Pour la plupart des clients Snowflake, les coûts de compute (les frais liés aux virtual warehouses) représentent la plus grosse part de la facture. Pour réduire ces dépenses et maîtriser les coûts efficacement, il faut identifier avec précision les requêtes les plus coûteuses.
Les clients Snowflake sont facturés 1 à la seconde dès qu'un virtual warehouse est actif, avec une facturation minimale de 60 secondes à chaque reprise. L'interface Snowflake propose aujourd'hui une ventilation des coûts par virtual warehouse, mais ne descend pas jusqu'à l'attribution requête par requête. Cet article présente en détail différentes méthodes pour attribuer les coûts d'un warehouse aux requêtes, les compare, et fournit le code nécessaire pour les implémenter.
Pour aller droit au but et consulter l'implémentation SQL de l'approche recommandée, rendez-vous directement à la fin de l'article !
Approche simple
Commençons par une approche simple : multiplier le temps d'exécution d'une requête par le tarif de facturation du warehouse sur lequel elle a tourné. Supposons par exemple qu'une requête s'exécute pendant 10 minutes sur un warehouse de taille medium. Un warehouse medium coûte 4 crédits par heure, et avec un coût de 3 $ par crédit
2, cette requête revient à 2 $ (10/60 heures * 4 crédits/heure * 3 $/crédit).
Implémentation SQL
On peut implémenter cela en SQL en s'appuyant sur la vue snowflake.account_usage.query_history, qui contient toutes les requêtes de la dernière année ainsi que des métadonnées clés comme le temps total d'exécution et la taille du warehouse :
WITH
warehouse_sizes AS (
SELECT 'X-Small' AS warehouse_size, 1 AS credits_per_hour UNION ALL
SELECT 'Small' AS warehouse_size, 2 AS credits_per_hour UNION ALL
SELECT 'Medium' AS warehouse_size, 4 AS credits_per_hour UNION ALL
SELECT 'Large' AS warehouse_size, 8 AS credits_per_hour UNION ALL
SELECT 'X-Large' AS warehouse_size, 16 AS credits_per_hour UNION ALL
SELECT '2X-Large' AS warehouse_size, 32 AS credits_per_hour UNION ALL
SELECT '3X-Large' AS warehouse_size, 64 AS credits_per_hour UNION ALL
SELECT '4X-Large' AS warehouse_size, 128 AS credits_per_hour
)
SELECT
qh.query_id,
qh.query_text,
qh.execution_time/(1000*60*60)*wh.credits_per_hour AS query_cost
Développer le code
On obtient ainsi une estimation du coût pour chaque query_id. Pour tenir compte du fait qu'une même requête peut s'exécuter plusieurs fois sur la période, on peut agréger par query_text :
WITH
warehouse_sizes AS (
// identique à ci-dessus
),
queries AS (
SELECT
qh.query_id,
qh.query_text,
qh.execution_time/(1000*60*60)*wh.credits_per_hour AS query_cost
FROM snowflake.account_usage.query_history AS qh
INNER JOIN warehouse_sizes AS wh
ON qh.warehouse_size=wh.warehouse_size
WHERE
start_time >= CURRENT_DATE - 30
)
Développer le code
Pistes d'amélioration
Simple et facile à comprendre, cette approche a toutefois un défaut majeur : Snowflake ne facture pas chaque seconde durant laquelle une requête s'exécute. Snowflake facture chaque seconde durant laquelle le warehouse est actif. Une requête peut redémarrer automatiquement le warehouse, s'exécuter pendant 6 secondes, puis laisser le warehouse en idle avant qu'il ne soit suspendu automatiquement. Snowflake facture ce temps d'inactivité, et il peut donc être utile de refacturer ce coût à la requête. De même, si deux requêtes s'exécutent simultanément sur le warehouse durant les mêmes 20 minutes, Snowflake facture 20 minutes, pas 40. Le temps d'inactivité et la concurrence sont donc des éléments importants à prendre en compte pour l'attribution des coûts et les efforts d'optimisation.
