En Buenas prácticas para workflows de dbt, Parte 1: Conceptos y Slim Local Builds, presenté el concepto de un build "slim" en dbt y compartí algunos ejemplos para el desarrollo local con dbt. También describí los distintos "contextos de invocación de dbt" (Local, CI/CD y Scheduled).
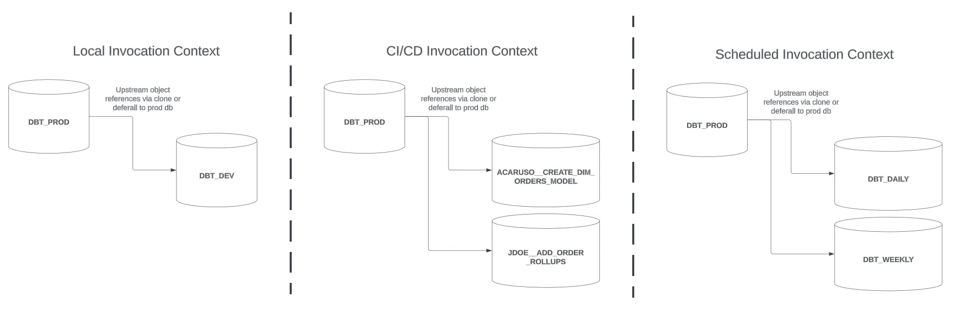
Este post es la continuación de la Parte 1, donde veremos puntualmente las estrategias para lograr slim builds de dbt en un contexto de invocación CI/CD (la sección central de la imagen anterior).
Resumen de la Parte 1: Slim Builds locales de dbt
Los builds "slim" de dbt reducen al mínimo las invocaciones de modelos redundantes, innecesarias o erróneas. Cuando invocamos dbt, por lo general buscamos una de estas dos cosas:
- Construir, probar y validar cambios de código o de lógica en recursos de dbt (modelos, tests, etc.)
- Contexto de invocación
LocaloCI/CD
- Refrescar modelos a medida que llegan nuevos datos de origen
- Contexto de invocación
Scheduled
En ambos casos, normalmente basta con construir un subconjunto reducido del DAG. Para cualquier invocación de dbt existe un conjunto mínimo de recursos que se deben construir para alcanzar el objetivo. La meta de los slim builds es acercarse lo más posible a ese conjunto mínimo, para no malgastar tiempo de cómputo ni dinero en otros recursos.
Los builds locales de dbt se pueden "adelgazar" para apuntar únicamente a los recursos relevantes mediante el flag CLI --defer, el flag CLI --empty, o técnicas de muestreo de filas.
Requisitos previos
- Ya leíste hasta la sección
Slim Local Buildsen Buenas prácticas para workflows de dbt, Parte 1: Conceptos y Slim Local Builds - Ya configuraste la persistencia de artefactos de dbt, como se describe en la Parte 1
- Cuentas con un pipeline de CI/CD funcional para invocar dbt sobre una base de datos o un schema aislado en tu entorno de destino
Slim Builds en CI/CD
Selector state:modified
La herramienta más potente para los slim builds en CI/CD es el selector de nodos state:modified. Este selector permite ejecutar solo los modelos que se modificaron respecto a un estado previo del DAG de dbt, descrito por un manifest artifact. Normalmente, ese manifest será el último de producción.
Supongamos que tu proyecto tiene 1000 modelos y abres un Pull Request que modifica solo 2 de ellos. Para probar y validar tus cambios, lo más probable es que quieras construir únicamente esos 2 modelos y sus dependencias downstream, en vez de todo el DAG. Esto se logra con el siguiente comando:
1dbt run --select state:modified+ --state .state
dbt podrá determinar de forma dinámica qué recursos se modificaron en el changeset actual, en relación al último manifest de producción.
dbt ahora admite selectores state:modified más específicos, como state:modified.body, state:modified.config, etc. Revisa la documentación para información detallada sobre estos sub-selectores.
Flag CLI --fail-fast para salidas tempranas y feedback rápido
El flag CLI --fail-fast obliga a las invocaciones de dbt a terminar de inmediato con un exit code 1 apenas se detecta cualquier error. Por defecto, dbt no se comporta así: sigue ejecutando todos los demás recursos no afectados por el error, como por ejemplo subgrafos no conectados, hasta completar el job.
Esto no siempre es deseable en un contexto de CI/CD, porque esas invocaciones adicionales de recursos pueden salir caras, y además vas a tardar más en recibir feedback sobre el estado final del build.
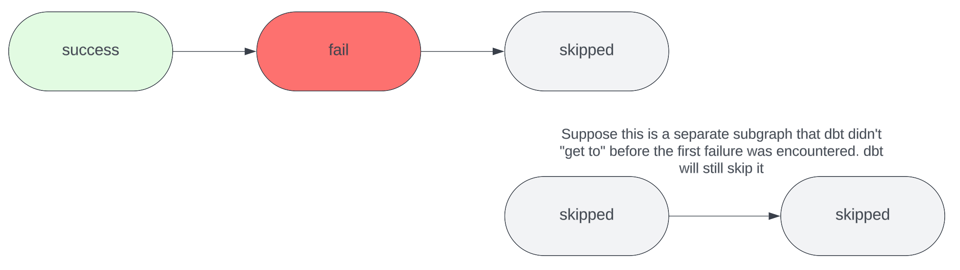
La única desventaja de este enfoque es que, si tu proyecto tiene otros errores downstream del recurso que falló, no vas a enterarte de ellos hasta que resuelvas el primer error que disparó el fail fast y vuelvas a invocar dbt. Es decir, vas a necesitar varias invocaciones sucesivas de dbt para resolver varios errores. Aunque es tedioso, sigue siendo mucho más eficiente en costo que dejar que todos los recursos se construyan cada vez. Por lo general, desactivo el flag --fail-fast cuando tengo un changeset grande que modifica varios subgrafos no relacionados; en esas situaciones, prefiero enterarme de todos los errores "de una sola vez", para resolverlos en conjunto sin tener que correr varias invocaciones después.
