dbt è ormai un pilastro per molti team dati: permette di costruire workflow di trasformazione modulari e coerenti, a supporto di prodotti BI e ML. Quando un progetto dbt cresce fino a contare centinaia o addirittura migliaia di modelli, l'efficienza delle build diventa cruciale per tenere sotto controllo i costi e mantenere alte le prestazioni. I modi per ottimizzare un progetto dbt e mantenerlo snello sono numerosi: si va dalle ottimizzazioni a livello di singolo modello alle scelte architetturali che favoriscono build più efficienti. Questo è il primo articolo di una serie in 3 parti che approfondisce proprio quest'ultimo aspetto, ovvero le strategie per ottenere build dbt "slim". In questo post introdurremo alcuni concetti generali e analizzeremo poi diversi esempi pratici per uno sviluppo dbt locale efficiente.
Cosa sono le slim build di dbt?
Le build dbt "slim" puntano a ridurre il più possibile le invocazioni di modelli ridondanti, superflue o errate, nei limiti del proprio ambiente di esecuzione. L'espressione "slim CI" è stata diffusa dalla stessa dbt nel 2021 con l'introduzione del node selector state:modified. Si tratta di una tecnica potente per eliminare invocazioni di nodi non necessarie, ma oggi esistono molte altre opzioni da esplorare per mantenere il progetto dbt snello e performante.
L'immagine qui sotto illustra il concetto alla base delle slim build: secondo i criteri di selezione scelti, solo un sottoinsieme dei modelli totali viene ricostruito in una determinata invocazione di dbt. Possono essere i modelli con codice modificato, quelli con sorgenti aggiornate o quelli che soddisfano altri criteri.
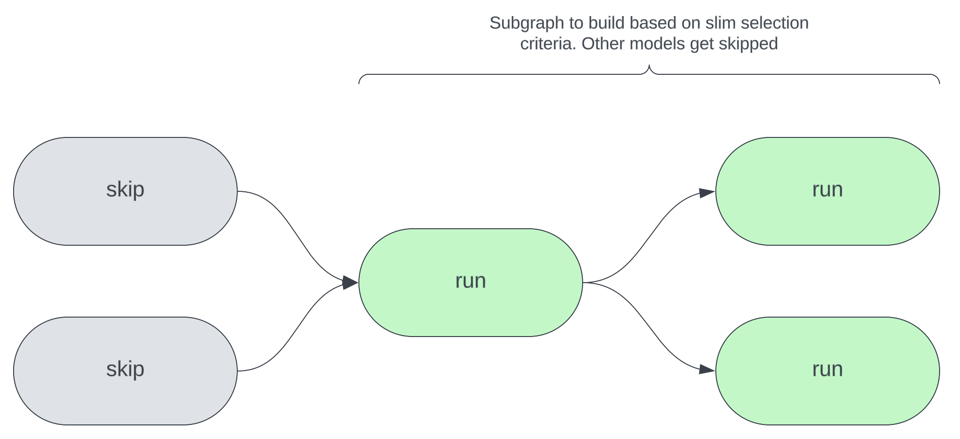
Perché concentrarsi sull'orchestration anziché su altre ottimizzazioni?
Una cosa che ho osservato spesso nelle discussioni sui profili di performance e sui costi dei progetti dbt è la tendenza a focalizzarsi su ottimizzazioni e considerazioni "di basso livello". Esempi tipici sono i query profile dei singoli modelli, le clustering key, il right-sizing dei warehouse o l'incrementalizzazione dei modelli. Tutti aspetti importanti per mantenere un progetto dbt performante e con costi sotto controllo.
C'è però un aspetto che, a mio avviso, viene comunemente trascurato: le scelte di orchestration legate all'esecuzione dei modelli dbt. In particolare, contano le condizioni e la frequenza con cui i modelli vengono costruiti e ricostruiti. Idealmente, i modelli andrebbero ricostruiti il meno spesso possibile e le invocazioni ridondanti o superflue andrebbero eliminate del tutto, oppure modificate per ridurre al minimo il runtime e i costi di compute.
Se i costi di compute dbt sono fuori controllo, il motivo potrebbe non essere la scarsa performance dei modelli. Magari li stai semplicemente ricostruendo troppo spesso!
Prima di entrare nelle strategie per ottenere build slim, vediamo alcune assunzioni e le possibili architetture che possono incidere sui concetti trattati nella serie.
