dbt se ha convertido en una pieza fundamental para muchos equipos de datos, ya que permite armar workflows de transformación modulares y consistentes que alimentan productos de BI y ML. A medida que los proyectos de dbt escalan a cientos o incluso miles de modelos, lograr builds eficientes se vuelve clave para mantener los costos bajos y el rendimiento alto. Hay muchas formas de optimizar proyectos de dbt y mantenerlos ágiles, desde optimizaciones a nivel de modelo hasta decisiones de arquitectura que favorecen builds eficientes. Este es el primer post de una serie de 3 partes que profundiza en lo segundo, específicamente en estrategias para lograr builds "slim" de dbt. En este post se presentan algunos conceptos generales y luego se repasan varios ejemplos prácticos para un desarrollo local eficiente con dbt.
¿Qué son los Slim Builds de dbt?
Los builds "slim" de dbt buscan reducir al mínimo las invocaciones de modelos redundantes, innecesarias o erróneas, dentro de los límites de tu entorno de ejecución. La expresión "slim CI" fue popularizada por el propio dbt en 2021 con la incorporación del selector de nodos state:modified. Este selector es una técnica potente para eliminar invocaciones innecesarias de nodos, pero hoy existen muchas más opciones para mantener tu proyecto de dbt ágil y eficiente.
La imagen de abajo ilustra el concepto central de los slim builds: a partir de ciertos criterios de selección que tú defines, solo un subconjunto del total de modelos se reconstruye en una invocación dada de dbt. Pueden ser modelos cuyo código se modificó, que tienen sources actualizados o que cumplen otros criterios.
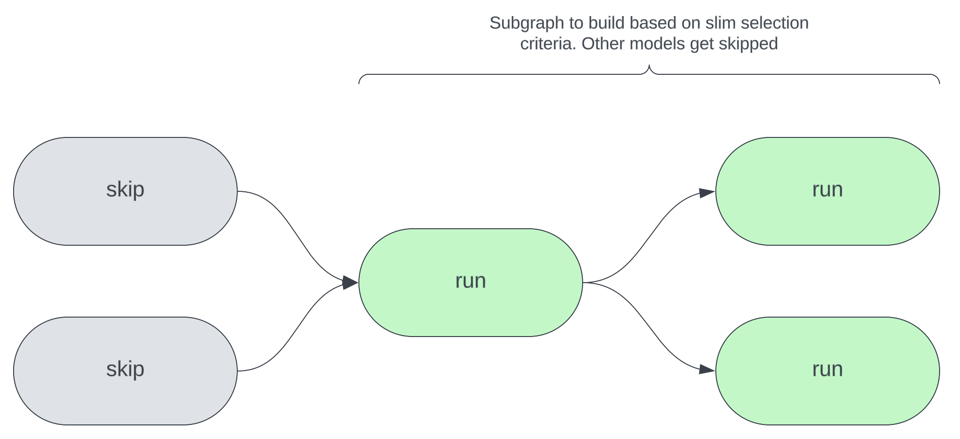
¿Por qué enfocarse en la orquestación y no en otras optimizaciones?
Algo que he notado seguido en las discusiones sobre el perfil de rendimiento y la huella de costos de los proyectos de dbt es el enfoque en optimizaciones y consideraciones de "bajo nivel". Algunos ejemplos serían los query profiles de modelos individuales, las clustering keys, el right-sizing de warehouses o la incrementalización de modelos. Todos estos aspectos son importantes para mantener un proyecto de dbt eficiente en rendimiento y costo.
Sin embargo, hay un aspecto que creo que suele pasarse por alto: las consideraciones de orquestación al correr modelos de dbt. En particular, las condiciones bajo las cuales y la frecuencia con la que se construyen y reconstruyen los modelos son factores importantes. Lo ideal es que los modelos se reconstruyan con la menor frecuencia posible, y que las invocaciones redundantes o innecesarias se eliminen por completo o se ajusten para reducir el tiempo de ejecución y el costo de cómputo asociado.
Si tus costos de cómputo en dbt están fuera de control, puede que no sea porque tus modelos sean poco eficientes. ¡Quizá simplemente los estás reconstruyendo de más!
Antes de meternos en algunas estrategias para lograr slim builds, repasemos algunos supuestos y posibles arquitecturas que pueden tener implicaciones en los conceptos de esta serie.
