Per la maggior parte dei clienti Snowflake, i costi di compute (gli addebiti dei virtual warehouse) rappresentano la voce più consistente della fattura. Per ridurre efficacemente questa spesa e tenere sotto controllo i costi, è indispensabile individuare con precisione le query più onerose.
I clienti Snowflake vengono fatturati 1 per ogni secondo di attività dei virtual warehouse, con un addebito minimo di 60 secondi a ogni ripresa. L'interfaccia di Snowflake mostra oggi una ripartizione dei costi per singolo virtual warehouse, ma non attribuisce la spesa a un livello più granulare, cioè per singola query. Questo articolo propone una panoramica dettagliata e un confronto tra i diversi modi di attribuire i costi dei warehouse alle query, con il codice necessario per farlo.
Se preferisce passare direttamente all'implementazione SQL dell'approccio consigliato, vada pure alla fine!
Approccio semplice
Partiamo da un approccio semplice, che moltiplica il tempo di esecuzione di una query per la tariffa di fatturazione del warehouse su cui è stata eseguita. Supponiamo, ad esempio, che una query sia stata eseguita per 10 minuti su un warehouse di dimensione Medium. Un warehouse Medium costa 4 crediti l'ora e, con un costo di 3 $ per credito
2, possiamo dire che la query costa 2 $ (10/60 ore * 4 crediti / ora * 3 $/credito).
Implementazione SQL
Possiamo implementarlo in SQL sfruttando la vista snowflake.account_usage.query_history, che contiene tutte le query dell'ultimo anno insieme a metadati chiave come il tempo totale di esecuzione e la dimensione del warehouse su cui la query è stata eseguita:
WITH
warehouse_sizes AS (
SELECT 'X-Small' AS warehouse_size, 1 AS credits_per_hour UNION ALL
SELECT 'Small' AS warehouse_size, 2 AS credits_per_hour UNION ALL
SELECT 'Medium' AS warehouse_size, 4 AS credits_per_hour UNION ALL
SELECT 'Large' AS warehouse_size, 8 AS credits_per_hour UNION ALL
SELECT 'X-Large' AS warehouse_size, 16 AS credits_per_hour UNION ALL
SELECT '2X-Large' AS warehouse_size, 32 AS credits_per_hour UNION ALL
SELECT '3X-Large' AS warehouse_size, 64 AS credits_per_hour UNION ALL
SELECT '4X-Large' AS warehouse_size, 128 AS credits_per_hour
)
SELECT
qh.query_id,
qh.query_text,
qh.execution_time/(1000*60*60)*wh.credits_per_hour AS query_cost
Espandi codice
Otteniamo così una stima del costo per ciascun query_id. Per tenere conto del fatto che la stessa query venga eseguita più volte nello stesso periodo, possiamo aggregare per query_text:
WITH
warehouse_sizes AS (
// come sopra
),
queries AS (
SELECT
qh.query_id,
qh.query_text,
qh.execution_time/(1000*60*60)*wh.credits_per_hour AS query_cost
FROM snowflake.account_usage.query_history AS qh
INNER JOIN warehouse_sizes AS wh
ON qh.warehouse_size=wh.warehouse_size
WHERE
start_time >= CURRENT_DATE - 30
)
Espandi codice
Margini di miglioramento
Per quanto semplice e intuitivo, il limite principale di questo approccio è che Snowflake non addebita i secondi di esecuzione della query, bensì ogni secondo di attività del warehouse. Una query può riattivare automaticamente il warehouse, durare 6 secondi e poi lasciarlo inattivo finché non viene sospeso. Snowflake fattura anche questo tempo di inattività e per questo può essere utile "ribaltarne" il costo sulla query. Allo stesso modo, se due query vengono eseguite in parallelo sullo stesso warehouse per 20 minuti, Snowflake fatturerà 20 minuti, non 40. Inattività e concorrenza sono quindi fattori centrali nell'attribuzione e nell'ottimizzazione dei costi.
