En Buenas prácticas para workflows de dbt, Parte 1: conceptos y builds locales slim presenté el concepto de un build "slim" de dbt y mostré algunos ejemplos para desarrollo local con dbt. También describí los distintos "contextos de invocación de dbt" (Local, CI/CD y Programado).
En Buenas prácticas para workflows de dbt, Parte 2: builds slim en CI/CD describí algunas técnicas para conseguir builds slim en pipelines de CI/CD.
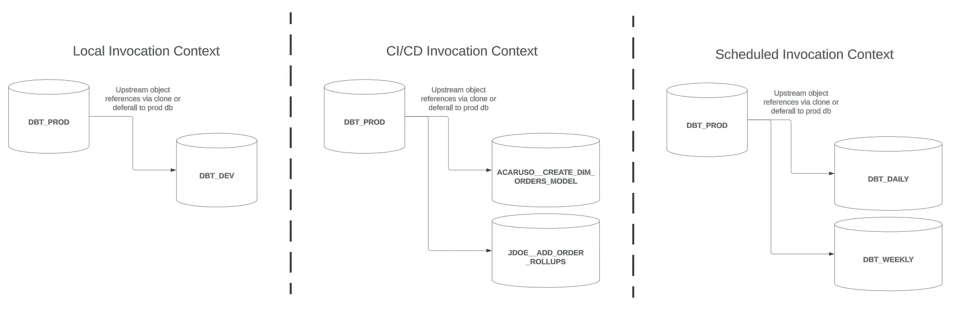
En este post veremos el último contexto de invocación que queda a la derecha: Programado, y recorreremos algunas estrategias para builds slim. Cerraré con algunas consideraciones adicionales sobre builds de dbt que aplican a los tres contextos de invocación.
[@portabletext/react] Unknown block type "cta", specify a component for it in the `components.types` prop
Repaso de la Parte 1: builds locales slim de dbt
Los builds "slim" de dbt minimizan las invocaciones de modelos redundantes, innecesarias o erróneas. Cuando invocamos dbt, lo habitual es buscar uno de estos dos objetivos:
- Construir, probar y validar cambios de código o lógica en recursos de dbt (modelos, tests, etc.)
- Contexto de invocación
LocaloCI/CD - Refrescar modelos a medida que llegan nuevos datos de origen
- Contexto de invocación
Programado
En ambos casos, normalmente solo hace falta construir un subconjunto pequeño del DAG. Para cualquier invocación de dbt existe un conjunto mínimo de recursos que se deben construir para alcanzar el objetivo. La meta de los builds slim es acercarse lo más posible a ese conjunto mínimo, para no malgastar tiempo de cómputo ni dinero en otros recursos.
Los builds locales de dbt se pueden "adelgazar" para apuntar únicamente a los recursos relevantes usando la flag de CLI --defer, la flag --empty o técnicas de muestreo de filas.
Repaso de la Parte 2: CI/CD slim
Los builds slim en CI/CD se logran con el selector state:modified+ o con la flag de CLI --fail-fast. --defer también se puede usar en algunos contextos de CI/CD, aunque no en todos.
Prerrequisitos
- Leíste hasta
Slim Local Buildsen Buenas prácticas para workflows de dbt, Parte 1: conceptos y builds locales slim - Configuraste la persistencia de artefactos de dbt, tal como se describe en la Parte 1
- Tienes un pipeline de orquestación funcional para invocar builds programados de dbt contra una base de datos o un esquema aislado en tu entorno de destino
Builds programados slim
En un contexto de invocación programado de dbt no hay cambios de código, solo refrescos de datos de origen. Esto significa que las decisiones sobre qué modelos construir en cada invocación dependen únicamente de la frecuencia con la que se refrescan los datos de origen y de los SLAs de exposición de los modelos downstream.
Selector source_status:fresher+
dbt puede capturar la "frescura" de tus tablas de datos de origen mediante el comando dbt source freshness. La "frescura" de una tabla indica cuándo se actualizó por última vez, normalmente a partir de una columna de timestamp, y la diferencia entre el valor máximo de esa columna y algún umbral de SLA (diario, semanal, etc.).
Si las sources están configuradas como se indica en los docs enlazados arriba (con las propiedades freshness y loaded_at_field), el comando dbt source freshness generará un artefacto sources.json que almacena el valor max_loaded_at de cada tabla source. Ese artefacto se puede combinar con el selector source_status:fresher+ para seleccionar únicamente las sources que se hayan actualizado desde la última vez que se generó.
