dbtは多くのデータチームにとって欠かせない存在となり、モジュール化された一貫性のあるデータ変換ワークフローでBIやMLプロダクトを支えています。dbtプロジェクトのモデル数が数百、数千へとスケールしていくなかで、コストを抑えつつパフォーマンスを維持するには、効率的なビルドが欠かせません。dbtプロジェクトをスリムに最適化する方法は、モデル単位のチューニングから、効率的なビルドを後押しするアーキテクチャ設計まで多岐にわたります。本記事は全3回シリーズの第1回として、後者、とりわけ「スリムな」dbtビルドを実現するための戦略を掘り下げます。まずは大枠の考え方を整理したうえで、効率的なローカルdbt開発に向けた具体例を見ていきましょう。
dbtのスリムビルドとは?
「スリム」なdbtビルドとは、実行環境の制約のなかで、冗長・不要・誤ったモデル呼び出しを徹底的に減らすという考え方です。「slim CI」という言葉は、2021年にstate:modifiedノードセレクタが導入された際、dbt自身が広めました。このセレクタは不要なノード呼び出しを排除する強力な手段ですが、いまではdbtプロジェクトをスリムかつ高速に保つための選択肢はさらに増えています。
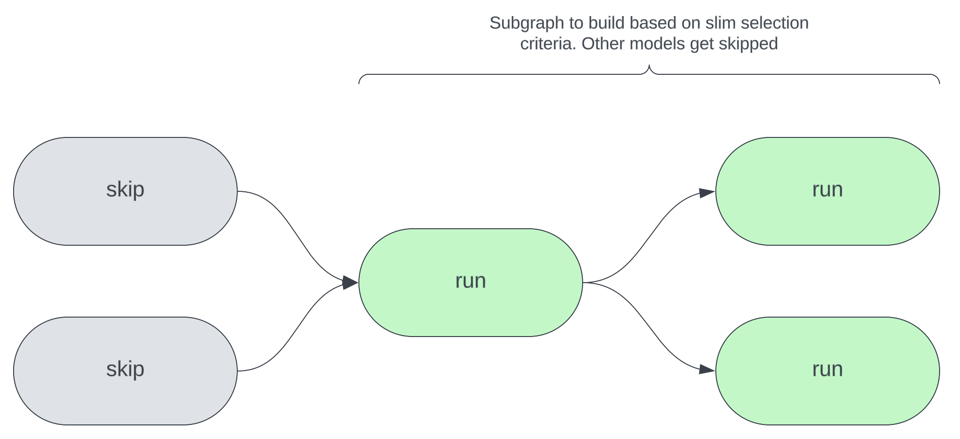
下図はスリムビルドの中心的な考え方を示したものです。任意の選択基準に基づき、dbtの実行ごとに再ビルドされるのは全モデルのうち一部だけになります。対象は、コードが変更されたモデル、ソースが更新されたモデル、あるいはその他の条件を満たすモデルなどです。
なぜ他の最適化ではなくオーケストレーションに着目するのか?
dbtプロジェクトのパフォーマンスやコスト構造をめぐる議論では、「低レベル」な最適化に注目が集まりがちです。たとえば個々のモデルのクエリプロファイル、クラスタリングキー、ウェアハウスのライトサイジング、モデルのインクリメンタル化などが典型例です。いずれも、パフォーマンスとコスト効率の両立に欠かせない要素であることは間違いありません。
一方で、見落とされがちなのがdbtモデルの実行を取り巻くオーケストレーションの視点だと私は考えています。とりわけ、どのような条件で、どのくらいの頻度でモデルがビルド・再ビルドされるかは重要なポイントです。理想を言えば、モデルの再ビルドはできるだけ少ない頻度に抑え、冗長または不要な呼び出しは完全に取り除くか、実行時間とコンピュートコストを最小化する形に変えるべきです。
dbtのコンピュートコストが膨らんでいる原因は、モデルが遅いことではないかもしれません。単に再ビルドの回数が多すぎるだけ、というケースは少なくないのです。
スリムビルドを実現する具体策に入る前に、本シリーズの前提となる条件と想定アーキテクチャを確認しておきましょう。
前提条件
シリーズ全体を通じて一貫性を保つため、以下を前提とします。
dbt cloudではなくdbt coreを使用- ウェアハウスが適切にサイジングされている。すなわち、大規模モデルに対してアンダースペックなウェアハウスを使い、実行時間が長引くようなことはない
- 日次・週次・月次のリフレッシュ頻度を持つ標準的なバッチ処理パイプライン。マイクロバッチ、ストリーム、ダイナミックテーブルといった比較的特殊なパターンは扱いません
- 異なるdbt呼び出しコンテキスト間でデータベースレベルの分離が行われている
dbtの呼び出しコンテキスト
多くの組織では、dbtを大きく3つの「呼び出しコンテキスト」で実行しています。
- ローカル開発(例:ノートPCからdbtを実行)
- CI/CDパイプライン(例:本番にプッシュする前にコード変更をテストするGitHub Actionsジョブ)
- スケジュール実行。通常はAirflow、Dagster、Prefectなどのツールでオーケストレーションされる
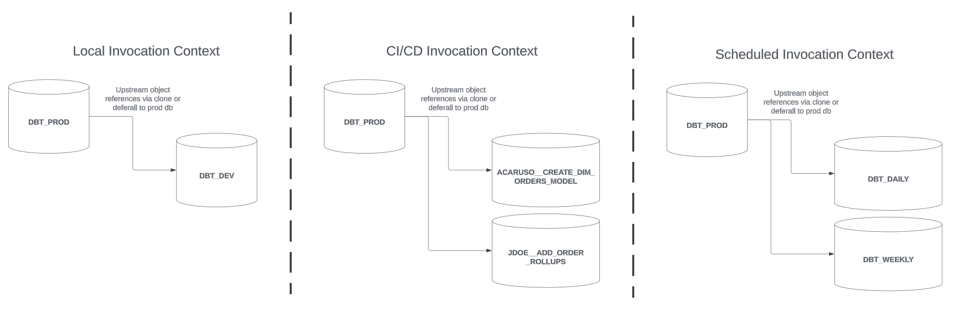
これらの呼び出しコンテキストには通常、モデルを隔離してビルドできる専用のデータベースまたはスキーマが1つ以上用意されています。本シリーズで紹介するスリムビルドの戦略は、いずれのコンテキストでも効果を発揮します。簡略化のため、以下のアーキテクチャを前提とします。
