Bei den meisten Snowflake-Kunden machen die Compute-Kosten – also die Gebühren für Virtual Warehouses – den größten Posten auf der Rechnung aus. Um diese Ausgaben spürbar zu senken und die Kosten im Griff zu behalten, müssen teure Queries verlässlich identifiziert werden.
Snowflake rechnet 1 jede Sekunde ab, in der ein Virtual Warehouse läuft – mit einer Mindestabrechnung von 60 Sekunden bei jedem Wiederanlauf. Die Snowflake-Oberfläche zeigt die Kosten zwar pro Virtual Warehouse, schlüsselt die Ausgaben aber nicht bis auf Query-Ebene auf. Dieser Beitrag vergleicht verschiedene Wege, Warehouse-Kosten einzelnen Queries zuzuordnen – inklusive des nötigen Codes.
Wer direkt zur SQL-Implementierung des empfohlenen Ansatzes springen möchte, geht direkt ans Ende des Beitrags.
Der einfache Ansatz
Wir beginnen mit einem einfachen Ansatz: Die Ausführungszeit einer Query wird mit dem Abrechnungssatz des Warehouses multipliziert, auf dem sie lief. Beispiel: Eine Query läuft 10 Minuten auf einem Medium-Warehouse. Ein Medium-Warehouse kostet 4 Credits pro Stunde, und bei 3 USD pro Credit
2 ergibt das 2 USD für diese Query (10/60 Stunden * 4 Credits/Stunde * 3 USD/Credit).
SQL-Implementierung
In SQL lässt sich das über die View snowflake.account_usage.query_history umsetzen. Sie enthält alle Queries des letzten Jahres samt wichtiger Metadaten wie der Gesamtausführungszeit und der Größe des verwendeten Warehouses:
WITH
warehouse_sizes AS (
SELECT 'X-Small' AS warehouse_size, 1 AS credits_per_hour UNION ALL
SELECT 'Small' AS warehouse_size, 2 AS credits_per_hour UNION ALL
SELECT 'Medium' AS warehouse_size, 4 AS credits_per_hour UNION ALL
SELECT 'Large' AS warehouse_size, 8 AS credits_per_hour UNION ALL
SELECT 'X-Large' AS warehouse_size, 16 AS credits_per_hour UNION ALL
SELECT '2X-Large' AS warehouse_size, 32 AS credits_per_hour UNION ALL
SELECT '3X-Large' AS warehouse_size, 64 AS credits_per_hour UNION ALL
SELECT '4X-Large' AS warehouse_size, 128 AS credits_per_hour
)
SELECT
qh.query_id,
qh.query_text,
qh.execution_time/(1000*60*60)*wh.credits_per_hour AS query_cost
Code anzeigen
So bekommen wir für jede query_id die geschätzten Kosten. Damit mehrfach ausgeführte Queries im Zeitraum zusammenfließen, aggregieren wir über den query_text:
WITH
warehouse_sizes AS (
// wie oben
),
queries AS (
SELECT
qh.query_id,
qh.query_text,
qh.execution_time/(1000*60*60)*wh.credits_per_hour AS query_cost
FROM snowflake.account_usage.query_history AS qh
INNER JOIN warehouse_sizes AS wh
ON qh.warehouse_size=wh.warehouse_size
WHERE
start_time >= CURRENT_DATE - 30
)
Code anzeigen
Wo dieser Ansatz an seine Grenzen stößt
So eingängig dieser Weg ist – die größte Schwäche: Snowflake rechnet nicht pro Sekunde Query-Laufzeit ab, sondern pro Sekunde, in der das Warehouse läuft. Eine Query kann das Warehouse automatisch starten, 6 Sekunden lang laufen und es danach bis zur automatischen Abschaltung im Leerlauf stehen lassen. Auch diese Leerlaufzeit wird abgerechnet – und es kann sinnvoll sein, sie der auslösenden Query zuzurechnen. Genauso gilt: Laufen zwei Queries 20 Minuten parallel auf demselben Warehouse, berechnet Snowflake 20 Minuten, nicht 40. Leerlauf und Parallelität sind deshalb zentrale Faktoren bei der Kostenzuordnung und Optimierung.