Lorsqu'on agrège par query_text pour obtenir le coût total sur une période, on regroupe à partir du texte brut de la requête. En pratique, il est fréquent que les systèmes qui génèrent ces requêtes y injectent des métadonnées uniques. Looker, par exemple, ajoute un peu de contexte à chaque requête. Lors d'une première exécution, elle peut ressembler à ceci :
SELECT
id,
created_at
FROM orders
-- Looker Query Context '{"user_id":181,"history_slug":"9dcf35a","instance_slug":"aab1f6"}'
À l'exécution suivante, ces métadonnées seront différentes :
SELECT
id,
created_at
FROM orders
-- Looker Query Context '{"user_id":181,"history_slug":"1kal99e","instance_slug":"jju3q8"}'
Sur le même principe, dbt ajoute ses propres métadonnées en attribuant à chaque requête un invocation_id unique :
SELECT
id,
created_at
FROM orders
/*{
"app": "dbt",
"invocation_id": "52c47806ae6d",
"node_id": "model.jaffle_shop.orders",
...
}*/
Lorsqu'elles sont regroupées par query_text, les deux occurrences de la requête ci-dessus ne seront pas associées, car ces métadonnées rendent chaque exécution unique. Résultat : une source de coût élevé pourtant facile à corriger (un dashboard, par exemple) peut passer inaperçue.
On peut même aller plus loin et regrouper les coûts à un niveau supérieur. Les modèles dbt sont souvent composés de plusieurs requêtes : un CREATE TEMPORARY TABLE suivi d'une instruction MERGE. Un dashboard peut quant à lui déclencher 5 requêtes différentes à chaque rafraîchissement. Pouvoir regrouper l'ensemble des requêtes issues d'une même origine est extrêmement utile pour attribuer les dépenses et cibler les améliorations sans perdre de temps.
Avec ces pistes en tête, peut-on faire mieux ?
Nouvelle approche
Pour pouvoir réconcilier le total des coûts attribués aux requêtes avec la facture finale, il est essentiel de partir des charges exactes facturées pour chaque warehouse. Le choix d'une granularité horaire découle de snowflake.account_usage.warehouse_metering_history, la source de vérité pour les charges des warehouses, qui rapporte la consommation de crédits à l'heure. On peut ensuite calculer combien de secondes chaque requête a passé en exécution dans l'heure, puis allouer les crédits proportionnellement à chaque requête selon sa part du temps d'exécution total. On prend ainsi en compte le temps d'inactivité en le répartissant entre les requêtes ayant tourné sur la période. La concurrence est elle aussi gérée, puisqu'un plus grand nombre de requêtes simultanées tend à abaisser le coût moyen par requête.
Pour illustrer cela par un exemple, supposons que le TRANSFORMING_WAREHOUSE ait consommé 100 crédits en une heure. Durant cette heure, trois requêtes se sont exécutées : 2 pendant 10 minutes et 1 pendant 20 minutes, soit 40 minutes d'exécution au total. Dans ce scénario, on attribuerait les crédits à chaque requête de la manière suivante :
- Requête 1 (10 minutes) -> 25 crédits
- Requête 2 (20 minutes) -> 50 crédits
- Requête 3 (10 minutes) -> 25 crédits
Dans le schéma ci-dessous, la requête 3 démarre entre 17:00 et 18:00 et se termine après 18:00. Pour les requêtes qui s'étalent sur plusieurs heures, on n'inclut que la portion exécutée dans chaque heure.
