Em Boas práticas para workflows dbt, Parte 1: conceitos e builds slim locais, apresentei o conceito de build "slim" no dbt e mostrei alguns exemplos de desenvolvimento local com dbt. Também descrevi os diferentes "contextos de invocação do dbt" (Local, CI/CD e Agendado).
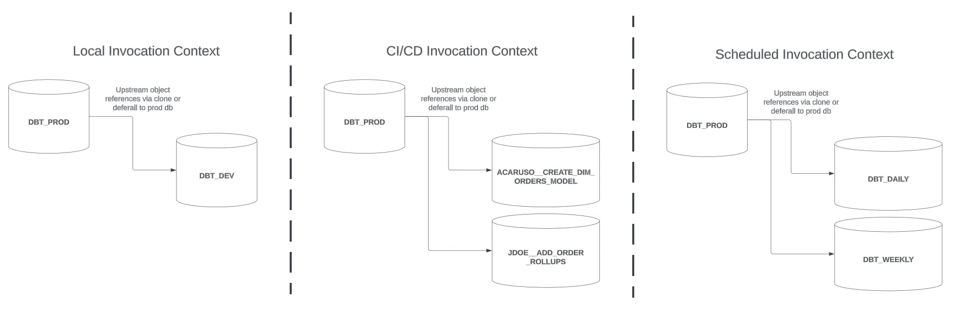
Este post dá continuidade à Parte 1 e foca especificamente nas estratégias para builds slim do dbt em um contexto de invocação CI/CD (a seção central da imagem acima).
Recapitulando a Parte 1: builds slim locais do dbt
Builds "slim" do dbt minimizam invocações de modelos redundantes, desnecessárias ou equivocadas. Quando invocamos o dbt, geralmente queremos atingir um destes dois objetivos:
- Construir, testar e validar mudanças de código/lógica em recursos do dbt (modelos, testes etc.)
- Contexto de invocação
LocalouCI/CD
- Atualizar modelos conforme novos dados de origem chegam
- Contexto de invocação
Agendado
Nos dois casos, geralmente basta construir um subconjunto menor do DAG. Para qualquer invocação do dbt, existe um conjunto mínimo de recursos que precisam ser construídos para atingir o objetivo. A meta dos builds slim é chegar o mais perto possível desse conjunto mínimo, para não desperdiçar tempo de computação nem dinheiro com outros recursos.
Builds locais do dbt podem ser "enxugados" para mirar apenas nos recursos relevantes usando a flag --defer da CLI, a flag --empty da CLI ou técnicas de amostragem de linhas.
Pré-requisitos
- Você leu até a seção
Slim Local Buildsem Boas práticas para workflows dbt, Parte 1: conceitos e builds slim locais - Você configurou a persistência de artefatos do dbt, conforme descrito na Parte 1
- Você tem um pipeline de CI/CD funcional para invocar o dbt em um banco de dados ou schema isolado no seu ambiente de destino
Builds slim em CI/CD
Seletor state:modified
A ferramenta mais poderosa para builds slim em CI/CD é o seletor de nós state:modified. Esse seletor permite executar apenas os modelos que foram modificados em relação a algum estado anterior do DAG do dbt, descrito por um artefato manifest. Normalmente, esse manifest é o manifest de produção mais recente.
Imagine que seu projeto tenha 1.000 modelos e você abra um Pull Request que altera apenas 2 deles. Para testar e validar suas mudanças, faz sentido construir só esses 2 modelos e suas dependências downstream, em vez do DAG inteiro. Isso pode ser feito com o seguinte comando:
1dbt run --select state:modified+ --state .state
O dbt consegue determinar dinamicamente quais recursos foram modificados no changeset atual em relação ao manifest de produção mais recente.
O dbt agora suporta seletores state:modified mais específicos, como state:modified.body, state:modified.config etc. Veja a documentação para informações detalhadas sobre esses sub-seletores.
Flag --fail-fast da CLI para saídas antecipadas e feedback rápido
A flag --fail-fast da CLI faz com que as invocações do dbt encerrem imediatamente com exit code 1 assim que qualquer erro é encontrado. Por padrão, o dbt não faz isso: ele continua executando todos os outros recursos que não foram afetados pelo erro, como subgrafos desconectados, até concluir o job.
Em um contexto de CI/CD, esse comportamento nem sempre é desejável, porque essas invocações extras de recursos podem sair caras e ainda fazem você esperar mais tempo pelo feedback sobre o status final do build.
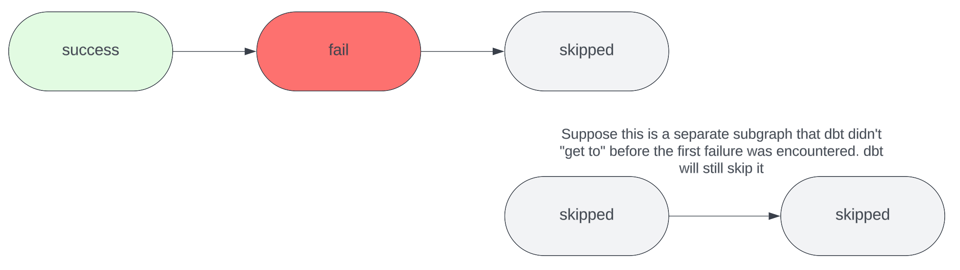
A única desvantagem dessa abordagem é que, se o seu projeto tiver outros erros downstream do recurso que falhou, você só vai descobri-los depois de resolver o primeiro erro que disparou o fail fast e rodar outra invocação do dbt. Ou seja, você vai precisar de várias invocações do dbt para resolver múltiplos erros. Por mais tedioso que isso seja, ainda pode ser bem mais econômico do que deixar todos os recursos serem construídos toda vez. Costumo desativar a flag --fail-fast quando tenho um changeset grande que mexe em vários subgrafos não relacionados; nessas situações, prefiro ver todos os erros "de uma vez" para resolvê-los juntos, sem precisar de várias invocações subsequentes.
