Dans Bonnes pratiques pour les workflows dbt, partie 1 : concepts et slim local builds, j'ai présenté le concept de build dbt slim et donné quelques exemples pour le développement dbt en local. J'ai également décrit les différents contextes d'invocation dbt (Local, CI/CD et Scheduled).
Dans Bonnes pratiques pour les workflows dbt, partie 2 : slim CI/CD builds, j'ai détaillé plusieurs techniques pour obtenir des builds slim dans les pipelines CI/CD.
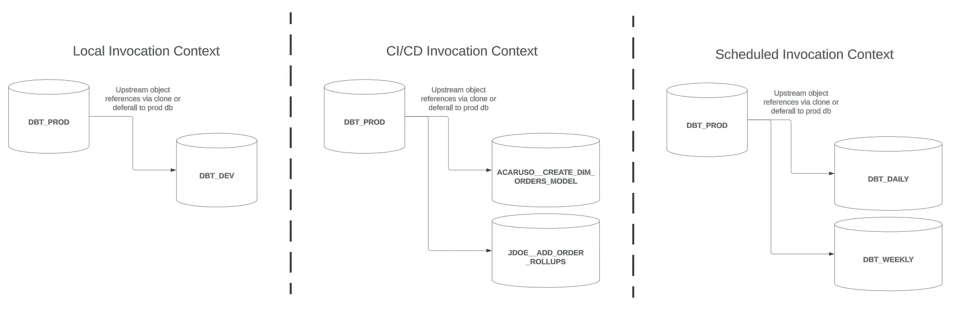
Dans cet article, nous abordons le dernier contexte d'invocation, à droite : Scheduled, et explorons plusieurs stratégies pour obtenir des builds slim. Je terminerai par quelques considérations supplémentaires applicables aux builds dbt dans les trois contextes d'invocation.
[@portabletext/react] Unknown block type "cta", specify a component for it in the `components.types` prop
Récap de la partie 1 : slim local builds dbt
Les builds dbt slim réduisent au minimum les invocations de modèles redondantes, inutiles ou erronées. Lorsqu'on invoque dbt, on cherche généralement à atteindre l'un de ces deux objectifs :
- Construire, tester et valider des changements de code ou de logique sur des ressources dbt (modèles, tests, etc.)
- Contexte d'invocation
LocalouCI/CD - Rafraîchir les modèles lorsque de nouvelles données source arrivent
- Contexte d'invocation
Scheduled
Dans les deux cas, il suffit en général de construire un sous-ensemble réduit du DAG. Pour toute invocation dbt, il existe un ensemble minimal de ressources à construire pour atteindre l'objectif visé. L'enjeu des slim builds est de s'approcher au plus près de cet ensemble minimal, afin de ne gaspiller ni temps de calcul ni budget sur le reste des ressources.
Les builds dbt locaux peuvent être allégés pour ne cibler que les ressources pertinentes, grâce à l'option CLI --defer, à l'option CLI --empty ou à des techniques d'échantillonnage de lignes.
Récap de la partie 2 : slim CI/CD
Les builds CI/CD slim s'obtiennent à l'aide du sélecteur state:modified+ ou de l'option CLI --fail-fast. --defer peut également être utilisé dans certains contextes CI/CD, mais pas tous.
Prérequis
- Vous avez lu jusqu'à la section
Slim Local Buildsde Bonnes pratiques pour les workflows dbt, partie 1 : concepts et slim local builds - Vous avez mis en place la persistance des artefacts dbt, comme décrit dans la partie 1
- Vous disposez d'un pipeline d'orchestration fonctionnel permettant de déclencher des builds dbt planifiés sur une base de données ou un schéma isolé dans votre environnement de destination
Slim Scheduled Builds
Dans un contexte d'invocation dbt planifiée, il n'y a aucun changement de code, uniquement des rafraîchissements de données source. Les décisions concernant les modèles à construire pour une invocation donnée ne dépendent donc que de la fréquence de rafraîchissement des données source et des SLA d'exposition des modèles en aval.