Aggregando per query_text per ottenere il costo totale del periodo, abbiamo raggruppato in base al testo della query non elaborato. Nella pratica, è frequente che i sistemi che generano queste query inseriscano metadati univoci in ciascuna di esse. Looker, ad esempio, aggiunge del contesto a ogni query. Alla prima esecuzione, una query può apparire così:
SELECT
id,
created_at
FROM orders
-- Looker Query Context '{"user_id":181,"history_slug":"9dcf35a","instance_slug":"aab1f6"}'
All'esecuzione successiva, questi metadati saranno diversi:
SELECT
id,
created_at
FROM orders
-- Looker Query Context '{"user_id":181,"history_slug":"1kal99e","instance_slug":"jju3q8"}'
Allo stesso modo, anche dbt aggiunge i propri metadati, assegnando a ogni query un invocation_id univoco:
SELECT
id,
created_at
FROM orders
/*{
"app": "dbt",
"invocation_id": "52c47806ae6d",
"node_id": "model.jaffle_shop.orders",
...
}*/
Raggruppando per query_text, le due occorrenze della query precedente non risulteranno collegate, perché questi metadati rendono ciascuna unica. Il risultato è che una singola fonte di query costose facilmente risolvibile (ad esempio un dashboard) può sfuggire all'analisi.
Potremmo voler spingerci oltre e raggruppare i costi a un livello ancora superiore. I modelli dbt spesso comprendono più query eseguite in sequenza: un CREATE TEMPORARY TABLE seguito da uno statement MERGE. Un dashboard può lanciare 5 query diverse a ogni aggiornamento. Riuscire a raggruppare l'intero insieme di query con la stessa origine è estremamente utile per attribuire la spesa e indirizzare poi gli interventi di ottimizzazione in modo efficiente.
Considerate queste opportunità, possiamo fare di meglio?
Un nuovo approccio
Per poter riconciliare il totale dei costi attribuiti alle query con la fattura finale, è fondamentale partire dagli addebiti esatti di ciascun warehouse. La scelta di una granularità oraria deriva da snowflake.account_usage.warehouse_metering_history, fonte di riferimento per gli addebiti dei warehouse, che riporta il consumo di crediti su base oraria. Possiamo quindi calcolare quanti secondi ciascuna query è rimasta in esecuzione nell'ora e allocare proporzionalmente i crediti a ogni query in base alla sua quota sul tempo totale di esecuzione. Così facendo, terremo conto del tempo di inattività distribuendolo tra le query eseguite nel periodo. Anche la concorrenza sarà gestita correttamente, perché un maggior numero di query in esecuzione tende ad abbassare il costo medio per query.
Vediamolo con un esempio: supponiamo che il TRANSFORMING_WAREHOUSE abbia consumato 100 crediti in un'ora. In quel lasso di tempo sono state eseguite tre query, due da 10 minuti e una da 20, per un totale di 40 minuti di esecuzione. In questo scenario allocheremmo i crediti a ciascuna query nel modo seguente:
- Query 1 (10 minuti) -> 25 crediti
- Query 2 (20 minuti) -> 50 crediti
- Query 3 (10 minuti) -> 25 crediti
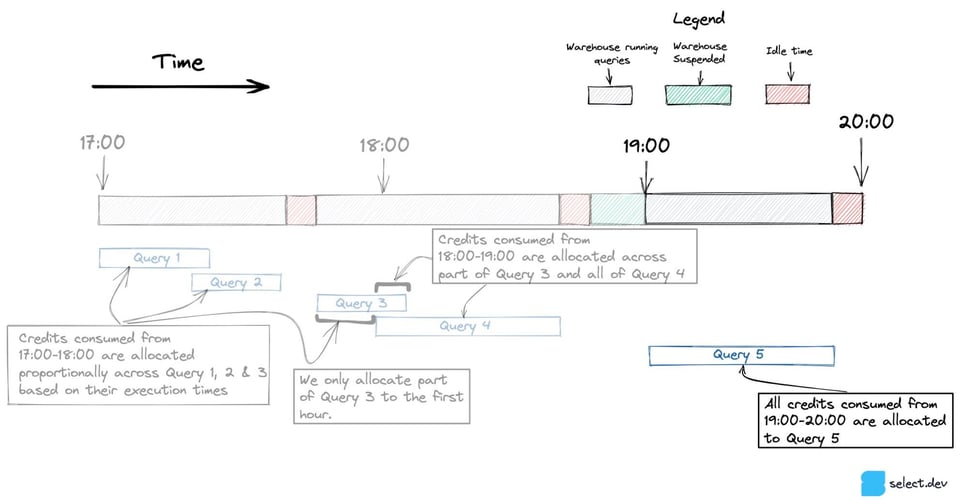
Nel diagramma sottostante, la query 3 inizia tra le 17:00 e le 18:00 e termina dopo le 18:00. Per gestire le query che si estendono su più ore, includiamo solo la porzione di query eseguita in ciascuna ora.