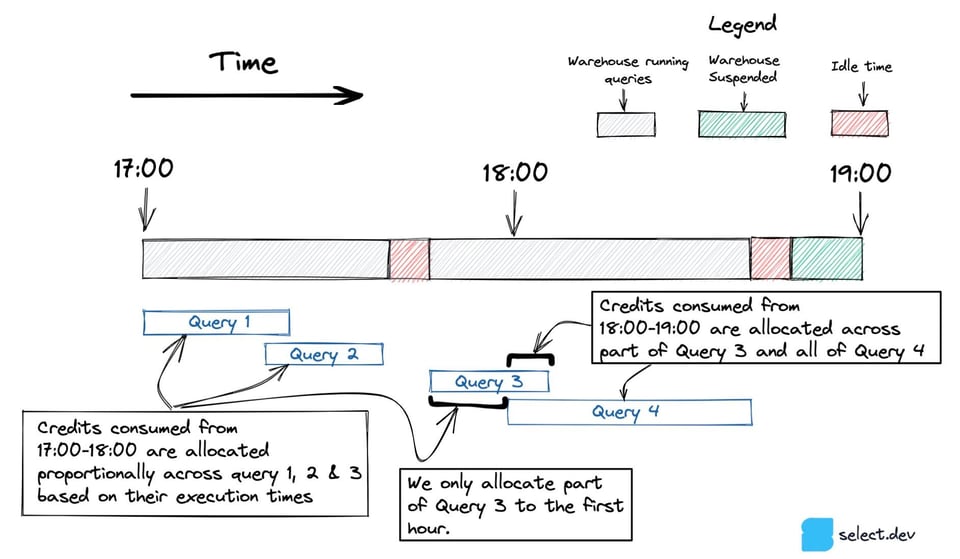
Lorsqu'une seule requête tourne durant une heure, comme la Requête 5 ci-dessous, l'intégralité de la consommation de crédits lui est attribuée, y compris les crédits consommés par le warehouse resté en idle.
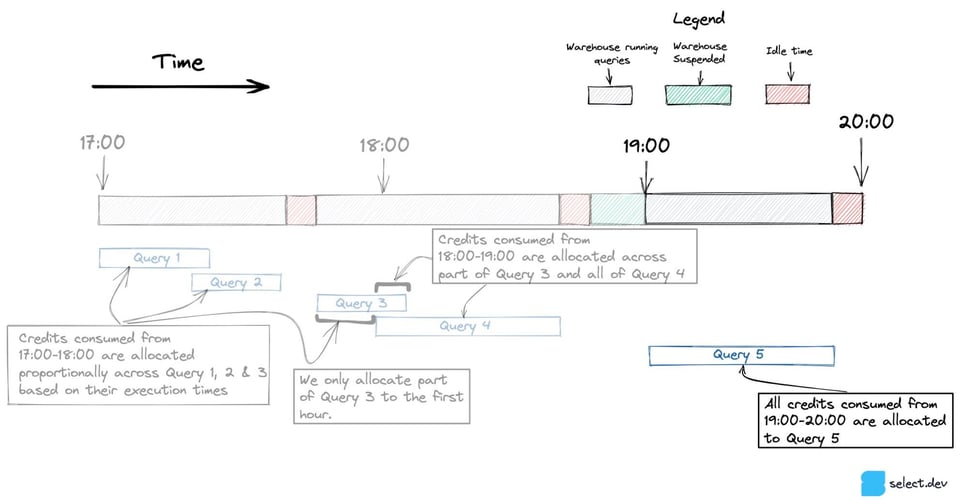
Implémentation SQL
Certaines requêtes ne s'exécutent pas sur un warehouse et sont entièrement traitées par la couche cloud services. Pour les filtrer, on retire les requêtes dont warehouse_size IS NULL
3. On calcule aussi un nouveau timestamp, execution_start_time, pour indiquer l'heure précise à laquelle la requête a commencé à s'exécuter sur le warehouse
4.
