In Best Practices für dbt-Workflows, Teil 1: Konzepte & Slim Local Builds habe ich das Konzept eines "schlanken" dbt-Builds vorgestellt und Beispiele für die lokale dbt-Entwicklung gezeigt. Außerdem habe ich die verschiedenen "dbt-Invocation-Kontexte" beschrieben (Local, CI/CD und Scheduled).
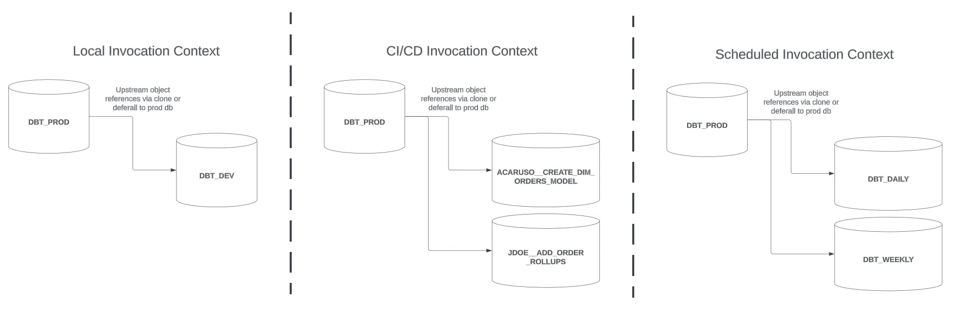
Dieser Beitrag knüpft an Teil 1 an und widmet sich gezielt Strategien für schlanke dbt-Builds im CI/CD-Invocation-Kontext (der mittlere Bereich in der Abbildung oben).
Rückblick auf Teil 1: Local dbt Slim Builds
"Schlanke" dbt-Builds minimieren redundante, überflüssige oder fehlerhafte Modell-Invocations. Wenn wir dbt aufrufen, verfolgen wir in der Regel eines von zwei Zielen:
- Code- bzw. Logikänderungen an dbt-Ressourcen (Modelle, Tests usw.) bauen, testen und validieren
- Invocation-Kontext
LocaloderCI/CD
- Modelle aktualisieren, sobald neue Quelldaten eintreffen
- Invocation-Kontext
Scheduled
In beiden Fällen müssen wir meist nur einen kleineren Ausschnitt des DAG bauen. Für jede dbt-Invocation gibt es eine minimale Menge an Ressourcen, die nötig sind, um das Ziel zu erreichen. Ziel schlanker Builds ist es, dieser minimalen Menge so nahe wie möglich zu kommen, damit keine Rechenzeit und kein Geld für andere Ressourcen verschwendet wird.
Lokale dbt-Builds lassen sich mit dem CLI-Flag --defer, dem CLI-Flag --empty oder über Row-Sampling-Techniken auf die relevanten Ressourcen reduzieren.
Voraussetzungen
- Sie haben Best Practices für dbt-Workflows, Teil 1: Konzepte & Slim Local Builds bis einschließlich
Slim Local Buildsgelesen - Sie haben die Persistenz von dbt-Artefakten eingerichtet, wie in Teil 1 beschrieben
- Sie verfügen über eine funktionierende CI/CD-Pipeline, um dbt gegen eine isolierte Datenbank oder ein isoliertes Schema in Ihrer Zielumgebung auszuführen
Slim CI/CD Builds
state:modified-Selektor
Das mächtigste Werkzeug für schlanke CI/CD-Builds ist der Node-Selektor state:modified. Mit ihm lassen sich nur die Modelle ausführen, die sich gegenüber einem früheren dbt-DAG-Zustand geändert haben — beschrieben durch ein Manifest-Artefakt. In der Regel handelt es sich dabei um das aktuelle Produktions-Manifest.
Angenommen, Ihr Projekt umfasst 1000 Modelle und Sie öffnen einen Pull Request, der nur 2 davon ändert. Um Ihre Änderungen zu testen und zu validieren, wollen Sie vermutlich nur diese 2 Modelle samt ihrer Downstream-Abhängigkeiten bauen — und nicht den gesamten DAG. Das gelingt mit folgendem Befehl:
1dbt run --select state:modified+ --state .state
dbt erkennt dynamisch, welche Ressourcen im aktuellen Changeset gegenüber dem neuesten Produktions-Manifest geändert wurden.