Esto resulta útil para "adelgazar" los builds programados e ignorar modelos downstream de sources que no han tenido cambios desde la última invocación de dbt. Por ejemplo, supón que tienes una fuente de datos grande que solo se actualiza una vez por semana, pero además ejecutas un build programado de dbt cada noche. Los modelos downstream de esa source deberían saltarse 6 de cada 7 días, salvo que también dependan de otras sources que se refresquen con más frecuencia que la semanal.
Ejemplo
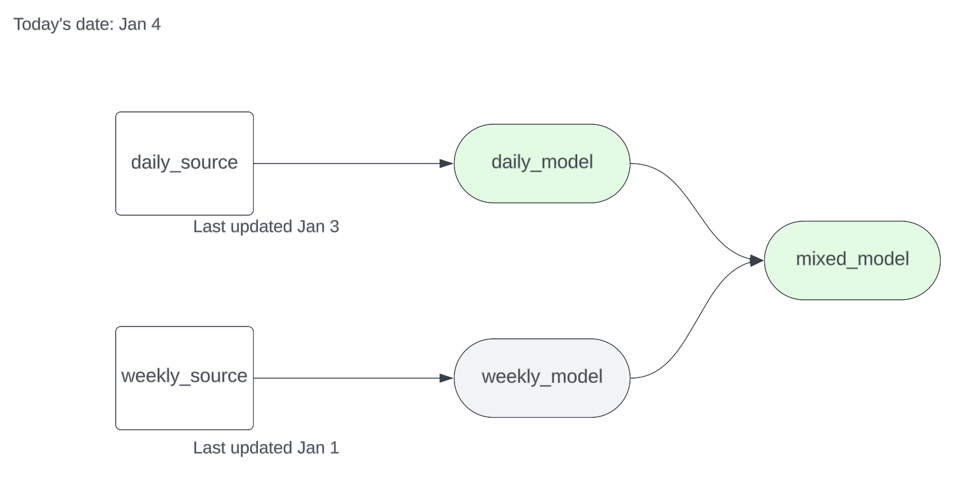
Supón que tienes dos sources, una que se actualiza a diario y otra de forma semanal, y algunos modelos downstream. Después de ejecutar dbt source freshness, tu artefacto source.json se ve así:
1[\
\
2 {\
\
3 "unique_id": "source.projectname.sourcename.daily_source",\
\
4 "max_loaded_at": "2025-01-03T12:00:00.000000+00:00",\
\
5 ...\
\
6 },\
\
7 {\
\
8 "unique_id": "source.projectname.sourcename.weekly_source",\
\
9 "max_loaded_at": "2025-01-01T00:00:00.000000+00:00",\
\
10 ...\
\
11 }\
\
12]
La daily_source se actualizó por última vez el 3 de enero al mediodía, y la weekly_source el 1 de enero a medianoche. Si el 4 de enero ejecutamos dbt run -s source_status:fresher+ --state .state sobre el siguiente subgrafo, el modelo downstream de la source semanal debería saltarse.
Consideraciones
- ¿Cuándo conviene ejecutar
dbt source freshness?- Este comando debe ejecutarse antes de cada nueva invocación programada de dbt. El artefacto
sources.jsonresultante debe persistirse para que las invocaciones posteriores puedan descargarlo a disco y utilizarlo con el selectorsource_status:fresher+.
- Este comando debe ejecutarse antes de cada nueva invocación programada de dbt. El artefacto
- Asegúrate de que todas las sources tengan configurados
freshnessyloaded_at_field- Si no los tienen, dbt las ignorará durante el comando
dbt source freshnessy no generará el metadato de timestampmax_loaded_aten el artefactosources.json. Como resultado, esas sources serán completamente ignoradas por el selectorsource_status:fresher+. - Garantizar que todas las sources tengan esta configuración es algo tedioso; mi equipo lo refuerza con una macro que inspecciona todas las sources y verifica que esos atributos estén definidos.
- Si no los tienen, dbt las ignorará durante el comando
Tagging de modelos
Otra forma de conseguir builds programados slim es mediante el tagging de modelos. En vez de ejecutar todos los modelos en cada build programado, podemos ejecutar solo los modelos o subgrafos asociados a un tag. Una forma práctica de hacerlo en un contexto de invocación programado es usar tags nombrados según el SLA de refresco, como daily, weekly o monthly.
Por ejemplo, supongamos que tenemos algunos modelos que alimentan reportes con un SLA de refresco semanal. Tienen que estar al día al inicio de la jornada laboral los lunes por la mañana. Aunque el SLA de refresco sea semanal, los datos de origen subyacentes en realidad se actualizan a diario.
No podemos usar el selector source_status:fresher+ para saltar estos modelos, porque sus sources se refrescan con más frecuencia de la que necesita el SLA del modelo downstream.
