In Best practice per i workflow dbt, Parte 1: concetti e slim local builds ho introdotto il concetto di build dbt "slim" e proposto alcuni esempi per lo sviluppo dbt in locale. Ho inoltre descritto i diversi "contesti di invocazione di dbt" (Local, CI/CD e Scheduled).
In Best practice per i workflow dbt, Parte 2: slim CI/CD builds ho descritto alcune tecniche per ottenere build snelle nelle pipeline CI/CD.
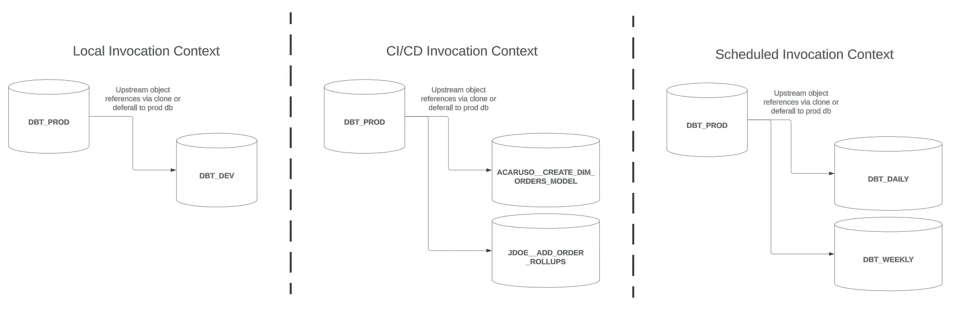
In questo articolo analizzeremo l'ultimo contesto di invocazione sulla destra, Scheduled, e vedremo alcune strategie per ottenere build snelle. Chiuderò con qualche considerazione aggiuntiva valida per tutti e tre i contesti di invocazione.
[@portabletext/react] Unknown block type "cta", specify a component for it in the `components.types` prop
Riepilogo della Parte 1: slim builds di dbt in locale
Le build dbt "slim" riducono al minimo le invocazioni di modelli ridondanti, superflue o errate. Quando invochiamo dbt, in genere puntiamo a uno di questi due obiettivi:
- Costruire, testare e validare modifiche al codice o alla logica delle risorse dbt (modelli, test, ecc.)
- Contesto di invocazione
LocaloCI/CD - Aggiornare i modelli al sopraggiungere di nuovi dati sorgente
- Contesto di invocazione
Scheduled
In entrambi i casi è quasi sempre sufficiente costruire un sottoinsieme ridotto del DAG. Per ogni invocazione di dbt esiste un insieme minimo di risorse necessarie a raggiungere l'obiettivo. Lo scopo delle slim builds è avvicinarsi il più possibile a quell'insieme minimo, per non sprecare tempo di calcolo e denaro su altre risorse.
Le build dbt in locale possono essere "snellite" per agire solo sulle risorse rilevanti tramite il flag CLI --defer, il flag CLI --empty o tecniche di row sampling.
Riepilogo della Parte 2: slim CI/CD
Le build CI/CD snelle si possono ottenere con il selettore state:modified+ o con il flag CLI --fail-fast. --defer è utilizzabile in alcuni contesti CI/CD, ma non in tutti.
Prerequisiti
- Ha letto fino alla sezione
Slim Local Buildsdi Best practice per i workflow dbt, Parte 1: concetti e slim local builds - Ha configurato la persistenza degli artefatti dbt, come descritto nella Parte 1
- Dispone di una pipeline di orchestrazione funzionante per invocare build dbt schedulate su un database o uno schema isolato nel proprio ambiente di destinazione
Slim scheduled builds
In un contesto di invocazione schedulata di dbt non avvengono modifiche al codice, ma solo aggiornamenti dei dati sorgente. Le decisioni su quali modelli costruire per una determinata invocazione dipendono quindi unicamente dalla frequenza di aggiornamento dei dati sorgente e dagli SLA di esposizione dei modelli a valle.
