In Best Practices für dbt-Workflows, Teil 1: Konzepte & Slim Local Builds habe ich das Konzept des "Slim"-dbt-Builds eingeführt und einige Beispiele für die lokale dbt-Entwicklung gezeigt. Außerdem habe ich die verschiedenen "dbt Invocation Contexts" (Local, CI/CD und Scheduled) beschrieben.
In Best Practices für dbt-Workflows, Teil 2: Slim CI/CD Builds habe ich Techniken vorgestellt, mit denen sich Slim Builds in CI/CD-Pipelines umsetzen lassen.
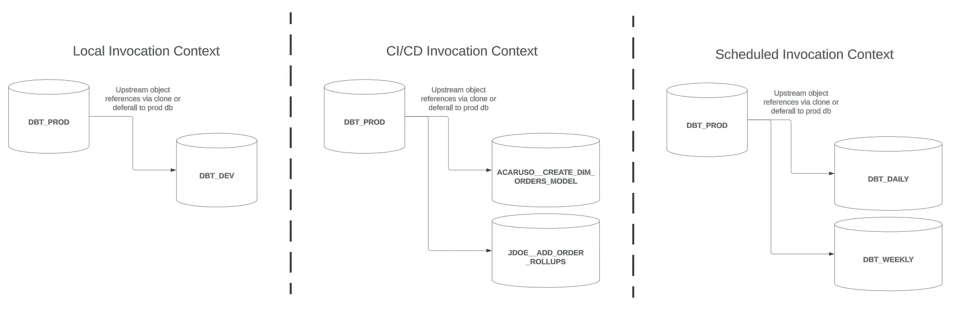
In diesem Beitrag widmen wir uns dem letzten Invocation Context auf der rechten Seite – Scheduled – und gehen einige Strategien für Slim Builds durch. Zum Abschluss bespreche ich weitere Aspekte, die für dbt-Builds in allen drei Invocation Contexts relevant sind.
[@portabletext/react] Unknown block type "cta", specify a component for it in the `components.types` prop
Rückblick Teil 1: Slim Builds in der lokalen dbt-Entwicklung
"Slim"-dbt-Builds minimieren redundante, unnötige oder fehlerhafte Modellaufrufe. Wenn wir dbt aufrufen, verfolgen wir in der Regel eines von zwei Zielen:
- Build, Test und Validierung von Code- bzw. Logikänderungen an dbt-Ressourcen (Models, Tests usw.)
- Invocation Context
LocaloderCI/CD - Aktualisierung von Models, sobald neue Quelldaten eintreffen
- Invocation Context
Scheduled
In beiden Fällen müssen wir meist nur einen kleineren Teil des DAG bauen. Für jeden dbt-Aufruf existiert eine minimale Menge an Ressourcen, die nötig ist, um das Ziel zu erreichen. Ziel von Slim Builds ist es, dieser minimalen Menge möglichst nahezukommen, damit keine Rechenzeit und kein Geld für überflüssige Ressourcen verschwendet werden.
Lokale dbt-Builds lassen sich auf relevante Ressourcen eingrenzen – mit dem CLI-Flag --defer, dem CLI-Flag --empty oder mit Row-Sampling-Techniken.
Rückblick Teil 2: Slim CI/CD
Slim CI/CD-Builds lassen sich mit dem Selector state:modified+ oder dem CLI-Flag --fail-fast umsetzen. --defer kann in manchen, aber nicht in allen CI/CD-Kontexten ebenfalls eingesetzt werden.
Voraussetzungen
- Sie haben den Abschnitt bis einschließlich
Slim Local Buildsin Best Practices für dbt-Workflows, Teil 1: Konzepte & Slim Local Builds gelesen. - Sie haben die Persistierung von dbt-Artefakten wie in Teil 1 beschrieben eingerichtet.
- Sie verfügen über eine funktionierende Orchestrierungs-Pipeline, die geplante dbt-Builds gegen eine isolierte Datenbank oder ein isoliertes Schema in Ihrer Zielumgebung ausführt.