Supuestos
Para mantener la consistencia a lo largo de esta serie, asumamos lo siguiente:
- Uso de
dbt core, en lugar dedbt cloud - Los warehouses están right-sized; es decir, no hay warehouses subdimensionados corriendo modelos grandes que alarguen los tiempos de ejecución
- Pipelines estándar de procesamiento por lotes con frecuencias de refresh diarias, semanales o mensuales. Vamos a ignorar patrones menos comunes como microbatches, streams o dynamic tables
- Aislamiento a nivel de base de datos entre los distintos contextos de invocación de dbt
Contextos de invocación de dbt
La mayoría de las organizaciones suele correr dbt en tres "contextos de invocación" distintos:
- Desarrollo local (p. ej., correr dbt desde tu laptop)
- Pipelines de CI/CD (p. ej., jobs de GitHub Actions para probar cambios de código antes de subirlos a producción)
- Builds programados, normalmente orquestados con herramientas como Airflow, Dagster o Prefect
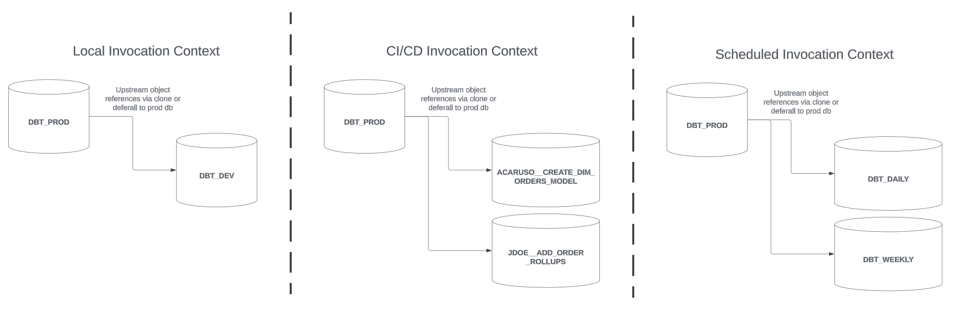
Cada uno de estos contextos suele tener una o más bases de datos o schemas dedicados donde los modelos se construyen de forma aislada. Las estrategias para slim builds que se describen en esta serie aportan beneficios en cada uno de estos contextos. Por simplicidad, asumamos la siguiente arquitectura:
- Las invocaciones locales de dbt se construyen en una base de datos dedicada
DBT_DEV, con un schema por desarrollador - Las invocaciones de dbt en CI/CD se construyen en una base de datos dedicada
<GIT BRANCH NAME>, nombrada según la rama de git de tu changeset / PR. Por ejemplo,ACARUSO__CREATE_DIM_ORDERS_MODEL - Las invocaciones programadas de dbt se construyen en una base de datos dedicada, nombrada según la programación. Por ejemplo,
DBT_DAILY
Las dependencias upstream de los modelos construidos en cada uno de estos contextos pueden referenciarse como clones o mediante deferrals. Para los builds de CI/CD y de producción programados, asumamos que los modelos se promueven a una base de datos de producción tras una invocación exitosa de dbt, al estilo blue-green.
Ejemplo de configuración: persistencia de artifacts de dbt
Antes de pasar a ejemplos concretos de criterios de selección slim y técnicas de build, veamos un enfoque sencillo para persistir los artifacts de dbt, que se necesitan para algunas técnicas de selección slim. En particular, vamos a necesitar persistir los archivos manifest.json y sources.json. Estos archivos se generan automáticamente en target/<artifact>.json al ejecutar varios comandos de dbt como dbt run, dbt build o dbt source freshness.
En un contexto de invocación de CI/CD, lo normal es que no corras los jobs en una máquina con almacenamiento persistente entre builds. Por eso me gusta guardar los artifacts en almacenamiento de objetos externo remoto como AWS S3.
(después de una invocación exitosa en producción de dbt run o dbt build):
cd target
aws s3 cp manifest.json s3://dbt-artifacts/manifest.json
(después de una invocación exitosa en producción de dbt source freshness):
cd target
aws s3 cp sources.json s3://dbt-artifacts/sources.json
Ahora puedes descargar estos archivos a un directorio llamado .state antes de cualquier invocación de dbt donde uses selectores basados en estado.
1aws s3 sync s3://dbt-artifacts .state
Con estos archivos listos, dbt tiene la información que necesita para decidir qué nodos ejecutar en una invocación con un determinado conjunto de selectores de estado.