Assunzioni
Per coerenza in tutta la serie, assumiamo quanto segue:
- Utilizzo di
dbt core, non didbt cloud - I warehouse sono dimensionati correttamente, ovvero non ci sono warehouse sottodimensionati per modelli di grandi dimensioni che ne allungherebbero i tempi di esecuzione
- Pipeline standard di batch processing con refresh giornaliero, settimanale o mensile. Tralasciamo pattern meno comuni come microbatch, stream o dynamic table
- Isolamento a livello di database tra i diversi contesti di invocazione di dbt
Contesti di invocazione di dbt
La maggior parte delle organizzazioni esegue dbt in tre diversi "contesti di invocazione":
- Sviluppo locale (ad esempio, eseguendo dbt dal proprio laptop)
- Pipeline CI/CD (ad esempio, job di GitHub Actions per testare le modifiche al codice prima del push in produzione)
- Build pianificate, tipicamente orchestrate da strumenti come Airflow, Dagster o Prefect
Ognuno di questi contesti dispone in genere di uno o più database o schemi dedicati in cui i modelli possono essere costruiti in isolamento. Le strategie per slim build descritte in questa serie offrono benefici in ciascuno di questi contesti. Per semplicità, assumiamo la seguente architettura:
- Le invocazioni dbt locali vengono costruite in un database dedicato
DBT_DEV, con uno schema per ciascuno sviluppatore - Le invocazioni dbt in CI/CD vengono costruite in un database dedicato
<NOME BRANCH GIT>, denominato in base al branch git del changeset / PR. Ad esempio,ACARUSO__CREATE_DIM_ORDERS_MODEL - Le invocazioni dbt pianificate vengono costruite in un database dedicato, denominato in base alla schedulazione. Ad esempio,
DBT_DAILY
Le dipendenze upstream dei modelli costruiti in ognuno di questi contesti possono essere referenziate tramite cloni oppure tramite deferral. Per le build CI/CD e quelle pianificate in produzione, assumiamo che i modelli vengano promossi a un db di produzione dopo un'invocazione dbt riuscita, in stile blue-green.
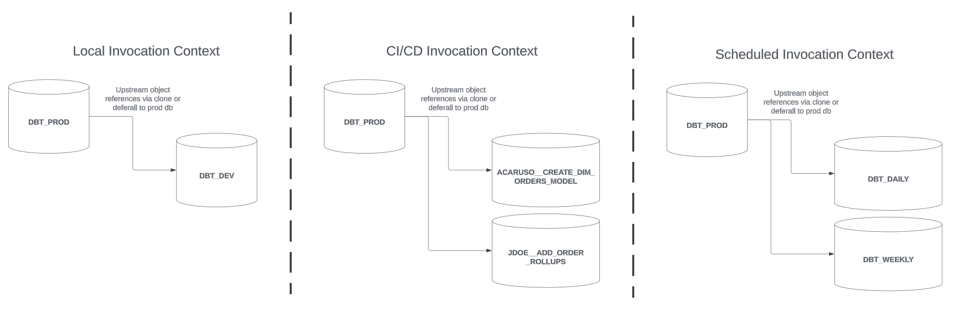
Setup di esempio: persistenza degli artifact dbt
Prima di passare a esempi specifici di criteri di selezione slim e tecniche di build, vediamo un approccio semplice per la persistenza degli artifact dbt, necessaria per alcune tecniche di selezione slim. In particolare, dovremo conservare i file manifest.json e sources.json. Questi file vengono generati automaticamente in target/<artifact>.json all'esecuzione di vari comandi dbt come dbt run, dbt build o dbt source freshness.
In un contesto CI/CD, di solito i job non vengono eseguiti su macchine con storage persistente tra una build e l'altra. Per questo preferisco salvare gli artifact in un object storage esterno remoto, come AWS S3.
(dopo un'invocazione di produzione riuscita di dbt run o dbt build):
cd target
aws s3 cp manifest.json s3://dbt-artifacts/manifest.json
(dopo un'invocazione di produzione riuscita di dbt source freshness):
cd target
aws s3 cp sources.json s3://dbt-artifacts/sources.json
A questo punto puoi scaricare questi file in una directory chiamata .state prima di qualsiasi invocazione dbt che faccia uso di selettori basati sullo stato.
1aws s3 sync s3://dbt-artifacts .state
Con questi file a disposizione, dbt ha tutte le informazioni che servono per determinare quali nodi eseguire in un'invocazione con un dato insieme di selettori di stato.
