Em Boas práticas para workflows dbt, Parte 1: Conceitos e Slim Local Builds, apresentei o conceito de build dbt "slim" e mostrei alguns exemplos para desenvolvimento dbt local. Também descrevi os diferentes "contextos de invocação do dbt" (Local, CI/CD e Scheduled).
Em Boas práticas para workflows dbt, Parte 2: Slim CI/CD Builds, descrevi algumas técnicas para conseguir slim builds em pipelines de CI/CD.
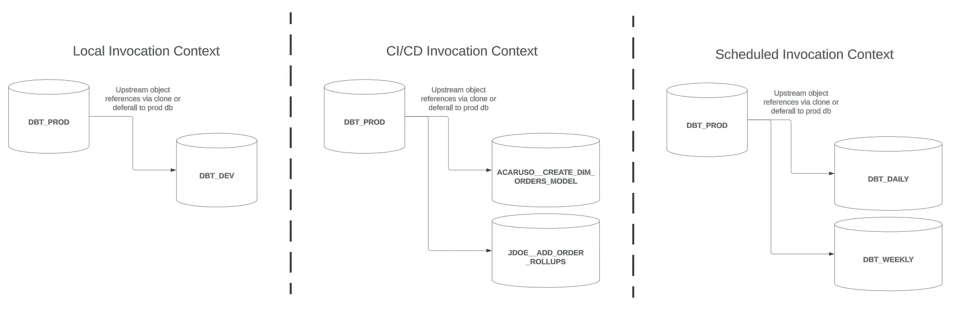
Neste post, vamos olhar para o último contexto de invocação à direita: Scheduled, explorando algumas estratégias para slim builds. Vou encerrar com uma discussão sobre outros pontos a considerar para builds dbt nos três contextos de invocação.
[@portabletext/react] Unknown block type "cta", specify a component for it in the `components.types` prop
Recap da Parte 1: Slim Builds dbt locais
Builds dbt "slim" minimizam invocações de modelos redundantes, desnecessárias ou equivocadas. Quando invocamos o dbt, normalmente queremos atingir um destes dois objetivos:
- Construir, testar e validar mudanças de código/lógica em recursos dbt (modelos, testes, etc.)
- Contexto de invocação
LocalouCI/CD - Atualizar modelos conforme novos dados de origem chegam
- Contexto de invocação
Scheduled
Nos dois casos, geralmente só precisamos construir um subconjunto menor do DAG. Em qualquer invocação do dbt, existe um conjunto mínimo de recursos que precisam ser construídos para atingir o objetivo. A meta dos slim builds é chegar o mais perto possível desse conjunto mínimo, para não desperdiçar tempo de compute e dinheiro com outros recursos.
Builds dbt locais podem ser "enxutos" para mirar apenas nos recursos relevantes usando a flag de CLI --defer, a flag --empty ou técnicas de amostragem de linhas.
Recap da Parte 2: Slim CI/CD
Slim builds em CI/CD podem ser obtidos com o seletor state:modified+ ou com a flag de CLI --fail-fast. O --defer também pode ser usado em alguns contextos de CI/CD, mas não em todos.
Pré-requisitos
- Você leu até a parte de
Slim Local Buildsem Boas práticas para workflows dbt, Parte 1: Conceitos e Slim Local Builds - Você configurou a persistência de artefatos do dbt, conforme descrito na Parte 1
- Você tem um pipeline de orquestração funcional para invocar builds dbt agendados em um database ou schema isolado no seu ambiente de destino
Slim Scheduled Builds
Em um contexto de invocação dbt agendada, não há mudanças de código acontecendo, apenas atualizações nos dados de origem. Isso significa que as decisões sobre quais modelos construir em uma determinada invocação dependem apenas da frequência de atualização dos dados de origem e dos SLAs dos modelos downstream expostos.
Seletor source_status:fresher+
O dbt consegue capturar a "freshness" das suas tabelas de dados de origem usando o comando dbt source freshness. A "freshness" de uma tabela indica quando ela foi atualizada pela última vez, normalmente com base em uma coluna de timestamp, e a diferença entre o valor máximo dessa coluna e algum limite de SLA (diário, semanal, etc.).
Se as origens estiverem configuradas conforme descrito na documentação acima (com as propriedades freshness e loaded_at_field), o comando dbt source freshness vai gerar um artefato sources.json que armazena o valor max_loaded_at de cada tabela de origem. Esse artefato pode ser usado em conjunto com o seletor source_status:fresher+ para selecionar apenas as origens que foram atualizadas em relação à última vez que ele foi gerado.