Slim Local Builds
Veamos ahora las distintas opciones que tienes para correr builds eficientes de dbt en local.
Flag --defer en la CLI para reutilizar objetos de producción ya construidos
En lugar de reconstruir desde cero las dependencias upstream cada vez que invocas dbt localmente, puedes "diferir" las referencias a otra base de datos usando el flag --defer de la CLI. Así te ahorras la espera de builds largos y costosos en un contexto de desarrollo local. Si los upstreams de los modelos en los que estás trabajando ya están construidos en alguna base de datos de producción, y no necesitas hacerles cambios, lo más práctico es reutilizarlos en desarrollo.
Supongamos que nuestro DAG se ve así:
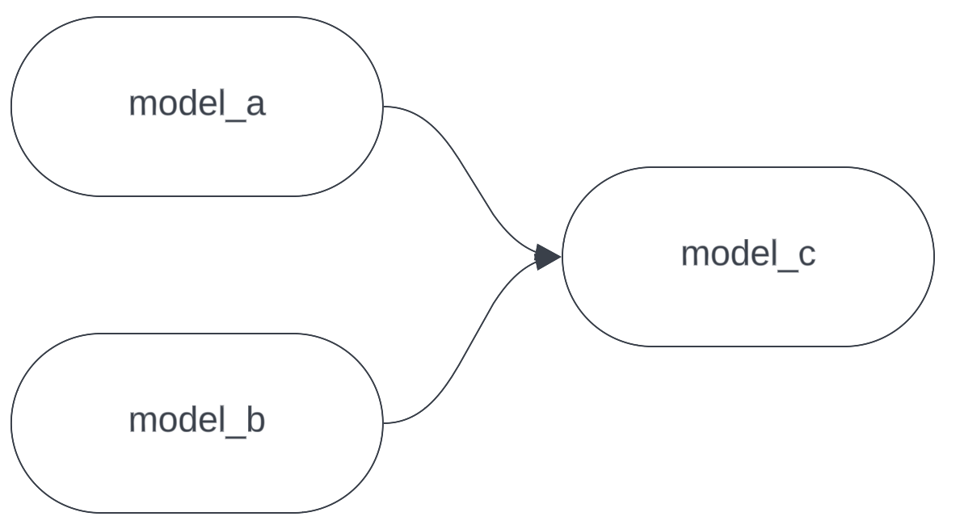
Ahora imagina que estás haciendo cambios en model_c y corriendo dbt localmente para probarlos. Necesitas los datos más recientes de model_a y model_b para probar tus cambios, pero son modelos enormes y costosos que tardarían horas en construirse en un warehouse de desarrollo. Este es un caso ideal para --defer. En lugar de ejecutar:
1dbt run -s +model_c
prueba:
1dbt run -s model_c --defer --state .state
Esto "diferirá" las referencias a esos modelos hacia la base de datos definida en tu archivo .state/manifest.json, que debería ser tu base de datos de producción, como configuramos antes. Ahora tu SQL compilado para model_c podría verse así:
create or replace transient table dbt_dev.acaruso.model_c as
with
a as (select * from dbt_prod.schema.model_a),
b as (select * from dbt_prod.schema.model_b),
final as (select * from a inner join b using (id))
select * from final;
Fíjate cómo las referencias completamente calificadas a model_a y model_b usan la base de datos dbt_prod, y no dbt_dev, porque nunca las reconstruimos en dev. Nota: conviene siempre trabajar desde un schema vacío con --defer, para asegurarte de que las referencias efectivamente se difieran. Si las refs ya existen en tu schema de destino, dbt usará esas en lugar de diferirlas.
Los mismos beneficios se pueden lograr con clones de objetos, como los que crea la función Zero Copy Clone de Snowflake. Sin embargo, los clones hay que recrearlos cada vez que se actualizan los objetos en la base de datos origen, y no todos los sistemas de data warehouse soportan zero copy cloning. Por eso es un poco más directo y general usar --defer para casos de desarrollo local.