Beim Aggregieren nach query_text haben wir zudem über den unbearbeiteten Query-Text gruppiert. In der Praxis fügen viele Systeme jeder Query individuelle Metadaten hinzu. Looker hängt zum Beispiel an jede Query einen Kontext an. Beim ersten Aufruf könnte das so aussehen:
SELECT
id,
created_at
FROM orders
-- Looker Query Context '{"user_id":181,"history_slug":"9dcf35a","instance_slug":"aab1f6"}'
Beim nächsten Lauf sehen diese Metadaten anders aus:
SELECT
id,
created_at
FROM orders
-- Looker Query Context '{"user_id":181,"history_slug":"1kal99e","instance_slug":"jju3q8"}'
Ähnlich verfährt dbt: Jede Query bekommt eine eindeutige invocation_id:
SELECT
id,
created_at
FROM orders
/*{
"app": "dbt",
"invocation_id": "52c47806ae6d",
"node_id": "model.jaffle_shop.orders",
...
}*/
Beim Gruppieren nach query_text werden die beiden Aufrufe oben nicht zusammengeführt, weil die Metadaten jeden Lauf einzigartig machen. Eine einzelne, leicht zu behebende Kostenquelle – etwa ein Dashboard – bleibt so unter Umständen unerkannt.
Wir können sogar noch einen Schritt weiter gehen und Kosten auf einer höheren Ebene bündeln. Ein dbt-Modell besteht oft aus mehreren Queries – etwa einem CREATE TEMPORARY TABLE gefolgt von einem MERGE. Ein Dashboard kann bei jedem Refresh 5 verschiedene Queries auslösen. Wer alle Queries einer Quelle gemeinsam betrachten kann, ordnet Ausgaben gezielter zu und priorisiert Optimierungen effizienter.
Mit diesen Punkten im Hinterkopf: Geht es besser?
Der neue Ansatz
Damit sich die summierten Query-Kosten am Ende mit der tatsächlichen Rechnung abgleichen lassen, muss man von den exakten Gebühren pro Warehouse ausgehen. Die stündliche Granularität ergibt sich aus snowflake.account_usage.warehouse_metering_history – der maßgeblichen Quelle für Warehouse-Kosten, die den Credit-Verbrauch stündlich ausweist. Wir berechnen, wie viele Sekunden jede Query innerhalb einer Stunde ausgeführt wurde, und verteilen die Credits anteilig auf die Queries entsprechend ihrem Anteil an der Gesamtausführungszeit. So wird Leerlaufzeit auf die Queries umgelegt, die in dem Zeitraum liefen. Parallelität ist ebenfalls berücksichtigt, denn je mehr Queries gleichzeitig laufen, desto niedriger fallen in der Regel die durchschnittlichen Kosten pro Query aus.
Ein Beispiel: Das TRANSFORMING_WAREHOUSE verbraucht in einer Stunde 100 Credits. In dieser Zeit laufen drei Queries: zwei je 10 Minuten und eine 20 Minuten – also 40 Minuten Gesamtausführungszeit. Die Credits werden dann so verteilt:
- Query 1 (10 Minuten) -> 25 Credits
- Query 2 (20 Minuten) -> 50 Credits
- Query 3 (10 Minuten) -> 25 Credits
Im Diagramm unten startet Query 3 zwischen 17:00 und 18:00 Uhr und endet nach 18:00 Uhr. Bei Queries, die sich über mehrere Stunden ziehen, zählen wir nur den Anteil, der in der jeweiligen Stunde lief.