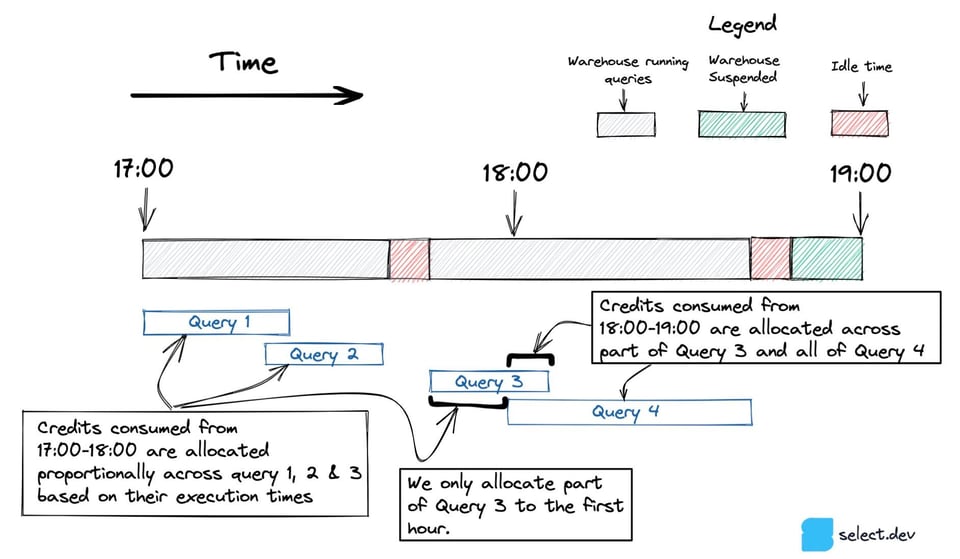
Quando in un'ora viene eseguita una sola query, come la Query 5 nell'immagine seguente, tutto il consumo di crediti viene attribuito a quell'unica query, compresi i crediti consumati dal warehouse rimasto inattivo.
Implementazione SQL
Alcune query non vengono eseguite su un warehouse, ma sono elaborate interamente dal livello dei cloud services. Per filtrarle escludiamo le query con warehouse_size IS NULL
3. Calcoliamo inoltre un nuovo timestamp, execution_start_time, per indicare l'istante esatto in cui la query ha iniziato a essere eseguita sul warehouse
4.
SELECT
query_id,
query_text,
warehouse_id,
TIMEADD(
'millisecond',
queued_overload_time + compilation_time +
queued_provisioning_time + queued_repair_time +
list_external_files_time,
start_time
) AS execution_start_time,
end_time
FROM snowflake.account_usage.query_history AS q
WHERE TRUE
AND warehouse_size IS NOT NULL
AND start_time >= CURRENT_DATE - 30
A questo punto dobbiamo determinare per quanto tempo ciascuna query è stata eseguita in ogni ora. Supponiamo di avere due query: una eseguita interamente all'interno di un'ora e una iniziata in un'ora e conclusa in quella successiva.
