dbtワークフローのベストプラクティス 第1回:コンセプトとスリムなローカルビルドでは、「スリム」なdbtビルドという考え方を紹介し、ローカルでのdbt開発における具体例をいくつか取り上げました。あわせて、さまざまな「dbtの実行コンテキスト」(ローカル、CI/CD、スケジュール)についても説明しました。
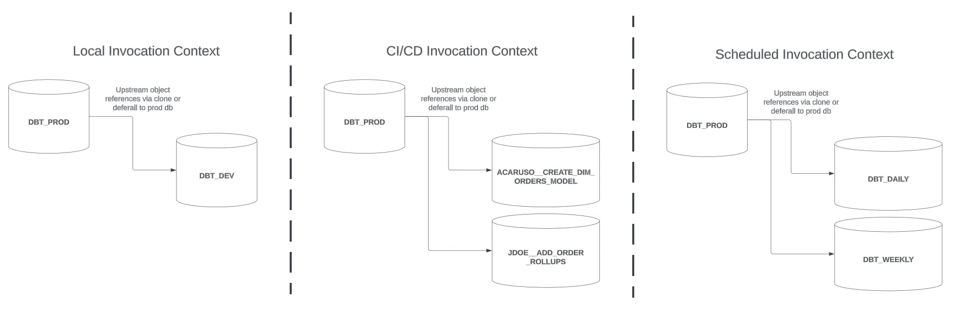
本記事は第1回の続編として、CI/CDの実行コンテキスト(上図の中央部分)におけるスリムなdbtビルドの戦略に焦点を当てて解説します。
第1回の振り返り:ローカルでのdbtスリムビルド
「スリム」なdbtビルドとは、冗長・不要・誤ったモデル実行を最小限に抑えるビルドのことです。dbtを実行する目的は、通常、次の2つのいずれかに集約されます。
- dbtリソース(モデルやテストなど)に対するコードやロジックの変更をビルド・テスト・検証する
ローカルまたはCI/CDの実行コンテキスト
- 新しいソースデータの到着に合わせてモデルを更新する
スケジュールの実行コンテキスト
いずれの場合も、ビルドが必要なのはDAGの一部だけというのが一般的です。どのdbt実行にも、目的を達成するために最低限必要なリソースの集合が存在します。スリムビルドの狙いは、その最小集合にできる限り近づけ、それ以外のリソースに計算時間とコストを費やさないようにすることです。
ローカルでのdbtビルドは、--deferや--emptyなどのCLIフラグ、あるいは行サンプリングの手法を使うことで、必要なリソースだけを対象にした「スリム」な実行に絞り込めます。
前提条件
- dbtワークフローのベストプラクティス 第1回:コンセプトとスリムなローカルビルドの
Slim Local Buildsのセクションまでを読み終えていること - 第1回で説明したdbtアーティファクトの永続化を設定済みであること
- デプロイ先環境の独立したデータベースまたはスキーマに対してdbtを実行できるCI/CDパイプラインが稼働していること
スリムなCI/CDビルド
state:modified セレクタ
スリムなCI/CDビルドにおいて最も強力な武器となるのが、state:modifiedノードセレクタです。このセレクタを使うと、マニフェストアーティファクトで表現された過去のdbt DAG状態と比較して、変更があったモデルだけを実行できます。比較対象となるマニフェストは、通常は最新の本番マニフェストです。
たとえばプロジェクトに1000個のモデルがあり、そのうち2個だけを変更するPull Requestを作成したとします。変更内容をテスト・検証するには、DAG全体ではなく、その2個のモデルと下流の依存関係だけをビルドできれば十分でしょう。これは次のコマンドで実現できます。
1dbt run --select state:modified+ --state .state
dbtは、最新の本番マニフェストと比較して、現在の変更セットでどのリソースが変更されたかを動的に判定します。
さらに現在のdbtでは、state:modified.bodyやstate:modified.configなど、より細かいstate:modifiedセレクタもサポートされています。これらのサブセレクタの詳細は公式ドキュメントをご確認ください。
--fail-fast CLIフラグによる早期終了と素早いフィードバック
--fail-fast CLIフラグを指定すると、エラーが発生した時点でdbtの実行が即座に終了コード1で停止します。デフォルトでは、dbtはこの挙動を取りません。代わりに、エラーの影響を受けないリソース(接続されていないサブグラフなど)の実行をジョブが完了するまで継続します。
CI/CDの文脈では、この挙動が常に望ましいとは限りません。余計なリソース実行はコスト増につながりますし、ビルドの最終ステータスに関するフィードバックを得るまでに時間もかかるためです。
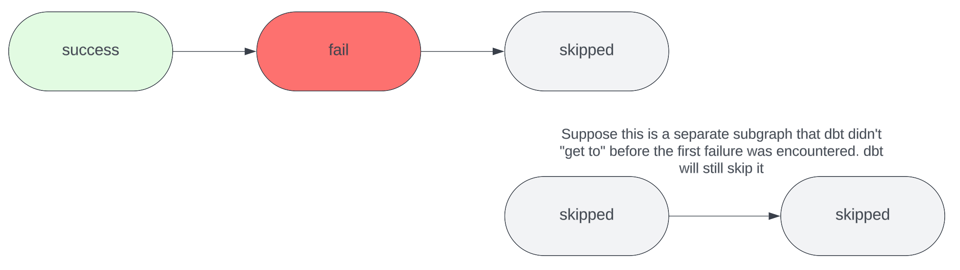