Slim Scheduled Builds
Im Scheduled Invocation Context gibt es keine Code-Änderungen, sondern ausschließlich Aktualisierungen der Quelldaten. Welche Models bei einem Aufruf gebaut werden, hängt damit allein von der Aktualisierungsfrequenz der Quelldaten und den SLAs der nachgelagerten Models ab.
source_status:fresher+ Selector
dbt kann die "Freshness" Ihrer Quelltabellen über den Befehl dbt source freshness erfassen. Die "Freshness" einer Tabelle beschreibt, wann sie zuletzt aktualisiert wurde – üblicherweise anhand einer Zeitstempelspalte – und ergibt sich aus der Differenz zwischen dem Maximalwert dieser Spalte und einer SLA-Schwelle, etwa täglich, wöchentlich usw.
Wenn Sources wie in der oben verlinkten Dokumentation konfiguriert sind (mit den Properties freshness und loaded_at_field), erzeugt der Befehl dbt source freshness ein sources.json-Artefakt, das den Wert max_loaded_at für jede Source-Tabelle speichert. In Kombination mit dem Selector source_status:fresher+ lassen sich so nur jene Sources auswählen, die seit der letzten Erzeugung dieses Artefakts aktualisiert wurden.
Das ist nützlich, um Scheduled Builds zu "verschlanken" und Models, die von Sources ohne Aktualisierungen seit dem letzten dbt-Aufruf abhängen, zu überspringen. Angenommen, Sie haben eine große Datenquelle, die nur einmal wöchentlich aktualisiert wird, führen aber jede Nacht einen geplanten dbt-Build aus. Models, die von dieser Source abhängen, sollten an 6 von 7 Tagen übersprungen werden – es sei denn, sie hängen zusätzlich von einer oder mehreren Sources ab, die häufiger als wöchentlich aktualisiert werden.
Beispiel
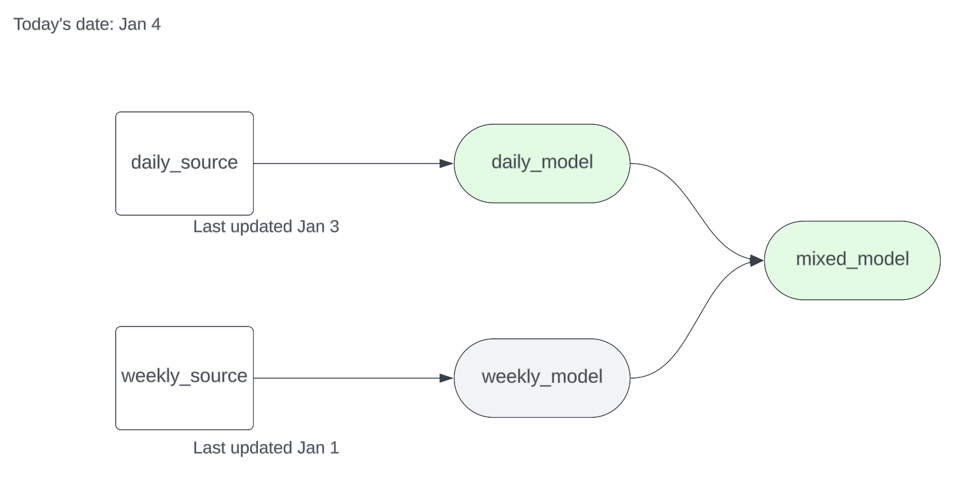
Angenommen, Sie haben zwei Sources – eine wird täglich, die andere wöchentlich aktualisiert – sowie einige nachgelagerte Models. Nach dem Ausführen von dbt source freshness sieht Ihr source.json-Artefakt so aus:
1[\
\
2 {\
\
3 "unique_id": "source.projectname.sourcename.daily_source",\
\
4 "max_loaded_at": "2025-01-03T12:00:00.000000+00:00",\
\
5 ...\
\
6 },\
\
7 {\
\
8 "unique_id": "source.projectname.sourcename.weekly_source",\
\
9 "max_loaded_at": "2025-01-01T00:00:00.000000+00:00",\
\
10 ...\
\
11 }\
\
12]
Die daily_source wurde zuletzt am 3. Januar um 12:00 Uhr aktualisiert, die weekly_source am 1. Januar um Mitternacht. Führen wir am 4. Januar dbt run -s source_status:fresher+ --state .state gegen den unten gezeigten Subgraphen aus, sollte das Model nachgelagert zur wöchentlichen Source übersprungen werden.
