Para a maioria dos clientes do Snowflake, os custos de computação (as cobranças dos virtual warehouses) representam a maior fatia da fatura. Para reduzir esse gasto de forma eficaz e gerenciar os custos, é preciso identificar com precisão as queries mais caras.
Os clientes do Snowflake pagam 1 por cada segundo em que os virtual warehouses ficam ativos, com cobrança mínima de 60 segundos sempre que um warehouse é retomado. Hoje, a interface do Snowflake mostra um detalhamento de custo por virtual warehouse, mas não atribui o gasto em um nível mais granular, por query. Este post traz uma visão detalhada e a comparação de diferentes formas de atribuir os custos de warehouse às queries, com o código necessário para isso.
Se você quiser pular direto para a implementação em SQL da abordagem recomendada, vá direto para o final!
Abordagem simples
Vamos começar com uma abordagem simples: multiplicar o tempo de execução de uma query pela taxa de cobrança do warehouse em que ela rodou. Por exemplo, digamos que uma query rodou por 10 minutos em um warehouse de tamanho medium. Um warehouse medium custa 4 créditos por hora e, com um custo de US$ 3 por crédito
2, essa query custaria US$ 2 (10/60 horas * 4 créditos / hora * US$ 3/crédito).
Implementação em SQL
Podemos implementar isso em SQL usando a view snowflake.account_usage.query_history, que contém todas as queries do último ano junto com metadados importantes, como o tempo total de execução e o tamanho do warehouse em que cada query rodou:
WITH
warehouse_sizes AS (
SELECT 'X-Small' AS warehouse_size, 1 AS credits_per_hour UNION ALL
SELECT 'Small' AS warehouse_size, 2 AS credits_per_hour UNION ALL
SELECT 'Medium' AS warehouse_size, 4 AS credits_per_hour UNION ALL
SELECT 'Large' AS warehouse_size, 8 AS credits_per_hour UNION ALL
SELECT 'X-Large' AS warehouse_size, 16 AS credits_per_hour UNION ALL
SELECT '2X-Large' AS warehouse_size, 32 AS credits_per_hour UNION ALL
SELECT '3X-Large' AS warehouse_size, 64 AS credits_per_hour UNION ALL
SELECT '4X-Large' AS warehouse_size, 128 AS credits_per_hour
)
SELECT
qh.query_id,
qh.query_text,
qh.execution_time/(1000*60*60)*wh.credits_per_hour AS query_cost
Expandir código
Com isso, temos uma estimativa de custo por query para cada query_id. Para considerar a mesma query executada várias vezes em um período, podemos agregar por query_text:
WITH
warehouse_sizes AS (
// mesmo que acima
),
queries AS (
SELECT
qh.query_id,
qh.query_text,
qh.execution_time/(1000*60*60)*wh.credits_per_hour AS query_cost
FROM snowflake.account_usage.query_history AS qh
INNER JOIN warehouse_sizes AS wh
ON qh.warehouse_size=wh.warehouse_size
WHERE
start_time >= CURRENT_DATE - 30
)
Expandir código
Oportunidades de melhoria
Apesar de simples e fácil de entender, o grande problema dessa abordagem é que o Snowflake não cobra pelo tempo que a query rodou. Ele cobra por cada segundo em que o warehouse fica ativo. Uma query pode retomar o warehouse automaticamente, rodar por 6 segundos e, em seguida, deixá-lo ocioso até ser suspenso automaticamente. O Snowflake cobra por esse tempo ocioso e, por isso, pode fazer sentido "repassar" esse custo para a query. Da mesma forma, se duas queries rodam simultaneamente no warehouse pelos mesmos 20 minutos, o Snowflake cobra 20 minutos, não 40. Tempo ocioso e concorrência são, portanto, fatores importantes na hora de atribuir custos e planejar otimizações.
Ao agregar por query_text para chegar ao custo total no período, agrupamos pelo texto bruto da query. Na prática, é comum que os sistemas que geram essas queries adicionem metadados únicos em cada uma. O Looker, por exemplo, acrescenta contexto a cada query. Na primeira execução, ela pode ter este formato:
SELECT
id,
created_at
FROM orders
-- Looker Query Context '{"user_id":181,"history_slug":"9dcf35a","instance_slug":"aab1f6"}'
E na execução seguinte, esses metadados aparecem diferentes:
SELECT
id,
created_at
FROM orders
-- Looker Query Context '{"user_id":181,"history_slug":"1kal99e","instance_slug":"jju3q8"}'
Assim como o Looker, o dbt adiciona seus próprios metadados, atribuindo a cada query um invocation_id único:
SELECT
id,
created_at
FROM orders
/*{
"app": "dbt",
"invocation_id": "52c47806ae6d",
"node_id": "model.jaffle_shop.orders",
...
