Snowflakeをご利用の多くのお客様にとって、コンピュートコスト(仮想ウェアハウスの料金)は請求額の大部分を占めます。この支出を効果的に削減し、コストを管理するためには、コストの高いクエリを正確に特定することが欠かせません。
Snowflakeでは、仮想ウェアハウスが稼働している1秒ごとに課金が発生し 1、ウェアハウスが再開されるたびに最低60秒分が請求されます。SnowflakeのUIでは仮想ウェアハウス単位のコスト内訳は確認できますが、クエリ単位の細かい粒度では支出が割り当てられません。本記事では、ウェアハウスのコストをクエリに割り当てるさまざまな方法を比較しながら、実装に必要なコードまで詳しく紹介します。
推奨アプローチのSQL実装をすぐに確認したい方は、記事末尾に直接お進みください。
シンプルなアプローチ
まずは、クエリの実行時間に、そのクエリが動いたウェアハウスの課金レートを掛け合わせるシンプルな方法から見ていきましょう。たとえば、あるクエリがMediumサイズのウェアハウスで10分間実行されたとします。Mediumウェアハウスは1時間あたり4クレジットを消費し、1クレジットあたり$3
2とすると、このクエリのコストは$2(10/60時間 × 4クレジット/時間 × $3/クレジット)となります。
SQL実装
SQLでは、過去1年分のすべてのクエリと、合計実行時間や実行されたウェアハウスのサイズといった主要なメタデータが格納された snowflake.account_usage.query_history ビューを使って、これを実装できます。
WITH
warehouse_sizes AS (
SELECT 'X-Small' AS warehouse_size, 1 AS credits_per_hour UNION ALL
SELECT 'Small' AS warehouse_size, 2 AS credits_per_hour UNION ALL
SELECT 'Medium' AS warehouse_size, 4 AS credits_per_hour UNION ALL
SELECT 'Large' AS warehouse_size, 8 AS credits_per_hour UNION ALL
SELECT 'X-Large' AS warehouse_size, 16 AS credits_per_hour UNION ALL
SELECT '2X-Large' AS warehouse_size, 32 AS credits_per_hour UNION ALL
SELECT '3X-Large' AS warehouse_size, 64 AS credits_per_hour UNION ALL
SELECT '4X-Large' AS warehouse_size, 128 AS credits_per_hour
)
SELECT
qh.query_id,
qh.query_text,
qh.execution_time/(1000*60*60)*wh.credits_per_hour AS query_cost
コードを展開
これにより、query_id ごとのクエリコストの推定値が得られます。期間中に同じクエリが複数回実行されている場合に対応するには、query_text で集計します。
WITH
warehouse_sizes AS (
// 上記と同じ
),
queries AS (
SELECT
qh.query_id,
qh.query_text,
qh.execution_time/(1000*60*60)*wh.credits_per_hour AS query_cost
FROM snowflake.account_usage.query_history AS qh
INNER JOIN warehouse_sizes AS wh
ON qh.warehouse_size=wh.warehouse_size
WHERE
start_time >= CURRENT_DATE - 30
)
コードを展開
改善の余地
この方法は分かりやすい反面、最大の落とし穴は、Snowflakeがクエリの実行秒数ではなく、ウェアハウスが稼働している秒数に対して課金するという点です。たとえば、あるクエリが自動でウェアハウスを再開させ、6秒間実行されたあと、自動停止までウェアハウスがアイドル状態のまま残るケースがあります。Snowflakeはこのアイドル時間にも課金するため、その分のコストをクエリに「振り戻す」ことが有効です。同様に、2つのクエリが同じ20分間にウェアハウス上で並行して動いた場合、Snowflakeは40分ではなく20分として課金します。したがって、アイドル時間と並行実行はコスト割り当てと最適化において重要なポイントになります。
また、query_text で集計して期間内の合計コストを算出した際は、未加工のクエリ文をそのままグルーピングしていました。実際には、クエリを発行するシステムが各クエリに固有のメタデータを差し込むことがよくあります。たとえばLookerは、各クエリにコンテキストを付加します。初回実行時のクエリは次のような形です。
SELECT
id,
created_at
FROM orders
-- Looker Query Context '{"user_id":181,"history_slug":"9dcf35a","instance_slug":"aab1f6"}'
次回の実行では、このメタデータの値が変わります。
SELECT
id,
created_at
FROM orders
-- Looker Query Context '{"user_id":181,"history_slug":"1kal99e","instance_slug":"jju3q8"}'
Lookerと同様に、dbtも独自のメタデータを付加し、各クエリに固有の invocation_id を割り当てます。
SELECT
id,
created_at
FROM orders
/*{
"app": "dbt",
"invocation_id": "52c47806ae6d",
"node_id": "model.jaffle_shop.orders",
...
