dbt est devenu une pierre angulaire pour de nombreuses équipes data, en permettant des workflows de transformation modulaires et cohérents qui alimentent les produits BI et ML. À mesure que les projets dbt atteignent des centaines, voire des milliers de modèles, l'efficacité des builds devient déterminante pour maîtriser les coûts et préserver les performances. Il existe de nombreuses façons d'optimiser les projets dbt et de les garder légers, des optimisations au niveau des modèles aux choix d'architecture qui favorisent des builds efficaces. Ceci est le premier article d'une série en 3 parties qui explorera en profondeur ce dernier aspect, et plus précisément les stratégies pour obtenir des builds dbt slim. Cet article présente quelques concepts de haut niveau, puis passe en revue plusieurs exemples concrets pour un développement dbt local efficace.
Qu'est-ce qu'un build dbt slim ?
Un build dbt slim, c'est minimiser autant que possible les invocations de modèles redondantes, inutiles ou erronées, dans les limites de votre environnement d'exécution. L'expression slim CI a été popularisée par dbt en 2021 avec l'introduction du sélecteur de nœuds state:modified. Ce sélecteur est une technique puissante pour éliminer les invocations de nœuds inutiles, mais aujourd'hui bien d'autres options existent pour garder votre projet dbt léger et performant.
L'image ci-dessous illustre le concept central des builds slim : selon les critères de sélection que vous choisissez, seul un sous-ensemble des modèles est reconstruit lors d'une invocation dbt donnée. Il peut s'agir de modèles dont le code a été modifié, dont les sources ont été mises à jour, ou qui répondent à d'autres critères.
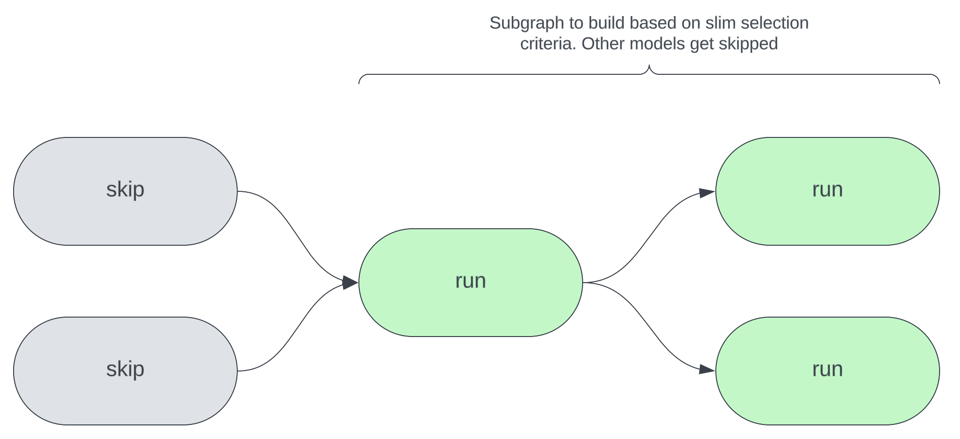
Pourquoi se concentrer sur l'orchestration plutôt que sur d'autres optimisations ?
Au fil des discussions sur les profils de performance et les coûts des projets dbt, j'ai souvent constaté que l'attention se portait sur des optimisations et considérations de bas niveau. Par exemple : les profils de requêtes des modèles individuels, les clés de clustering, le right-sizing des warehouses ou le passage des modèles en incrémentiel. Tous ces aspects comptent pour maintenir un projet dbt performant et économique.
Mais un aspect souvent négligé concerne l'orchestration autour de l'exécution des modèles dbt. Plus précisément, les conditions dans lesquelles et la fréquence à laquelle les modèles sont construits et reconstruits sont des considérations importantes. Idéalement, les modèles sont reconstruits le moins souvent possible, et les invocations redondantes ou inutiles sont soit complètement éliminées, soit retravaillées pour minimiser le temps d'exécution et le coût de calcul.
Si vos coûts de calcul dbt deviennent incontrôlables, ce n'est peut-être pas parce que vos modèles ne sont pas performants. Vous les reconstruisez peut-être tout simplement trop souvent !
Avant de plonger dans les stratégies pour obtenir des builds slim, passons en revue quelques hypothèses et architectures possibles qui peuvent avoir des implications sur les concepts de cette série.