| query_id | execution_start_time | end_time |
|---|---|---|
| 123 | 2022-10-08 08:27:51.234 | 2022-10-08 08:30:20.812 |
| 456 | 2022-10-08 08:30:11.941 | 2022-10-08 09:01:56.000 |
Dobbiamo generare una tabella con una riga per ciascuna ora in cui la query è stata eseguita.
| query_id | execution_start_time | end_time | hour_start | hour_end |
|---|---|---|---|---|
| 123 | 2022-10-08 08:27:51.234 | 2022-10-08 08:30:20.812 | 2022-10-08 08:00:00.000 | 2022-10-08 09:00:00.000 |
| 456 | 2022-10-08 08:30:11.941 | 2022-10-08 09:01:56.000 | 2022-10-08 08:00:00.000 | 2022-10-08 09:00:00.000 |
| 456 | 2022-10-08 08:30:11.941 | 2022-10-08 09:01:56.000 | 2022-10-08 09:00:00.000 | 2022-10-08 10:00:00.000 |
Per ottenerlo in SQL generiamo una CTE, hours_list, con 1 riga per ciascuna ora nell'intervallo di 30 giorni che stiamo considerando. Eseguiamo poi un range join con filtered_queries per ottenere una CTE, query_hours, con 1 riga per ogni ora in cui una query è stata in esecuzione.
WITH
filtered_queries AS (
SELECT
query_id,
query_text,
warehouse_id,
TIMEADD(
'millisecond',
queued_overload_time + compilation_time +
queued_provisioning_time + queued_repair_time +
list_external_files_time,
start_time
) AS execution_start_time,
end_time
FROM snowflake.account_usage.query_history AS q
WHERE TRUE
AND warehouse_size IS NOT NULL
AND start_time >= DATEADD('day', -30, DATEADD('day', -1, CURRENT_DATE))
),
hours_list AS (
SELECT
DATEADD(
'hour',
'-' || row_number() over (order by null),
DATEADD('day', '+1', CURRENT_DATE)
) as hour_start,
DATEADD('hour', '+1', hour_start) AS hour_end
FROM TABLE(generator(rowcount => (24*31))) t
),
-- 1 riga per ogni ora in cui una query è stata eseguita
query_hours AS (
SELECT
hl.hour_start,
hl.hour_end,
queries.*
FROM hours_list AS hl
INNER JOIN filtered_queries AS queries
ON hl.hour_start >= DATE_TRUNC('hour', queries.execution_start_time)
AND hl.hour_start < queries.end_time
),
Ora possiamo calcolare il numero di millisecondi di esecuzione di ciascuna query all'interno di ogni ora, oltre alla loro quota relativa rispetto a tutte le query, sfruttando la funzione DATEDIFF.
query_seconds_per_hour AS (
SELECT
*,
DATEDIFF('millisecond', GREATEST(execution_start_time, hour_start), LEAST(end_time, hour_end)) AS num_milliseconds_query_ran,
SUM(num_milliseconds_query_ran) OVER (PARTITION BY warehouse_id, hour_start) AS total_query_milliseconds_in_hour,
num_milliseconds_query_ran/total_query_milliseconds_in_hour AS fraction_of_total_query_time_in_hour,
hour_start AS hour
FROM query_hours
),
Infine recuperiamo i crediti effettivamente utilizzati da snowflake.account_usage.warehouse_metering_history e li allochiamo a ciascuna query in base alla quota di tempo di esecuzione totale a cui ha contribuito. Effettuiamo un'ultima aggregazione per riportare il dataset a una riga per query.