Selettore source_status:fresher+
dbt è in grado di rilevare la "freschezza" delle tabelle sorgente tramite il comando dbt source freshness. La "freschezza" di una tabella indica quando è stata aggiornata l'ultima volta, di solito sulla base di una colonna timestamp, e la differenza tra il valore massimo di quella colonna e una soglia SLA (giornaliera, settimanale, ecc.).
Se le sorgenti sono configurate come descritto nella documentazione linkata sopra (con le proprietà freshness e loaded_at_field), il comando dbt source freshness genera un artefatto sources.json che memorizza il valore max_loaded_at per ogni tabella sorgente. Lo si può usare insieme al selettore source_status:fresher+ per selezionare solo le sorgenti aggiornate rispetto all'ultima generazione dell'artefatto.
È utile per "snellire" le build schedulate ignorando i modelli a valle delle sorgenti che non hanno avuto aggiornamenti dall'ultima invocazione di dbt. Immagini, ad esempio, di avere una grande datasource che si aggiorna una sola volta a settimana, ma di eseguire anche una build dbt schedulata ogni notte. I modelli a valle di questa sorgente dovrebbero essere saltati 6 giorni su 7, a meno che non dipendano anche da altre sorgenti aggiornate con frequenza superiore alla settimanale.
Esempio
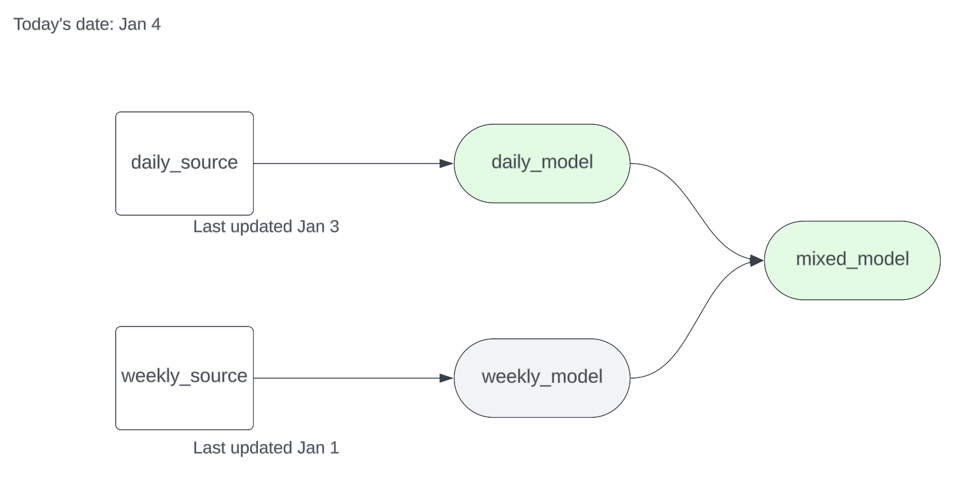
Supponga di avere due sorgenti, una aggiornata quotidianamente e l'altra settimanalmente, e alcuni modelli a valle. Dopo aver eseguito dbt source freshness, il suo artefatto source.json avrà questo aspetto:
1[\
\
2 {\
\
3 "unique_id": "source.projectname.sourcename.daily_source",\
\
4 "max_loaded_at": "2025-01-03T12:00:00.000000+00:00",\
\
5 ...\
\
6 },\
\
7 {\
\
8 "unique_id": "source.projectname.sourcename.weekly_source",\
\
9 "max_loaded_at": "2025-01-01T00:00:00.000000+00:00",\
\
10 ...\
\
11 }\
\
12]
La daily_source è stata aggiornata l'ultima volta il 3 gennaio a mezzogiorno, mentre la weekly_source il 1° gennaio a mezzanotte. Eseguendo dbt run -s source_status:fresher+ --state .state il 4 gennaio sul sottografo qui sotto, il modello a valle della sorgente settimanale verrà saltato.