Isso é útil para "enxugar" builds agendados, ignorando modelos downstream de origens que não tiveram nenhuma atualização desde a última invocação do dbt. Por exemplo, suponha que você tenha uma fonte de dados grande que só atualiza uma vez por semana, mas também executa um build dbt agendado todas as noites. Os modelos downstream dessa origem devem ser pulados em 6 de cada 7 dias, a menos que também dependam de uma ou mais origens que atualizam com mais frequência do que semanalmente.
Exemplo
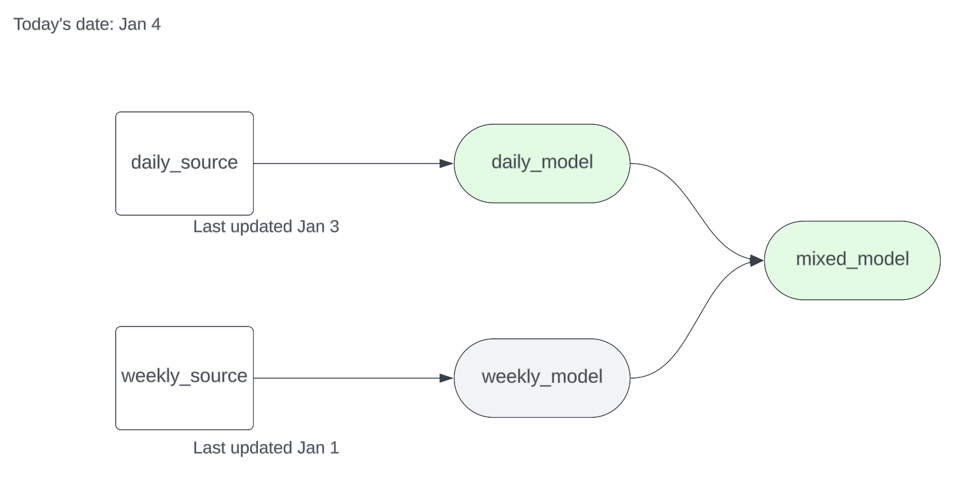
Suponha que você tenha duas origens, uma que atualiza diariamente e outra semanalmente, e alguns modelos downstream. Depois de rodar dbt source freshness, seu artefato source.json fica assim:
1[\
\
2 {\
\
3 "unique_id": "source.projectname.sourcename.daily_source",\
\
4 "max_loaded_at": "2025-01-03T12:00:00.000000+00:00",\
\
5 ...\
\
6 },\
\
7 {\
\
8 "unique_id": "source.projectname.sourcename.weekly_source",\
\
9 "max_loaded_at": "2025-01-01T00:00:00.000000+00:00",\
\
10 ...\
\
11 }\
\
12]
A daily_source foi atualizada pela última vez em 03/01 ao meio-dia, e a weekly_source em 01/01 à meia-noite. Se rodarmos dbt run -s source_status:fresher+ --state .state em 04/01 contra o subgrafo abaixo, o modelo downstream da origem semanal deve ser pulado.
Considerações
- Quando rodar o
dbt source freshness?- Esse comando deve ser executado antes de cada nova invocação dbt agendada. O artefato
sources.jsonresultante deve ser persistido, para que invocações subsequentes de builds dbt agendados consigam baixá-lo em disco e utilizá-lo no seletorsource_status:fresher+.
- Esse comando deve ser executado antes de cada nova invocação dbt agendada. O artefato
- Garanta que todas as origens tenham as configurações
freshnesseloaded_at_fielddefinidas- Se não tiverem, o dbt vai ignorar essas origens durante o comando
dbt source freshnesse não vai gerar nenhum metadado de timestampmax_loaded_atno artefatosources.json. Aí essas origens serão completamente ignoradas pelo seletorsource_status:fresher+ - Dá um certo trabalho garantir que todas as origens tenham essa configuração — meu time aplica isso com uma macro que inspeciona todas as origens e valida que esses atributos estão definidos.
- Se não tiverem, o dbt vai ignorar essas origens durante o comando
Tags em modelos
Outra forma de conseguir slim scheduled builds é com tags em modelos. Em vez de rodar todos os modelos a cada build agendado, podemos rodar apenas modelos ou subgrafos associados a uma tag. Uma forma prática de fazer isso em um contexto de invocação agendada é usar tags nomeadas com base em algum SLA de atualização, como daily, weekly ou monthly.
Por exemplo, suponha que tenhamos alguns modelos servindo relatórios com SLA de atualização semanal. Eles precisam estar atualizados no início do expediente de segunda-feira. Mesmo que o SLA seja semanal, os dados de origem subjacentes atualizam diariamente.
Não dá para usar o seletor source_status:fresher+ para pular esses modelos, porque as origens deles atualizam com mais frequência do que o necessário para o SLA do modelo downstream.