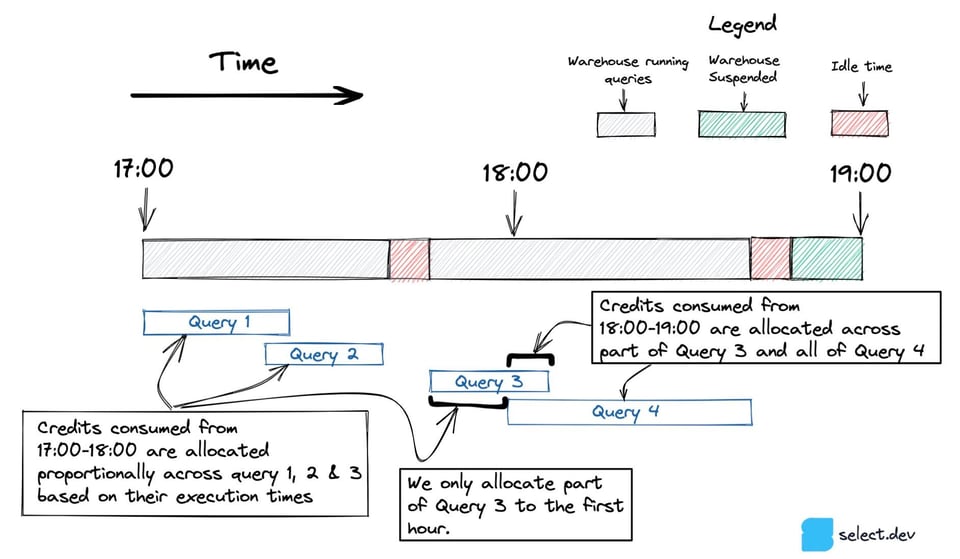
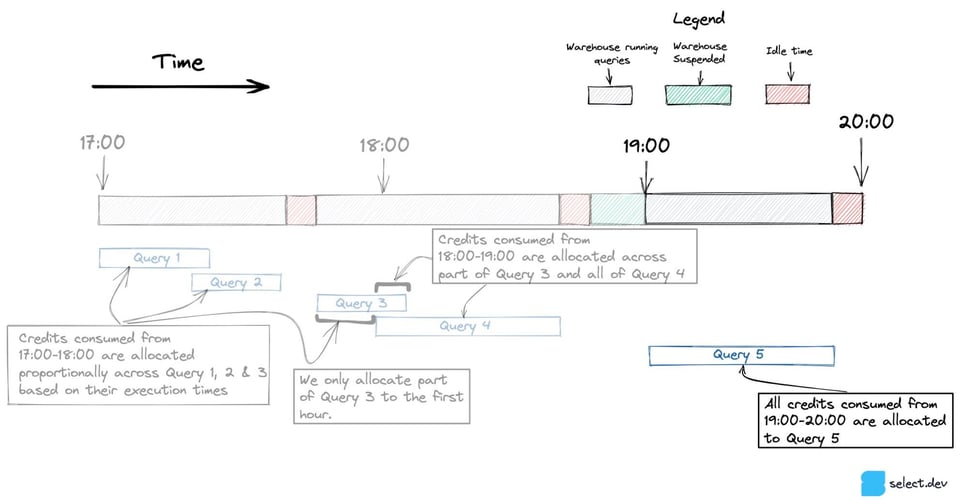
Läuft in einer Stunde nur eine einzige Query – wie Query 5 unten –, geht der gesamte Credit-Verbrauch auf ihr Konto, einschließlich der Credits, die das Warehouse im Leerlauf verbraucht hat.
SQL-Implementierung
Manche Queries laufen gar nicht auf einem Warehouse, sondern werden vollständig in der Cloud-Services-Schicht verarbeitet. Diese filtern wir mit warehouse_size IS NULL
3 heraus. Außerdem berechnen wir einen neuen Zeitstempel execution_start_time, der den exakten Moment markiert, in dem die Query auf dem Warehouse zu laufen begann
4.
SELECT
query_id,
query_text,
warehouse_id,
TIMEADD(
'millisecond',
queued_overload_time + compilation_time +
queued_provisioning_time + queued_repair_time +
list_external_files_time,
start_time
) AS execution_start_time,
end_time
FROM snowflake.account_usage.query_history AS q
WHERE TRUE
AND warehouse_size IS NOT NULL
AND start_time >= CURRENT_DATE - 30
Als Nächstes ermitteln wir, wie lange jede Query in welcher Stunde lief. Angenommen, wir haben zwei Queries: eine läuft innerhalb einer Stunde, die andere startet in einer Stunde und endet in der nächsten.