Zu beachten
- Wann sollte
dbt source freshnessausgeführt werden?- Dieser Befehl sollte vor jedem neuen geplanten dbt-Aufruf laufen. Das erzeugte
sources.json-Artefakt sollte persistiert werden, damit nachfolgende Scheduled Builds es lokal verfügbar machen und für den Selectorsource_status:fresher+nutzen können.
- Dieser Befehl sollte vor jedem neuen geplanten dbt-Aufruf laufen. Das erzeugte
- Stellen Sie sicher, dass für alle Sources
freshnessundloaded_at_fieldkonfiguriert sind.- Andernfalls ignoriert dbt diese Sources beim Befehl
dbt source freshnessund erzeugt keinemax_loaded_at-Zeitstempel imsources.json-Artefakt. Der Selectorsource_status:fresher+ignoriert diese Sources dann komplett. - Es ist etwas mühsam, sicherzustellen, dass alle Sources diese Konfiguration tragen – mein Team setzt das über ein Macro durch, das alle Sources prüft und das Vorhandensein dieser Attribute erzwingt.
- Andernfalls ignoriert dbt diese Sources beim Befehl
Model Tagging
Eine weitere Möglichkeit für Slim Scheduled Builds ist das Tagging von Models. Statt bei jedem geplanten Build alle Models laufen zu lassen, können wir gezielt nur Models oder Subgraphen ausführen, die einem bestimmten Tag zugeordnet sind. Im Scheduled Context bewährt es sich, Tags nach Refresh-SLAs zu benennen – etwa daily, weekly oder monthly.
Angenommen, wir haben Models, die Reports mit einer wöchentlichen Refresh-SLA bedienen. Sie müssen montagmorgens zu Geschäftsbeginn aktuell sein. Auch wenn die Refresh-SLA wöchentlich ist, werden die zugrunde liegenden Quelldaten täglich aktualisiert.
Den Selector source_status:fresher+ können wir hier nicht nutzen, um diese Models zu überspringen, da ihre Sources häufiger aktualisiert werden, als es die SLA der nachgelagerten Models erfordert.
Beispiel
Betrachten wir den folgenden dbt-Build-Befehl:
1dbt build -s tag:weekly+
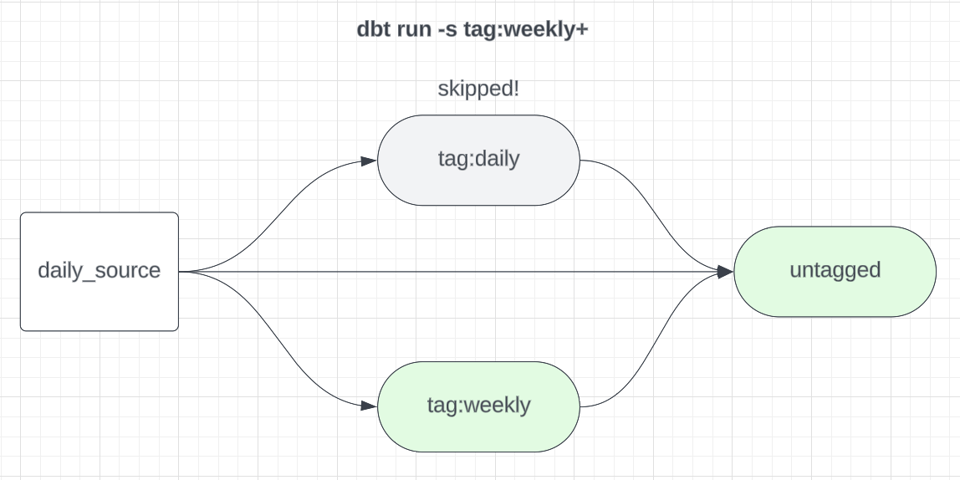
Damit werden alle mit weekly getaggten Models samt nachgelagerter Children ausgeführt. Die Downstreams müssen ebenfalls laufen, damit beispielsweise Models, die sowohl auf weekly- als auch auf daily-Daten basieren, aktualisiert werden. Wenn wir wöchentliche Models als eigenen Subgraphen ausführen, sollten wir sie zudem aus den täglichen Builds ausschließen, damit sie nicht unnötig erneut gebaut werden.
