In Best practice per i workflow dbt, Parte 1: concetti e build locali slim ho introdotto il concetto di build dbt "slim" e ho fornito alcuni esempi per lo sviluppo dbt in locale. Ho inoltre descritto i diversi "contesti di invocazione di dbt" (Local, CI/CD e Scheduled).
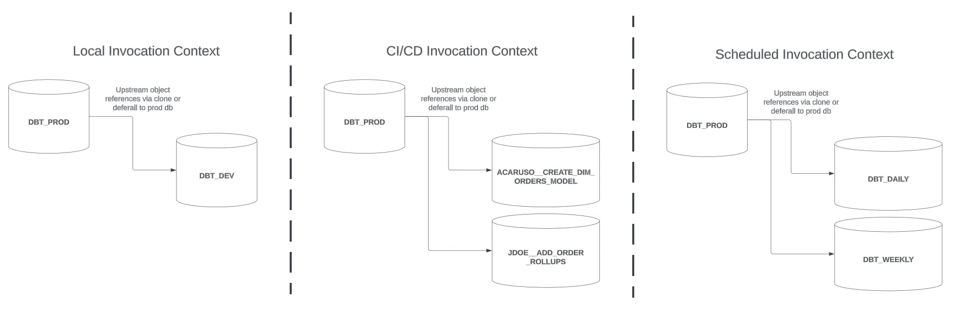
Questo articolo è il seguito della Parte 1 e si concentra nello specifico sulle strategie per build dbt slim in un contesto di invocazione CI/CD (la sezione centrale dell'immagine qui sopra).
Riepilogo della Parte 1: build dbt locali slim
Le build dbt "slim" riducono al minimo le invocazioni di modelli ridondanti, superflue o errate. Quando invochiamo dbt, di solito puntiamo a uno di questi due obiettivi:
- Costruire, testare e validare modifiche al codice o alla logica delle risorse dbt (modelli, test, ecc.)
- Contesto di invocazione
LocaloCI/CD
- Aggiornare i modelli man mano che arrivano nuovi dati sorgente
- Contesto di invocazione
Scheduled
In entrambi i casi, di norma basta costruire un sottoinsieme ridotto del DAG. Per ogni invocazione di dbt esiste un insieme minimo di risorse da costruire per raggiungere l'obiettivo. Lo scopo delle build slim è avvicinarsi il più possibile a questo insieme minimo, per non sprecare tempo di calcolo e denaro su altre risorse.
Le build dbt locali possono essere "snellite" per puntare solo alle risorse rilevanti tramite il flag CLI --defer, il flag CLI --empty oppure tecniche di campionamento delle righe.
Prerequisiti
- Aver letto fino alla sezione
Slim Local Buildsdi Best practice per i workflow dbt, Parte 1: concetti e build locali slim - Aver configurato la persistenza degli artefatti dbt, come descritto nella Parte 1
- Disporre di una pipeline CI/CD funzionante per invocare dbt su un database o schema isolato nell'ambiente di destinazione
Build CI/CD slim
Selettore state:modified
Lo strumento più potente per ottenere build CI/CD slim è il selettore di nodi state:modified. Questo selettore consente di eseguire solo i modelli modificati rispetto a uno stato precedente del DAG dbt, descritto da un manifest artifact. In genere si tratta dell'ultimo manifest di produzione.
Supponiamo che il progetto contenga 1000 modelli e che venga aperta una Pull Request che ne modifica solo 2. Per testare e validare le modifiche, potrebbe essere utile costruire soltanto questi 2 modelli e le relative dipendenze a valle, anziché l'intero DAG. È possibile farlo con il seguente comando:
1dbt run --select state:modified+ --state .state
dbt è in grado di determinare dinamicamente quali risorse sono state modificate nel changeset corrente, rispetto all'ultimo manifest di produzione.
dbt supporta ora selettori state:modified più specifici, come state:modified.body, state:modified.config, ecc. Per i dettagli su questi sotto-selettori si rimanda alla documentazione.
Flag CLI --fail-fast per uscite anticipate e feedback rapido
Il flag CLI --fail-fast obbliga le invocazioni di dbt a terminare immediatamente con exit code pari a 1 al primo errore incontrato. Per impostazione predefinita, dbt non si comporta così: continua a eseguire tutte le altre risorse non interessate dall'errore, ad esempio i sottografi non connessi, fino al completamento del job.
Questo non è sempre auspicabile in un contesto CI/CD, poiché queste invocazioni aggiuntive di risorse possono essere onerose e il tempo necessario per ricevere un riscontro sullo stato finale della build si allunga.
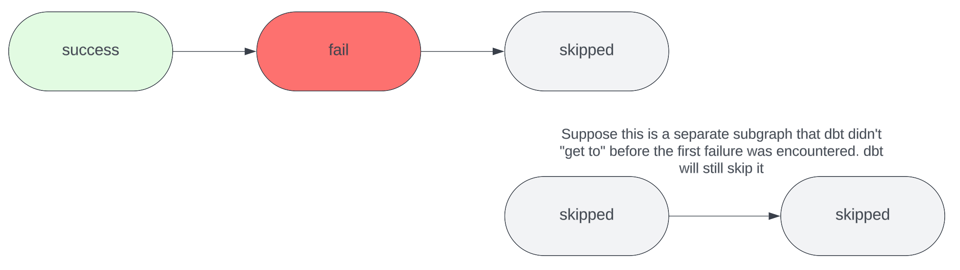
L'unico svantaggio di questo approccio è che, se il progetto presenta altri errori a valle della risorsa fallita, non se ne avrà notizia finché non si risolve il primo errore che ha innescato il fail fast e non si esegue una nuova invocazione di dbt. Servono quindi invocazioni dbt ripetute per risolvere più errori. Sebbene il processo sia macchinoso, può comunque essere molto più efficiente sul piano dei costi rispetto al lasciar costruire tutte le risorse ogni volta. Di norma disabilito il flag --fail-fast quando ho un changeset di grandi dimensioni che modifica più sottografi non correlati: in questi casi voglio scoprire tutti gli errori "in un colpo solo" e risolverli insieme, senza dover eseguire più invocazioni successive.