| query_id | execution_start_time | end_time |
|---|---|---|
| 123 | 2022-10-08 08:27:51.234 | 2022-10-08 08:30:20.812 |
| 456 | 2022-10-08 08:30:11.941 | 2022-10-08 09:01:56.000 |
Wir brauchen eine Tabelle mit einer Zeile pro Stunde, in der die Query lief.
| query_id | execution_start_time | end_time | hour_start | hour_end |
|---|---|---|---|---|
| 123 | 2022-10-08 08:27:51.234 | 2022-10-08 08:30:20.812 | 2022-10-08 08:00:00.000 | 2022-10-08 09:00:00.000 |
| 456 | 2022-10-08 08:30:11.941 | 2022-10-08 09:01:56.000 | 2022-10-08 08:00:00.000 | 2022-10-08 09:00:00.000 |
| 456 | 2022-10-08 08:30:11.941 | 2022-10-08 09:01:56.000 | 2022-10-08 09:00:00.000 | 2022-10-08 10:00:00.000 |
In SQL erzeugen wir dazu eine CTE hours_list mit einer Zeile pro Stunde im 30-Tage-Zeitraum. Anschließend führen wir einen Range Join mit den filtered_queries aus und erhalten die CTE query_hours mit einer Zeile pro Stunde, in der eine Query lief.
WITH
filtered_queries AS (
SELECT
query_id,
query_text,
warehouse_id,
TIMEADD(
'millisecond',
queued_overload_time + compilation_time +
queued_provisioning_time + queued_repair_time +
list_external_files_time,
start_time
) AS execution_start_time,
end_time
FROM snowflake.account_usage.query_history AS q
WHERE TRUE
AND warehouse_size IS NOT NULL
AND start_time >= DATEADD('day', -30, DATEADD('day', -1, CURRENT_DATE))
),
hours_list AS (
SELECT
DATEADD(
'hour',
'-' || row_number() over (order by null),
DATEADD('day', '+1', CURRENT_DATE)
) as hour_start,
DATEADD('hour', '+1', hour_start) AS hour_end
FROM TABLE(generator(rowcount => (24*31))) t
),
-- 1 Zeile pro Stunde, in der eine Query lief
query_hours AS (
SELECT
hl.hour_start,
hl.hour_end,
queries.*
FROM hours_list AS hl
INNER JOIN filtered_queries AS queries
ON hl.hour_start >= DATE_TRUNC('hour', queries.execution_start_time)
AND hl.hour_start < queries.end_time
),
Jetzt berechnen wir mit der DATEDIFF-Funktion, wie viele Millisekunden jede Query in jeder Stunde lief – und welchen Anteil sie an der Gesamtlaufzeit aller Queries hatte.
query_seconds_per_hour AS (
SELECT
*,
DATEDIFF('millisecond', GREATEST(execution_start_time, hour_start), LEAST(end_time, hour_end)) AS num_milliseconds_query_ran,
SUM(num_milliseconds_query_ran) OVER (PARTITION BY warehouse_id, hour_start) AS total_query_milliseconds_in_hour,
num_milliseconds_query_ran/total_query_milliseconds_in_hour AS fraction_of_total_query_time_in_hour,
hour_start AS hour
FROM query_hours
),
Zum Schluss holen wir die tatsächlich verbrauchten Credits aus snowflake.account_usage.warehouse_metering_history und verteilen sie entsprechend dem Anteil jeder Query an der Gesamtausführungszeit. Eine abschließende Aggregation bringt das Dataset zurück auf eine Zeile pro Query.