Ejemplo
Considera el siguiente comando de build de dbt:
1dbt build -s tag:weekly+
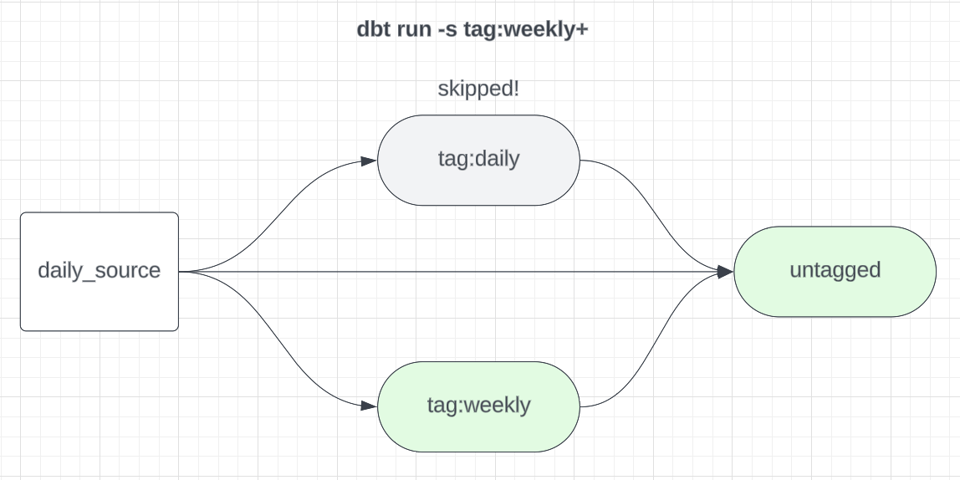
Esto ejecutará todos los modelos etiquetados como weekly y sus hijos downstream. Los downstreams también deben ejecutarse para garantizar que cualquier modelo que dependa tanto de datos weekly como de datos daily, por ejemplo, también se refresque. Si ejecutamos los modelos semanales como un subgrafo dedicado, también deberíamos excluirlos de los builds diarios para que no se reconstruyan una y otra vez sin necesidad.
1dbt build -s tag:daily+ --exclude tag:weekly
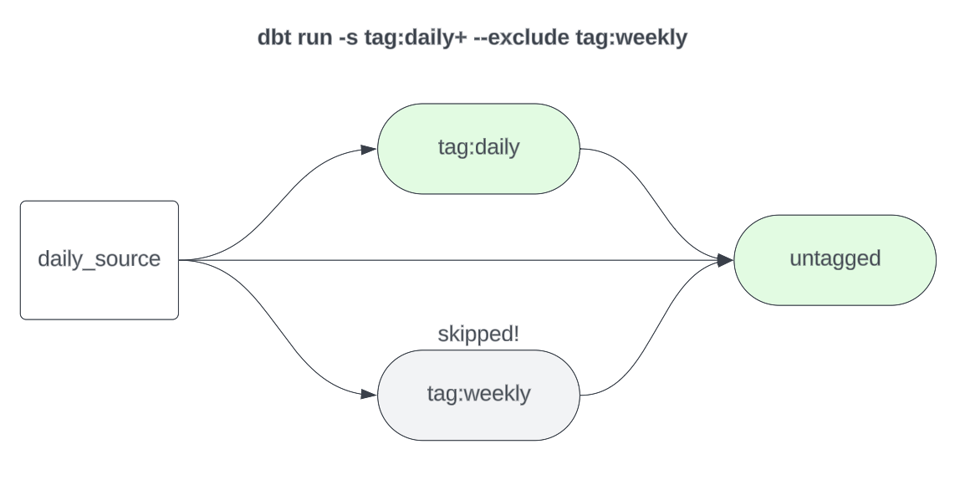
Nota: no hace falta etiquetar todos y cada uno de los modelos de tu proyecto con una frecuencia de refresco. Puedes dejar sin tags tus modelos "baseline", que normalmente se ejecutan con más frecuencia (digamos, a diario), y construirlos sin ningún selector de tag. En el ejemplo anterior usé tag:daily por claridad, pero si ese selector está en su sitio, en realidad no hace falta --exclude tag:weekly. Sin embargo, si "daily" es tu frecuencia típica de build baseline y tus modelos "daily" están sin etiquetar, entonces sí hace falta excluir explícitamente los modelos semanales.