Sélecteur source_status:fresher+
dbt sait capturer la fraîcheur de vos tables de données source via la commande dbt source freshness. La fraîcheur d'une table indique sa dernière mise à jour, généralement à partir d'une colonne d'horodatage, en comparant la valeur maximale de cette colonne à un seuil SLA (quotidien, hebdomadaire, etc.).
Si les sources sont configurées comme décrit dans la documentation citée plus haut (avec les propriétés freshness et loaded_at_field), la commande dbt source freshness génère un artefact sources.json qui stocke la valeur max_loaded_at pour chaque table source. Cet artefact peut être combiné au sélecteur source_status:fresher+ afin de ne sélectionner que les sources mises à jour depuis la dernière génération de l'artefact.
C'est utile pour alléger les builds planifiés en ignorant les modèles situés en aval de sources qui n'ont reçu aucune mise à jour depuis la dernière invocation dbt. Par exemple, supposons que vous ayez une grande source de données qui ne se met à jour qu'une fois par semaine, mais que vous exécutiez aussi un build dbt nocturne planifié. Les modèles en aval de cette source devraient être ignorés 6 jours sur 7, sauf s'ils dépendent également d'une ou plusieurs sources rafraîchies plus fréquemment qu'une fois par semaine.
Exemple
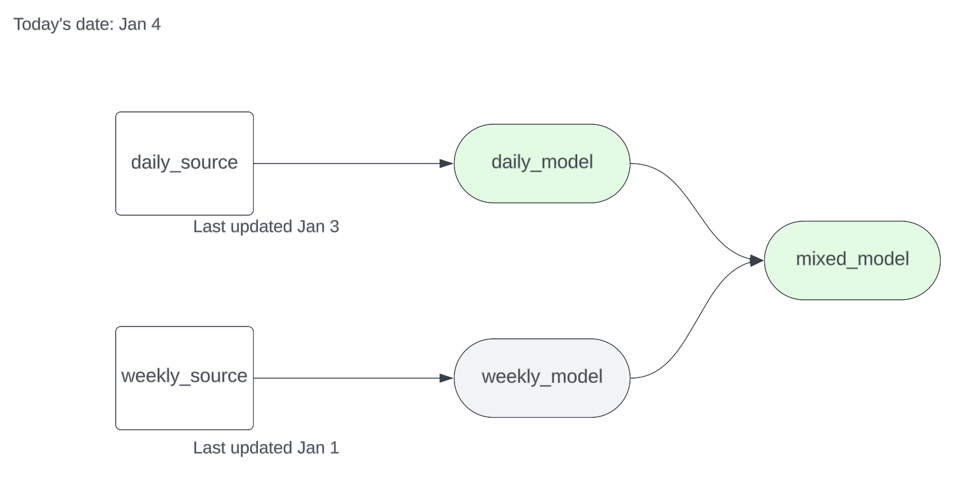
Supposons que vous ayez deux sources, l'une mise à jour quotidiennement et l'autre hebdomadairement, ainsi que quelques modèles en aval. Après avoir exécuté dbt source freshness, votre artefact source.json ressemble à ceci :
1[\
\
2 {\
\
3 "unique_id": "source.projectname.sourcename.daily_source",\
\
4 "max_loaded_at": "2025-01-03T12:00:00.000000+00:00",\
\
5 ...\
\
6 },\
\
7 {\
\
8 "unique_id": "source.projectname.sourcename.weekly_source",\
\
9 "max_loaded_at": "2025-01-01T00:00:00.000000+00:00",\
\
10 ...\
\
11 }\
\
12]
La daily_source a été mise à jour pour la dernière fois le 3 janvier à midi, et la weekly_source le 1er janvier à minuit. Si nous exécutons dbt run -s source_status:fresher+ --state .state le 4 janvier sur le sous-graphe ci-dessous, le modèle en aval de la source hebdomadaire devrait être ignoré.