SELECT
query_id,
query_text,
warehouse_id,
TIMEADD(
'millisecond',
queued_overload_time + compilation_time +
queued_provisioning_time + queued_repair_time +
list_external_files_time,
start_time
) AS execution_start_time,
end_time
FROM snowflake.account_usage.query_history AS q
WHERE TRUE
AND warehouse_size IS NOT NULL
AND start_time >= CURRENT_DATE - 30
Il faut ensuite déterminer combien de temps chaque requête a tourné dans chaque heure. Supposons deux requêtes : une qui s'exécute entièrement dans la même heure, et une qui démarre dans une heure et se termine dans la suivante.
| query_id | execution_start_time | end_time |
|---|---|---|
| 123 | 2022-10-08 08:27:51.234 | 2022-10-08 08:30:20.812 |
| 456 | 2022-10-08 08:30:11.941 | 2022-10-08 09:01:56.000 |
On veut produire une table avec une ligne par heure durant laquelle la requête s'est exécutée.
| query_id | execution_start_time | end_time | hour_start | hour_end |
|---|---|---|---|---|
| 123 | 2022-10-08 08:27:51.234 | 2022-10-08 08:30:20.812 | 2022-10-08 08:00:00.000 | 2022-10-08 09:00:00.000 |
| 456 | 2022-10-08 08:30:11.941 | 2022-10-08 09:01:56.000 | 2022-10-08 08:00:00.000 | 2022-10-08 09:00:00.000 |
| 456 | 2022-10-08 08:30:11.941 | 2022-10-08 09:01:56.000 | 2022-10-08 09:00:00.000 | 2022-10-08 10:00:00.000 |
Pour y parvenir en SQL, on génère un CTE, hours_list, avec 1 ligne par heure sur la plage de 30 jours qui nous intéresse. On effectue ensuite une range join avec filtered_queries pour obtenir un CTE, query_hours, avec 1 ligne pour chaque heure durant laquelle une requête s'est exécutée.
WITH
filtered_queries AS (
SELECT
query_id,
query_text,
warehouse_id,
TIMEADD(
'millisecond',
queued_overload_time + compilation_time +
queued_provisioning_time + queued_repair_time +
list_external_files_time,
start_time
) AS execution_start_time,
end_time
FROM snowflake.account_usage.query_history AS q
WHERE TRUE
AND warehouse_size IS NOT NULL
AND start_time >= DATEADD('day', -30, DATEADD('day', -1, CURRENT_DATE))
),
hours_list AS (
SELECT
DATEADD(
'hour',
'-' || row_number() over (order by null),
DATEADD('day', '+1', CURRENT_DATE)
) as hour_start,
DATEADD('hour', '+1', hour_start) AS hour_end
FROM TABLE(generator(rowcount => (24*31))) t
),
-- 1 ligne par heure durant laquelle une requête s'est exécutée
query_hours AS (
SELECT
hl.hour_start,
hl.hour_end,
queries.*
FROM hours_list AS hl
INNER JOIN filtered_queries AS queries
ON hl.hour_start >= DATE_TRUNC('hour', queries.execution_start_time)
AND hl.hour_start < queries.end_time
),
On peut maintenant calculer le nombre de millisecondes durant lesquelles chaque requête a tourné dans chaque heure, ainsi que sa part relative par rapport à l'ensemble des requêtes, à l'aide de la fonction DATEDIFF.
query_seconds_per_hour AS (
SELECT
*,
DATEDIFF('millisecond', GREATEST(execution_start_time, hour_start), LEAST(end_time, hour_end)) AS num_milliseconds_query_ran,
SUM(num_milliseconds_query_ran) OVER (PARTITION BY warehouse_id, hour_start) AS total_query_milliseconds_in_hour,
num_milliseconds_query_ran/total_query_milliseconds_in_hour AS fraction_of_total_query_time_in_hour,
hour_start AS hour
FROM query_hours
),
On récupère enfin les crédits réellement consommés depuis snowflake.account_usage.warehouse_metering_history et on les répartit entre chaque requête selon sa part du temps d'exécution total. Une dernière agrégation permet de revenir à un dataset avec une ligne par requête.