Considerazioni
- Quando eseguire
dbt source freshness?- Va eseguito prima di ogni nuova invocazione dbt schedulata. L'artefatto
sources.jsonprodotto va reso persistente, in modo che le build dbt successive possano scaricarlo su disco e usarlo con il selettoresource_status:fresher+.
- Va eseguito prima di ogni nuova invocazione dbt schedulata. L'artefatto
- Verifichi che tutte le sorgenti abbiano definita la configurazione
freshnesseloaded_at_field- In caso contrario, dbt ignorerà queste sorgenti durante il comando
dbt source freshnesse non genererà alcun metadatomax_loaded_atnell'artefattosources.json. Di conseguenza, queste sorgenti verranno completamente ignorate anche dal selettoresource_status:fresher+. - Assicurarsi che tutte le sorgenti abbiano questa configurazione è un po' tedioso: il mio team la applica tramite una macro che ispeziona tutte le sorgenti e verifica che questi attributi siano definiti.
- In caso contrario, dbt ignorerà queste sorgenti durante il comando
Tagging dei modelli
Un altro modo per ottenere slim scheduled builds è il tagging dei modelli. Anziché eseguire tutti i modelli a ogni build schedulata, possiamo limitarci ai modelli o ai sottografi associati a un determinato tag. In un contesto di invocazione schedulata è comodo usare tag che richiamano uno SLA di aggiornamento, come daily, weekly o monthly.
Immagini ad esempio di avere alcuni modelli che alimentano report con SLA di aggiornamento settimanale. Devono essere pronti all'inizio della giornata lavorativa del lunedì mattina. Anche se lo SLA di aggiornamento è settimanale, i dati sorgente sottostanti si aggiornano in realtà ogni giorno.
Non possiamo usare il selettore source_status:fresher+ per saltare questi modelli, perché le sorgenti si aggiornano con frequenza superiore a quella richiesta dallo SLA del modello a valle.
Esempio
Consideri il seguente comando dbt build:
1dbt build -s tag:weekly+
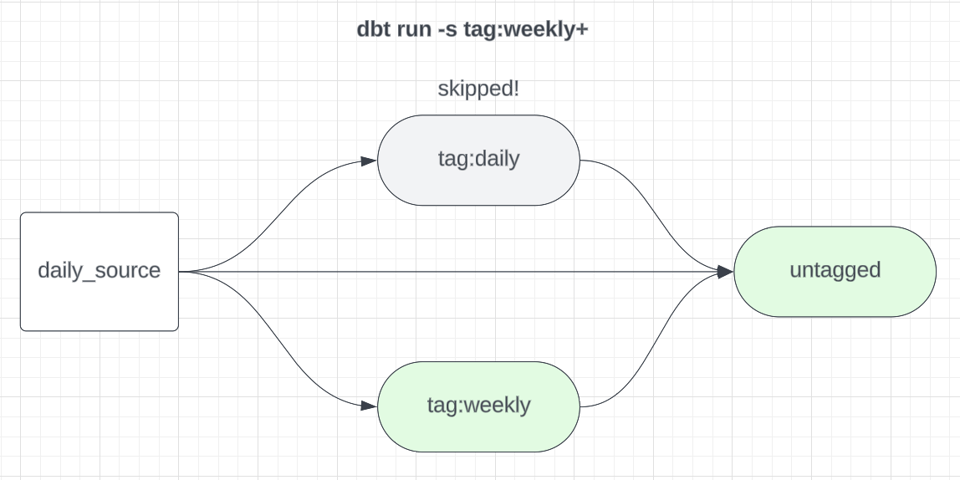
Verranno eseguiti tutti i modelli taggati weekly e i relativi discendenti a valle. Anche i discendenti vanno eseguiti per garantire che eventuali modelli che dipendono sia da dati weekly sia da dati daily, ad esempio, vengano aggiornati. Se eseguiamo i modelli settimanali come sottografo dedicato, conviene anche escluderli dalle build giornaliere, così da evitare ricostruzioni ripetute e inutili.
