dbtワークフロー ベストプラクティス第1回:基本概念とスリムなローカルビルドでは、「スリム」なdbtビルドという考え方を紹介し、ローカル開発での具体例をいくつか示しました。あわせて、dbtの実行コンテキスト(Local、CI/CD、Scheduled)についても整理しました。
dbtワークフロー ベストプラクティス第2回:スリムなCI/CDビルドでは、CI/CDパイプラインでスリムビルドを実現するためのテクニックを取り上げました。
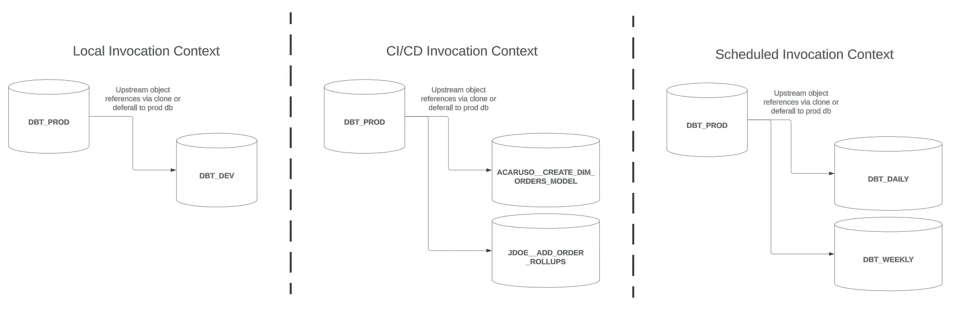
今回は、図の右端に残った最後の実行コンテキストであるScheduledを取り上げ、スリムビルドを実現するためのアプローチを見ていきます。最後に、3つの実行コンテキストに共通するdbtビルドの留意点にも触れます。
[@portabletext/react] Unknown block type "cta", specify a component for it in the `components.types` prop
第1回の振り返り:ローカルでのスリムなdbtビルド
「スリム」なdbtビルドとは、重複した実行・不要な実行・誤った実行をできるだけ減らすことを指します。dbtを実行する目的は、たいてい次のどちらかです。
- dbtリソース(モデルやテストなど)に加えたコードやロジックの変更をビルド・テスト・検証する
LocalまたはCI/CDの実行コンテキスト- 新しいソースデータの取り込みに合わせてモデルをリフレッシュする
Scheduledの実行コンテキスト
いずれの場合も、ビルドが必要なのはDAGの一部分にとどまるのが普通です。各実行において目的を果たすために必要な「最小限のリソース集合」が必ず存在します。スリムビルドのゴールは、その最小集合にできる限り近づけて、それ以外のリソースに計算時間とコストを費やさないようにすることです。
ローカルのdbtビルドは、--deferや--emptyのCLIフラグ、あるいは行サンプリングの手法を使うことで、対象を関連リソースだけに「スリム化」できます。
第2回の振り返り:スリムなCI/CD
CI/CDのスリムビルドは、state:modified+セレクタや--fail-fastのCLIフラグで実現できます。--deferも、すべてではないものの一部のCI/CDコンテキストで利用できます。
前提条件
- dbtワークフロー ベストプラクティス第1回:基本概念とスリムなローカルビルドの
Slim Local Buildsまでを読了済みであること - 第1回で説明したdbtアーティファクトの永続化を設定済みであること
- デプロイ先環境内の隔離されたデータベースまたはスキーマに対して、スケジュール実行のdbtビルドを起動できるオーケストレーションパイプラインが稼働していること
スリムなスケジュール実行
スケジュール実行コンテキストではコード変更は発生せず、ソースデータのリフレッシュだけが行われます。そのため、その実行でどのモデルをビルドするかは、ソースデータのリフレッシュ頻度と、下流モデルの公開SLAの2点だけで決まります。
source_status:fresher+ セレクタ
dbtでは、dbt source freshnessコマンドを使ってソーステーブルの「鮮度(freshness)」を取得できます。テーブルの鮮度とは、通常はタイムスタンプ列をもとにした最終更新時刻、つまりその列の最大値と、日次や週次といったSLAしきい値との差分のことです。