credits_billed_per_hour AS (
SELECT
start_time AS hour,
warehouse_id,
credits_used_compute
FROM snowflake.account_usage.warehouse_metering_history
),
query_cost AS (
SELECT
query.*,
credits.credits_used_compute*2.28 AS actual_warehouse_cost,
credits.credits_used_compute*fraction_of_total_query_time_in_hour*2.28 AS query_allocated_cost_in_hour
FROM query_seconds_per_hour AS query
INNER JOIN credits_billed_per_hour AS credits
ON query.warehouse_id=credits.warehouse_id
AND query.hour=credits.hour
)
-- Agrégation finale pour obtenir 1 ligne par requête
SELECT
query_id,
ANY_VALUE(MD5(query_text)) AS query_signature,
ANY_VALUE(query_text) AS query_text,
SUM(query_allocated_cost_in_hour) AS query_cost,
ANY_VALUE(warehouse_id) AS warehouse_id,
SUM(num_milliseconds_query_ran) / 1000 AS execution_time_s
FROM query_cost
GROUP BY 1
Traitement du texte de la requête
Comme évoqué plus haut, beaucoup de requêtes contiennent des métadonnées personnalisées ajoutées en commentaire, ce qui limite notre capacité à regrouper les requêtes identiques. Les commentaires SQL existent sous deux formes :
- Commentaires sur une seule ligne, commençant par
-- - Commentaires sur une ou plusieurs lignes, de la forme
/* <texte du commentaire> */
-- Ceci est un commentaire SQL valide
SELECT
id,
total_price, -- Celui-ci aussi
created_at /* Et celui-là ! */
FROM orders
/*
Ceci est également un commentaire SQL valide.
Youpi !
*/
Chacun de ces types de commentaires peut être supprimé via la fonction REGEXP_REPLACE de Snowflake5.
SELECT
query_text AS original_query_text,
-- On retire d'abord les commentaires délimités par /* <texte du commentaire> */
REGEXP_REPLACE(query_text, '(/\*.*\*/)') AS _cleaned_query_text,
-- Puis les commentaires sur une seule ligne commençant par --
-- et se terminant soit par un saut de ligne, soit en fin de chaîne
REGEXP_REPLACE(_cleaned_query_text, '(--.*$)|(--.*\n)') AS cleaned_query_text,
FROM snowflake.account_usage.query_history AS q
On peut désormais agréger par cleaned_query_text plutôt que par query_text d'origine pour identifier les requêtes les plus coûteuses sur une période donnée. Pour voir la version finale de l'implémentation SQL utilisant cleaned_query_text, rendez-vous en annexe.
Pistes d'amélioration
Cette méthode constitue une nette avancée par rapport à l'approche simple, mais des marges de progression subsistent. Les crédits liés au temps d'inactivité du warehouse sont répartis entre toutes les requêtes ayant tourné durant une heure donnée. Attribuer plutôt cette dépense d'inactivité à la seule requête (ou aux requêtes) qui en sont directement responsables améliorerait la précision du modèle, et donc son efficacité pour orienter les efforts de réduction des coûts.
Cette approche ne tient pas non plus compte de la facturation minimale de 60 secondes. Si deux requêtes s'exécutent séparément durant une heure, l'une prenant 1 seconde et l'autre 60 secondes, la seconde apparaîtra 60 fois plus coûteuse que la première, alors même que cette première consomme déjà 60 secondes de crédits.
La technique de traitement du query_text peut elle aussi être améliorée. Il n'est pas rare que les modèles de données incrémentaux comportent des dates en dur générées dans le SQL, qui changent à chaque exécution. Par exemple :
-- Requête exécutée le 2022-10-03
CREATE TEMPORARY TABLE orders AS (
SELECT
...
FROM orders
WHERE
created_at BETWEEN DATE'2022-10-01' AND DATE'2022-10-02'
)
On retrouve ce comportement dans les requêtes paramétrées de dashboards. Un dashboard marketing peut par exemple exposer une requête templatisée :
SELECT
id,
email
FROM customers
WHERE
country_code = {{ selected_country_code }}
AND signup_date >= CURRENT_DATE - {{ signup_days_back }}
À chaque exécution de cette même requête, elle est renseignée avec des valeurs différentes :
SELECT
id,
email
FROM customers
WHERE
country_code = 'CA'
AND signup_date >= CURRENT_DATE - 90
Si les requêtes paramétrées peuvent être prises en charge par un traitement SQL plus avancé, les temps d'inactivité et la facturation minimale restent plus délicats à gérer. En fin de compte, l'objectif d'attribuer les coûts d'un warehouse aux requêtes est d'aider les utilisateurs à savoir où concentrer leurs efforts. Nous sommes convaincus que l'approche présentée ici vous permettra de l'atteindre. Tous les modèles sont faux, mais certains sont utiles.