Inzwischen unterstützt dbt auch spezifischere state:modified-Selektoren wie state:modified.body, state:modified.config usw. Details zu diesen Sub-Selektoren finden Sie in der Dokumentation.
--fail-fast CLI-Flag für frühen Abbruch & schnelles Feedback
Das CLI-Flag --fail-fast sorgt dafür, dass dbt-Invocations sofort mit dem Exit Code 1 abbrechen, sobald ein Fehler auftritt. Standardmäßig macht dbt das nicht, sondern führt alle weiteren Ressourcen aus, die vom Fehler nicht betroffen sind — etwa nicht verbundene Subgraphen — bis der Job abgeschlossen ist.
Im CI/CD-Kontext ist das nicht immer wünschenswert: Diese zusätzlichen Ressourcen-Invocations können teuer werden, und Sie erhalten erst später Rückmeldung über den endgültigen Status des Builds.
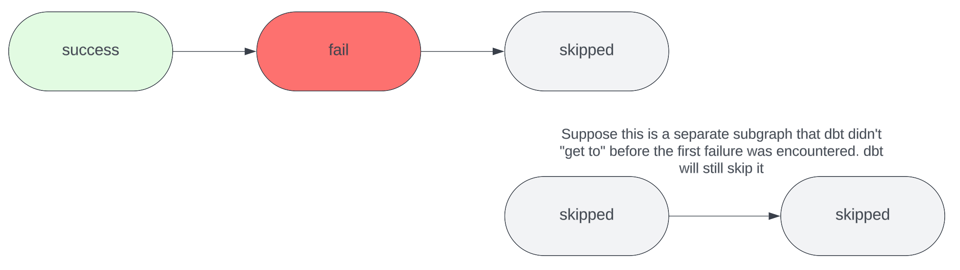
Der einzige Nachteil: Enthält Ihr Projekt weitere Fehler downstream der fehlgeschlagenen Ressource, erfahren Sie davon erst, nachdem Sie den ersten Fehler behoben haben, der den Fail-Fast ausgelöst hat, und eine erneute dbt-Invocation starten. Sie brauchen also mehrere dbt-Invocations, um mehrere Fehler abzuarbeiten. Das ist mühsam, aber immer noch deutlich kosteneffizienter, als jedes Mal alle Ressourcen bauen zu lassen. Ich deaktiviere das --fail-fast-Flag typischerweise, wenn ich ein großes Changeset habe, das mehrere voneinander unabhängige Subgraphen ändert; in solchen Fällen möchte ich alle Fehler "auf einen Schlag" sehen, um sie gemeinsam und ohne mehrere Folge-Invocations beheben zu können.
--defer in CI/CD-Pipelines und Überlegungen zu Blue-Green-Architekturen
In Teil 1 habe ich das CLI-Flag --defer als Option vorgestellt, um lokale dbt-Invocations zu verschlanken.
1dbt run -s my_model --defer --state .state
Grundsätzlich lässt es sich auch im CI/CD-Invocation-Kontext einsetzen, allerdings gibt es einige zusätzliche Punkte zu bedenken — vor allem bei Workflows, die Modelle in Produktivumgebungen deployen.
Mein Team betreibt zwei Arten von dbt-CI/CD-Pipelines:
- "PR"-Builds
- Sie sind an einen einzelnen Pull Request gekoppelt und bauen Ressourcen in einer isolierten Datenbank oder einem isolierten Schema, benannt nach dem Git-Branch, in dem das Changeset gepflegt wird.
- Sie sind eine Art "Lite"-Build, den Entwickler mehrfach ausführen können, bevor sie ihre Änderungen schließlich mergen und über einen separaten "Main-Build" in die Produktion bringen. Die "PR"-Datenbank wird verworfen, sobald die Entwickler ihre Änderungen ausreichend getestet haben.
- "Main"-Builds
- Sie bauen Ressourcen in einer "Staging"-DB (z. B.