1dbt build -s tag:daily+ --exclude tag:weekly
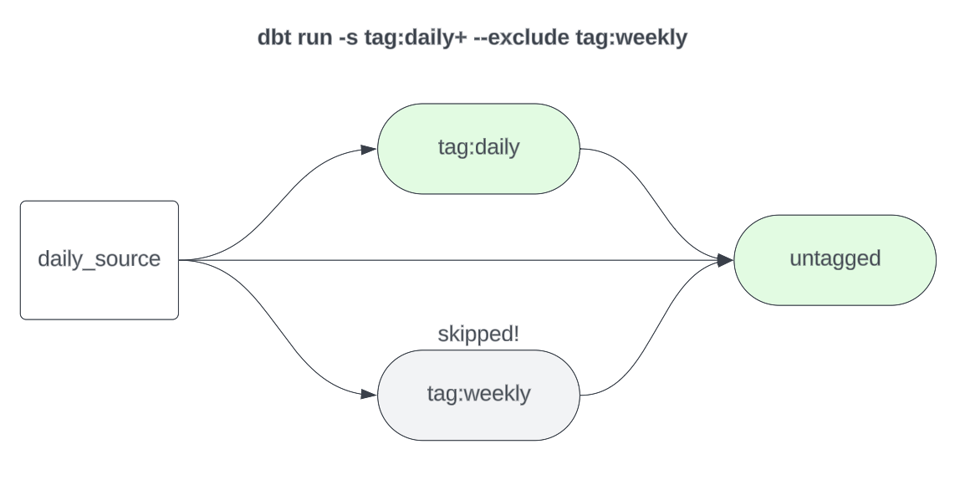
Nota: non è obbligatorio taggare ogni modello del progetto con una frequenza di aggiornamento. Può semplicemente lasciare senza tag i modelli "baseline", quelli eseguiti più di frequente (ad esempio ogni giorno), e costruirli senza alcun selettore di tag. Nell'esempio sopra ho usato tag:daily per chiarezza, ma se questo selettore è in uso, --exclude tag:weekly non è in realtà necessario. Tuttavia, se la sua frequenza di build baseline è giornaliera e i modelli "daily" non hanno tag, allora un'esclusione esplicita dei modelli settimanali diventa necessaria.
Considerazioni
- Forse si sta chiedendo: "perché non posso semplicemente usare una materializzazione incrementale?". È una soluzione possibile, ma non è generica come l'uso dei tag. Alcuni modelli potrebbero essere materializzati come
tablee risultare troppo complessi da incrementalizzare con facilità. Possono anche avere una logica non deterministica che rende impossibile l'incrementalizzazione. - Non confonda la frequenza di aggiornamento delle sorgenti con gli SLA di aggiornamento dei modelli
- Il fatto che una sorgente si aggiorni settimanalmente non significa che anche i suoi modelli a valle debbano essere eseguiti solo una volta a settimana. Una soluzione più pulita è provare a eseguirli ogni giorno, usando il selettore
source_status:fresher+o una materializzazione incrementale. In questo modo si ha la garanzia che vengano aggiornati alla prima invocazione di dbt successiva a un aggiornamento della sorgente. In caso contrario, potrebbe verificarsi un "ritardo" di più giorni tra l'aggiornamento di una sorgente settimanale e la build dei corrispondenti modelli settimanali, il che non è l'ideale.