}*/
Quando agrupadas por query_text, as duas ocorrências da query acima não ficam vinculadas, já que esses metadados tornam cada uma única. Isso pode fazer com que uma fonte única e potencialmente fácil de resolver de queries caras (um dashboard, por exemplo) passe despercebida.
Talvez você queira ir ainda além e agrupar custos em um nível mais alto. Modelos dbt costumam ser formados por várias queries executadas em sequência: um CREATE TEMPORARY TABLE seguido de um MERGE. Um dashboard pode disparar 5 queries diferentes a cada atualização. Conseguir agrupar todo o conjunto de queries de uma mesma origem é muito útil para atribuir o gasto e, em seguida, priorizar as melhorias de forma eficiente.
Com essas oportunidades em mente, dá para fazer melhor?
Nova abordagem
Para conseguir reconciliar o custo total atribuído às queries com a fatura final, é importante partir das cobranças exatas de cada warehouse. A escolha por uma granularidade horária vem de snowflake.account_usage.warehouse_metering_history, a fonte da verdade para as cobranças de warehouse, que reporta o consumo de créditos em nível horário. A partir daí, podemos calcular quantos segundos cada query passou em execução dentro da hora e alocar os créditos proporcionalmente, com base na fração que cada uma representa do tempo total de execução. Assim, o tempo ocioso é considerado ao ser distribuído entre as queries que rodaram no período. A concorrência também fica resolvida, já que mais queries rodando geralmente reduzem o custo médio por query.
Para ilustrar com um exemplo, digamos que o TRANSFORMING_WAREHOUSE consumiu 100 créditos em uma única hora. Nesse intervalo, três queries rodaram: 2 por 10 minutos e 1 por 20 minutos, totalizando 40 minutos de tempo de execução. Nesse cenário, alocaríamos os créditos a cada query assim:
- Query 1 (10 minutos) -> 25 créditos
- Query 2 (20 minutos) -> 50 créditos
- Query 3 (10 minutos) -> 25 créditos
No diagrama abaixo, a query 3 começa entre 17:00 e 18:00 e termina depois das 18:00. Para tratar queries que atravessam várias horas, incluímos apenas a porção da query que rodou em cada hora.