credits_billed_per_hour AS (
SELECT
start_time AS hour,
warehouse_id,
credits_used_compute
FROM snowflake.account_usage.warehouse_metering_history
),
query_cost AS (
SELECT
query.*,
credits.credits_used_compute*2.28 AS actual_warehouse_cost,
credits.credits_used_compute*fraction_of_total_query_time_in_hour*2.28 AS query_allocated_cost_in_hour
FROM query_seconds_per_hour AS query
INNER JOIN credits_billed_per_hour AS credits
ON query.warehouse_id=credits.warehouse_id
AND query.hour=credits.hour
)
-- Aggregazione finale a 1 riga per query
SELECT
query_id,
ANY_VALUE(MD5(query_text)) AS query_signature,
ANY_VALUE(query_text) AS query_text,
SUM(query_allocated_cost_in_hour) AS query_cost,
ANY_VALUE(warehouse_id) AS warehouse_id,
SUM(num_milliseconds_query_ran) / 1000 AS execution_time_s
FROM query_cost
GROUP BY 1
Elaborazione del testo della query
Come anticipato in precedenza, molte query contengono metadati personalizzati aggiunti come commenti, che limitano la nostra capacità di raggruppare query identiche. I commenti in SQL possono presentarsi in due forme:
- Commenti su una sola riga che iniziano con
-- - Commenti su una o più righe nella forma
/* <testo del commento> */
-- Questo è un commento SQL valido
SELECT
id,
total_price, -- Anche questo lo è
created_at /* E anche questo! */
FROM orders
/*
Anche questo è un commento SQL valido.
Evvai!
*/
Entrambi i tipi di commento possono essere rimossi con la funzione REGEXP_REPLACE di Snowflake5.
SELECT
query_text AS original_query_text,
-- Per prima cosa rimuoviamo i commenti racchiusi tra /* <testo del commento> */
REGEXP_REPLACE(query_text, '(/\*.*\*/)') AS _cleaned_query_text,
-- Poi rimuoviamo i commenti su una sola riga che iniziano con --
-- e terminano con un a capo o con la fine della stringa
REGEXP_REPLACE(_cleaned_query_text, '(--.*$)|(--.*\n)') AS cleaned_query_text,
FROM snowflake.account_usage.query_history AS q
Ora possiamo aggregare per cleaned_query_text invece che per il query_text originale quando individuiamo le query più costose in un determinato intervallo temporale. Per la versione definitiva dell'implementazione SQL basata su cleaned_query_text, vada all'appendice.
Margini di miglioramento
Pur rappresentando un netto passo avanti rispetto all'approccio semplice, questo metodo ha ancora margini di miglioramento. I crediti associati al tempo di inattività del warehouse vengono distribuiti su tutte le query eseguite in una determinata ora. Attribuire la spesa di inattività solo alla query (o alle query) che l'hanno effettivamente generata migliorerebbe l'accuratezza del modello e, di conseguenza, la sua efficacia nell'orientare le iniziative di riduzione dei costi.
Questo approccio non tiene inoltre conto dell'addebito minimo di fatturazione di 60 secondi. Se in una determinata ora vengono eseguite separatamente due query, una da 1 secondo e una da 60 secondi, la seconda risulterà 60 volte più costosa della prima, anche se la prima ha comunque consumato 60 secondi di crediti.
Anche la tecnica di elaborazione di query_text presenta margini di miglioramento. Non è raro che i modelli di dati incrementali generino date hardcoded nel codice SQL, che cambiano a ogni esecuzione. Ad esempio:
-- Query eseguita il 2022-10-03
CREATE TEMPORARY TABLE orders AS (
SELECT
...
FROM orders
WHERE
created_at BETWEEN DATE'2022-10-01' AND DATE'2022-10-02'
)
Lo stesso comportamento si osserva nelle query parametrizzate dei dashboard. Un dashboard di marketing, ad esempio, può esporre una query con template:
SELECT
id,
email
FROM customers
WHERE
country_code = {{ selected_country_code }}
AND signup_date >= CURRENT_DATE - {{ signup_days_back }}
A ogni esecuzione, la stessa query viene popolata con valori diversi:
SELECT
id,
email
FROM customers
WHERE
country_code = 'CA'
AND signup_date >= CURRENT_DATE - 90
Le query parametrizzate possono essere gestite con un'elaborazione del testo SQL più avanzata, mentre i tempi di inattività e di fatturazione minima sono più ostici da trattare. In fondo, lo scopo dell'attribuzione dei costi del warehouse alle query è aiutare gli utenti a capire su cosa concentrare il proprio tempo. Con questo approccio, siamo convinti che l'obiettivo possa essere raggiunto. Tutti i modelli sono sbagliati, ma alcuni sono utili.