- Il fatto che una sorgente si aggiorni settimanalmente non significa che anche i suoi modelli a valle debbano essere eseguiti solo una volta a settimana. Una soluzione più pulita è provare a eseguirli ogni giorno, usando il selettore
- Selettori di modelli sovrapposti e ricostruzioni ridondanti
- Avrà notato nei diagrammi sopra che il modello
untaggeda valle viene comunque selezionato e ricostruito da entrambi i comandi di invocazione di dbt. Si tratta di una ridondanza! - Non si preoccupi: nonostante questa ridondanza, resta un miglioramento netto rispetto all'esecuzione quotidiana dei modelli taggati
weekly. Il compromesso è dover ricostruire in modo ridondante il modellountaggeda valle una volta a settimana (una per la build giornaliera, una per quella settimanale). Naturalmente, questa analisi costi-benefici dipende dai costi relativi del modello untagged rispetto a quello settimanale. - Si può migliorare ulteriormente con pattern di selettori più sofisticati e architetture di DAG più evolute, ma non entrerò nel dettaglio in questa sede.
- Avrà notato nei diagrammi sopra che il modello
In sintesi: mettere tutto insieme
È possibile combinare diversi flag CLI e selettori basati sullo stato discussi in questa serie per ottenere build estremamente snelle nei contesti di invocazione CI/CD o Scheduled.
Contesto CI/CD
"Costruisci tutti i modelli modificati e i loro discendenti a valle, differendo i riferimenti a monte al database di produzione DBT_PROD. Fail fast in caso di errore."
1dbt build --fail-fast --defer --select state:modified+ --state .state
Contesto Scheduled
"Costruisci tutti i modelli a valle delle sorgenti con record aggiornati rispetto alla build precedente, se quei modelli sono taggati daily. Differisci i riferimenti a monte al database di produzione DBT_PROD e fail fast in caso di errore."
1dbt build --fail-fast --defer --select source_status:fresher+,tag:daily
Altre considerazioni
Cloni di oggetti vs riferimenti differiti tramite --defer
Sia nella Parte 1 sia nella Parte 2 di questa serie ho mostrato come alcuni dei vantaggi del flag CLI --defer si possano ottenere anche con oggetti clonati zero-copy. Anziché partire da un database di invocazione vuoto e differire i riferimenti a monte verso un database di produzione, gli oggetti possono essere clonati nel database di invocazione prima dell'esecuzione di dbt e poi referenziati normalmente.
Questa strategia offre una protezione maggiore contro le race condition, perché la sezione "critica" durante la quale gli oggetti di produzione vengono "fotografati" (clonati) è molto più ridotta rispetto ai riferimenti tramite --defer. Se si differiscono i riferimenti a un altro db, si corre il rischio che quegli oggetti nel db di deferral cambino a metà della build a causa di un deployment fuori banda. I cloni possono essere una scelta migliore per le invocazioni dbt "critiche", come quelle associate alle build CI/CD del branch main (merge / deploy).
La strategia di cloning ha anche degli svantaggi, in particolare il fatto che i cloni vanno ricreati ogni volta che gli oggetti sorgente cambiano, e le complicazioni legate all'RBAC in Snowflake.
Strategie di materializzazione
La strategia di materializzazione è un altro elemento fondamentale delle slim builds. È un argomento a sé, quindi non entrerò nel dettaglio. Detto questo, i team dovrebbero ricordare che un eccesso di build full refresh, soprattutto nei contesti CI/CD, è una delle principali cause di build ridondanti dei modelli e di spesa. L'uso del flag --full-refresh, così come la scelta tra materializzazioni incremental e table, va valutata con attenzione in ciascun contesto di invocazione.
Conclusioni
Le strategie per invocare e fare deploy dei modelli dbt sembrano davvero infinite. Questa flessibilità è un grande vantaggio, ma scarica anche sugli sviluppatori la responsabilità di evitare che i modelli vengano costruiti e ricostruiti in eccesso. È un aspetto particolarmente importante quando soluzioni di data warehouse come Snowflake rendono molto facile esagerare con la spesa di compute. Mi auguro che le tecniche illustrate in questo articolo la aiutino a gestire meglio le invocazioni di dbt e a mantenere snelle le sue build d'ora in avanti.
Alex Caruso·Lead Data Platform Engineer presso Entera
Alex è Lead Data Platform Engineer presso Entera, con sede a New York, Stati Uniti.