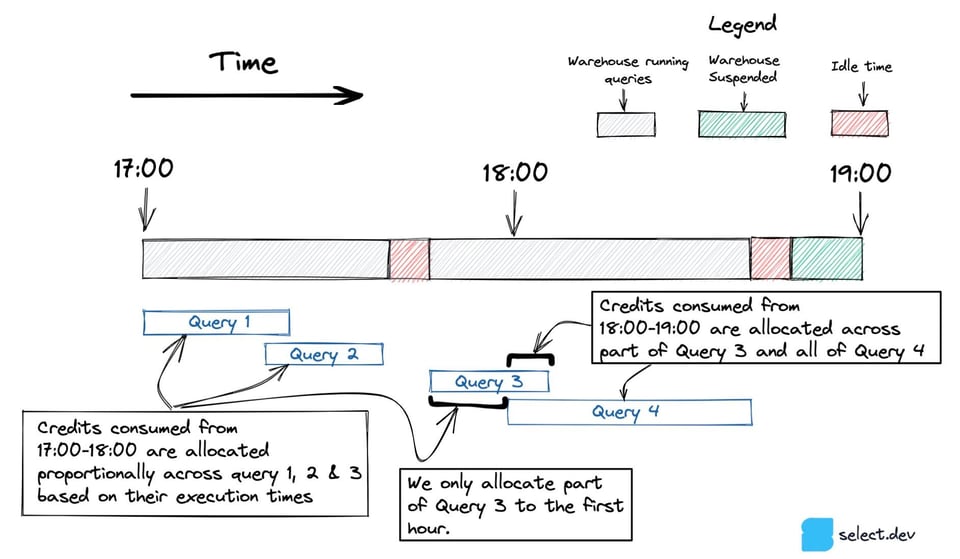
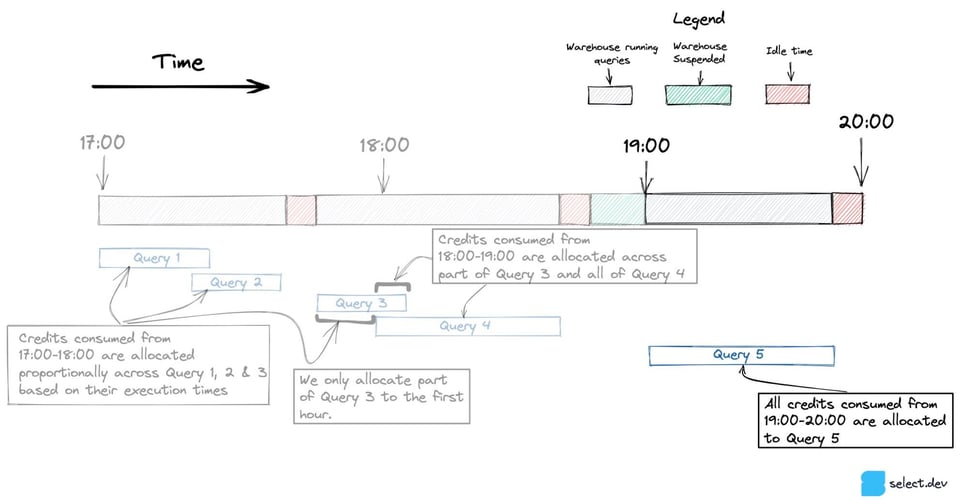
Quando apenas uma query roda em uma hora, como a Query 5 abaixo, todo o consumo de créditos é atribuído a ela, inclusive os créditos consumidos pelo warehouse ocioso.
Implementação em SQL
Algumas queries não rodam em um warehouse e são processadas inteiramente pela camada de cloud services. Para filtrá-las, removemos as queries com warehouse_size IS NULL
3. Também vamos calcular um novo timestamp, execution_start_time, para indicar o momento exato em que a query começou a rodar no warehouse
4.
SELECT
query_id,
query_text,
warehouse_id,
TIMEADD(
'millisecond',
queued_overload_time + compilation_time +
queued_provisioning_time + queued_repair_time +
list_external_files_time,
start_time
) AS execution_start_time,
end_time
FROM snowflake.account_usage.query_history AS q
WHERE TRUE
AND warehouse_size IS NOT NULL
AND start_time >= CURRENT_DATE - 30
Em seguida, precisamos descobrir por quanto tempo cada query rodou em cada hora. Digamos que temos duas queries: uma que rodou dentro da mesma hora e outra que começou em uma hora e terminou em outra.
| query_id | execution_start_time | end_time |
|---|---|---|
| 123 | 2022-10-08 08:27:51.234 | 2022-10-08 08:30:20.812 |
| 456 | 2022-10-08 08:30:11.941 | 2022-10-08 09:01:56.000 |
Precisamos gerar uma tabela com uma linha por hora em que a query rodou.
| query_id | execution_start_time | end_time | hour_start | hour_end |
|---|---|---|---|---|
| 123 | 2022-10-08 08:27:51.234 | 2022-10-08 08:30:20.812 | 2022-10-08 08:00:00.000 | 2022-10-08 09:00:00.000 |
| 456 | 2022-10-08 08:30:11.941 | 2022-10-08 09:01:56.000 | 2022-10-08 08:00:00.000 | 2022-10-08 09:00:00.000 |
| 456 | 2022-10-08 08:30:11.941 | 2022-10-08 09:01:56.000 | 2022-10-08 09:00:00.000 | 2022-10-08 10:00:00.000 |
Para fazer isso em SQL, geramos um CTE, hours_list, com 1 linha por hora no intervalo de 30 dias que estamos analisando. Depois, fazemos um range join com filtered_queries para obter um CTE, query_hours, com 1 linha para cada hora em que uma query foi executada.