Miglioramenti previsti per il futuro
Oltre all'elaborazione SQL del testo più avanzata di cui sopra, abbiamo in programma altri miglioramenti per questo approccio:
- Se i crediti dei cloud services superano il 10% dei crediti di compute giornalieri, Snowflake inizia ad addebitarli. Per rendere il modello più solido, dobbiamo tenere conto dei crediti dei cloud services associati a ciascuna query eseguita in un warehouse, oltre che delle query eseguite senza alcun warehouse. Query semplici come
SHOW TABLES, che vengono eseguite solo nei cloud services, possono finire per consumare crediti se vengono lanciate molto di frequente. Veda questo post su come le query di metadati di Metabase costavano 500 $ al mese in crediti cloud services. - Estendere il modello per calcolare il costo per data asset, anziché il costo per query. Per calcolare il costo per modello dbt occorrerà fare il parsing dei metadati JSON di dbt iniettati automaticamente in ogni query SQL generata da dbt. Potrebbe anche prevedere il collegamento ai metadati degli strumenti di BI per calcolare valori come il "costo per dashboard".
- Abbiamo in programma di racchiudere questo codice in un nuovo pacchetto dbt, così che gli utenti possano ottenere facilmente una maggiore visibilità sulla spesa Snowflake
Come individuare le query più costose
Una volta calcolato il costo per query e salvato in una nuova tabella (ad esempio query_history_enriched), può individuare rapidamente le 100 query più costose del proprio account eseguendo la query seguente:
with
max_date as (
select max(date(end_time)) as date
from query_history_enriched
)
select
md5(query_parameterized_hash) as query_parameterized_hash,
sum(query_cost) as total_cost_last_30d,
total_cost_last_30d*12 as estimated_annual_cost,
max_by(query_text, start_time) as latest_query_text,
max_by(warehouse_name, start_time) as latest_warehouse_name,
max_by(warehouse_size, start_time) as latest_warehouse_size,
max_by(query_id, start_time) as latest_query_id,
avg(execution_time/1000) as avg_execution_time_s,
count(*) as num_executions
Espandi codice
Note
Snowflake utilizza il concetto di crediti per la maggior parte dei suoi servizi fatturabili. Quando sono in esecuzione, i warehouse consumano crediti. Il ritmo con cui i crediti vengono consumati raddoppia a ogni aumento della dimensione del warehouse. Un warehouse X-Small costa 1 credito l'ora, uno Small 2 crediti l'ora, uno Medium 4 crediti l'ora e così via. Ciascun cliente Snowflake paga una tariffa fissa per credito, dalla quale si ricava poi il valore finale in dollari sulla fattura mensile.
Il costo per credito varia in base al piano sottoscritto (Standard, Enterprise, Business Critical, ecc.) e al contratto. I clienti on demand pagano in genere 2 $/credito per Standard e 3 $/credito per Enterprise. Sottoscrivendo un contratto annuale con Snowflake, la tariffa viene scontata in base al numero di crediti acquistati in anticipo. Tutti gli esempi qui riportati sono in dollari americani.
È possibile che alcune query vengano eseguite senza un warehouse, sfruttando i metadati nei cloud services.
Prima che una query possa iniziare a essere eseguita in un warehouse devono verificarsi diverse operazioni, come la compilazione della query nei cloud services e il provisioning del warehouse. In un futuro articolo approfondiremo il ciclo di vita di una query Snowflake.
⚠️, la REGEX
'(/\*.*\*/)'non funziona con due commenti sulla stessa riga, come/* hi */SELECT * FROM table/* hello there */
Appendice
Query SQL completa
Per un account Snowflake con circa 9 milioni di query al mese, la query seguente ha impiegato 93 secondi su un warehouse X-Small.
