O dbt virou peça-chave para muitos times de dados, viabilizando workflows de transformação modulares e consistentes que sustentam produtos de BI e ML. Conforme os projetos dbt crescem para centenas ou até milhares de modelos, garantir builds eficientes vira algo crítico para segurar os custos e manter a performance lá em cima. Há várias formas de otimizar projetos dbt e mantê-los enxutos, desde otimizações no nível do modelo até escolhas de arquitetura que favorecem builds eficientes. Este é o primeiro post de uma série de 3 partes, que vai se aprofundar justamente nesse segundo ponto: as estratégias para alcançar builds dbt "slim". Aqui vamos apresentar alguns conceitos gerais e, na sequência, percorrer vários exemplos práticos para um desenvolvimento local com dbt mais eficiente.
O que são Slim Builds no dbt?
Builds "slim" no dbt têm como objetivo reduzir ao máximo as invocações de modelos redundantes, desnecessárias ou erradas, dentro das restrições do seu ambiente de execução. O termo "slim CI" foi popularizado pelo próprio dbt em 2021, com a chegada do seletor de nós state:modified. Esse seletor é uma técnica poderosa para eliminar invocações desnecessárias de nós, mas hoje existem muitas outras opções para manter seu projeto dbt enxuto e performático.
A imagem abaixo ilustra o conceito central por trás dos slim builds: com base em algum critério de seleção que você define, apenas um subconjunto do total de modelos é reconstruído em uma determinada invocação do dbt. Pode ser, por exemplo, modelos cujo código foi alterado, que tiveram as fontes atualizadas ou que atendem a outros critérios.
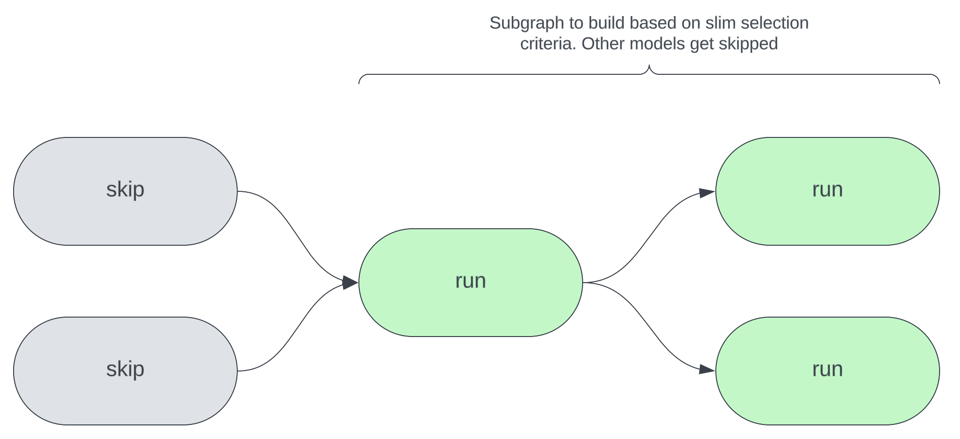
Por que focar em orquestração em vez de outras otimizações?
Algo que noto com frequência em discussões sobre performance e custo de projetos dbt é o foco em otimizações e considerações de "baixo nível". São exemplos disso: perfis de query de modelos individuais, clustering keys, right-sizing de warehouse ou incrementalização de modelos. Todos esses pontos são importantes para manter um projeto dbt performático e com bom custo-benefício.
Mas, na minha visão, um aspecto que costuma passar batido é o das considerações de orquestração em torno da execução dos modelos dbt. Mais especificamente, vale prestar atenção nas condições e na frequência com que os modelos são construídos e reconstruídos. O ideal é que sejam reconstruídos o mínimo possível, e que invocações redundantes ou desnecessárias sejam totalmente eliminadas ou ajustadas para reduzir tempo de execução e custo de computação.
Se seus custos de computação com dbt estão fora de controle, talvez o problema não seja a performance dos modelos. Pode ser que você simplesmente esteja reconstruindo eles demais!
Antes de partir para as estratégias para alcançar slim builds, vamos revisar algumas premissas e arquiteturas possíveis que podem impactar os conceitos desta série.