Exemplo
Considere o seguinte comando de build dbt:
1dbt build -s tag:weekly+
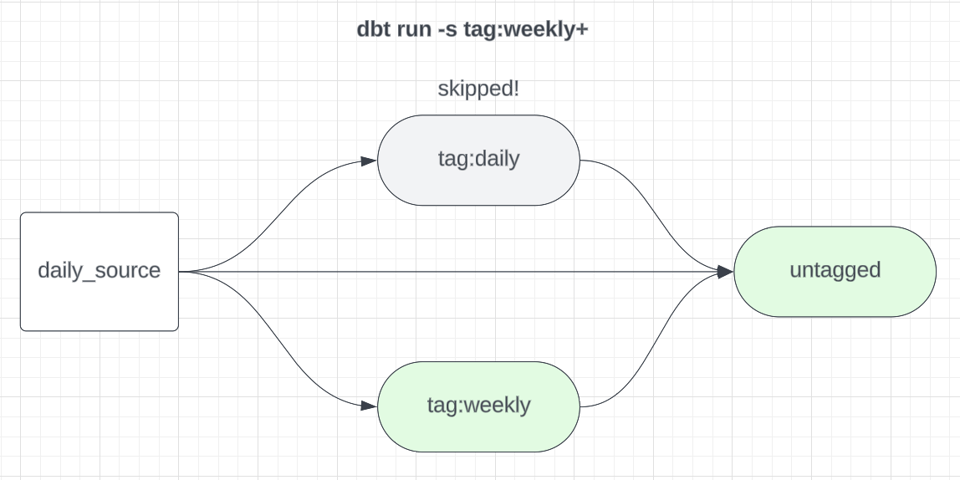
Isso vai rodar todos os modelos com a tag weekly e seus filhos downstream. Os downstreams também precisam ser executados para garantir que qualquer modelo que dependa tanto de dados weekly quanto de dados daily, por exemplo, também seja atualizado. Se estamos rodando modelos semanais como um subgrafo dedicado, também devemos excluir esses modelos dos builds diários, para que não sejam reconstruídos sem necessidade.
1dbt build -s tag:daily+ --exclude tag:weekly
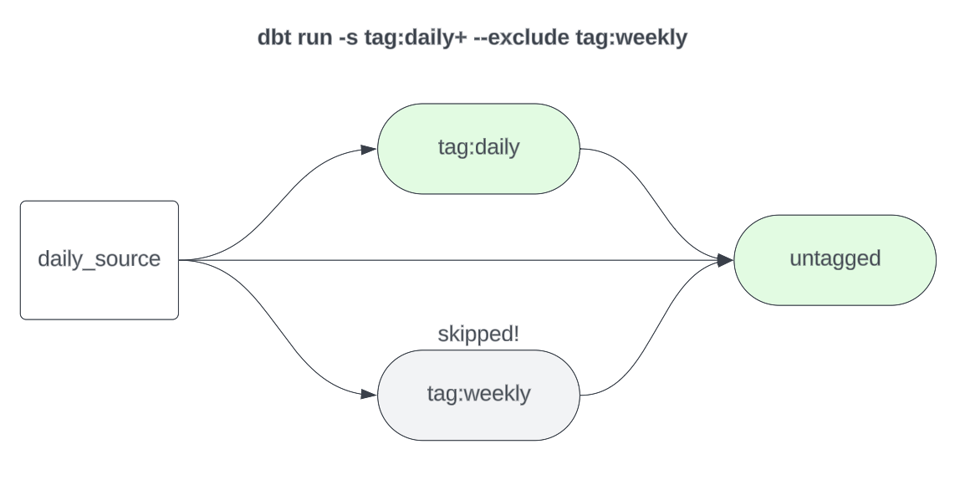
Observação: você não precisa, necessariamente, marcar todos os modelos do projeto com uma frequência de atualização. Você pode simplesmente deixar seus modelos "baseline", que normalmente rodam com mais frequência (digamos, diariamente), sem tag, e construí-los sem nenhum seletor de tag. No exemplo acima, usei tag:daily para deixar mais claro, mas se esse seletor estiver em uso, o --exclude tag:weekly não é realmente necessário. Por outro lado, se "daily" é a frequência típica do seu build baseline e seus modelos "daily" não têm tag, então uma exclusão explícita dos modelos semanais é necessária.