credits_billed_per_hour AS (
SELECT
start_time AS hour,
warehouse_id,
credits_used_compute
FROM snowflake.account_usage.warehouse_metering_history
),
query_cost AS (
SELECT
query.*,
credits.credits_used_compute*2.28 AS actual_warehouse_cost,
credits.credits_used_compute*fraction_of_total_query_time_in_hour*2.28 AS query_allocated_cost_in_hour
FROM query_seconds_per_hour AS query
INNER JOIN credits_billed_per_hour AS credits
ON query.warehouse_id=credits.warehouse_id
AND query.hour=credits.hour
)
-- Zurück auf 1 Zeile pro Query aggregieren
SELECT
query_id,
ANY_VALUE(MD5(query_text)) AS query_signature,
ANY_VALUE(query_text) AS query_text,
SUM(query_allocated_cost_in_hour) AS query_cost,
ANY_VALUE(warehouse_id) AS warehouse_id,
SUM(num_milliseconds_query_ran) / 1000 AS execution_time_s
FROM query_cost
GROUP BY 1
Den Query-Text aufbereiten
Wie weiter oben erwähnt, enthalten viele Queries individuelle Metadaten als Kommentare, die das Zusammenfassen identischer Queries erschweren. SQL-Kommentare gibt es in zwei Varianten:
- Einzeilige Kommentare, die mit
--beginnen - Einzeilige oder mehrzeilige Kommentare der Form
/* <Kommentartext> */
-- Dies ist ein gültiger SQL-Kommentar
SELECT
id,
total_price, -- Dieser auch
created_at /* Und dieser! */
FROM orders
/*
Auch das ist ein gültiger SQL-Kommentar.
Juhu!
*/
Beide Kommentarvarianten lassen sich mit Snowflakes Funktion REGEXP_REPLACE entfernen5.
SELECT
query_text AS original_query_text,
-- Zuerst entfernen wir Kommentare in /* <Kommentartext> */
REGEXP_REPLACE(query_text, '(/\*.*\*/)') AS _cleaned_query_text,
-- Danach einzeilige Kommentare, die mit -- beginnen
-- und entweder mit einem Zeilenumbruch oder dem Stringende enden
REGEXP_REPLACE(_cleaned_query_text, '(--.*$)|(--.*\n)') AS cleaned_query_text,
FROM snowflake.account_usage.query_history AS q
Jetzt können wir bei der Identifikation der teuersten Queries in einem Zeitraum nach cleaned_query_text aggregieren statt nach dem ursprünglichen query_text. Die finale SQL-Implementierung mit cleaned_query_text finden Sie im Anhang.
Wo dieser Ansatz noch besser werden kann
So deutlich diese Methode den einfachen Ansatz übertrifft – Luft nach oben bleibt. Die Credits für Warehouse-Leerlaufzeit verteilen sich aktuell auf alle Queries einer Stunde. Würde man Leerlaufkosten gezielt der Query bzw. den Queries zuordnen, die sie tatsächlich verursacht haben, gewänne das Modell an Genauigkeit – und damit an Nutzen für die Kostensenkung.
Auch die 60-Sekunden-Mindestabrechnung berücksichtigt der Ansatz nicht. Laufen in einer Stunde zwei voneinander getrennte Queries – eine 1 Sekunde, die andere 60 Sekunden –, erscheint die zweite 60-mal teurer als die erste, obwohl bereits die erste 60 Sekunden Credit-Verbrauch auslöst.
Auch die Aufbereitung des query_text bietet Raum für Verbesserungen. Inkrementelle Datenmodelle enthalten häufig hartcodierte Datumswerte, die sich bei jedem Lauf ändern. Zum Beispiel:
-- Query, ausgeführt am 2022-10-03
CREATE TEMPORARY TABLE orders AS (
SELECT
...
FROM orders
WHERE
created_at BETWEEN DATE'2022-10-01' AND DATE'2022-10-02'
)
Dasselbe Verhalten zeigen parametrisierte Dashboard-Queries. Ein Marketing-Dashboard kann etwa eine Template-Query bereitstellen:
SELECT
id,
email
FROM customers
WHERE
country_code = {{ selected_country_code }}
AND signup_date >= CURRENT_DATE - {{ signup_days_back }}
Bei jeder Ausführung wird diese Query mit anderen Werten befüllt:
SELECT
id,
email
FROM customers
WHERE
country_code = 'CA'
AND signup_date >= CURRENT_DATE - 90
Parametrisierte Queries lassen sich mit fortgeschrittener SQL-Textverarbeitung in den Griff bekommen; Leerlauf und Mindestabrechnung sind kniffliger. Am Ende geht es bei der Zuordnung von Warehouse-Kosten zu Queries darum, Nutzer:innen zu zeigen, wo sich der Optimierungsaufwand lohnt. Wir sind überzeugt, dass der vorgestellte Ansatz genau das leistet. Alle Modelle sind falsch, aber manche sind nützlich.