--defer en pipelines de CI/CD y consideraciones para arquitectura Blue-Green
En la Parte 1 presenté el flag CLI --defer como una opción para adelgazar las invocaciones locales de dbt.
1dbt run -s my_model --defer --state .state
También se puede usar en un contexto de invocación CI/CD, pero hay algunas consideraciones adicionales, sobre todo en workflows que despliegan modelos a entornos de producción.
Mi equipo corre dos tipos de pipelines de CI/CD de dbt:
- Builds de "PR"
- Están asociados a un Pull Request individual y construyen recursos en una base de datos o schema aislado, nombrado según la rama de Git donde se rastrea el changeset.
- Funcionan como un build "lite" que los desarrolladores pueden correr varias veces antes de finalmente hacer merge y promover los cambios a producción mediante un "Main build" aparte. La base de datos del "PR" se descarta cuando los desarrolladores terminan de probar sus cambios.
- Builds de "Main"
- Construyen recursos en una db de "staging" (por ejemplo
DBT_CI_MAIN) y los promueven a producción al estilo blue-green swap. - Suelen ser más agresivos con full refreshes y validaciones, para garantizar una alta calidad de los datos antes de que los modelos lleguen a producción.
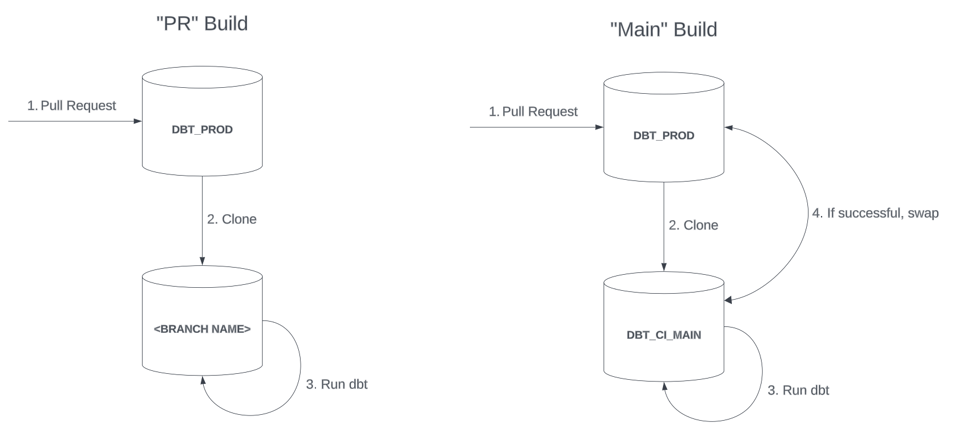
En un despliegue blue-green a producción, los objetos recién construidos contenidos en la db de invocación (DBT_CI_MAIN en el diagrama anterior) deben "promoverse" a una db de producción una vez que la invocación de dbt termina con éxito. La forma más directa de hacerlo es ejecutar un swap de la base de datos o del schema completo. Esto asume que la db de invocación se crea a partir de un clone antes de invocar dbt.
Otra opción es partir de una db vacía y diferir las referencias a objetos upstream hacia la db de producción. Sin embargo, si la db de invocación arranca vacía, un swap completo de base de datos o schema va a dejar muchos objetos faltantes en producción. Es decir, los objetos de bajo nivel (tablas, vistas, etc.) tendrían que promoverse uno por uno con sentencias create or replace ... clone o swap.
Aunque es factible, también resulta algo complejo de implementar a escala. Por eso, el enfoque de clonar la base de datos completa probablemente sea más adecuado para builds programados o despliegues CI/CD de la rama main. --defer es más adecuado para invocaciones locales, y puede usarse para algunas, pero no todas, las invocaciones de CI/CD (en concreto, los builds de "PR", donde los objetos resultantes no necesitan promoverse a producción).
Cierre
En este post repasamos tres técnicas para slim builds en pipelines de CI/CD: el selector state:modified, el flag CLI --fail-fast y el flag CLI --defer. Cada una de ellas permite reducir el conjunto de modelos que se deben construir como parte de los pipelines de CI/CD de dbt.
También vimos algunas arquitecturas posibles de CI/CD, y los pros y contras de usar --defer frente a clones de objetos para las referencias a modelos upstream en pipelines de CI/CD.
Continúa con la Parte 3 de esta serie, Buenas prácticas para workflows de dbt, Parte 2: Slim Scheduled Builds, donde nos adentraremos en las estrategias para slim Scheduled builds.
Alex Caruso·Lead Data Platform Engineer en Entera
Alex es Lead Data Platform Engineer en Entera, con base en Nueva York, Estados Unidos.