Dans Bonnes pratiques pour les workflows dbt, Partie 1 : concepts et builds locaux slim, j'ai introduit la notion de build dbt slim et donné quelques exemples pour le développement dbt en local. J'ai également décrit différents contextes d'invocation dbt (Local, CI/CD et Scheduled).
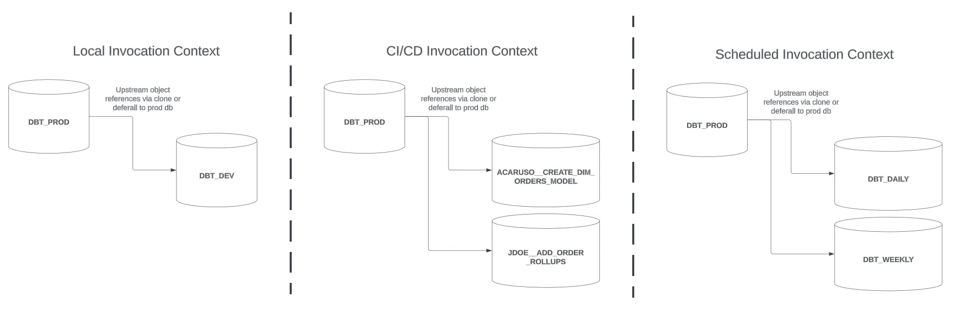
Cet article fait suite à la Partie 1 et se concentre spécifiquement sur les stratégies de builds dbt slim dans un contexte d'invocation CI/CD (la section centrale dans l'image ci-dessus).
Récapitulatif de la Partie 1 : builds dbt locaux slim
Les builds dbt slim réduisent au minimum les invocations de modèles redondantes, inutiles ou erronées. Lorsque l'on invoque dbt, on cherche généralement à atteindre l'un des deux objectifs suivants :
- Construire, tester et valider des modifications de code ou de logique apportées à des ressources dbt (models, tests, etc.)
- Contexte d'invocation
LocalouCI/CD
- Rafraîchir les modèles à mesure que de nouvelles données source arrivent
- Contexte d'invocation
Scheduled
Dans les deux cas, il suffit généralement de construire un sous-ensemble plus restreint du DAG. Pour toute invocation dbt donnée, il existe un ensemble minimal de ressources à construire pour atteindre l'objectif. L'objectif des builds slim est de se rapprocher le plus possible de cet ensemble minimal, afin de ne gaspiller ni temps de calcul ni argent sur d'autres ressources.
Les builds dbt locaux peuvent être allégés pour cibler uniquement les ressources pertinentes via le flag CLI --defer, le flag CLI --empty ou des techniques d'échantillonnage de lignes.
Prérequis
- Vous avez lu jusqu'à la section
Slim Local Buildsdans Bonnes pratiques pour les workflows dbt, Partie 1 : concepts et builds locaux slim - Vous avez mis en place la persistance des artefacts dbt, comme décrit dans la Partie 1
- Vous disposez d'un pipeline CI/CD opérationnel qui invoque dbt sur une base de données ou un schéma isolé dans votre environnement de destination
Builds CI/CD slim
Sélecteur state:modified
L'outil le plus puissant pour des builds CI/CD slim est le sélecteur de nœud state:modified. Ce sélecteur permet de n'exécuter que les modèles modifiés par rapport à un état antérieur du DAG dbt, décrit par un artefact manifest. En général, ce manifest correspond au dernier manifest de production.
Supposons que votre projet contienne 1000 modèles et que vous ouvriez une Pull Request modifiant seulement 2 d'entre eux. Pour tester et valider vos changements, vous voudrez sans doute construire uniquement ces 2 modèles ainsi que leurs dépendances en aval, plutôt que le DAG entier. Cela se fait avec la commande suivante :
1dbt run --select state:modified+ --state .state
dbt déterminera dynamiquement quelles ressources ont été modifiées dans le changeset actuel par rapport au dernier manifest de production.
dbt prend désormais en charge des sélecteurs state:modified plus spécifiques, comme state:modified.body, state:modified.config, etc. Consultez la documentation pour le détail de ces sous-sélecteurs.
Flag CLI --fail-fast pour des sorties anticipées et un feedback rapide
Le flag CLI --fail-fast force les invocations dbt à s'interrompre immédiatement avec un code de sortie 1 dès qu'une erreur survient. Par défaut, dbt ne se comporte pas ainsi : il poursuit l'exécution de toutes les autres ressources non affectées par l'erreur, par exemple les sous-graphes déconnectés, jusqu'à la fin du job.
Ce comportement n'est pas toujours souhaitable en CI/CD, car ces invocations de ressources supplémentaires peuvent coûter cher et retardent le moment où vous obtenez un retour sur l'état final du build.