Premissas
Para manter a consistência ao longo da série, vamos assumir o seguinte:
- Uso do
dbt core, e não dodbt cloud - Warehouses estão right-sized; ou seja, não há warehouses subdimensionados sendo usados em modelos grandes, o que estenderia os tempos de execução
- Pipelines padrão de processamento em batch, com atualizações diárias, semanais ou mensais. Vamos ignorar padrões menos comuns envolvendo microbatches, streams ou dynamic tables
- Isolamento no nível do database entre contextos distintos de invocação do dbt
Contextos de invocação do dbt
A maioria das organizações roda o dbt em três "contextos de invocação" diferentes:
- Desenvolvimento local (ex.: rodar o dbt direto do seu notebook)
- Pipelines de CI/CD (ex.: jobs do GitHub Actions para testar mudanças de código antes de subir para produção)
- Builds agendados, normalmente orquestrados por ferramentas como Airflow, Dagster ou Prefect
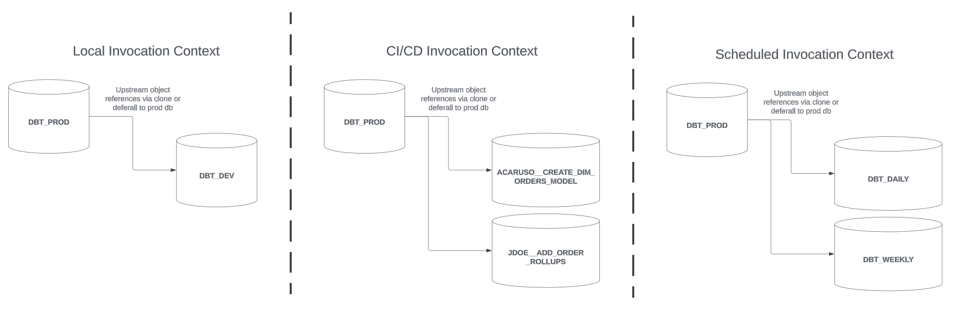
Cada um desses contextos costuma ter um ou mais databases ou schemas dedicados, onde os modelos podem ser construídos de forma isolada. As estratégias para slim builds descritas nesta série trazem benefícios em todos esses contextos. Para simplificar, vamos assumir a seguinte arquitetura:
- Invocações locais do dbt são construídas em um database dedicado, o
DBT_DEV, com um schema por desenvolvedor - Invocações de CI/CD do dbt são construídas em um database dedicado
<GIT BRANCH NAME>, com nome baseado na branch do git para o seu changeset / PR. Por exemplo,ACARUSO__CREATE_DIM_ORDERS_MODEL - Invocações agendadas do dbt são construídas em um database dedicado, com nome baseado no agendamento. Por exemplo,
DBT_DAILY
As dependências upstream dos modelos construídos em cada um desses contextos podem ser referenciadas como clones ou via deferrals. Para builds agendados de CI/CD e produção, assuma que os modelos são promovidos para um database de produção depois de uma invocação bem-sucedida do dbt, em estilo blue-green.
Exemplo de configuração: persistindo artefatos do dbt
Antes de partir para exemplos específicos de critérios de seleção slim e técnicas de build, vamos ver uma abordagem simples para persistir artefatos do dbt, que serão necessários para algumas técnicas de seleção slim. Em especial, vamos precisar persistir os arquivos manifest.json e sources.json. Eles são gerados automaticamente em target/<artifact>.json ao rodar comandos como dbt run, dbt build ou dbt source freshness.
Em um contexto de invocação via CI/CD, normalmente você não roda jobs em uma máquina com armazenamento persistente entre builds. Por isso, eu gosto de guardar os artefatos em um object storage remoto e externo, como o AWS S3.
(depois de uma invocação bem-sucedida em produção de dbt run ou dbt build):
cd target
aws s3 cp manifest.json s3://dbt-artifacts/manifest.json
(depois de uma invocação bem-sucedida em produção de dbt source freshness):
cd target
aws s3 cp sources.json s3://dbt-artifacts/sources.json
Agora você pode baixar esses arquivos em um diretório chamado .state antes de qualquer invocação do dbt que utilize seletores baseados em state.
1aws s3 sync s3://dbt-artifacts .state
Com esses arquivos no lugar, o dbt tem as informações necessárias para determinar quais nós executar em uma invocação com um determinado conjunto de seletores de state.
Slim Local Builds
Agora vamos mergulhar nas diferentes opções que você tem para rodar builds dbt eficientes localmente.