À prendre en compte
- Quand exécuter
dbt source freshness?- Cette commande doit être lancée avant chaque nouvelle invocation dbt planifiée. L'artefact
sources.jsonobtenu doit être persisté, afin que les invocations dbt planifiées suivantes puissent le télécharger sur disque et l'exploiter avec le sélecteursource_status:fresher+.
- Cette commande doit être lancée avant chaque nouvelle invocation dbt planifiée. L'artefact
- Vérifiez que toutes les sources disposent bien d'une configuration
freshnessetloaded_at_field- Faute de quoi, dbt ignorera ces sources lors de l'exécution de
dbt source freshnesset ne générera aucune métadonnéemax_loaded_atdans l'artefactsources.json. Ces sources seront alors totalement ignorées par le sélecteursource_status:fresher+. - Garantir cette configuration sur l'ensemble des sources peut s'avérer fastidieux — mon équipe l'impose grâce à une macro qui inspecte toutes les sources et vérifie que ces attributs sont bien définis.
- Faute de quoi, dbt ignorera ces sources lors de l'exécution de
Tagging des modèles
Une autre façon d'obtenir des builds planifiés slim consiste à utiliser le tagging de modèles. Plutôt que d'exécuter tous les modèles à chaque build planifié, on peut n'exécuter que les modèles ou sous-graphes associés à un tag. Une approche pratique en contexte d'invocation planifiée consiste à utiliser des tags nommés d'après un SLA de rafraîchissement, comme daily, weekly ou monthly.
Supposons par exemple que nous ayons des modèles alimentant des rapports avec un SLA de rafraîchissement hebdomadaire. Ils doivent être à jour en début de journée le lundi matin. Même si le SLA est hebdomadaire, les données source sous-jacentes se mettent en réalité à jour quotidiennement.
Nous ne pouvons pas utiliser le sélecteur source_status:fresher+ pour ignorer ces modèles, car leurs sources se rafraîchissent plus fréquemment que ne l'exige le SLA du modèle en aval.
Exemple
Prenons la commande de build dbt suivante :
1dbt build -s tag:weekly+
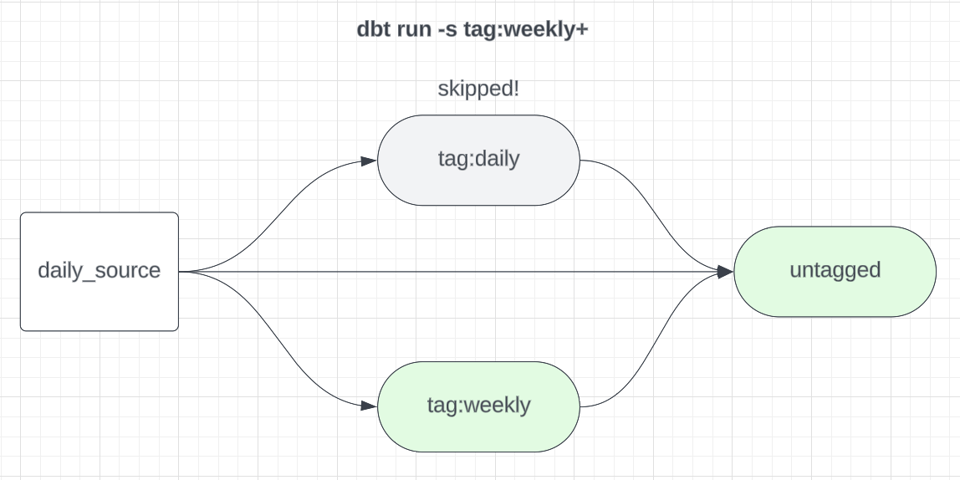
Elle exécute tous les modèles taggés weekly ainsi que leurs descendants en aval. Les descendants doivent aussi être exécutés pour garantir que les modèles dépendant à la fois de données weekly et de données daily soient également rafraîchis. Si nous traitons les modèles hebdomadaires comme un sous-graphe dédié, il faut aussi les exclure des builds quotidiens, pour éviter qu'ils soient reconstruits inutilement à répétition.