--defer nelle pipeline CI/CD e considerazioni per architetture blue-green
Nella Parte 1 ho presentato il flag CLI --defer come opzione per snellire le invocazioni dbt in locale.
1dbt run -s my_model --defer --state .state
Questo flag può essere usato anche in un contesto di invocazione CI/CD, ma ci sono alcune considerazioni aggiuntive, in particolare per i workflow che distribuiscono modelli in ambienti di produzione.
Il mio team gestisce due tipi di pipeline CI/CD dbt:
- Build "PR"
- Sono associate a una singola Pull Request e costruiscono le risorse in un database o schema isolato, con lo stesso nome del branch Git in cui è tracciato il changeset.
- Sono una sorta di build "lite" che gli sviluppatori possono eseguire più volte prima del merge definitivo e della promozione delle modifiche in produzione tramite una "Main build" separata. Il database "PR" viene eliminato quando gli sviluppatori hanno finito di testare le proprie modifiche.
- Build "Main"
- Costruiscono le risorse in un db di "staging" (ad es.
DBT_CI_MAIN) e le promuovono in produzione con uno swap in stile blue-green. - Sono in genere più aggressive nei full refresh e nelle validazioni, così da garantire un'elevata qualità dei dati prima che i modelli arrivino in produzione.
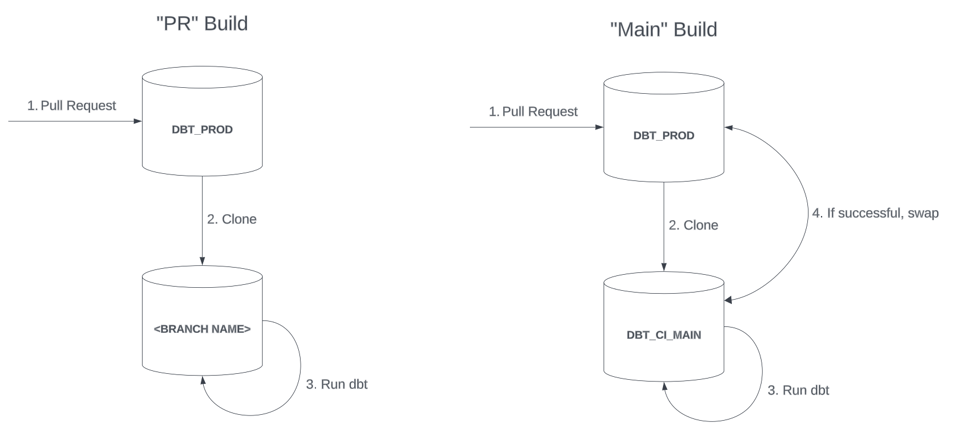
In un deployment di produzione blue-green, gli oggetti appena costruiti nel db di invocazione (DBT_CI_MAIN nel diagramma sopra) devono essere "promossi" a un db di produzione dopo il completamento corretto dell'invocazione dbt. Il modo più immediato per farlo è eseguire uno swap dell'intero database o schema. Si presuppone che il db di invocazione venga creato a partire da un clone prima dell'invocazione di dbt.
Un'altra opzione è partire da un db vuoto e differire i riferimenti agli oggetti a monte verso il db di produzione. Tuttavia, se il db di invocazione parte vuoto, uno swap completo di database o schema produrrà molti oggetti mancanti in produzione. Significa che gli oggetti di basso livello (tabelle, view, ecc.) dovranno essere promossi singolarmente tramite istruzioni create or replace ... clone o swap.
Pur essendo fattibile, su larga scala è piuttosto complesso da implementare. Per questo motivo, l'approccio del cloning completo del database è probabilmente il più adatto alle build pianificate o ai deployment CI/CD del branch main. --defer è invece più adatto alle invocazioni in locale e può essere usato per alcune invocazioni CI/CD, ma non per tutte (nello specifico le build "PR", in cui gli oggetti risultanti non devono essere promossi in produzione).
Conclusioni
Questo articolo ha passato in rassegna tre tecniche per le build slim nelle pipeline CI/CD: il selettore state:modified, il flag CLI --fail-fast e il flag CLI --defer. Ognuna di queste tecniche permette di ridurre l'insieme di modelli da costruire all'interno delle pipeline CI/CD di dbt.
Abbiamo anche esaminato alcune possibili architetture CI/CD e i pro e i contro dell'uso di --defer rispetto ai clone degli oggetti per i riferimenti ai modelli a monte nelle pipeline CI/CD.
Proseguite con la Parte 3 della serie, Best practice per i workflow dbt, Parte 3: build Scheduled slim, in cui approfondiremo le strategie per le build Scheduled slim.
Alex Caruso·Lead Data Platform Engineer presso Entera
Alex è Lead Data Platform Engineer presso Entera, con sede a New York, Stati Uniti.