Améliorations prévues
En complément du traitement SQL plus avancé évoqué ci-dessus, nous prévoyons quelques autres améliorations :
- Si les crédits cloud services dépassent 10 % de vos crédits compute quotidiens, Snowflake commence à vous les facturer. Pour rendre le modèle plus robuste, il faudra prendre en compte les crédits cloud services associés à chaque requête ayant tourné sur un warehouse, ainsi qu'à celles qui n'ont tourné sur aucun warehouse. Des requêtes simples comme
SHOW TABLES, qui ne s'exécutent que dans cloud services, peuvent finir par consommer des crédits si elles tournent très fréquemment. Voir cet article qui montre comment les requêtes de métadonnées de Metabase coûtaient 500 $/mois en crédits cloud services. - Étendre le modèle pour calculer le coût par actif de données, plutôt que par requête. Calculer le coût par modèle dbt impliquera de parser les métadonnées JSON dbt automatiquement injectées dans chaque requête SQL générée par dbt. Cela pourra aussi passer par une connexion aux métadonnées des outils de BI pour calculer des indicateurs comme le coût par dashboard.
- Nous prévoyons d'empaqueter ce code dans un nouveau package dbt pour offrir facilement aux utilisateurs une meilleure visibilité sur leurs dépenses Snowflake.
Comment identifier les requêtes coûteuses
Une fois le coût par requête calculé et stocké dans une nouvelle table (par exemple query_history_enriched), vous pouvez identifier rapidement les 100 requêtes les plus coûteuses de votre compte en exécutant la requête suivante :
with
max_date as (
select max(date(end_time)) as date
from query_history_enriched
)
select
md5(query_parameterized_hash) as query_parameterized_hash,
sum(query_cost) as total_cost_last_30d,
total_cost_last_30d*12 as estimated_annual_cost,
max_by(query_text, start_time) as latest_query_text,
max_by(warehouse_name, start_time) as latest_warehouse_name,
max_by(warehouse_size, start_time) as latest_warehouse_size,
max_by(query_id, start_time) as latest_query_id,
avg(execution_time/1000) as avg_execution_time_s,
count(*) as num_executions
Développer le code
Notes
Snowflake repose sur la notion de crédits pour la plupart de ses services facturables. Lorsqu'ils tournent, les warehouses consomment des crédits. Le rythme de consommation double à chaque palier de taille du warehouse. Un warehouse X-Small coûte 1 crédit par heure, un small 2 crédits par heure, un medium 4 crédits par heure, etc. Chaque client Snowflake paie un tarif fixe par crédit, qui sert au calcul du montant final en dollars sur la facture mensuelle.
Le coût par crédit varie selon votre formule (Standard, Enterprise, Business Critical, etc.) et votre contrat. Les clients on-demand paient en général 2 $/crédit en Standard et 3 $/crédit en Enterprise. Si vous signez un contrat annuel avec Snowflake, ce tarif est remisé selon le volume de crédits achetés à l'avance. Tous les exemples sont en dollars américains.
Il est possible d'exécuter des requêtes sans warehouse, en s'appuyant sur les métadonnées dans cloud services.
Plusieurs étapes interviennent avant qu'une requête puisse commencer à s'exécuter sur un warehouse, comme la compilation dans cloud services et le provisionnement du warehouse. Dans un prochain article, nous explorerons en profondeur le cycle de vie d'une requête Snowflake.
⚠️ la REGEX
'(/\*.*\*/)'ne fonctionne pas pour deux commentaires sur la même ligne, du type/* hi */SELECT * FROM table/* hello there */
Annexe
Requête SQL complète
Sur un compte Snowflake comptabilisant environ 9 millions de requêtes par mois, la requête ci-dessous a pris 93 secondes sur un warehouse X-Small.