1dbt build -s tag:daily+ --exclude tag:weekly
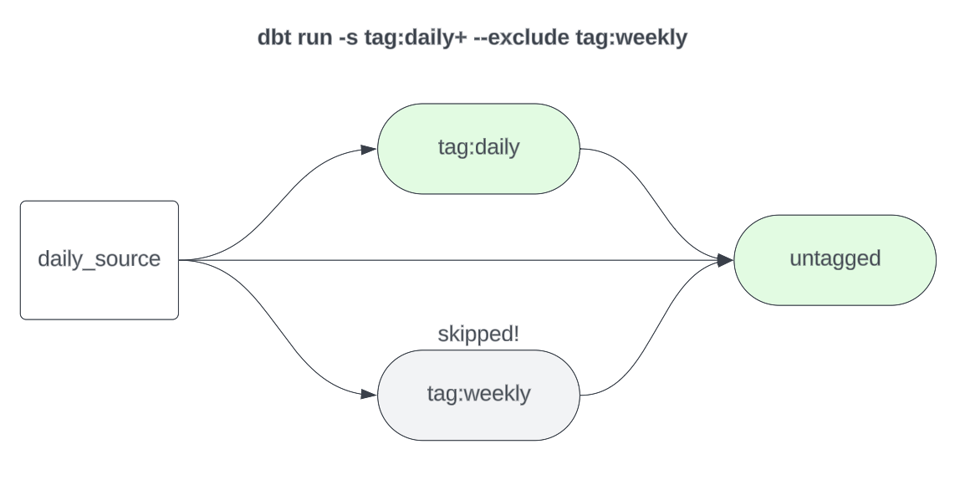
Remarque : il n'est pas nécessaire de tagger chaque modèle de votre projet avec une fréquence de rafraîchissement. Vous pouvez laisser vos modèles de référence, ceux qui s'exécutent le plus souvent (typiquement quotidiennement), sans tag, et les construire sans sélecteur de tag. Dans l'exemple ci-dessus, j'ai utilisé tag:daily pour plus de clarté, mais si ce sélecteur est en place, le --exclude tag:weekly devient en réalité superflu. En revanche, si daily correspond à votre fréquence de build de référence et que vos modèles quotidiens ne sont pas taggés, alors une exclusion explicite des modèles hebdomadaires devient nécessaire.
À prendre en compte
- Vous vous demandez peut-être pourquoi ne pas simplement recourir à une matérialisation incrémentale. C'est une solution envisageable, mais moins polyvalente que les tags. Certains modèles peuvent être matérialisés en
tableet trop complexes pour être facilement incrémentalisés. Ils peuvent aussi reposer sur une logique non déterministe qui rend l'incrémentalisation impossible. - Ne confondez pas fréquence de rafraîchissement des sources et SLA de rafraîchissement des modèles
- Ce n'est pas parce qu'une source ne se rafraîchit qu'une fois par semaine que ses modèles en aval doivent eux aussi ne s'exécuter qu'une fois par semaine. Une approche plus propre consiste à tenter de les exécuter chaque jour, à l'aide du sélecteur
source_status:fresher+ou d'une matérialisation incrémentale. Ainsi, ils sont garantis d'être mis à jour dès la première invocation dbt qui suit un rafraîchissement de la source. Sinon, vous risquez un décalage de plusieurs jours entre la mise à jour d'une source hebdomadaire et le build des modèles hebdomadaires correspondants, ce qui n'est pas idéal.
