen Sie arbeiten, bereits in einer Produktionsdatenbank vorliegen und keine Änderungen daran nötig sind, können Sie sie genauso gut im Entwicklungskontext weiternutzen.
Angenommen, unser DAG sieht so aus:
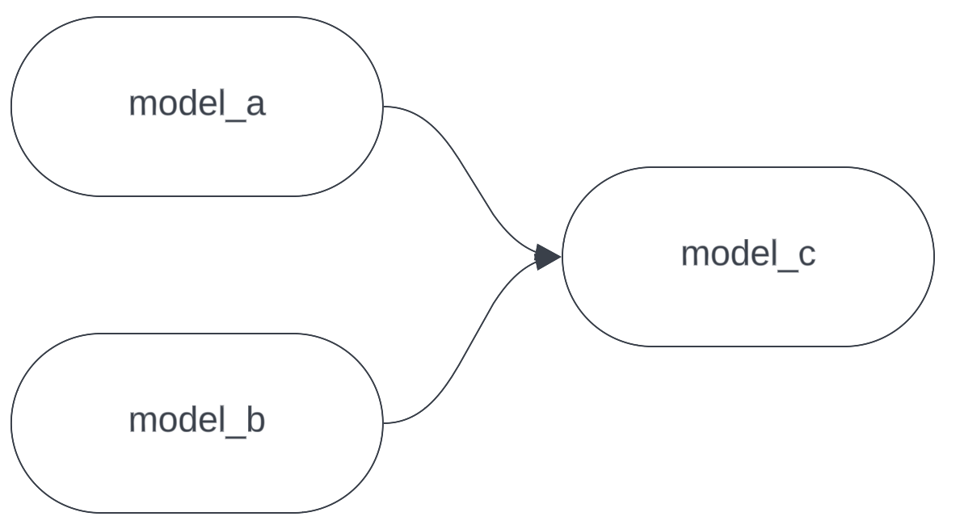
Nun stellen Sie sich vor, Sie nehmen Änderungen an model_c vor und führen dbt lokal aus, um sie zu testen. Für den Test brauchen Sie die aktuellen Daten aus model_a und model_b – beides sind jedoch riesige, teure Modelle, deren Build auf einem Entwicklungs-Warehouse Stunden dauern würde. Ein perfekter Fall für --defer. Statt:
1dbt run -s +model_c
verwenden Sie:
1dbt run -s model_c --defer --state .state
Damit werden die Referenzen auf diese Modelle auf die Datenbank umgeleitet, die in Ihrer .state/manifest.json hinterlegt ist – wie oben beschrieben also auf Ihre Produktionsdatenbank. Das kompilierte SQL für model_c könnte dann so aussehen:
create or replace transient table dbt_dev.acaruso.model_c as
with
a as (select * from dbt_prod.schema.model_a),
b as (select * from dbt_prod.schema.model_b),
final as (select * from a inner join b using (id))
select * from final;
Beachten Sie, dass die voll qualifizierten Referenzen auf model_a und model_b die Datenbank dbt_prod verwenden und nicht dbt_dev – schließlich haben wir diese Modelle in Dev nie neu gebaut. Hinweis: Arbeiten Sie mit --defer immer aus einem leeren Schema heraus, damit Referenzen tatsächlich umgeleitet werden. Existieren die Refs bereits in Ihrem Target-Schema, nutzt dbt diese, statt zu deferren.
Den gleichen Effekt erzielen Sie auch mit Object Clones, etwa über Snowflakes Zero Copy Clone. Clones müssen allerdings jedes Mal neu erstellt werden, wenn sich Objekte in der Quelldatenbank ändern, und nicht jedes Data Warehouse unterstützt Zero Copy Cloning. Für lokale Entwicklungsfälle ist --defer daher etwas einfacher und universeller einsetzbar.
Bonus: Wrapper-Skript für --defer
Damit Sie nicht jedes Mal Ihr Remote-Manifest-Artefakt abrufen und --defer --state /path/to/your/state eintippen müssen, habe ich ein kleines Wrapper-Skript geschrieben. Ich hoste meine dbt-Docs-Site aus demselben S3-Bucket, in dem ich nach Builds die Artefakte ablege – so lassen sich die aktuellen Prod-Artefakte vor dbt-Aufrufen mit --defer bequem abrufen.