Consideraciones
- Quizá te estés preguntando "¿por qué no uso simplemente una materialización incremental para esto?". Es una solución posible, pero no es tan general como usar tags. Algunos modelos pueden ser materializaciones
tabley demasiado complejos para incrementalizarlos con facilidad. También pueden tener lógica no determinista que hace imposible la incrementalización. - No confundas la frecuencia de refresco de la source con los SLAs de refresco de los modelos
- Que una source solo se refresque semanalmente no significa que sus modelos downstream también deban ejecutarse solo una vez por semana. Una solución más limpia es intentar ejecutarlos todos los días, usando el selector
source_status:fresher+o una materialización incremental. Así queda garantizado que se actualicen en la primera invocación de dbt posterior a un refresco de la source. De lo contrario, podría haber un "retraso" de varios días entre la actualización de una source semanal y la construcción de los modelos semanales correspondientes, lo cual no es ideal.
- Que una source solo se refresque semanalmente no significa que sus modelos downstream también deban ejecutarse solo una vez por semana. Una solución más limpia es intentar ejecutarlos todos los días, usando el selector
- Selectores de modelos superpuestos y reconstrucciones redundantes
- Quizás notes en los diagramas anteriores que el modelo downstream
untaggedse sigue seleccionando y construyendo en ambos comandos de invocación de dbt. ¡Esto es redundante! - No te preocupes: pese a la redundancia, sigue siendo una mejora importante frente a ejecutar todos los días los modelos etiquetados como
weekly. El trade-off es que tenemos que reconstruir de forma redundante el modelo downstreamuntaggeduna vez por semana (en el build diario y de nuevo en el semanal). Por supuesto, este análisis costo-beneficio depende del costo relativo del modelo untagged frente al modelo semanal. - Esto se puede mejorar todavía más con patrones de selectores y arquitecturas de DAG más sofisticados, pero no entraré en eso aquí.
- Quizás notes en los diagramas anteriores que el modelo downstream
Cierre: juntando todas las piezas
Es posible combinar varias de las flags de CLI y de los selectores basados en estado que vimos en esta serie para conseguir builds ultra slim en contextos de invocación CI/CD o Programado.
Contexto CI/CD
"Construir todos los modelos modificados y sus hijos downstream, y diferir las referencias upstream a la db de producción DBT_PROD. Fallar rápido en cuanto se encuentre un error."
1dbt build --fail-fast --defer --select state:modified+ --state .state
Contexto Programado
"Construir todos los modelos downstream de sources con actualizaciones de registros respecto al build anterior, siempre que esos modelos estén etiquetados como daily. Diferir las referencias upstream a la db de producción DBT_PROD y fallar rápido cuando se encuentre un error."
1dbt build --fail-fast --defer --select source_status:fresher+,tag:daily
Otras consideraciones
Clones de objetos vs. referencias diferidas vía --defer
Tanto en la Parte 1 como en la Parte 2 de esta serie comenté que algunos beneficios de la flag de CLI --defer también se pueden conseguir con objetos clonados con zero copy. En lugar de partir de una base de datos de invocación vacía y diferir las referencias upstream a una base de datos de producción, esos objetos se pueden clonar dentro de la db de invocación antes de invocar dbt y referenciarse de la forma habitual.
Esta estrategia ofrece más protección frente a race conditions, porque la sección "crítica" durante la cual se "fotografían" (clonan) los objetos de producción es mucho más corta que con las referencias vía --defer. Si difieres referencias a otra db, corres el riesgo de que esos objetos en la db diferida cambien a mitad de tu build a causa de un despliegue fuera de banda. Los clones pueden ser una mejor estrategia para invocaciones de dbt "críticas", como las que se asocian a builds de CI/CD sobre la rama main (merge / deploy).
La estrategia de clonación también tiene desventajas, sobre todo el hecho de que los clones deben recrearse cada vez que cambian los objetos de origen, y las complicaciones con RBAC en Snowflake.
Estrategias de materialización
La estrategia de materialización es otro componente clave de los builds slim. Es un tema en sí mismo, así que no entraré en detalle aquí. Dicho esto, los equipos deben tener presente que abusar de los builds con full refresh, sobre todo en contextos de CI/CD, es una fuente importante de reconstrucciones redundantes y de gasto. El uso de la flag --full-refresh, así como la elección entre materializaciones incremental y table, debe analizarse con cuidado en cada contexto de invocación.
Cierre
Las estrategias para invocar y desplegar modelos de dbt parecen no tener fin. Esa flexibilidad es estupenda, pero también deja en manos de los desarrolladores la responsabilidad de evitar que los modelos se construyan y reconstruyan en exceso. Esto cobra especial importancia cuando soluciones de data warehouse como Snowflake hacen muy fácil irse de las manos con el gasto de cómputo. Esperamos que las técnicas revisadas en este post te dejen mejor preparado para gestionar tus invocaciones de dbt y mantener tus builds slim de aquí en adelante.
Alex Caruso·Lead Data Platform Engineer en Entera
Alex es Lead Data Platform Engineer en Entera, con base en Nueva York, Estados Unidos.