WITH
filtered_queries AS (
SELECT
query_id,
query_text AS original_query_text,
-- On retire d'abord les commentaires délimités par /* <texte du commentaire> */
REGEXP_REPLACE(query_text, '(/\*.*\*/)') AS _cleaned_query_text,
-- Puis les commentaires sur une seule ligne commençant par --
-- et se terminant soit par un saut de ligne, soit en fin de chaîne
REGEXP_REPLACE(_cleaned_query_text, '(--.*$)|(--.*\n)') AS cleaned_query_text,
warehouse_id,
TIMEADD(
'millisecond',
queued_overload_time + compilation_time +
Développer le code
Approche alternative envisagée
Avant de retenir l'approche finale présentée ci-dessus, nous avons étudié une approche traitant plus précisément la concurrence et le temps d'inactivité, notamment sur les multi-cluster warehouses. Plutôt que de partir des crédits réellement facturés par heure, cette approche s'appuyait sur la vue snowflake.account_usage.warehouse_events_history pour construire un dataset avec 1 ligne par seconde d'activité de chaque cluster de warehouse. Avec ce dataset, et en sachant quelle requête a tourné sur quel cluster, il devient possible d'attribuer plus précisément les crédits à chaque ensemble de requêtes, comme illustré dans le schéma ci-dessous.
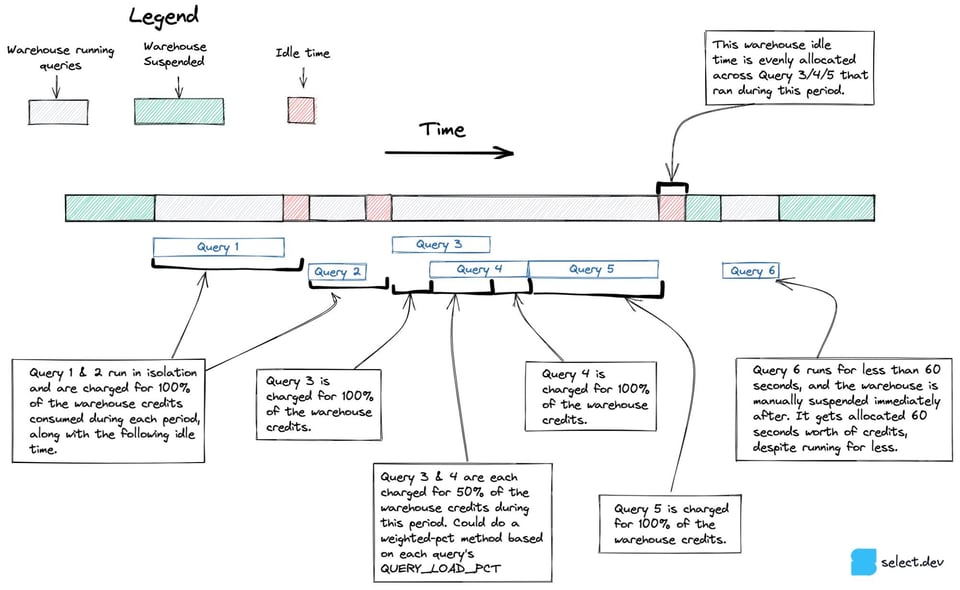
Malheureusement, nous avons constaté que warehouse_events_history ne reflète pas parfaitement les périodes d'activité de chaque cluster de warehouse ; cette approche a donc été abandonnée.
Ian Whitestone · Co-fondateur et CEO de SELECT
Ian est le co-fondateur et CEO de SELECT, une plateforme SaaS de gestion et d'optimisation des coûts Snowflake. Avant de fonder SELECT, Ian a passé 6 ans à la tête d'équipes full stack data science et engineering chez Shopify et Capital One. Chez Shopify, il a piloté les efforts d'optimisation du data warehouse et de visibilité sur les coûts.