dbtdefer.sh
#!/bin/bash -ue
prod_manifest_uri="http://dbt.yourdomain/manifest.json"
target_dir="path/to/your/dbt/project/target/prod_manifest"
mkdir -p $target_dir
target_file="${target_dir}/manifest.json"
# this writes the contents of "$prod_manifest_uri" to "$target_file", if
# "$prod_manifest_uri" has been modified more recently than "$target_file"
curl -o "$target_file" -z "$target_file" "$prod_manifest_uri"
set -x
dbt $@ --defer --state "$target_dir"
chmod +x dbtdefer.sh
echo 'alias dbtdefer="/path/to/your/dbt/project/bin/dbt_defer/dbtdefer.sh"' >> ~/.bashrc
source ~/.bashrc
Mit einem einzigen Befehl holen Sie nun das aktuelle Manifest ab und leiten Referenzen um: dbtdefer run -s <Ihre Selectors>. Das funktioniert auch mit dbtdefer build oder jedem anderen dbt-Befehl, bei dem Sie Referenzen deferren möchten.
CLI-Flag --empty: Schema-only Dry Runs
Ein weiteres Werkzeug für Slim Local Builds ist das CLI-Flag --empty. Setzen Sie es bei dbt run, wird in alle Sources und Refs Ihres Modells ein limit 0 injiziert.
Statt:
with my_expensive_transform as (
select ...
from {{ ref('source', 'my_big_table') }}
)
...
schickt dbt Folgendes an das Ziel:
with my_expensive_transform as (
select ...
from {{ ref('source', 'my_big_table') }}
limit 0
)
...
Ein scheinbar kleiner Unterschied, der bei komplexen Queries mit teuren Transformationen oder großen Basistabellen aber enormen Effekt haben kann. dbt führt das Modell-SQL weiterhin gegen das Ziel-Data-Warehouse aus, vermeidet dabei aber teure Reads und Transformationen der Eingabedaten. So validieren Sie Abhängigkeiten und stellen sicher, dass Ihre Modelle sauber bauen würden – ohne sie tatsächlich aufzubauen. Praktisch, um Schemaänderungen in der lokalen Entwicklung zu prüfen und die Modelle anschließend in einer Umgebung mit mehr Compute-Ressourcen vollständig zu bauen.
Row Sampling
Ein weiterer kreativer Weg, das Datenvolumen in Entwicklungskontexten (lokal oder CI/CD) zu begrenzen. Die Idee: Modelle mit hoher Zeilenzahl in Dev limitieren oder filtern, damit Transformationen über die kleineren Datenmengen schnell laufen. Zum Beispiel:
with my_big_ref as (
select * from {{ ref('my_big_table') }}
limit 500
-- OR
-- where updated_at >= DATEADD(week, -1, CURRENT_DATE)
-- etc
)
... more transforms go here ...
Solche Sampling-Techniken lassen sich in einem Override des ref-Makros bündeln, sodass Sampling je nach dbt-target automatisch greift.
{% macro ref(model_name) %}
{%- set original_ref = builtins.ref(model_name) -%}
{%- if target.name == 'dev' -%}
(
select *
from {{ original_ref }}
limit 1000
)
{%- else -%}
{{ original_ref }}
{%- endif -%}
{% endmacro %}
Dasselbe funktioniert auch für das source-Makro. Beachten Sie: Wenn Sie Builtins überschreiben und ihr Verhalten verändern, kann das zu Kompatibilitätsproblemen mit anderen Makros führen, etwa dbt_utils.star().
Offenbar arbeitet dbt an nativer Unterstützung dafür – möglicherweise über ein CLI-Flag --sample.
Persönlich fand ich diesen Ansatz aus Sicht der Developer Experience nie besonders angenehm. Damit Samples beim Testen verlässlich sind, müssen sie referenzielle Integrität und ungleichmäßig verteilte Daten berücksichtigen – und das ist bei einem komplexen DAG schwieriger, als es klingt. Trotzdem wollte ich es erwähnen, zumal dbt dafür bald native Unterstützung bieten könnte.
Fazit
Dieser Beitrag hat die Kernkonzepte hinter Slim dbt Builds vorgestellt und praxisnahe Beispiele gezeigt, wie sich Slim Builds im lokalen dbt-Kontext umsetzen lassen. Außerdem haben wir die Persistierung von dbt-Artefakten eingerichtet und mehrere dbt-"Aufrufkontexte" beleuchtet, in denen sich Slim-Build-Techniken anwenden lassen. Weiter geht es in Teil 2 dieser Serie: Best Practices für dbt-Workflows, Teil 2: Slim CI/CD Builds, in dem wir uns Slim-CI/CD-Strategien im Detail ansehen.
Alex Caruso·Lead Data Platform Engineer bei Entera
Alex ist Lead Data Platform Engineer bei Entera und lebt in New York, USA.