WITH
filtered_queries AS (
SELECT
query_id,
query_text,
warehouse_id,
TIMEADD(
'millisecond',
queued_overload_time + compilation_time +
queued_provisioning_time + queued_repair_time +
list_external_files_time,
start_time
) AS execution_start_time,
end_time
FROM snowflake.account_usage.query_history AS q
WHERE TRUE
AND warehouse_size IS NOT NULL
AND start_time >= DATEADD('day', -30, DATEADD('day', -1, CURRENT_DATE))
),
hours_list AS (
SELECT
DATEADD(
'hour',
'-' || row_number() over (order by null),
DATEADD('day', '+1', CURRENT_DATE)
) as hour_start,
DATEADD('hour', '+1', hour_start) AS hour_end
FROM TABLE(generator(rowcount => (24*31))) t
),
-- 1 linha por hora em que uma query rodou
query_hours AS (
SELECT
hl.hour_start,
hl.hour_end,
queries.*
FROM hours_list AS hl
INNER JOIN filtered_queries AS queries
ON hl.hour_start >= DATE_TRUNC('hour', queries.execution_start_time)
AND hl.hour_start < queries.end_time
),
Agora dá para calcular quantos milissegundos cada query rodou dentro de cada hora, junto com a fração que ela representa em relação a todas as queries, usando a função DATEDIFF.
query_seconds_per_hour AS (
SELECT
*,
DATEDIFF('millisecond', GREATEST(execution_start_time, hour_start), LEAST(end_time, hour_end)) AS num_milliseconds_query_ran,
SUM(num_milliseconds_query_ran) OVER (PARTITION BY warehouse_id, hour_start) AS total_query_milliseconds_in_hour,
num_milliseconds_query_ran/total_query_milliseconds_in_hour AS fraction_of_total_query_time_in_hour,
hour_start AS hour
FROM query_hours
),
Por fim, pegamos os créditos efetivamente consumidos em snowflake.account_usage.warehouse_metering_history e os alocamos a cada query conforme a fração do tempo total de execução que ela representou. Uma última agregação devolve o dataset para uma linha por query.
credits_billed_per_hour AS (
SELECT
start_time AS hour,
warehouse_id,
credits_used_compute
FROM snowflake.account_usage.warehouse_metering_history
),
query_cost AS (
SELECT
query.*,
credits.credits_used_compute*2.28 AS actual_warehouse_cost,
credits.credits_used_compute*fraction_of_total_query_time_in_hour*2.28 AS query_allocated_cost_in_hour
FROM query_seconds_per_hour AS query
INNER JOIN credits_billed_per_hour AS credits
ON query.warehouse_id=credits.warehouse_id
AND query.hour=credits.hour
)
-- Agrega de volta para 1 linha por query
SELECT
query_id,
ANY_VALUE(MD5(query_text)) AS query_signature,
ANY_VALUE(query_text) AS query_text,
SUM(query_allocated_cost_in_hour) AS query_cost,
ANY_VALUE(warehouse_id) AS warehouse_id,
SUM(num_milliseconds_query_ran) / 1000 AS execution_time_s
FROM query_cost
GROUP BY 1
Processando o texto da query
Como vimos antes, muitas queries trazem metadados personalizados em forma de comentário, o que dificulta agrupar queries iguais. Comentários em SQL aparecem de duas formas:
- Comentários de uma linha começando com
-- - Comentários de uma ou várias linhas no formato
/* <texto do comentário> */
-- Este é um comentário SQL válido
SELECT
id,
total_price, -- Este também é
created_at /* E este também! */
FROM orders
/*
Isto também é um comentário SQL válido.
Uhuu!
*/
Cada um desses tipos de comentário pode ser removido com a função REGEXP_REPLACE do Snowflake5.
SELECT
query_text AS original_query_text,
-- Primeiro, removemos comentários delimitados por /* <texto do comentário> */
REGEXP_REPLACE(query_text, '(/\*.*\*/)') AS _cleaned_query_text,
-- Em seguida, removemos comentários de uma linha começando com --
-- e terminando com uma nova linha ou no fim da string
REGEXP_REPLACE(_cleaned_query_text, '(--.*$)|(--.*\n)') AS cleaned_query_text,
FROM snowflake.account_usage.query_history AS q
Agora dá para agregar por cleaned_query_text em vez do query_text original ao identificar as queries mais caras em um período. Para ver a versão final da implementação em SQL usando esse cleaned_query_text, vá até o apêndice.
Oportunidades de melhoria
Embora esse método represente um grande avanço em relação à abordagem simples, ainda dá para melhorar. Os créditos associados ao tempo ocioso do warehouse são distribuídos entre todas as queries que rodaram em uma determinada hora. Atribuir o gasto ocioso apenas à query (ou queries) que diretamente o causou aumentaria a precisão do modelo e, portanto, sua eficácia para orientar a redução de custos.