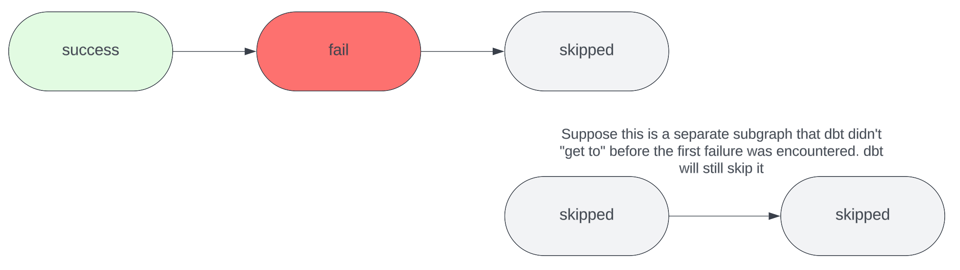
Le seul inconvénient de cette approche : si votre projet contient d'autres erreurs en aval de la ressource défaillante, vous ne les découvrirez qu'après avoir résolu la première erreur ayant déclenché le fail fast, puis relancé une invocation dbt. Il faudra donc enchaîner plusieurs invocations dbt pour résoudre plusieurs erreurs. C'est certes fastidieux, mais cela reste bien plus économique que de laisser toutes les ressources se construire à chaque fois. En général, je désactive le flag --fail-fast lorsque j'ai un changeset volumineux qui modifie plusieurs sous-graphes sans rapport entre eux ; dans ces situations, je préfère découvrir toutes les erreurs d'un seul coup, pour les corriger ensemble sans enchaîner plusieurs invocations.
--defer dans les pipelines CI/CD et considérations pour une architecture blue-green
Dans la Partie 1, j'ai présenté le flag CLI --defer comme une option pour alléger les invocations dbt locales.
1dbt run -s my_model --defer --state .state
Il peut aussi être utilisé dans un contexte d'invocation CI/CD, mais cela implique quelques considérations supplémentaires, en particulier pour les workflows qui déploient des modèles vers des environnements de production.
Mon équipe exécute deux types de pipelines CI/CD dbt :
- Les builds PR
- Ils sont associés à une Pull Request individuelle et construisent les ressources dans une base de données ou un schéma isolé, nommé d'après la branche Git où le changeset est suivi.
- Ils s'apparentent à un build léger que les développeurs peuvent lancer plusieurs fois avant de merger et de promouvoir les modifications en production via un Main build séparé. La base de données PR est supprimée une fois que les développeurs ont fini de tester leurs changements.
- Les builds Main
- Ils construisent les ressources dans une base de données de staging (par ex.
DBT_CI_MAIN) et les promeuvent en production via un mécanisme de type swap blue-green. - Ils sont généralement plus agressifs sur les full refreshes et les validations, afin de garantir une qualité de données élevée avant que les modèles n'atteignent la production.
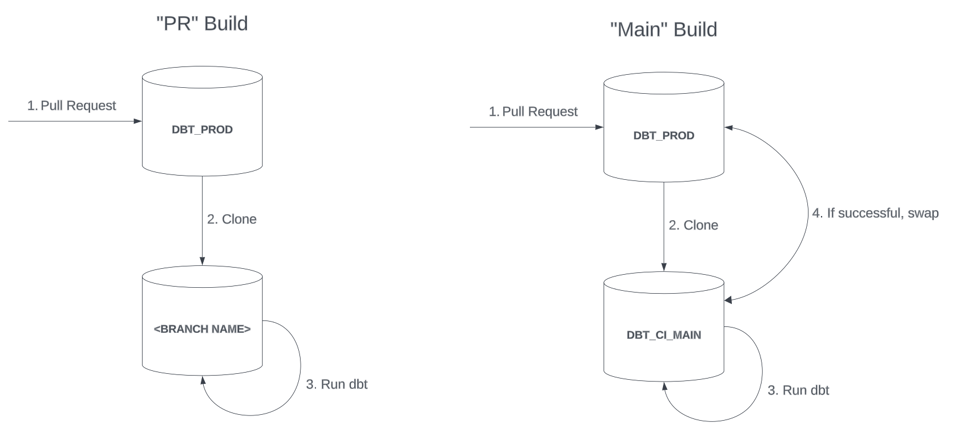
Dans un déploiement de production blue-green, les objets nouvellement construits contenus dans la base d'invocation (DBT_CI_MAIN dans le schéma ci-dessus) doivent être promus vers une base de production, une fois l'invocation dbt terminée avec succès. La manière la plus directe consiste à effectuer un swap de la base de données ou du schéma entier. Cela suppose que la base d'invocation soit créée à partir d'un clone avant l'invocation de dbt.
Une autre option consiste à partir d'une base vide et à différer les références aux objets en amont vers la base de production. Cependant, si la base d'invocation démarre vide, un swap complet de base ou de schéma entraînera de nombreux objets manquants en production. Les objets de bas niveau (tables, vues, etc.) doivent alors être promus individuellement via des instructions create or replace ... clone ou swap.
C'est faisable, mais relativement complexe à mettre en œuvre à grande échelle. Pour cette raison, l'approche par clonage complet de base est sans doute la plus adaptée aux builds planifiés ou aux déploiements CI/CD de la branche main. --defer convient surtout aux invocations locales et peut être utilisé pour certaines invocations CI/CD, mais pas toutes (à savoir les builds PR, où les objets résultants n'ont pas besoin d'être promus en production).
Conclusion
Cet article a passé en revue trois techniques pour des builds slim dans les pipelines CI/CD : le sélecteur state:modified, le flag CLI --fail-fast et le flag CLI --defer. Chacune permet de réduire l'ensemble des modèles à construire dans le cadre des pipelines CI/CD dbt.
Nous avons également examiné quelques architectures CI/CD possibles, ainsi que les avantages et inconvénients de --defer par rapport aux clones d'objets pour les références aux modèles en amont dans les pipelines CI/CD.
Poursuivez avec la Partie 3 de cette série, Bonnes pratiques pour les workflows dbt, Partie 2 : builds planifiés slim, où nous explorerons les stratégies pour des builds planifiés slim.
Alex Caruso·Lead Data Platform Engineer chez Entera
Alex est Lead Data Platform Engineer chez Entera, basé à New York, aux États-Unis.