Hypothèses
Par souci de cohérence tout au long de cette série, supposons ce qui suit :
- Utilisation de
dbt core, plutôt que dedbt cloud - Les warehouses sont correctement dimensionnés ; autrement dit, aucun warehouse sous-dimensionné n'est utilisé pour de gros modèles, ce qui allongerait les temps d'exécution
- Pipelines de traitement par lots standards, avec un rafraîchissement quotidien, hebdomadaire ou mensuel. Nous laissons de côté les schémas moins courants impliquant des microbatches, des flux ou des tables dynamiques
- Isolation au niveau base de données entre les différents contextes d'invocation dbt
Contextes d'invocation dbt
La plupart des organisations exécutent dbt dans trois contextes d'invocation différents :
- Développement local (par exemple, exécuter dbt depuis votre poste)
- Pipelines CI/CD (par exemple, des jobs GitHub Actions pour tester les changements de code avant de les pousser en production)
- Builds planifiés, généralement orchestrés par des outils comme Airflow, Dagster ou Prefect
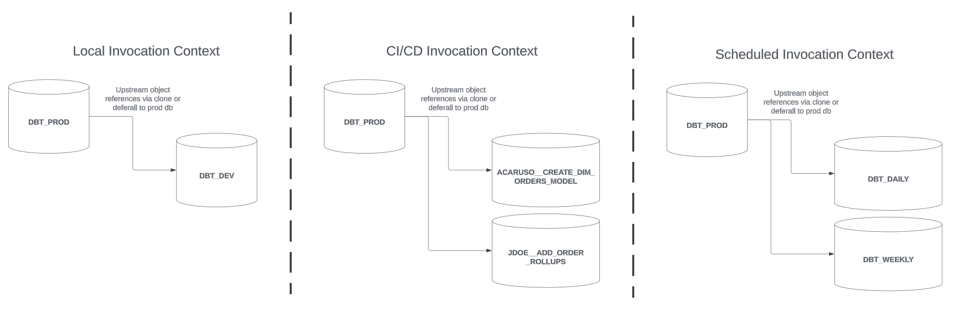
Chacun de ces contextes dispose habituellement d'une ou plusieurs bases de données ou schémas dédiés où les modèles peuvent être construits de manière isolée. Les stratégies de builds slim décrites dans cette série apportent des bénéfices dans chacun de ces contextes. Pour simplifier, supposons l'architecture suivante :
- Les invocations dbt locales sont construites dans une base de données dédiée
DBT_DEV, avec un schéma par développeur - Les invocations dbt CI/CD sont construites dans une base de données dédiée
<GIT BRANCH NAME>, nommée d'après la branche git de votre changeset / PR. Par exemple,ACARUSO__CREATE_DIM_ORDERS_MODEL - Les invocations dbt planifiées sont construites dans une base de données dédiée, nommée d'après la planification. Par exemple,
DBT_DAILY
Les dépendances en amont des modèles construits dans chacun de ces contextes peuvent être référencées soit sous forme de clones, soit via des deferrals. Pour les builds CI/CD et les builds de production planifiés, on suppose que les modèles sont promus vers une base de données de production après une invocation dbt réussie, dans un style blue-green.
Exemple de configuration : persister les artifacts dbt
Avant de passer aux exemples de critères de sélection slim et aux techniques de build, voyons une approche simple pour persister les artifacts dbt, qui seront nécessaires à certaines techniques de sélection slim. En particulier, il faudra persister les fichiers manifest.json et sources.json. Ces fichiers sont générés automatiquement dans target/<artifact>.json lors de l'exécution de diverses commandes dbt telles que dbt run, dbt build ou dbt source freshness.
Dans un contexte d'invocation CI/CD, vous n'exécuterez généralement pas vos jobs sur une machine dotée d'un stockage persistant entre les builds. J'aime donc stocker les artifacts dans un stockage objet externe distant comme AWS S3.
(après une invocation de production réussie de dbt run ou dbt build) :
cd target
aws s3 cp manifest.json s3://dbt-artifacts/manifest.json
(après une invocation de production réussie de dbt source freshness) :
cd target
aws s3 cp sources.json s3://dbt-artifacts/sources.json
Vous pouvez maintenant télécharger ces fichiers dans un répertoire nommé .state avant toute invocation dbt qui s'appuie sur des sélecteurs d'état.
1aws s3 sync s3://dbt-artifacts .state
Avec ces fichiers en place, dbt dispose des informations nécessaires pour déterminer quels nœuds exécuter lors d'une invocation avec un ensemble donné de sélecteurs d'état.
Builds locaux slim
Voyons maintenant les différentes options à votre disposition pour exécuter des builds dbt efficaces en local.