1dbt build -s tag:daily+ --exclude tag:weekly
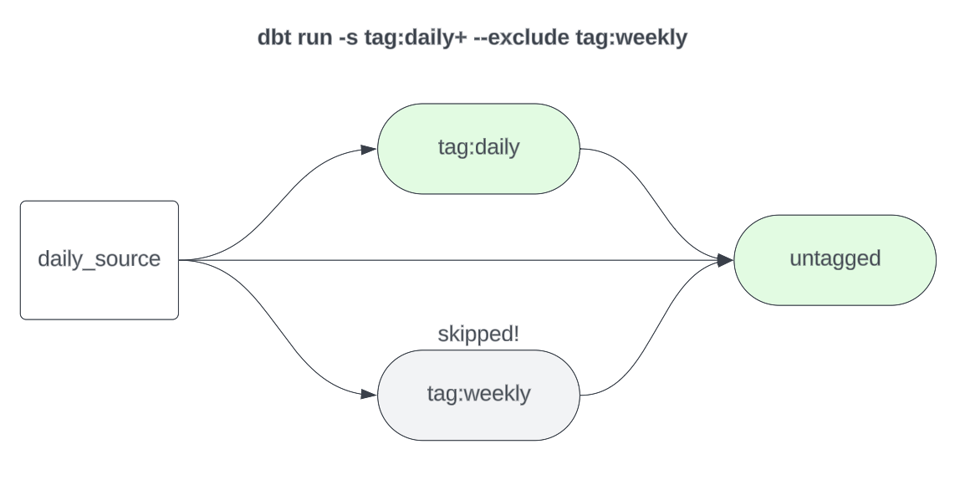
Hinweis: Sie müssen nicht zwingend jedes Model in Ihrem Projekt mit einer Refresh-Frequenz taggen. Sie können Ihre "Baseline"-Models, die typischerweise am häufigsten laufen (etwa täglich), ungetaggt lassen und ohne Tag-Selector bauen. Im obigen Beispiel habe ich der Klarheit halber tag:daily verwendet – ist dieser Selector aber gesetzt, ist --exclude tag:weekly eigentlich überflüssig. Ist hingegen "daily" Ihre typische Baseline-Build-Frequenz und sind Ihre "daily"-Models ungetaggt, müssen die wöchentlichen Models explizit ausgeschlossen werden.
Zu beachten
- Sie fragen sich vielleicht: "Warum nehme ich dafür nicht einfach eine inkrementelle Materialisierung?" Das ist ein möglicher Ansatz, aber nicht so universell wie Tags. Manche Models nutzen
table-Materialisierungen und sind zu komplex, um sie ohne Weiteres inkrementell zu fahren. Andere enthalten nicht-deterministische Logik, die eine Inkrementalisierung unmöglich macht. - Vermischen Sie nicht die Refresh-Frequenz der Sources mit den Refresh-SLAs der Models.
- Nur weil eine Source nur wöchentlich aktualisiert wird, müssen deren nachgelagerte Models nicht ebenfalls nur wöchentlich laufen. Sauberer ist es, sie täglich auszuführen – mit dem Selector
source_status:fresher+oder einer inkrementellen Materialisierung. So ist garantiert, dass sie beim ersten dbt-Aufruf nach einem Source-Refresh aktualisiert werden. Andernfalls droht ein mehrtägiger Verzug zwischen der Aktualisierung einer wöchentlichen Source und dem Build der zugehörigen wöchentlichen Models – das ist nicht ideal.
- Nur weil eine Source nur wöchentlich aktualisiert wird, müssen deren nachgelagerte Models nicht ebenfalls nur wöchentlich laufen. Sauberer ist es, sie täglich auszuführen – mit dem Selector
- Überlappende Model-Selectors und redundante Model-Rebuilds
- In den Diagrammen oben fällt vielleicht auf, dass das nachgelagerte
untagged-Model bei beiden dbt-Aufrufen ausgewählt und gebaut wird. Das ist redundant! - Keine Sorge: Trotz dieser Redundanz ist das immer noch ein deutlicher Fortschritt gegenüber dem täglichen Bauen aller mit
weeklygetaggten Models. Der Trade-off: Wir müssen das nachgelagerteuntagged-Model einmal pro Woche redundant neu bauen (einmal im Daily-Build, dann nochmals im Weekly-Build). Diese Kosten-Nutzen-Abwägung hängt natürlich von den relativen Kosten des untagged Models gegenüber dem Weekly Model ab. - Mit ausgefeilteren Selector-Mustern und DAG-Architekturen lässt sich das noch weiter optimieren – darauf gehe ich hier aber nicht ein.