--defer em pipelines de CI/CD e considerações para arquitetura blue-green
Na Parte 1, apresentei a flag --defer da CLI como uma opção para enxugar invocações locais do dbt.
1dbt run -s my_model --defer --state .state
Ela também pode ser usada em um contexto de invocação CI/CD, mas há algumas considerações adicionais, especialmente para workflows que implantam modelos em ambientes de produção.
Minha equipe roda dois tipos de pipelines CI/CD do dbt:
- Builds de "PR"
- Estão associados a um Pull Request individual e constroem recursos em um banco de dados ou schema isolado, nomeado de acordo com a branch Git onde o changeset é rastreado.
- Funcionam como um build "lite" que os desenvolvedores podem rodar várias vezes antes de fazer o merge e promover as mudanças para produção por meio de um "Main build" separado. O banco de dados de "PR" é descartado quando os desenvolvedores terminam de testar suas alterações.
- Builds de "Main"
- Constroem recursos em um banco de "staging" (por exemplo,
DBT_CI_MAIN) e os promovem para produção em um estilo de troca blue-green. - Costumam ser mais agressivos em full refreshes e validações, para garantir alta qualidade dos dados antes que os modelos cheguem à produção.
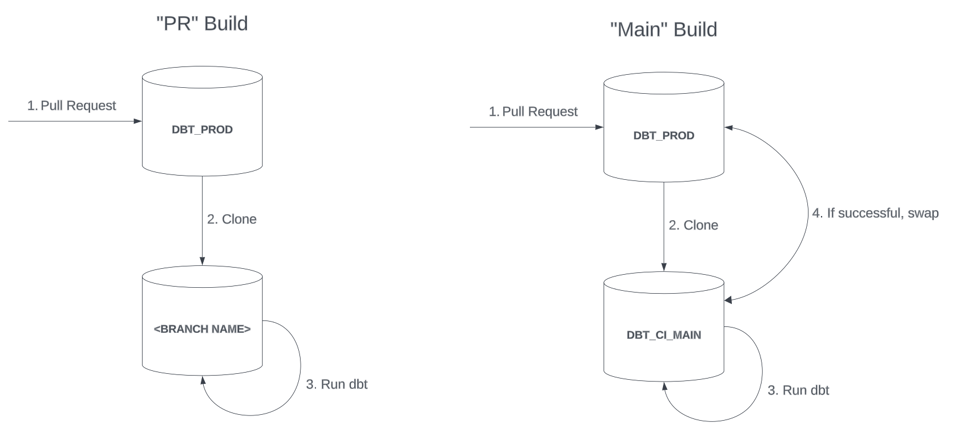
Em uma implantação de produção blue-green, os objetos recém-criados no banco de invocação (DBT_CI_MAIN, no diagrama acima) precisam ser "promovidos" para um banco de produção depois que a invocação do dbt for concluída com sucesso. A forma mais direta de fazer isso é dar um swap no banco de dados ou schema inteiro. Isso pressupõe que o banco de invocação seja criado a partir de um clone antes da invocação do dbt.
Outra opção é partir de um banco vazio e fazer defer das referências de objetos upstream para o banco de produção. Porém, se o banco de invocação começa vazio, um swap completo do banco ou schema vai resultar em muitos objetos faltando em produção. Isso significa que os objetos de baixo nível (tabelas, views etc.) precisam ser promovidos individualmente por meio de instruções create or replace ... clone ou swap.
Isso é viável, mas também é bastante complexo de implementar em escala. Por isso, a abordagem de clonagem completa do banco de dados costuma ser mais adequada para builds agendados ou implantações de CI/CD da branch main. Já o --defer é mais indicado para invocações locais e pode ser usado em algumas (mas não todas) invocações de CI/CD — especificamente, builds de "PR", em que os objetos resultantes não precisam ser promovidos para produção.
Encerrando
Este post mostrou três técnicas para builds slim em pipelines de CI/CD: o seletor state:modified, a flag --fail-fast da CLI e a flag --defer da CLI. Cada uma delas pode reduzir o conjunto de modelos que precisam ser construídos nos pipelines de CI/CD do dbt.
Também analisamos algumas arquiteturas possíveis de CI/CD, além dos prós e contras de usar --defer versus clones de objetos para referências de modelos upstream em pipelines de CI/CD.
Siga para a Parte 3 desta série, Boas práticas para workflows dbt, Parte 2: builds slim agendados, em que vamos mergulhar nas estratégias para builds slim agendados.
Alex Caruso·Lead Data Platform Engineer na Entera
Alex é Lead Data Platform Engineer na Entera, baseado em Nova York, Estados Unidos.