WITH
filtered_queries AS (
SELECT
query_id,
query_text AS original_query_text,
-- Per prima cosa rimuoviamo i commenti racchiusi tra /* <testo del commento> */
REGEXP_REPLACE(query_text, '(/\*.*\*/)') AS _cleaned_query_text,
-- Poi rimuoviamo i commenti su una sola riga che iniziano con --
-- e terminano con un a capo o con la fine della stringa
REGEXP_REPLACE(_cleaned_query_text, '(--.*$)|(--.*\n)') AS cleaned_query_text,
warehouse_id,
TIMEADD(
'millisecond',
queued_overload_time + compilation_time +
Espandi codice
Approccio alternativo valutato
Prima di scegliere l'approccio finale presentato sopra, abbiamo valutato un metodo capace di gestire concorrenza e tempo di inattività in modo più accurato, soprattutto con i warehouse multi-cluster. Invece di partire dai crediti effettivamente addebitati per ora, questo approccio sfruttava la vista snowflake.account_usage.warehouse_events_history per costruire un dataset con 1 riga per ogni secondo in cui ciascun cluster del warehouse era attivo. Combinando questo dataset con l'informazione su quale query è stata eseguita su quale cluster, è possibile attribuire i crediti a ciascun insieme di query con maggiore precisione, come mostrato nel diagramma seguente.
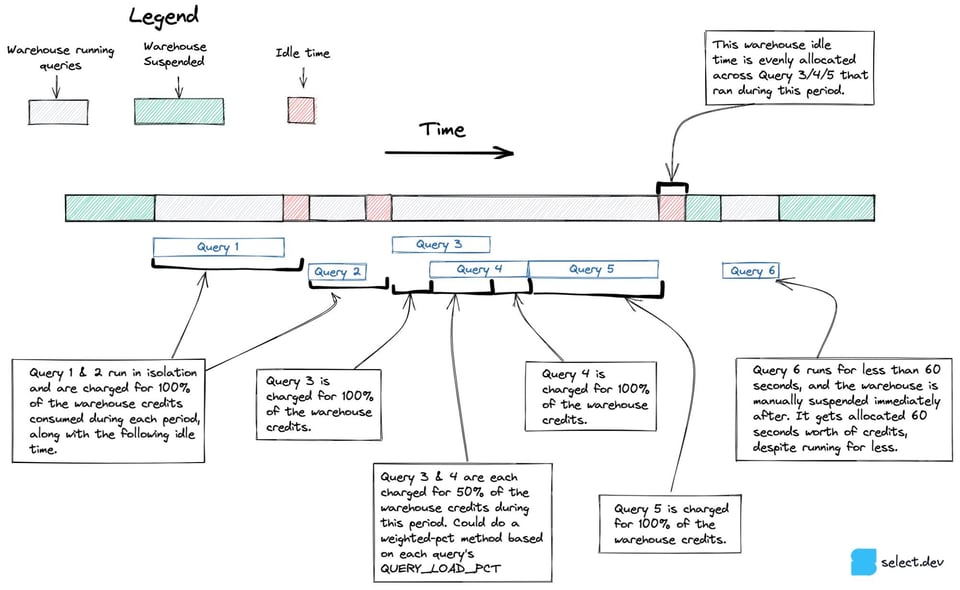
Purtroppo è emerso che warehouse_events_history non offre una rappresentazione perfetta dei periodi di attività di ciascun cluster del warehouse e per questo abbiamo abbandonato l'approccio.
Ian Whitestone·Co-founder & CEO di SELECT
Ian è Co-founder & CEO di SELECT, una piattaforma SaaS per la gestione e l'ottimizzazione dei costi di Snowflake. Prima di fondare SELECT, Ian ha guidato per 6 anni team full stack di data science & engineering in Shopify e Capital One. In Shopify ha coordinato le attività di ottimizzazione del data warehouse e di miglioramento dell'osservabilità dei costi.