上のドキュメントに従ってfreshnessとloaded_at_fieldを設定しておけば、dbt source freshnessコマンドは各ソーステーブルのmax_loaded_atを保持するsources.jsonアーティファクトを生成します。これをsource_status:fresher+セレクタと組み合わせれば、前回のアーティファクト生成時点から更新があったソースだけを対象にできます。
これにより、前回のdbt実行以降に更新のないソースの下流モデルを除外でき、スケジュールビルドを「スリム化」できます。たとえば、更新が週1回しかない大規模なデータソースがあり、一方で毎晩スケジュールビルドを回しているケースを考えてみてください。週次より頻繁に更新される他のソースに依存していない限り、このソースの下流モデルは7日のうち6日はスキップして構わないわけです。
例
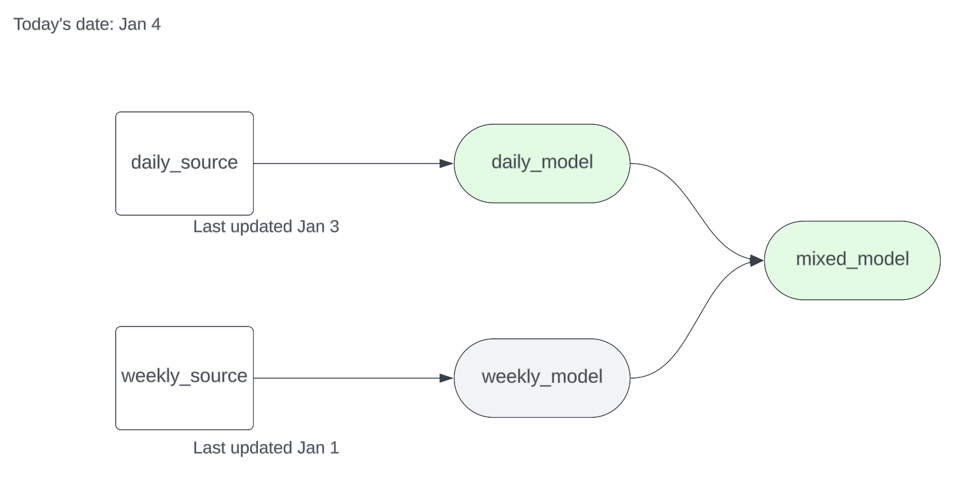
日次で更新されるソースと週次で更新されるソースが1つずつ、そしてその下流にいくつかのモデルがあるとします。dbt source freshnessを実行すると、source.jsonアーティファクトは次のような内容になります。
1[\
\
2 {\
\
3 "unique_id": "source.projectname.sourcename.daily_source",\
\
4 "max_loaded_at": "2025-01-03T12:00:00.000000+00:00",\
\
5 ...\
\
6 },\
\
7 {\
\
8 "unique_id": "source.projectname.sourcename.weekly_source",\
\
9 "max_loaded_at": "2025-01-01T00:00:00.000000+00:00",\
\
10 ...\
\
11 }\
\
12]
daily_sourceの最終更新は1月3日正午、weekly_sourceの最終更新は1月1日0時です。1月4日に、下図のサブグラフに対してdbt run -s source_status:fresher+ --state .stateを実行すれば、週次ソースの下流にあるモデルはスキップされます。
留意点
dbt source freshnessはいつ実行するか- このコマンドは、スケジュール実行のdbtビルドを起動する直前に毎回走らせます。生成された
sources.jsonは永続化しておき、次回以降のスケジュール実行時にディスクへダウンロードしてsource_status:fresher+セレクタから参照できるようにします。
- このコマンドは、スケジュール実行のdbtビルドを起動する直前に毎回走らせます。生成された
- すべてのソースに
freshnessとloaded_at_fieldの設定があるかを確認する- 設定がないソースは
dbt source freshnessコマンドで無視され、sources.jsonにmax_loaded_atのタイムスタンプが書き込まれません。その結果、source_status:fresher+セレクタからも完全に外れてしまいます。 - すべてのソースに漏れなく設定するのは地味に手間がかかる作業です。私のチームでは、全ソースを走査してこれらの属性が定義されているかを検証するマクロを使い、強制的にルール化しています。
- 設定がないソースは
モデルへのタグ付け
スリムなスケジュールビルドを実現するもう一つの手段が、モデルへのタグ付けです。スケジュール実行のたびに全モデルを動かすのではなく、特定のタグが付いたモデルやサブグラフだけを実行します。スケジュール実行コンテキストでよくあるのは、daily、weekly、monthlyのようにリフレッシュSLAに対応したタグ名を使う方法です。