- Ce n'est pas parce qu'une source ne se rafraîchit qu'une fois par semaine que ses modèles en aval doivent eux aussi ne s'exécuter qu'une fois par semaine. Une approche plus propre consiste à tenter de les exécuter chaque jour, à l'aide du sélecteur
- Chevauchement des sélecteurs et reconstructions redondantes
- Vous avez peut-être remarqué dans les schémas ci-dessus que le modèle
untaggeden aval est tout de même sélectionné et construit dans les deux commandes d'invocation dbt. C'est redondant ! - Pas d'inquiétude : malgré cette redondance, cela reste une amélioration majeure par rapport à l'exécution quotidienne des modèles taggés
weekly. Le compromis, c'est qu'il faut reconstruire de façon redondante le modèleuntaggeden aval une fois par semaine (une fois pour le build quotidien, puis à nouveau pour l'hebdomadaire). Bien entendu, cette analyse coût/bénéfice dépend du coût relatif du modèle untagged comparé à celui du modèle hebdomadaire. - On peut aller plus loin avec des patterns de sélecteurs et des architectures de DAG plus sophistiqués, mais je n'entrerai pas dans le détail ici.
- Vous avez peut-être remarqué dans les schémas ci-dessus que le modèle
Conclusion : tout assembler
Il est possible de combiner plusieurs des options CLI et sélecteurs basés sur l'état présentés dans cette série pour obtenir des builds ultra slim en contexte CI/CD ou Scheduled.
Contexte CI/CD
Construire tous les modèles modifiés et leurs descendants en aval, et déférer les références en amont vers la base de production DBT_PROD. Échouer rapidement en cas d'erreur.
1dbt build --fail-fast --defer --select state:modified+ --state .state
Contexte Scheduled
Construire tous les modèles en aval des sources ayant reçu des mises à jour depuis le build précédent, à condition que ces modèles soient taggés daily. Déférer les références en amont vers la base de production DBT_PROD et échouer rapidement en cas d'erreur.
1dbt build --fail-fast --defer --select source_status:fresher+,tag:daily
Autres considérations
Clones d'objets vs références déférées via --defer
Dans les parties 1 et 2 de cette série, j'ai expliqué qu'on peut en réalité obtenir certains des avantages de l'option CLI --defer via des clones zero-copy. Au lieu de partir d'une base d'invocation vide et de déférer les références en amont vers une base de production, ces objets peuvent être clonés dans la base d'invocation avant le lancement de dbt, puis référencés normalement.
Cette stratégie offre une meilleure protection contre les race conditions, car la section critique pendant laquelle les objets de production sont capturés (clonés) est bien plus courte que dans le cas de références via --defer. Si vous déférez les références vers une autre base, vous courez le risque que ces objets changent en cours de build à cause d'un déploiement hors bande. Le clonage peut donc constituer une meilleure stratégie pour les invocations dbt critiques, comme celles associées aux builds CI/CD sur la branche main (merge / déploiement).
La stratégie de clonage présente aussi quelques inconvénients, notamment le fait que les clones doivent être recréés à chaque modification des objets sources, et les complications liées au RBAC dans Snowflake.
Stratégies de matérialisation
La stratégie de matérialisation est un autre élément critique des slim builds. C'est un sujet à part entière, je n'entrerai donc pas dans les détails ici. Cela dit, les équipes doivent garder à l'esprit qu'un recours excessif aux full refresh builds, en particulier en CI/CD, est une source majeure de reconstructions redondantes et de surcoûts. L'utilisation de l'option --full-refresh, ainsi que le choix entre matérialisations incremental et table, doivent être soigneusement pesés dans chaque contexte d'invocation.
Pour conclure
Les stratégies pour invoquer et déployer des modèles dbt sont quasi infinies. Si cette flexibilité est précieuse, elle fait aussi peser sur les développeurs la responsabilité de veiller à ce que les modèles ne soient pas construits et reconstruits à l'excès. C'est d'autant plus important que les solutions de data warehouse comme Snowflake facilitent grandement les dérives en matière de dépenses de calcul. Nous espérons que les techniques présentées dans cet article vous aideront à mieux maîtriser vos invocations dbt et à garder vos builds slim à l'avenir.
Alex Caruso · Lead Data Platform Engineer chez Entera
Alex est Lead Data Platform Engineer chez Entera, basé à New York, aux États-Unis.