Flag --defer da CLI para reaproveitar objetos de produção já construídos
Em vez de reconstruir as dependências upstream do zero toda vez que você invoca o dbt localmente, dá para "adiar" (defer) as referências para outro database usando a flag de CLI --defer. Assim você não precisa ficar esperando builds longos e caros em um contexto de desenvolvimento local. Se os upstreams dos modelos em que você está trabalhando já existem em algum database de produção, e você não precisa mexer neles, faz todo sentido reaproveitar essas versões no contexto de desenvolvimento.
Suponha que nosso DAG seja assim:
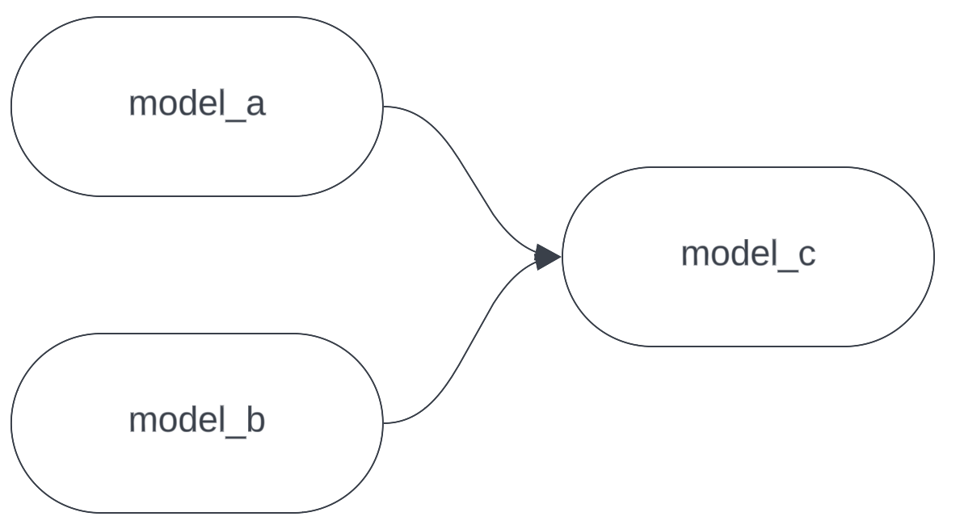
Agora imagine que você está fazendo alterações no model_c e rodando o dbt localmente para testar. Você precisa dos dados mais recentes do model_a e do model_b para validar suas mudanças, mas eles são modelos enormes e caros, que levariam horas para construir em um warehouse de desenvolvimento. Esse é o caso perfeito para o --defer. Em vez de rodar:
1dbt run -s +model_c
tente:
1dbt run -s model_c --defer --state .state
Isso vai "adiar" as referências a esses modelos para o database definido no seu arquivo .state/manifest.json, que deve ser o seu database de produção, conforme configuramos acima. Agora, o SQL compilado para o model_c pode ficar assim:
create or replace transient table dbt_dev.acaruso.model_c as
with
a as (select * from dbt_prod.schema.model_a),
b as (select * from dbt_prod.schema.model_b),
final as (select * from a inner join b using (id))
select * from final;
Repare que as referências totalmente qualificadas a model_a e model_b usam o database dbt_prod, e não o dbt_dev, justamente porque nunca reconstruímos esses modelos em dev. Atenção: sempre trabalhe a partir de um schema vazio ao usar --defer, para garantir que as referências de fato sejam adiadas. Se os refs já existirem no seu schema de destino, o dbt vai usá-los em vez de adiar.
Dá para obter os mesmos benefícios com clones de objetos, como os criados pelo recurso Zero Copy Clone do Snowflake. O detalhe é que os clones precisam ser recriados toda vez que os objetos no database de origem são atualizados, e nem todo data warehouse oferece suporte a zero copy cloning. Por isso, usar --defer para casos de desenvolvimento local é um pouco mais direto e abrangente.