Bonus: script wrapper para --defer
En vez de tener que descargar tu manifest remoto y escribir --defer --state /path/to/your/state cada vez, escribí un pequeño script wrapper para simplificar las cosas. Hospedo mi sitio de docs de dbt desde el mismo bucket de s3 donde guardo los artifacts después de los builds, así que es una forma fácil de traer los últimos artifacts de prod antes de correr invocaciones de dbt con --defer.
dbtdefer.sh
#!/bin/bash -ue
prod_manifest_uri="http://dbt.yourdomain/manifest.json"
target_dir="path/to/your/dbt/project/target/prod_manifest"
mkdir -p $target_dir
target_file="${target_dir}/manifest.json"
# this writes the contents of "$prod_manifest_uri" to "$target_file", if
# "$prod_manifest_uri" has been modified more recently than "$target_file"
curl -o "$target_file" -z "$target_file" "$prod_manifest_uri"
set -x
dbt $@ --defer --state "$target_dir"
chmod +x dbtdefer.sh
echo 'alias dbtdefer="/path/to/your/dbt/project/bin/dbt_defer/dbtdefer.sh"' >> ~/.bashrc
source ~/.bashrc
Ahora puedes traer el último manifest y diferir referencias con un solo comando: dbtdefer run -s <tus selectores>. También funciona con dbtdefer build, o con cualquier otro comando de dbt donde quieras diferir referencias.
Flag --empty en la CLI para dry runs solo de schema
Otra herramienta para slim local builds es el flag --empty de la CLI. Agregar esta opción a dbt run hace que se inyecte una sentencia limit 0 en todos los sources y refs de tu modelo.
En vez de:
with my_expensive_transform as (
select ...
from {{ ref('source', 'my_big_table') }}
)
...
dbt enviará esto al destino:
with my_expensive_transform as (
select ...
from {{ ref('source', 'my_big_table') }}
limit 0
)
...
Es una diferencia sutil, pero puede tener un gran impacto en consultas complejas con transformaciones costosas o tablas base grandes. dbt seguirá ejecutando el SQL del modelo contra el data warehouse de destino, pero evitará lecturas y transformaciones costosas de los datos de entrada. Esto valida las dependencias y asegura que tus modelos se construirán correctamente, sin llegar a construirlos en realidad. Es útil para validar cambios de schema en desarrollo local, donde luego puedes construir los modelos con los datos completos en otro entorno con más recursos de cómputo.
Row sampling
Esta es otra forma creativa de limitar la cantidad de datos que se construyen en contextos de desarrollo (local o CI/CD). La idea es limitar o filtrar modelos con muchos registros en desarrollo, para que las transformaciones sobre esos subconjuntos pequeños sean rápidas. Por ejemplo:
with my_big_ref as (
select * from {{ ref('my_big_table') }}
limit 500
-- OR
-- where updated_at >= DATEADD(week, -1, CURRENT_DATE)
-- etc
)
... more transforms go here ...
Estas técnicas de sampling de datos se pueden empaquetar en un override del macro ref, para que el sampling se aplique automáticamente según el target de dbt.
{% macro ref(model_name) %}
{%- set original_ref = builtins.ref(model_name) -%}
{%- if target.name == 'dev' -%}
(
select *
from {{ original_ref }}
limit 1000
)
{%- else -%}
{{ original_ref }}
{%- endif -%}
{% endmacro %}
Lo mismo se puede hacer con el macro source. Ten en cuenta que sobreescribir y cambiar el comportamiento de los builtins puede generar problemas de incompatibilidad con otros macros, por ejemplo dbt_utils.star().
Parece que dbt está trabajando en algunas funciones nativas para esto, posiblemente expuestas mediante un flag --sample en la CLI.
Personalmente, nunca me pareció un enfoque muy cómodo desde la experiencia de desarrollo. Las muestras necesitan considerar la integridad referencial y la distribución dispareja de los datos para ser útiles y confiables al hacer pruebas, y esto es mucho más difícil de lo que parece con un DAG complejo. Aun así, quería mencionarlo, sobre todo porque dbt podría darle soporte nativo pronto.
Cierre
Este post presentó los conceptos centrales detrás de los slim builds de dbt y algunos ejemplos prácticos para lograrlos en un contexto de invocación local. También configuramos la persistencia de artifacts de dbt y revisamos varios "contextos de invocación" de dbt donde se pueden aplicar las técnicas de slim build. Continúa con la Parte 2 de esta serie, Buenas prácticas para workflows de dbt, Parte 2: Slim CI/CD Builds, donde profundizamos en estrategias de slim CI/CD.
Alex Caruso·Lead Data Platform Engineer en Entera
Alex es Lead Data Platform Engineer en Entera, con base en Nueva York, Estados Unidos.