- ローカルのdbt実行は、専用の
DBT_DEVデータベース内で開発者ごとのスキーマにビルドされる - CI/CDのdbt実行は、変更セット/PRのgitブランチ名にちなんで命名された専用の
<GIT BRANCH NAME>データベースにビルドされる。例:ACARUSO__CREATE_DIM_ORDERS_MODEL - スケジュール実行は、スケジュール名にちなんだ専用データベースにビルドされる。例:
DBT_DAILY
これら各コンテキストでビルドされるモデルの上流依存は、クローン経由でも、deferralでも参照できます。CI/CDおよびスケジュール実行による本番ビルドでは、dbt実行が成功した後にブルーグリーン方式で本番DBへモデルを昇格させるものとします。
セットアップ例:dbtアーティファクトの永続化
スリムな選択基準やビルド手法の具体例に入る前に、dbtアーティファクトを永続化するシンプルな方法を確認しておきましょう。これは一部のスリム選択手法で必要になります。具体的に永続化が必要なのは、manifest.jsonとsources.jsonです。これらはdbt run、dbt build、dbt source freshnessなどのコマンド実行時に、target/<artifact>.jsonとして自動生成されます。
CI/CDの呼び出しコンテキストでは、ビルドをまたいで永続ストレージを保持するマシン上でジョブを実行することは通常ありません。そのため私は、AWS S3のようなリモートの外部オブジェクトストレージにアーティファクトを保存する方法をおすすめしています。
(本番でのdbt runまたはdbt build成功後):
cd target
aws s3 cp manifest.json s3://dbt-artifacts/manifest.json
(本番でのdbt source freshness成功後):
cd target
aws s3 cp sources.json s3://dbt-artifacts/sources.json
こうしておけば、状態ベースのセレクタを使うdbt実行の前に、これらのファイルを.stateディレクトリにダウンロードできます。
1aws s3 sync s3://dbt-artifacts .state
これらのファイルが揃えば、指定された状態セレクタに基づいてどのノードを実行すべきかをdbtが判断するために必要な情報が手に入ります。
スリムなローカルビルド
では、ローカルでdbtビルドを効率化するためのさまざまな選択肢を見ていきましょう。
--defer CLIフラグでビルド済み本番オブジェクトを再利用する
ローカルでdbtを実行するたびに上流依存をゼロから再ビルドする代わりに、--defer CLIフラグで参照を別のデータベースに「defer(委ねる)」できます。これにより、ローカル開発で時間とコストのかかるビルドを待つ必要がなくなります。作業対象モデルの上流が本番データベースですでにビルド済みで、変更も不要なら、開発でもそれをそのまま使えばよい、というわけです。
DAGが次のような構成だとしましょう。
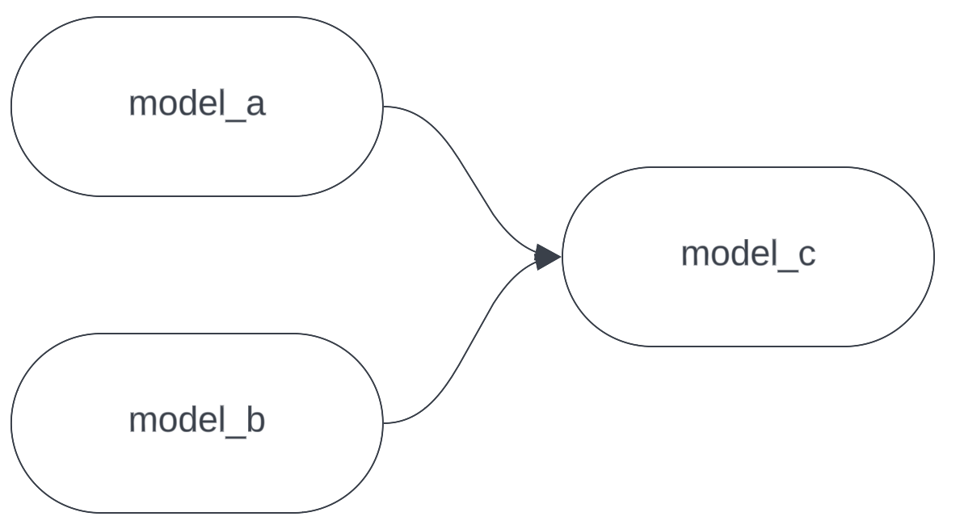
いま、model_cに変更を加え、ローカルでdbtを実行して動作確認しているとします。テストにはmodel_aとmodel_bの最新データが必要ですが、これらは巨大かつ高コストなモデルで、開発用ウェアハウスでビルドすると何時間もかかります。まさに--deferの出番です。次のように実行する代わりに:
1dbt run -s +model_c
こう実行します:
1dbt run -s model_c --defer --state .state
こうすると、これらのモデルへの参照は.state/manifest.jsonで定義されたデータベース(先ほどのセットアップどおり、本番データベース)にdeferされます。model_cのコンパイル後SQLは次のようになります:
create or replace transient table dbt_dev.acaruso.model_c as
with
a as (select * from dbt_prod.schema.model_a),
b as (select * from dbt_prod.schema.model_b),
final as (select * from a inner join b using (id))
select * from final;
model_aとmodel_bへの完全修飾参照がdbt_devではなくdbt_prodデータベースを指している点に注目してください。開発環境でこれらを再ビルドしていないためです。なお、--deferを使うときは、参照が確実にdeferされるよう、必ず空のスキーマから作業を始めてください。ターゲットスキーマにすでにrefが存在していると、dbtはdeferせずにそちらを使ってしまいます。
同じ効果はオブジェクトクローン、たとえばSnowflakeのZero Copy Clone機能で作成したクローンでも得られます。ただし、クローンはソースDBのオブジェクトが更新されるたびに作り直す必要があり、すべてのデータウェアハウスがゼロコピークローンに対応しているわけでもありません。そのため、ローカル開発のユースケースでは--deferのほうがシンプルで汎用的です。
ボーナス:--defer用のラッパースクリプト
毎回リモートのマニフェストアーティファクトを取得し、--defer --state /path/to/your/stateと入力するのは面倒なので、簡略化のための小さなラッパースクリプトを書いてみました。私はビルド後のアーティファクトを保存しているのと同じS3バケットからdbt docsサイトをホスティングしているので、--defer付きでdbtを実行する前に最新の本番アーティファクトを手軽に取得できます。
dbtdefer.sh
#!/bin/bash -ue
prod_manifest_uri="http://dbt.yourdomain/manifest.json"
target_dir="path/to/your/dbt/project/target/prod_manifest"
mkdir -p $target_dir
target_file="${target_dir}/manifest.json"
# this writes the contents of "$prod_manifest_uri" to "$target_file", if
# "$prod_manifest_uri" has been modified more recently than "$target_file"
curl -o "$target_file" -z "$target_file" "$prod_manifest_uri"
set -x
dbt $@ --defer --state "$target_dir"
chmod +x dbtdefer.sh
echo 'alias dbtdefer="/path/to/your/dbt/project/bin/dbt_defer/dbtdefer.sh"' >> ~/.bashrc
source ~/.bashrc
これでdbtdefer run -s <your selectors>というワンコマンドで、最新マニフェストの取得と参照のdeferをまとめて実行できます。dbtdefer buildはもちろん、参照をdeferしたい他のdbtコマンドでも同じように使えます。
--empty CLIフラグでスキーマのみのドライランを行う
スリムなローカルビルドのもう一つの武器が、--empty CLIフラグです。このオプションをdbt runに付けると、モデル内のすべてのソースとrefにlimit 0が差し込まれます。
つまり、以下のクエリの代わりに:
with my_expensive_transform as (
select ...