Slim build locali
Vediamo ora le diverse opzioni a disposizione per eseguire build dbt efficienti in locale.
Flag CLI --defer per riutilizzare oggetti di produzione già costruiti
Anziché ricostruire da zero le dipendenze upstream ogni volta che invochi dbt in locale, puoi "deferire" i riferimenti a un altro database usando il flag CLI --defer. In questo modo eviti di aspettare build lunghe e costose durante lo sviluppo locale. Se gli upstream dei modelli su cui stai lavorando sono già costruiti in un database di produzione e non devi modificarli, tanto vale riutilizzarli in fase di sviluppo.
Supponiamo che il nostro DAG sia questo:
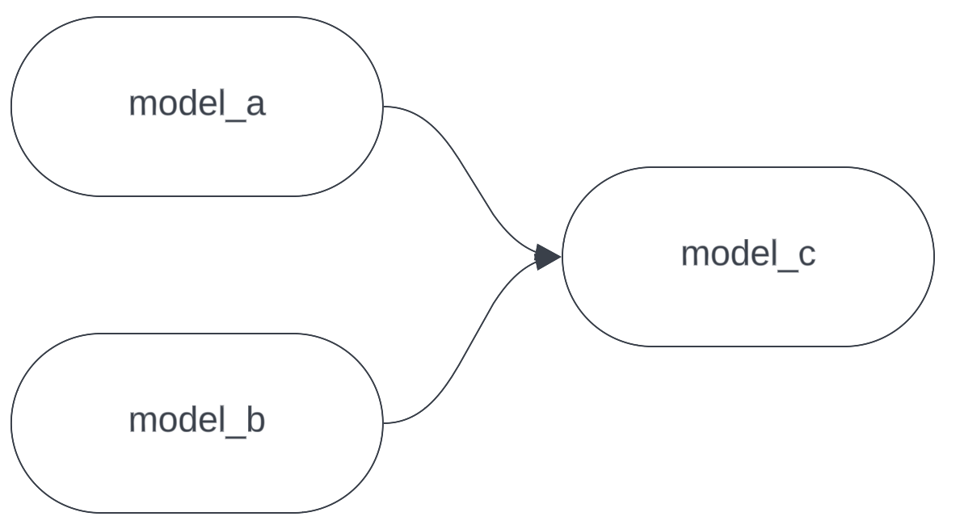
Ora immagina di apportare modifiche a model_c e di eseguire dbt in locale per testarle. Ti servono i dati più recenti di model_a e model_b per verificare le modifiche, ma sono modelli enormi e costosi che richiederebbero ore per essere costruiti su un warehouse di sviluppo. È il caso perfetto per --defer. Invece di eseguire:
1dbt run -s +model_c
prova:
1dbt run -s model_c --defer --state .state
In questo modo i riferimenti a quei modelli verranno "deferiti" al db definito nel tuo file .state/manifest.json, che dovrebbe essere il database di produzione, come abbiamo configurato sopra. Ora l'SQL compilato per model_c potrebbe presentarsi così:
create or replace transient table dbt_dev.acaruso.model_c as
with
a as (select * from dbt_prod.schema.model_a),
b as (select * from dbt_prod.schema.model_b),
final as (select * from a inner join b using (id))
select * from final;
Nota come i riferimenti fully qualified a model_a e model_b usano il database dbt_prod e non dbt_dev, dato che non li abbiamo mai ricostruiti in dev. Attenzione: con --defer conviene sempre lavorare a partire da uno schema vuoto, per essere certi che i riferimenti vengano effettivamente deferiti. Se i ref esistono già nello schema di destinazione, dbt userà quelli anziché applicare il defer.
Gli stessi benefici si possono ottenere con i cloni degli oggetti, come quelli creati dalla funzionalità Zero Copy Clone di Snowflake. I cloni, però, vanno ricreati ogni volta che gli oggetti nel db sorgente vengono aggiornati e non tutti i data warehouse supportano lo zero copy cloning. Per i casi d'uso di sviluppo locale, quindi, --defer è una soluzione più semplice e generale.