たとえば、週次リフレッシュSLAでレポートを提供するモデル群があり、月曜の業務開始時点で最新であることが求められるとします。SLAは週次ですが、元になるソースデータ自体は日次で更新されているケースです。
この場合、source_status:fresher+セレクタでスキップ判定することはできません。下流モデルのSLAが求めるよりも、ソース側のリフレッシュ頻度の方が高いためです。
例
次のdbt buildコマンドを見てみましょう。
1dbt build -s tag:weekly+
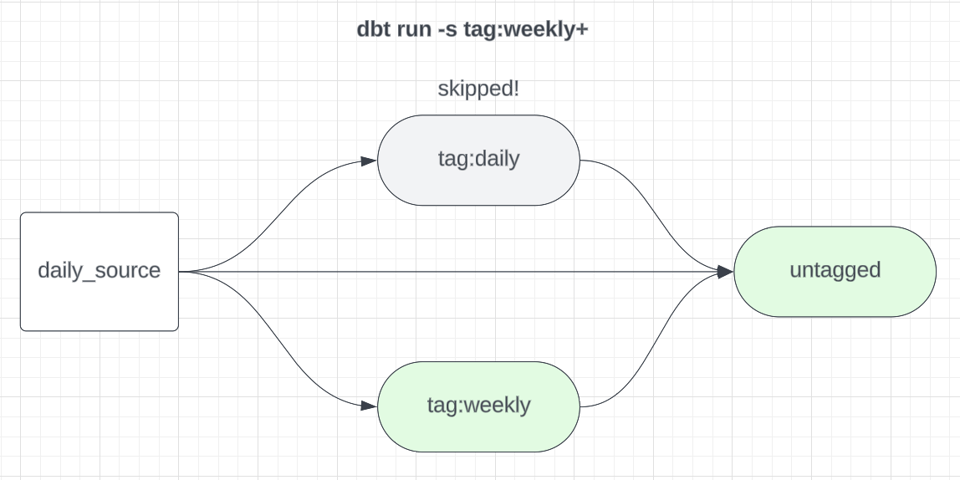
これはweeklyタグの付いたすべてのモデルと、その下流の子モデルを実行します。下流まで実行するのは、たとえばweeklyデータとdailyデータの両方に依存するモデルも忘れずにリフレッシュするためです。週次モデルを独立したサブグラフとして回す場合、日次ビルド側からはこれらを除外して、不要に再ビルドされないようにします。
1dbt build -s tag:daily+ --exclude tag:weekly
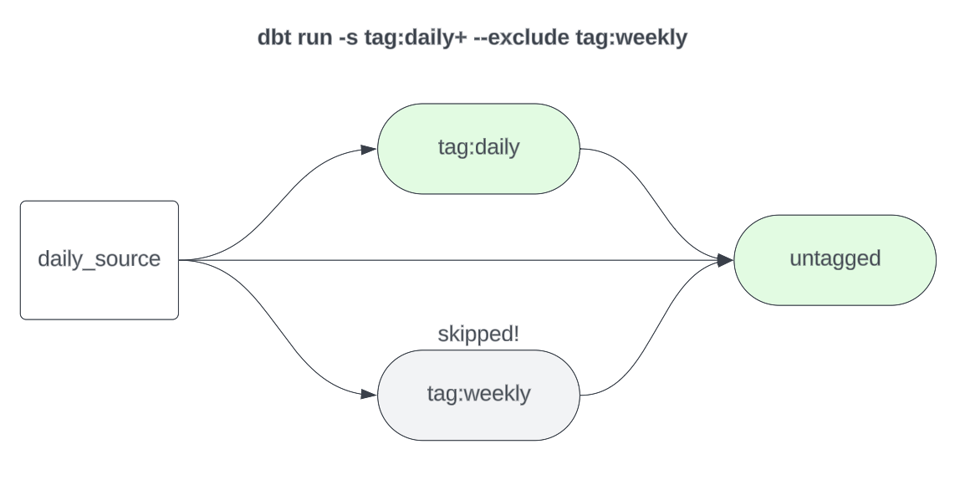
補足:プロジェクト内のすべてのモデルにリフレッシュ頻度のタグを付ける必要はありません。最も頻繁に走らせる「ベースライン」モデル(たとえば日次)はタグなしのまま残し、タグセレクタを指定せずにビルドする運用でも構いません。上の例ではわかりやすさのためにtag:dailyを使いましたが、このセレクタを使うのであれば--exclude tag:weeklyは本来不要です。一方、日次がベースラインの頻度で「日次」モデルにタグを付けない方針なら、週次モデルを明示的に除外する記述が必要になります。
留意点
- 「ここはインクリメンタル・マテリアライゼーションで済むのでは?」と思われるかもしれません。それも一つの選択肢ですが、タグほど汎用的ではありません。
tableマテリアライゼーションでロジックが複雑すぎてインクリメンタル化が難しいモデルもありますし、非決定的なロジックを含むためそもそもインクリメンタル化できないケースもあります。 - ソースのリフレッシュ頻度と、モデルのリフレッシュSLAを混同しない
- ソースが週次でしか更新されないからといって、その下流モデルも週次でしか動かさない、というのは早計です。よりすっきりした方法は、
source_status:fresher+セレクタやインクリメンタル・マテリアライゼーションを使って毎日実行を試みることです。こうしておけば、ソースがリフレッシュされた直後のdbt実行で確実に更新が反映されます。さもないと、週次ソースの更新と対応する週次モデルのビルドとの間に数日の「ラグ」が生じかねず、望ましい状態ではありません。
- ソースが週次でしか更新されないからといって、その下流モデルも週次でしか動かさない、というのは早計です。よりすっきりした方法は、
- セレクタの重複と冗長な再ビルド
- 上の図をよく見ると、下流の
untaggedモデルが両方のdbt実行で選択・ビルドされていることに気づくと思います。これは冗長です。 - とはいえ、多少の冗長性があっても、
weeklyタグのモデルを毎日実行するのに比べれば大幅な改善です。トレードオフは、下流のuntaggedモデルを週に1回だけ余分に再ビルドする点だけ(日次ビルドで1回、週次ビルドでさらに1回)。もちろん、このコスト対効果は、タグなしモデルと週次モデルの相対的なコストに左右されます。 - より洗練されたセレクタの組み合わせやDAG設計でさらに改善することもできますが、ここでは深入りしません。