Geplante Weiterentwicklungen
Neben der genannten fortgeschrittenen SQL-Textverarbeitung haben wir noch weitere Verbesserungen auf der Roadmap:
- Übersteigen Cloud-Services-Credits 10 % Ihrer täglichen Compute-Credits, stellt Snowflake sie in Rechnung. Damit das Modell robuster wird, müssen wir die Cloud-Services-Credits jeder im Warehouse laufenden Query ebenso berücksichtigen wie die Queries, die in keinem Warehouse laufen. Simple Queries wie
SHOW TABLES, die ausschließlich in den Cloud Services laufen, können bei hoher Frequenz spürbar Credits verbrauchen. Wie Metabase-Metadaten-Queries pro Monat 500 USD an Cloud-Services-Credits kosteten, zeigt dieser Beitrag. - Das Modell soll künftig Kosten pro Daten-Asset statt nur pro Query berechnen. Für Kosten pro dbt-Modell müssen wir die dbt-JSON-Metadaten parsen, die dbt automatisch in jede SQL-Query einfügt. Denkbar ist auch eine Anbindung an BI-Tool-Metadaten, etwa um "Kosten pro Dashboard" zu ermitteln.
- Wir planen, diesen Code als neues dbt-Paket bereitzustellen, damit Nutzer:innen ihre Snowflake-Ausgaben noch einfacher transparent machen können.
Teure Queries identifizieren
Sobald Sie die Kosten pro Query berechnet und in einer neuen Tabelle (z. B. query_history_enriched) gespeichert haben, finden Sie die 100 teuersten Queries Ihres Accounts mit folgender Query:
with
max_date as (
select max(date(end_time)) as date
from query_history_enriched
)
select
md5(query_parameterized_hash) as query_parameterized_hash,
sum(query_cost) as total_cost_last_30d,
total_cost_last_30d*12 as estimated_annual_cost,
max_by(query_text, start_time) as latest_query_text,
max_by(warehouse_name, start_time) as latest_warehouse_name,
max_by(warehouse_size, start_time) as latest_warehouse_size,
max_by(query_id, start_time) as latest_query_id,
avg(execution_time/1000) as avg_execution_time_s,
count(*) as num_executions
Code anzeigen
Anmerkungen
Snowflake nutzt für die meisten abrechenbaren Dienste das Konzept der Credits. Solange Warehouses laufen, verbrauchen sie Credits. Mit jeder Verdoppelung der Warehouse-Größe verdoppelt sich auch der Credit-Verbrauch pro Stunde: Ein X-Small kostet 1 Credit pro Stunde, ein Small 2, ein Medium 4 und so weiter. Jeder Snowflake-Kunde zahlt einen festen Preis pro Credit – daraus errechnet sich der Betrag auf der monatlichen Rechnung.
Der Preis pro Credit hängt vom gewählten Plan (Standard, Enterprise, Business Critical etc.) und vom Vertrag ab. On-Demand-Kunden zahlen meist 2 USD/Credit im Standard und 3 USD/Credit im Enterprise-Plan. Mit einem Jahresvertrag bei Snowflake wird dieser Preis abhängig von der Menge der vorab gekauften Credits rabattiert. Alle Beispiele hier sind in US-Dollar.
Queries können auch ohne Warehouse laufen, indem sie die Metadaten der Cloud Services nutzen.
Bevor eine Query auf einem Warehouse läuft, sind mehrere Schritte nötig – etwa die Kompilierung in den Cloud Services und das Provisionieren des Warehouses. In einem späteren Beitrag steigen wir tief in den Lifecycle einer Snowflake-Query ein.
⚠️ Der REGEX
'(/\*.*\*/)'funktioniert nicht für zwei Kommentare in derselben Zeile, etwa/* hi */SELECT * FROM table/* hello there */.