Essa abordagem também não considera a cobrança mínima de 60 segundos. Se duas queries rodam separadamente em uma mesma hora, uma levando 1 segundo e outra levando 60 segundos, a segunda vai parecer 60 vezes mais cara do que a primeira, mesmo que essa primeira tenha consumido 60 segundos de créditos.
A técnica de processamento do query_text também tem espaço para evoluir. É comum que modelos de dados incrementais tenham datas fixas geradas no SQL, que mudam a cada execução. Por exemplo:
-- Query executada em 2022-10-03
CREATE TEMPORARY TABLE orders AS (
SELECT
...
FROM orders
WHERE
created_at BETWEEN DATE'2022-10-01' AND DATE'2022-10-02'
)
Esse comportamento também aparece em queries parametrizadas de dashboards. Um dashboard de marketing, por exemplo, pode expor uma query templatizada:
SELECT
id,
email
FROM customers
WHERE
country_code = {{ selected_country_code }}
AND signup_date >= CURRENT_DATE - {{ signup_days_back }}
A cada execução, essa mesma query é preenchida com valores diferentes:
SELECT
id,
email
FROM customers
WHERE
country_code = 'CA'
AND signup_date >= CURRENT_DATE - 90
As queries parametrizadas podem ser tratadas com um processamento de texto SQL mais avançado, mas os tempos de ociosidade e a cobrança mínima são mais complicados. No fim das contas, o objetivo de atribuir os custos do warehouse às queries é ajudar os usuários a decidir onde concentrar seus esforços. Acreditamos firmemente que, com a abordagem atual, você vai conseguir atingir essa meta. Todos os modelos estão errados, mas alguns são úteis.
Melhorias planejadas para o futuro
Além do processamento de texto SQL mais avançado discutido acima, planejamos outras melhorias nessa abordagem:
- Se os créditos de cloud services ultrapassarem 10% dos seus créditos diários de computação, o Snowflake começa a cobrar por eles. Para tornar o modelo mais robusto, precisamos considerar os créditos de cloud services associados a cada query que rodou em um warehouse, além das queries que não rodaram em nenhum warehouse. Queries simples como
SHOW TABLES, que só rodam em cloud services, podem acabar consumindo créditos se forem executadas com muita frequência. Veja este post sobre como queries de metadados do Metabase estavam custando US$ 500/mês em créditos de cloud services. - Estender o modelo para calcular o custo por ativo de dados, e não apenas o custo por query. Para calcular o custo por modelo dbt, será preciso fazer o parsing dos metadados JSON do dbt injetados automaticamente em cada query SQL gerada pela ferramenta. Isso também pode envolver conectar-se a metadados de ferramentas de BI para calcular métricas como "custo por dashboard".
- Planejamos empacotar esse código em um novo pacote dbt para que os usuários ganhem mais visibilidade sobre o gasto no Snowflake com facilidade.
Como identificar queries caras
Depois de calcular o custo por query e armazená-lo em uma nova tabela (por exemplo, query_history_enriched), dá para identificar rapidamente as 100 queries mais caras da sua conta executando a query a seguir:
with
max_date as (
select max(date(end_time)) as date
from query_history_enriched
)
select
md5(query_parameterized_hash) as query_parameterized_hash,
sum(query_cost) as total_cost_last_30d,
total_cost_last_30d*12 as estimated_annual_cost,
max_by(query_text, start_time) as latest_query_text,
max_by(warehouse_name, start_time) as latest_warehouse_name,
max_by(warehouse_size, start_time) as latest_warehouse_size,
max_by(query_id, start_time) as latest_query_id,
avg(execution_time/1000) as avg_execution_time_s,
count(*) as num_executions
Expandir código
Notas
O Snowflake usa o conceito de créditos para a maioria dos seus serviços faturáveis. Quando os warehouses estão ativos, eles consomem créditos. A taxa de consumo dobra a cada aumento no tamanho do warehouse. Um warehouse X-Small custa 1 crédito por hora, um Small custa 2 créditos por hora, um Medium custa 4 créditos por hora, e assim por diante. Cada cliente Snowflake paga uma taxa fixa por crédito, que é o que define o valor final em dólares na fatura mensal.
O custo por crédito varia conforme o plano contratado (Standard, Enterprise, Business Critical etc.) e o seu contrato. Clientes on demand costumam pagar US$ 2/crédito no Standard e US$ 3/crédito no Enterprise. Se você assinar um contrato anual com o Snowflake, essa taxa ganha desconto conforme a quantidade de créditos comprada antecipadamente. Todos os exemplos aqui estão em dólares americanos.