- 上の図をよく見ると、下流の
まとめ:すべてを組み合わせる
本シリーズで紹介したCLIフラグとstateベースのセレクタを組み合わせることで、CI/CDやスケジュール実行コンテキストで極めてスリムなビルドを実現できます。
CI/CDコンテキスト
「変更されたすべてのモデルとその下流の子モデルをビルドし、上流の参照は本番DBDBT_PRODにdeferする。エラー発生時は即座に処理を中断する。」
1dbt build --fail-fast --defer --select state:modified+ --state .state
スケジュールコンテキスト
「前回ビルド以降にレコードが更新されたソースの下流モデルのうち、dailyタグが付いたものをビルドする。上流の参照は本番DBDBT_PRODにdeferし、エラー発生時は即座に処理を中断する。」
1dbt build --fail-fast --defer --select source_status:fresher+,tag:daily
その他の留意点
オブジェクトのクローン vs --deferによる遅延参照
本シリーズの第1回・第2回では、--defer CLIフラグのメリットの一部は、ゼロコピークローンで作成したオブジェクトでも得られるという考え方を取り上げました。空の実行用DBから本番DBへ上流参照をdeferする代わりに、対象オブジェクトをdbt実行前に実行用DBへクローンし、通常どおり参照する、というやり方です。
このアプローチは競合状態(race condition)に対する耐性が高いのが特長です。本番オブジェクトを「スナップショット」する(クローンする)クリティカルな区間が、--defer経由の参照に比べて圧倒的に短くて済むためです。別DBへ参照をdeferする方式では、ビルド中に予期せぬデプロイが入り、deferral DB側のオブジェクトが途中で変わってしまうリスクがあります。mainブランチのCI/CDビルド(マージ/デプロイ)のような「クリティカル」なdbt実行では、クローン方式の方が望ましい場合があります。
一方、クローン方式にも弱点はあります。元のオブジェクトが変わるたびにクローンを作り直す必要があること、そしてSnowflakeにおけるRBACの取り回しの難しさです。
マテリアライゼーション戦略
マテリアライゼーション戦略もスリムビルドの要となる要素です。これだけで一本のテーマになる話なので、本記事では詳細には立ち入りません。ただし、特にCI/CDコンテキストでフルリフレッシュを多用しすぎると、冗長なモデルビルドとコストの大きな温床になる、という点は押さえておきたいところです。--full-refreshフラグの使い方や、incrementalとtableマテリアライゼーションの使い分けは、実行コンテキストごとに丁寧に検討する必要があります。
おわりに
dbtモデルの実行・デプロイ方法は、ほとんど無数と言えるほど存在します。この柔軟性は大きな強みである一方、モデルが過剰にビルド・再ビルドされないよう管理する責任は開発者側に委ねられます。Snowflakeのようなデータウェアハウスでは、ちょっと油断するとすぐに計算コストが膨らんでしまうため、なおさら重要なポイントです。本記事で紹介したテクニックが、dbtの実行を上手にコントロールし、これからもスリムなビルドを保ち続けるための手がかりになれば幸いです。
Alex Caruso・Lead Data Platform Engineer at Entera
AlexはEnteraのLead Data Platform Engineerで、米国ニューヨークを拠点に活動しています。