Considerações
- Você pode estar se perguntando "por que eu não posso simplesmente usar uma materialização incremental para isso?". Essa é uma solução possível, mas não é tão genérica quanto usar tags. Alguns modelos podem ser materializações
tablee complexos demais para incrementalizar com facilidade. Eles também podem ter lógica não determinística que torna a incrementalização inviável. - Não confunda frequência de atualização da origem com os SLAs de atualização dos modelos
- Só porque uma origem atualiza apenas semanalmente, não significa que os modelos downstream dela devem rodar somente semanalmente também. Uma solução mais elegante é tentar rodá-los todos os dias, usando o seletor
source_status:fresher+ou uma materialização incremental. Dessa forma, eles ficam garantidamente atualizados já na primeira invocação dbt após uma atualização da origem. Caso contrário, pode haver um "atraso" de vários dias entre a atualização de uma origem semanal e o build dos modelos semanais correspondentes, o que não é ideal.
- Só porque uma origem atualiza apenas semanalmente, não significa que os modelos downstream dela devem rodar somente semanalmente também. Uma solução mais elegante é tentar rodá-los todos os dias, usando o seletor
- Seletores de modelo sobrepostos e rebuilds redundantes
- Você pode ter notado nos diagramas acima que o modelo
untaggeddownstream continua sendo selecionado e construído em ambos os comandos de invocação do dbt. Isso é redundante! - Mas não se preocupe: apesar de haver alguma redundância aqui, isso ainda é uma melhoria enorme em relação a rodar modelos com a tag
weeklytodos os dias. A contrapartida é que precisamos reconstruir o modelountaggeddownstream uma vez por semana de forma redundante (uma vez no build diário e outra no semanal). Claro, essa análise de custo-benefício depende dos custos relativos do modelo untagged em comparação com o modelo weekly. - Dá para melhorar ainda mais com padrões de seleção e arquiteturas de DAG mais sofisticados, mas não vou entrar nesse tema aqui.
- Você pode ter notado nos diagramas acima que o modelo
Conclusão: juntando tudo
É possível combinar várias das flags de CLI e seletores baseados em estado discutidos nesta série para conseguir builds ultra slim em contextos de invocação CI/CD ou Scheduled.
Contexto CI/CD
"Construa todos os modelos modificados e seus filhos downstream, e adie as referências upstream para o db de produção DBT_PROD. Falhe rapidamente quando um erro for encontrado."
1dbt build --fail-fast --defer --select state:modified+ --state .state
Contexto Scheduled
"Construa todos os modelos downstream de origens com atualizações de registros em relação ao build anterior, se esses modelos tiverem a tag daily. Adie as referências upstream para o db de produção DBT_PROD e falhe rapidamente quando um erro for encontrado."
1dbt build --fail-fast --defer --select source_status:fresher+,tag:daily
Outros pontos a considerar
Clones de objetos vs. referências adiadas via --defer
Tanto na Parte 1 quanto na Parte 2 desta série, abordei a ideia de que alguns dos benefícios da flag de CLI --defer também podem ser obtidos com objetos clonados zero-copy. Em vez de partir de um database de invocação vazio e adiar as referências upstream para um database de produção, esses objetos podem ser clonados para o db de invocação antes de invocar o dbt e referenciados normalmente.
Essa estratégia oferece mais proteção contra race conditions, porque a seção "crítica" durante a qual os objetos de produção são "snapshotados" (clonados) é bem menor do que com referências via --defer. Se você adia as referências para outro db, corre o risco de que esses objetos no db de deferência mudem no meio do seu build por causa de um deploy fora de banda. Clones podem ser uma estratégia melhor para invocações dbt "críticas", como invocações associadas a builds CI/CD da branch main (merge / deploy).
A estratégia de clonagem também tem algumas desvantagens, principalmente o fato de que os clones precisam ser recriados toda vez que os objetos de origem mudam, e complicações com RBAC no Snowflake.
Estratégias de materialização
A estratégia de materialização é outro componente crítico dos slim builds. Esse é um tema enorme por si só, então não vou entrar em detalhes aqui. Dito isso, os times devem ter em mente que builds excessivos de full refresh, especialmente em contextos de CI/CD, são uma grande fonte de builds redundantes e de gasto. O uso da flag --full-refresh, assim como as decisões entre materializações incremental e table, devem ser cuidadosamente avaliados em cada contexto de invocação.
Conclusão
Existem estratégias praticamente infinitas para invocar e implantar modelos dbt. Embora essa flexibilidade seja ótima de se ter, ela também coloca nos desenvolvedores a responsabilidade de garantir que os modelos não sejam construídos e reconstruídos em excesso. Isso é especialmente importante quando soluções de data warehouse como o Snowflake tornam tão fácil exagerar nos gastos com compute. Espero que as técnicas apresentadas neste post deixem você mais preparado para gerenciar suas invocações dbt e manter seus builds slim daqui para frente.
Alex Caruso·Lead Data Platform Engineer na Entera
Alex é Lead Data Platform Engineer na Entera, baseado em Nova York, Estados Unidos.