from {{ ref('source', 'my_big_table') }}
)
...
dbtはこちらを実行先に投げます:
with my_expensive_transform as (
select ...
from {{ ref('source', 'my_big_table') }}
limit 0
)
...
ささやかな違いに見えますが、重い変換処理や巨大なベーステーブルを伴う複雑なクエリでは大きな効果を発揮します。dbtはターゲットのデータウェアハウスに対してモデルSQLを実行はしますが、入力データの高コストな読み取りや変換は回避されます。これにより、モデルを実際にはビルドせずに、依存関係を検証し、ビルドが問題なく通ることを確認できます。ローカル開発でスキーマ変更を検証しつつ、フルデータでのビルドはより潤沢なコンピュートリソースを持つ別環境で行う、といった使い方に便利です。
行サンプリング
開発時の呼び出しコンテキスト(ローカルやCI/CD)でビルドされるデータ量を減らすもう一つの工夫が、行サンプリングです。考え方はシンプルで、開発環境では行数の多いモデルを制限・フィルタリングし、小さなサブセットに対してだけ変換を走らせることで処理を高速化します。例えば次のように書けます:
with my_big_ref as (
select * from {{ ref('my_big_table') }}
limit 500
-- OR
-- where updated_at >= DATEADD(week, -1, CURRENT_DATE)
-- etc
)
... more transforms go here ...
こうしたデータサンプリング処理はrefマクロのオーバーライドにまとめておけば、dbtのtargetに応じて自動的にサンプリングが適用されるようにできます。
{% macro ref(model_name) %}
{%- set original_ref = builtins.ref(model_name) -%}
{%- if target.name == 'dev' -%}
(
select *
from {{ original_ref }}
limit 1000
)
{%- else -%}
{{ original_ref }}
{%- endif -%}
{% endmacro %}
同じことはsourceマクロでも可能です。ただし、組み込み関数(builtins)をオーバーライドして挙動を変えると、たとえばdbt_utils.star()のような他のマクロとの互換性問題を引き起こすことがある点には注意してください。
dbt側でもこの機能のネイティブ対応が進められており、--sample CLIフラグとして公開される可能性があります。
個人的には、このアプローチは開発体験の面でそれほど使い勝手が良いと感じたことはありません。テストで使い物になる信頼できるサンプルを作るには、参照整合性や偏りのあるデータ分布まで考慮する必要があり、複雑なDAGになると想像以上に厄介です。とはいえ、dbtが近いうちにネイティブ対応する可能性もあるので、ここで触れておきたいと思いました。
まとめ
本記事では、スリムなdbtビルドの基本概念と、ローカルのdbt実行コンテキストでスリムビルドを実現するための実践例を紹介しました。あわせて、dbtアーティファクトの永続化のセットアップを行い、スリムビルド手法を適用できる複数のdbt「呼び出しコンテキスト」を整理しました。続編のdbtワークフローのベストプラクティス Part 2:スリムなCI/CDビルドでは、スリムなCI/CD戦略を掘り下げていきます。
Alex Caruso・Lead Data Platform Engineer at Entera
AlexはアメリカのニューヨークでEnteraのLead Data Platform Engineerを務めています。