É possível executar queries sem warehouse aproveitando os metadados em cloud services.
Muita coisa precisa acontecer antes que uma query comece a rodar em um warehouse, como a compilação da query em cloud services e o provisionamento do warehouse. Em um post futuro, vamos mergulhar no ciclo de vida de uma query Snowflake.
⚠️ o REGEX
'(/\*.*\*/)'não funciona para dois comentários na mesma linha, como/* hi */SELECT * FROM table/* hello there */
Apêndice
Query SQL completa
Em uma conta Snowflake com cerca de 9 milhões de queries por mês, a query abaixo levou 93 segundos em um warehouse X-Small.
WITH
filtered_queries AS (
SELECT
query_id,
query_text AS original_query_text,
-- Primeiro, removemos comentários delimitados por /* <texto do comentário> */
REGEXP_REPLACE(query_text, '(/\*.*\*/)') AS _cleaned_query_text,
-- Em seguida, removemos comentários de uma linha começando com --
-- e terminando com uma nova linha ou no fim da string
REGEXP_REPLACE(_cleaned_query_text, '(--.*$)|(--.*\n)') AS cleaned_query_text,
warehouse_id,
TIMEADD(
'millisecond',
queued_overload_time + compilation_time +
Expandir código
Abordagem alternativa avaliada
Antes de chegar à abordagem final apresentada acima, avaliamos uma alternativa que lidava com concorrência e tempo ocioso de forma mais precisa, principalmente em warehouses multi-cluster. Em vez de partir dos créditos efetivamente cobrados por hora, essa abordagem usava a view snowflake.account_usage.warehouse_events_history para montar um dataset com 1 linha por segundo em que cada cluster de warehouse esteve ativo. Combinando esse dataset com a informação de qual query rodou em qual cluster de warehouse, é possível atribuir créditos a cada conjunto de queries com mais precisão, como mostra o diagrama abaixo.
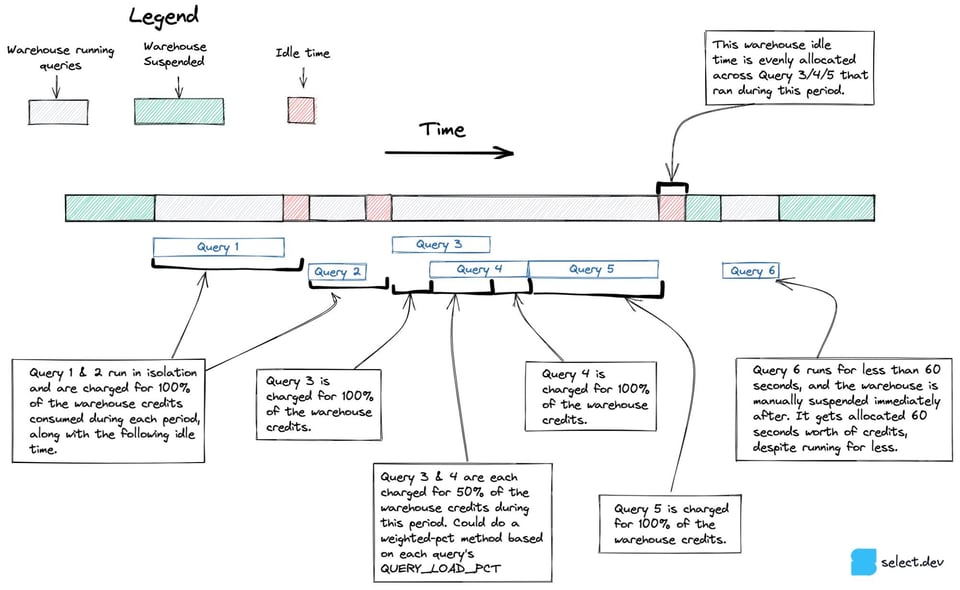
Infelizmente, descobrimos que o warehouse_events_history não representa com perfeição o intervalo em que cada cluster de warehouse esteve ativo, então abandonamos essa abordagem.
Ian Whitestone·Co-founder & CEO da SELECT
Ian é Co-founder & CEO da SELECT, uma plataforma SaaS de gestão e otimização de custos do Snowflake. Antes de fundar a SELECT, Ian passou 6 anos liderando times full stack de data science e engenharia na Shopify e na Capital One. Na Shopify, Ian liderou os esforços para otimizar o data warehouse e ampliar a observabilidade de custos.