Bônus: script wrapper para --defer
Em vez de ter que buscar o artefato remoto do manifest e digitar --defer --state /path/to/your/state toda vez, escrevi um pequeno script wrapper para simplificar. Eu hospedo o site de docs do meu dbt no mesmo bucket S3 onde persisto os artefatos depois dos builds, então essa é uma forma prática de buscar os artefatos de produção mais recentes antes de rodar invocações do dbt com --defer.
dbtdefer.sh
#!/bin/bash -ue
prod_manifest_uri="http://dbt.yourdomain/manifest.json"
target_dir="path/to/your/dbt/project/target/prod_manifest"
mkdir -p $target_dir
target_file="${target_dir}/manifest.json"
# this writes the contents of "$prod_manifest_uri" to "$target_file", if
# "$prod_manifest_uri" has been modified more recently than "$target_file"
curl -o "$target_file" -z "$target_file" "$prod_manifest_uri"
set -x
dbt $@ --defer --state "$target_dir"
chmod +x dbtdefer.sh
echo 'alias dbtdefer="/path/to/your/dbt/project/bin/dbt_defer/dbtdefer.sh"' >> ~/.bashrc
source ~/.bashrc
Agora dá para buscar o manifest mais recente e adiar as referências com um único comando: dbtdefer run -s <your selectors>. Também funciona com dbtdefer build, ou qualquer outro comando dbt em que você queira adiar referências.
Flag --empty da CLI para dry runs só de schema
Outra ferramenta para slim local builds é a flag de CLI --empty. Adicionar essa opção ao dbt run faz com que uma instrução limit 0 seja injetada em todas as sources e refs do seu modelo.
Em vez de:
with my_expensive_transform as (
select ...
from {{ ref('source', 'my_big_table') }}
)
...
o dbt vai mandar isto para o destino:
with my_expensive_transform as (
select ...
from {{ ref('source', 'my_big_table') }}
limit 0
)
...
É uma diferença sutil, mas que pode ter um grande impacto em queries complexas, com transformações caras ou tabelas base grandes. O dbt continua executando o SQL do modelo contra o data warehouse de destino, mas evita leituras e transformações caras dos dados de entrada. Isso valida as dependências e garante que seus modelos vão construir corretamente, mas sem efetivamente construí-los. É útil para validar mudanças de schema em desenvolvimento local, onde depois você pode construir os modelos com os dados completos em outro ambiente, com mais recursos de computação.
Amostragem de linhas
Essa é outra forma criativa de limitar o volume de dados sendo construído em contextos de invocação de desenvolvimento (local ou CI/CD). A ideia é limitar ou filtrar modelos com grande número de linhas em desenvolvimento, para que as transformações sobre esses subconjuntos menores sejam rápidas. Por exemplo:
with my_big_ref as (
select * from {{ ref('my_big_table') }}
limit 500
-- OR
-- where updated_at >= DATEADD(week, -1, CURRENT_DATE)
-- etc
)
... more transforms go here ...
Técnicas de amostragem assim podem ser empacotadas em um override da macro ref, para que a amostragem seja aplicada automaticamente conforme o target do dbt.
{% macro ref(model_name) %}
{%- set original_ref = builtins.ref(model_name) -%}
{%- if target.name == 'dev' -%}
(
select *
from {{ original_ref }}
limit 1000
)
{%- else -%}
{{ original_ref }}
{%- endif -%}
{% endmacro %}
O mesmo dá para fazer com a macro source. Só fique atento: sobrescrever e alterar o comportamento de builtins pode gerar problemas de incompatibilidade com outras macros, como o dbt_utils.star().
Pelo que parece, o dbt está desenvolvendo alguns recursos nativos para isso, possivelmente expostos via uma flag de CLI --sample.
Pessoalmente, nunca achei essa abordagem muito amigável do ponto de vista da experiência de desenvolvimento. As amostras precisam considerar integridade referencial e dados distribuídos de forma desigual para serem úteis e confiáveis nos testes, e isso é bem mais difícil do que parece em um DAG complexo. Mesmo assim, achei que valia a pena mencionar, até porque o dbt deve em breve oferecer suporte nativo para isso.
Conclusão
Este post apresentou os conceitos centrais por trás dos slim dbt builds e alguns exemplos práticos para alcançá-los em um contexto de invocação local do dbt. Também configuramos a persistência de artefatos do dbt e revisamos vários "contextos de invocação" do dbt em que essas técnicas podem ser aplicadas. Continue na Parte 2 da série, Boas práticas para workflows dbt, Parte 2: Slim CI/CD Builds, onde vamos mergulhar nas estratégias de slim CI/CD.
Alex Caruso·Lead Data Platform Engineer na Entera
Alex é Lead Data Platform Engineer na Entera, baseado em Nova York, Estados Unidos.