L'option CLI --defer pour réutiliser les objets de production déjà construits
Plutôt que de reconstruire les dépendances en amont depuis zéro à chaque invocation locale de dbt, vous pouvez déférer les références à une autre base de données via l'option CLI --defer. Cela vous évite d'attendre la fin de builds longs et coûteux dans un contexte de développement local. Si les dépendances en amont des modèles sur lesquels vous travaillez sont déjà construites dans une base de données de production et que vous n'avez pas besoin d'y apporter de modifications, autant les réutiliser dans un contexte de développement.
Supposons que notre DAG ressemble à ceci :
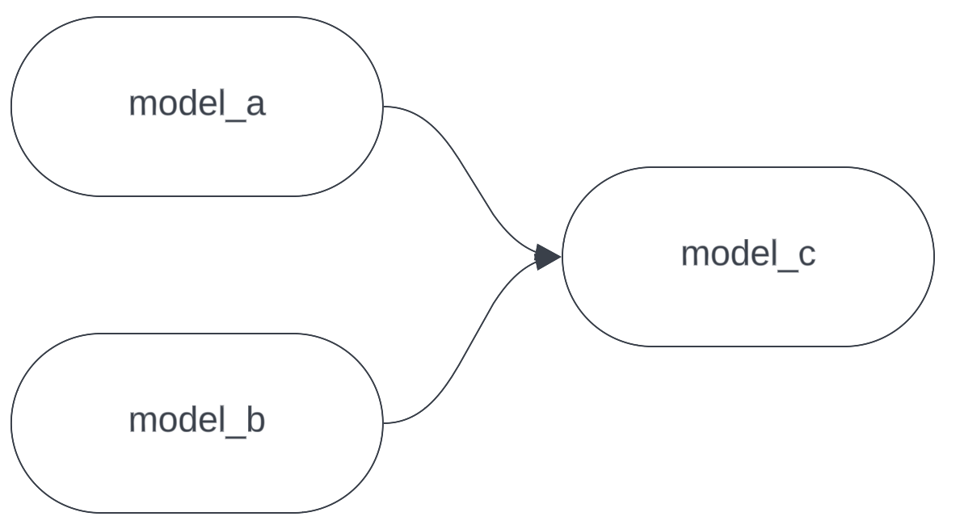
Imaginez maintenant que vous modifiez model_c et que vous exécutez dbt localement pour tester. Vous avez besoin des dernières données de model_a et model_b pour valider vos changements, mais ce sont d'énormes modèles coûteux dont la construction prendrait des heures sur un warehouse de développement. C'est un cas parfait pour --defer. Au lieu d'exécuter :
1dbt run -s +model_c
essayez :
1dbt run -s model_c --defer --state .state
Cela déférera les références à ces modèles vers la base de données définie dans votre fichier .state/manifest.json, qui devrait être votre base de données de production, comme configuré ci-dessus. Votre SQL compilé pour model_c pourrait alors ressembler à :
create or replace transient table dbt_dev.acaruso.model_c as
with
a as (select * from dbt_prod.schema.model_a),
b as (select * from dbt_prod.schema.model_b),
final as (select * from a inner join b using (id))
select * from final;
Remarquez que les références qualifiées à model_a et model_b pointent vers la base de données dbt_prod, et non dbt_dev, puisque nous ne les avons jamais reconstruites en dev. À noter : il faut toujours travailler depuis un schéma vide avec --defer, pour s'assurer que les références soient effectivement déférées. Si les refs existent déjà dans votre schéma cible, dbt les utilisera plutôt que de déférer.
Les mêmes bénéfices peuvent être obtenus avec des clones d'objets, comme ceux créés par la fonctionnalité Zero Copy Clone de Snowflake. Mais les clones doivent être recréés chaque fois que les objets de la base source sont mis à jour, et tous les systèmes de data warehouse ne prennent pas en charge le zero copy cloning. Il est donc plus simple et plus général d'utiliser --defer pour les cas d'usage de développement local.