Bonus: script wrapper per --defer
Per non dover recuperare ogni volta l'artifact manifest remoto e digitare --defer --state /path/to/your/state, ho scritto un piccolo script wrapper che semplifica il tutto. Ospito il mio sito di documentazione dbt sullo stesso bucket s3 in cui salvo gli artifact dopo le build, quindi è un modo comodo per recuperare gli artifact di prod più recenti prima di eseguire invocazioni dbt con --defer.
dbtdefer.sh
#!/bin/bash -ue
prod_manifest_uri="http://dbt.yourdomain/manifest.json"
target_dir="path/to/your/dbt/project/target/prod_manifest"
mkdir -p $target_dir
target_file="${target_dir}/manifest.json"
# this writes the contents of "$prod_manifest_uri" to "$target_file", if
# "$prod_manifest_uri" has been modified more recently than "$target_file"
curl -o "$target_file" -z "$target_file" "$prod_manifest_uri"
set -x
dbt $@ --defer --state "$target_dir"
chmod +x dbtdefer.sh
echo 'alias dbtdefer="/path/to/your/dbt/project/bin/dbt_defer/dbtdefer.sh"' >> ~/.bashrc
source ~/.bashrc
Ora puoi recuperare il manifest più recente e deferire i riferimenti con un solo comando: dbtdefer run -s <i tuoi selettori>. Funziona anche con dbtdefer build o con qualsiasi altro comando dbt in cui ti serva deferire i riferimenti.
Flag CLI --empty per dry run solo sullo schema
Un altro strumento utile per le slim build locali è il flag CLI --empty. Aggiungendo questa opzione a dbt run, in tutti i source e i ref del modello verrà iniettata un'istruzione limit 0.
Invece di:
with my_expensive_transform as (
select ...
from {{ ref('source', 'my_big_table') }}
)
...
dbt invierà al target:
with my_expensive_transform as (
select ...
from {{ ref('source', 'my_big_table') }}
limit 0
)
...
È una differenza sottile, ma può avere un impatto enorme su query complesse con trasformazioni costose o tabelle di base di grandi dimensioni. dbt eseguirà comunque l'SQL del modello sul data warehouse di destinazione, ma eviterà letture e trasformazioni costose dei dati di input. In questo modo si validano le dipendenze e ci si assicura che i modelli vengano costruiti correttamente, senza costruirli davvero. È utile per validare le modifiche allo schema in sviluppo locale, magari rimandando la build effettiva con i dati di input completi a un altro ambiente con risorse di compute maggiori.
Row Sampling
Un altro modo creativo per limitare la quantità di dati elaborati nei contesti di sviluppo (locale o CI/CD). L'idea è limitare o filtrare in sviluppo i modelli con un numero elevato di righe, così che le trasformazioni su quei piccoli sottoinsiemi di dati siano rapide. Ad esempio:
with my_big_ref as (
select * from {{ ref('my_big_table') }}
limit 500
-- OR
-- where updated_at >= DATEADD(week, -1, CURRENT_DATE)
-- etc
)
... more transforms go here ...
Tecniche di campionamento di questo tipo possono essere racchiuse in un override della macro ref, in modo che il sampling venga applicato automaticamente in base al target dbt.
{% macro ref(model_name) %}
{%- set original_ref = builtins.ref(model_name) -%}
{%- if target.name == 'dev' -%}
(
select *
from {{ original_ref }}
limit 1000
)
{%- else -%}
{{ original_ref }}
{%- endif -%}
{% endmacro %}
Lo stesso si può fare con la macro source. Attenzione: l'override e la modifica del comportamento dei builtin possono causare problemi di incompatibilità con altre macro, ad esempio dbt_utils.star().
Pare che dbt stia lavorando a funzionalità native in questo senso, potenzialmente esposte tramite un flag CLI --sample.
Personalmente, non ho mai trovato questo approccio particolarmente comodo dal punto di vista dell'esperienza di sviluppo. Per risultare utili e affidabili in fase di test, i sample devono tenere conto dell'integrità referenziale e della distribuzione disomogenea dei dati: con un DAG complesso è molto più difficile di quanto sembri. Vale comunque la pena menzionarlo, soprattutto perché dbt potrebbe presto fornirne il supporto nativo.
Conclusione
In questo articolo abbiamo introdotto i concetti fondamentali alla base delle slim build dbt e alcuni esempi pratici per ottenerle in un contesto di invocazione dbt locale. Abbiamo inoltre impostato la persistenza degli artifact dbt e passato in rassegna diversi "contesti di invocazione" dbt in cui si possono applicare le tecniche di slim build. Prosegui con la Parte 2 di questa serie, Best practice per i workflow dbt, Parte 2: slim build CI/CD, dove approfondiremo le strategie slim in CI/CD.
Alex Caruso·Lead Data Platform Engineer di Entera
Alex è Lead Data Platform Engineer di Entera, con base a New York, Stati Uniti.