このアプローチの唯一の難点は、失敗したリソースの下流に別のエラーが潜んでいる場合、fail-fastを引き起こした最初のエラーを解消して再実行するまで、それらのエラーに気づけないことです。つまり、複数のエラーを解決するには、dbtの実行を何度か繰り返す必要があります。手間はかかりますが、それでも毎回すべてのリソースをビルドさせるよりは、はるかにコスト効率が高いことが多いです。私自身は、無関係な複数のサブグラフにまたがる大規模な変更セットを扱う場合には--fail-fastフラグを無効にしています。こうした場面では、すべてのエラーを「一度に」洗い出し、何度も実行を繰り返さずにまとめて解決したいからです。
CI/CDパイプラインでの--deferとブルーグリーン構成における考慮点
第1回では、ローカルでのdbt実行をスリム化する手段として--defer CLIフラグを紹介しました。
1dbt run -s my_model --defer --state .state
このフラグはCI/CDの実行コンテキストでも利用可能ですが、特に本番環境へモデルをデプロイするワークフローでは、いくつか追加で考慮すべき点があります。
私たちのチームでは、2種類のdbt CI/CDパイプラインを運用しています。
- 「PR」ビルド
- 個々のPull Requestに紐づき、変更セットを管理するGitブランチ名にちなんだ独立したデータベースまたはスキーマにリソースをビルドします。
- 開発者がマージし、別途「Mainビルド」を介して本番に反映するまでの間に、何度でも実行できる「軽量」なビルドという位置づけです。「PR」用のデータベースは、開発者がテストを終えた時点で破棄されます。
- 「Main」ビルド
- 「ステージング」DB(例:
DBT_CI_MAIN)にリソースをビルドし、ブルーグリーン方式のスワップで本番へ昇格させます。 - モデルが本番に到達する前に高いデータ品質を担保するため、フルリフレッシュや検証をより積極的に行うのが一般的です。
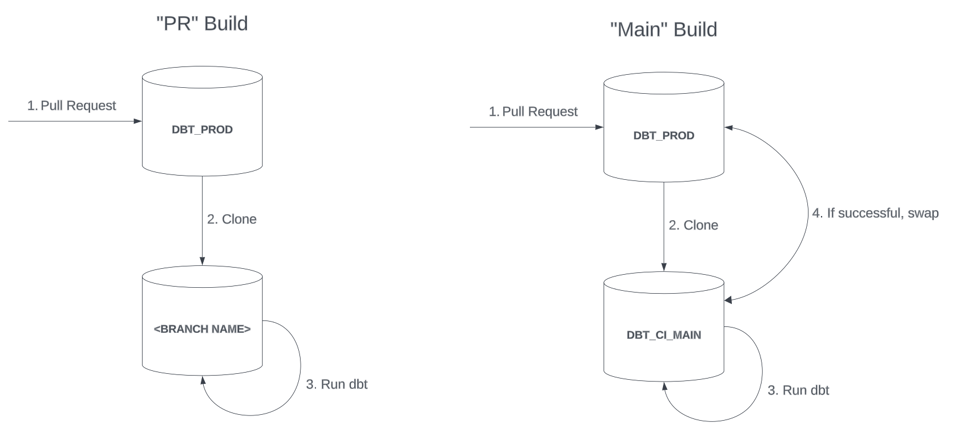
ブルーグリーン方式の本番デプロイでは、dbtの実行が成功した後に、実行用DB(上図のDBT_CI_MAIN)内に作成された新しいオブジェクトを本番DBへ「昇格」させる必要があります。最もシンプルなやり方は、データベースまたはスキーマ全体をswapすることです。ただし、これはdbtを実行する前に、実行用DBをcloneから作成していることが前提となります。
もう1つの方法は、空のDBから始めて、上流のオブジェクト参照を本番DBに対してdeferする手法です。ただし、実行用DBを空の状態から始めた場合、データベースまたはスキーマ全体をスワップすると、本番側で多数のオブジェクトが欠落してしまいます。そのため、テーブルやビューといった低レベルのオブジェクトは、create or replace ... cloneやswapステートメントで個別に昇格させる必要があります。
実現自体は可能ですが、大規模に運用しようとするとそれなりに複雑です。こうした理由から、データベース全体をクローンするアプローチは、スケジュールビルドやmainブランチのCI/CDデプロイに最も適していると言えるでしょう。--deferはローカル実行に最も適しており、CI/CD実行のうち一部(具体的には、結果オブジェクトを本番へ昇格させる必要のない「PR」ビルド)にも使えますが、すべてのCI/CD実行に向いているわけではありません。
まとめ
本記事では、CI/CDパイプラインでスリムなビルドを実現する3つの手法――state:modifiedセレクタ、--fail-fast CLIフラグ、--defer CLIフラグ――を紹介しました。いずれの手法も、dbt CI/CDパイプラインの一環としてビルドが必要なモデルの範囲を絞り込むのに役立ちます。
あわせて、想定されるCI/CD構成のパターンや、CI/CDパイプラインで上流モデルを参照する際の--deferとオブジェクトクローンの利点・欠点についても見てきました。
本シリーズ第3回dbtワークフローのベストプラクティス 第2回:スリムなスケジュールビルドでは、スリムなスケジュールビルドの戦略について掘り下げます。
Alex Caruso・Lead Data Platform Engineer at Entera
Alexは米国ニューヨークを拠点に、EnteraでLead Data Platform Engineerを務めています。