Bonus : script wrapper pour --defer
Pour éviter de récupérer manuellement votre artifact manifest distant et de taper --defer --state /path/to/your/state à chaque fois, j'ai écrit un petit script wrapper pour simplifier les choses. J'héberge mon site de docs dbt depuis le même bucket s3 où je persiste les artifacts après les builds, ce qui est un moyen facile de récupérer les derniers artifacts de prod avant d'exécuter des invocations dbt avec --defer.
dbtdefer.sh
#!/bin/bash -ue
prod_manifest_uri="http://dbt.yourdomain/manifest.json"
target_dir="path/to/your/dbt/project/target/prod_manifest"
mkdir -p $target_dir
target_file="${target_dir}/manifest.json"
# this writes the contents of "$prod_manifest_uri" to "$target_file", if
# "$prod_manifest_uri" has been modified more recently than "$target_file"
curl -o "$target_file" -z "$target_file" "$prod_manifest_uri"
set -x
dbt $@ --defer --state "$target_dir"
chmod +x dbtdefer.sh
echo 'alias dbtdefer="/path/to/your/dbt/project/bin/dbt_defer/dbtdefer.sh"' >> ~/.bashrc
source ~/.bashrc
Vous pouvez désormais récupérer le dernier manifest et déférer les références en une seule commande : dbtdefer run -s <vos sélecteurs>. Cela fonctionne aussi avec dbtdefer build, ou toute autre commande dbt où vous souhaitez déférer les références.
L'option CLI --empty pour des dry runs limités au schéma
Un autre outil pour les builds locaux slim est l'option CLI --empty. Ajouter cette option à dbt run entraînera l'injection d'une instruction limit 0 dans toutes les sources et refs de votre modèle.
Au lieu de :
with my_expensive_transform as (
select ...
from {{ ref('source', 'my_big_table') }}
)
...
dbt soumettra ceci à la destination :
with my_expensive_transform as (
select ...
from {{ ref('source', 'my_big_table') }}
limit 0
)
...
La différence est subtile, mais elle peut avoir un impact considérable sur les requêtes complexes comportant des transformations coûteuses ou de grandes tables de base. dbt exécutera toujours le SQL du modèle sur le data warehouse cible, mais évitera les lectures et transformations coûteuses des données d'entrée. Cela valide les dépendances et garantit que vos modèles se construiront correctement, sans les construire réellement. C'est utile pour valider des changements de schéma en développement local, lorsque vous prévoyez de construire les modèles avec l'ensemble des données d'entrée dans un autre environnement disposant de davantage de ressources de calcul.
Échantillonnage de lignes
Voici une autre manière créative de limiter la quantité de données construites dans les contextes d'invocation de développement (local ou CI/CD). L'idée est de limiter ou de filtrer en développement les modèles comportant un grand nombre de lignes, afin que les transformations sur ces petits sous-ensembles soient rapides. Par exemple :
with my_big_ref as (
select * from {{ ref('my_big_table') }}
limit 500
-- OR
-- where updated_at >= DATEADD(week, -1, CURRENT_DATE)
-- etc
)
... more transforms go here ...
Ces techniques d'échantillonnage peuvent être encapsulées dans une surcharge de la macro ref, afin que l'échantillonnage s'applique automatiquement selon le target dbt.
{% macro ref(model_name) %}
{%- set original_ref = builtins.ref(model_name) -%}
{%- if target.name == 'dev' -%}
(
select *
from {{ original_ref }}
limit 1000
)
{%- else -%}
{{ original_ref }}
{%- endif -%}
{% endmacro %}
La même chose est possible pour la macro source. Attention : surcharger et modifier le comportement des builtins peut entraîner des incompatibilités avec d'autres macros, par exemple dbt_utils.star().
Il semble que dbt travaille sur des fonctionnalités natives à ce sujet, potentiellement exposées via une option CLI --sample.
Personnellement, je n'ai jamais trouvé cette approche très agréable en termes d'expérience de développement. Pour être utiles et fiables lors des tests, les échantillons doivent tenir compte de l'intégrité référentielle et de la distribution inégale des données, et c'est bien plus difficile qu'il n'y paraît avec un DAG complexe. Cela dit, cela valait la peine d'en parler, surtout que dbt pourrait bientôt en proposer un support natif.
Conclusion
Cet article a présenté les concepts fondamentaux des builds dbt slim ainsi que quelques exemples concrets pour les mettre en œuvre dans un contexte d'invocation dbt local. Nous avons également mis en place la persistance des artifacts dbt et passé en revue plusieurs contextes d'invocation dbt dans lesquels les techniques de builds slim peuvent être appliquées. Poursuivez avec la partie 2 de cette série, Bonnes pratiques pour les workflows dbt, partie 2 : builds CI/CD slim, où nous explorerons les stratégies de CI/CD slim.
Alex Caruso·Lead Data Platform Engineer chez Entera
Alex est Lead Data Platform Engineer chez Entera, basé à New York, aux États-Unis.