Anhang
Vollständige SQL-Query
Für einen Snowflake-Account mit rund 9 Millionen Queries pro Monat lief die folgende Query 93 Sekunden auf einem X-Small-Warehouse.
WITH
filtered_queries AS (
SELECT
query_id,
query_text AS original_query_text,
-- Zuerst entfernen wir Kommentare in /* <Kommentartext> */
REGEXP_REPLACE(query_text, '(/\*.*\*/)') AS _cleaned_query_text,
-- Danach einzeilige Kommentare, die mit -- beginnen
-- und entweder mit einem Zeilenumbruch oder dem Stringende enden
REGEXP_REPLACE(_cleaned_query_text, '(--.*$)|(--.*\n)') AS cleaned_query_text,
warehouse_id,
TIMEADD(
'millisecond',
queued_overload_time + compilation_time +
Code anzeigen
Geprüfter Alternativansatz
Vor dem oben vorgestellten Ansatz hatten wir ein Verfahren erprobt, das Parallelität und Leerlaufzeit präziser abbildet – insbesondere bei Multi-Cluster-Warehouses. Statt von den tatsächlich pro Stunde abgerechneten Credits auszugehen, nutzte dieser Ansatz die View snowflake.account_usage.warehouse_events_history, um ein Dataset mit einer Zeile pro Sekunde aufzubauen, in der jedes Warehouse-Cluster aktiv war. In Kombination mit dem Wissen, welche Query auf welchem Warehouse-Cluster lief, lassen sich Credits damit präziser auf einzelne Query-Sets verteilen, wie das Diagramm unten zeigt.
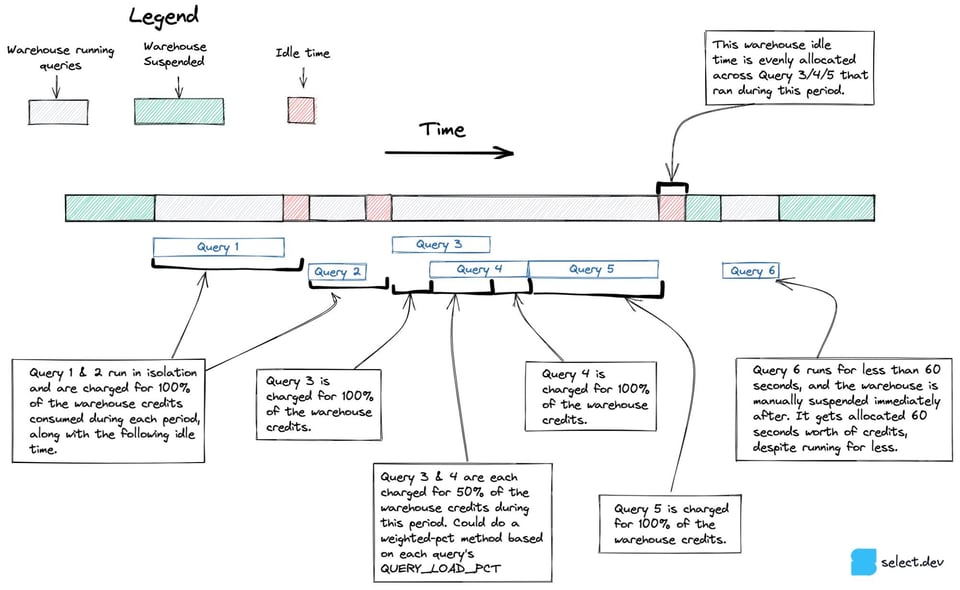
Leider zeigte sich, dass warehouse_events_history nicht exakt abbildet, wann jedes Warehouse-Cluster aktiv war – deshalb haben wir diesen Ansatz verworfen.
Ian Whitestone · Co-Founder & CEO von SELECT
Ian ist Co-Founder und CEO von SELECT, einer SaaS-Plattform für Snowflake-Kostenmanagement und -Optimierung. Vor SELECT hat er sechs Jahre lang Full-Stack-Data-Science- und Engineering-Teams bei Shopify und Capital One geleitet. Bei Shopify verantwortete er die Optimierung des Data Warehouses und baute die Kostentransparenz aus.