DBT_CI_MAIN) und überführen sie per Blue-Green-Swap in die Produktion. - Sie gehen in der Regel aggressiver mit Full Refreshes und Validierungen vor, um eine hohe Datenqualität sicherzustellen, bevor Modelle in der Produktion landen.
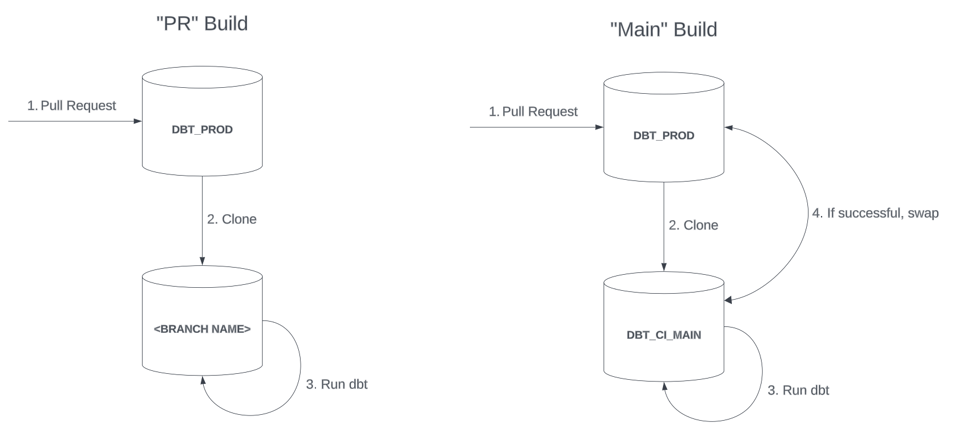
Bei einem Blue-Green-Production-Deployment müssen die neu gebauten Objekte in der Invocation-DB (im obigen Diagramm DBT_CI_MAIN) nach erfolgreichem Abschluss der dbt-Invocation in eine Produktions-DB "promoted" werden. Am einfachsten geht das, indem man die gesamte Datenbank oder das gesamte Schema per swap tauscht. Voraussetzung: Die Invocation-DB wird vor dem Aufruf von dbt aus einem clone erstellt.
Eine Alternative ist, mit einer leeren DB zu starten und Upstream-Objektreferenzen auf die Produktions-DB zu deferren. Startet die Invocation-DB allerdings leer, führt ein vollständiger Datenbank- oder Schema-Swap zu vielen fehlenden Objekten in der Produktion. Das heißt: Objekte auf niedriger Ebene (Tables, Views usw.) müssen einzeln per create or replace ... clone- oder swap-Statement promoted werden.
Machbar — aber in größerem Maßstab durchaus komplex. Daher eignet sich der Ansatz mit vollständigem Datenbank-Clone wohl am besten für Scheduled Builds oder CI/CD-Deployments des main-Branches. --defer passt am besten zu lokalen Invocations und lässt sich für einige, aber nicht alle CI/CD-Invocations nutzen (konkret für "PR"-Builds, bei denen die entstehenden Objekte nicht in die Produktion überführt werden müssen).
Fazit
Dieser Beitrag hat drei Techniken für schlanke Builds in CI/CD-Pipelines vorgestellt — den state:modified-Selektor, das CLI-Flag --fail-fast und das CLI-Flag --defer. Jede dieser Techniken kann die Menge an Modellen reduzieren, die im Rahmen von dbt-CI/CD-Pipelines gebaut werden müssen.
Wir haben außerdem einige mögliche CI/CD-Architekturen betrachtet und die Vor- und Nachteile von --defer gegenüber Objekt-Clones für Upstream-Modellreferenzen in CI/CD-Pipelines abgewogen.
Weiter geht es mit Teil 3 dieser Serie, Best Practices für dbt-Workflows, Teil 3: Slim Scheduled Builds, in dem wir tief in Strategien für schlanke Scheduled Builds einsteigen.
Alex Caruso · Lead Data Platform Engineer bei Entera
Alex ist Lead Data Platform Engineer bei Entera mit Sitz in New York, USA.