- In den Diagrammen oben fällt vielleicht auf, dass das nachgelagerte
Fazit: Alles zusammengeführt
Mehrere der in dieser Serie besprochenen CLI-Flags und State-basierten Selectors lassen sich kombinieren, um im CI/CD- oder Scheduled-Invocation-Context besonders schlanke Builds zu erzielen.
CI/CD-Context
"Baue alle geänderten Models und ihre nachgelagerten Children und deferiere vorgelagerte Referenzen auf die Produktions-DB DBT_PROD. Brich beim ersten Fehler sofort ab."
1dbt build --fail-fast --defer --select state:modified+ --state .state
Scheduled-Context
"Baue alle nachgelagerten Models von Sources mit Datensatzaktualisierungen seit dem vorherigen Build, sofern diese Models mit daily getaggt sind. Deferiere vorgelagerte Referenzen auf die Produktions-DB DBT_PROD und brich beim ersten Fehler sofort ab."
1dbt build --fail-fast --defer --select source_status:fresher+,tag:daily
Weitere Überlegungen
Object Clones vs. deferred References über --defer
Sowohl in Teil 1 als auch in Teil 2 dieser Serie habe ich darauf hingewiesen, dass sich einige Vorteile des CLI-Flags --defer auch mit Zero-Copy-Clones erreichen lassen. Statt von einer leeren Invocation-Datenbank auszugehen und vorgelagerte Referenzen auf eine Produktionsdatenbank zu deferieren, können diese Objekte vor dem dbt-Aufruf in die Invocation-DB geklont und ganz normal referenziert werden.
Diese Strategie bietet besseren Schutz vor Race Conditions, weil der "kritische" Zeitraum, in dem die Produktionsobjekte als Snapshot (Clone) festgehalten werden, deutlich kürzer ist als bei Referenzen via --defer. Beim Deferring auf eine andere DB besteht das Risiko, dass sich Objekte in der Deferral-DB mitten in Ihrem Build durch ein Out-of-Band-Deployment ändern. Clones sind daher häufig die bessere Wahl für "kritische" dbt-Aufrufe – etwa für CI/CD-Builds auf dem main-Branch (Merge / Deploy).
Die Cloning-Strategie hat aber auch Nachteile: Clones müssen jedes Mal neu erstellt werden, wenn sich die Quellobjekte ändern, und es gibt Komplikationen mit RBAC in Snowflake.
Materialisierungsstrategien
Die Materialisierungsstrategie ist eine weitere zentrale Komponente von Slim Builds. Das ist ein Thema für sich, daher gehe ich hier nicht ins Detail. Teams sollten sich aber bewusst sein, dass übermäßige Full-Refresh-Builds – gerade in CI/CD-Contexts – eine wesentliche Quelle redundanter Model-Builds und unnötiger Kosten sind. Der Einsatz des Flags --full-refresh sowie die Entscheidung zwischen incremental- und table-Materialisierungen sollten in jedem Invocation Context sorgfältig abgewogen werden.
Zusammenfassung
Es gibt scheinbar endlose Strategien, um dbt-Models aufzurufen und auszurollen. Diese Flexibilität ist ein Gewinn, legt aber zugleich die Verantwortung in die Hände der Entwickler, dafür zu sorgen, dass Models nicht über Gebühr gebaut und neu gebaut werden. Besonders wichtig ist das, weil Data-Warehouse-Lösungen wie Snowflake es einem leicht machen, bei den Compute-Kosten über das Ziel hinauszuschießen. Die in diesem Beitrag vorgestellten Techniken helfen Ihnen hoffentlich dabei, Ihre dbt-Aufrufe künftig besser zu steuern und Ihre Builds dauerhaft schlank zu halten.
Alex Caruso · Lead Data Platform Engineer bei Entera
Alex ist Lead Data Platform Engineer bei Entera und lebt in New York, USA.