}*/
query_text でグルーピングすると、上記の2つのクエリはこのメタデータのせいで別物として扱われ、紐付きません。その結果、ダッシュボードなど、本来は容易に対処できるはずの高コストなクエリの発生源を見落としてしまう恐れがあります。
さらに、もう一段上のレベルでコストをまとめたい場面もあります。dbtモデルは CREATE TEMPORARY TABLE に続いて MERGE 文を実行するなど、複数のクエリで構成されることが多くあります。ダッシュボードが更新されるたびに5つの異なるクエリが走るケースもあります。同じ起点から発生するクエリ群をまとめて扱えれば、支出の割り当てと改善の優先順位付けを効率よく進められます。
こうした課題を踏まえて、もっと良い方法はないでしょうか。
新しいアプローチ
各クエリに割り当てたコストの合計を最終的な請求額と一致させるには、各ウェアハウスへの正確な課金額を起点にすることが重要です。ウェアハウス課金の正本である snowflake.account_usage.warehouse_metering_history がクレジット消費量を1時間単位で記録しているため、本アプローチでも1時間単位の粒度を採用します。そのうえで、各クエリがその1時間のうち何秒間実行されたかを算出し、合計実行時間に占める割合に応じてクレジットを按分します。これによりアイドル時間はその時間帯に動いていたクエリ間で分配され、並行実行されるクエリが増えるほど1クエリあたりの平均コストが下がるため、並行実行も自然に考慮されます。
具体例で見てみましょう。TRANSFORMING_WAREHOUSE が1時間で100クレジットを消費したとします。その間に3つのクエリが実行され、うち2つは10分、1つは20分動作し、合計実行時間は40分でした。このケースでは、各クエリには次のようにクレジットが割り当てられます。
- クエリ1(10分) → 25クレジット
- クエリ2(20分) → 50クレジット
- クエリ3(10分) → 25クレジット
下図では、クエリ3は17:00〜18:00の間に開始し、18:00以降に終了しています。複数の時間帯にまたがるクエリについては、各時間内に実行された部分のみを対象にします。
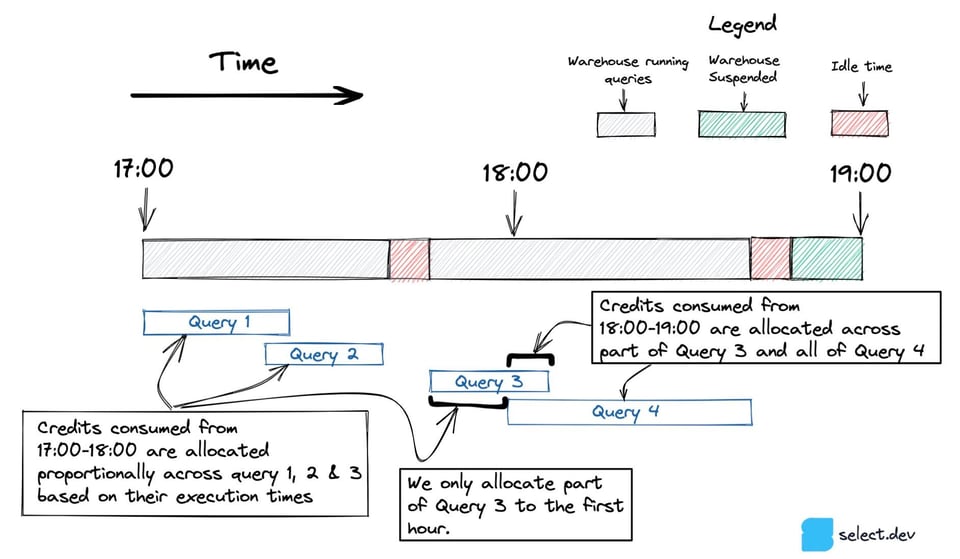
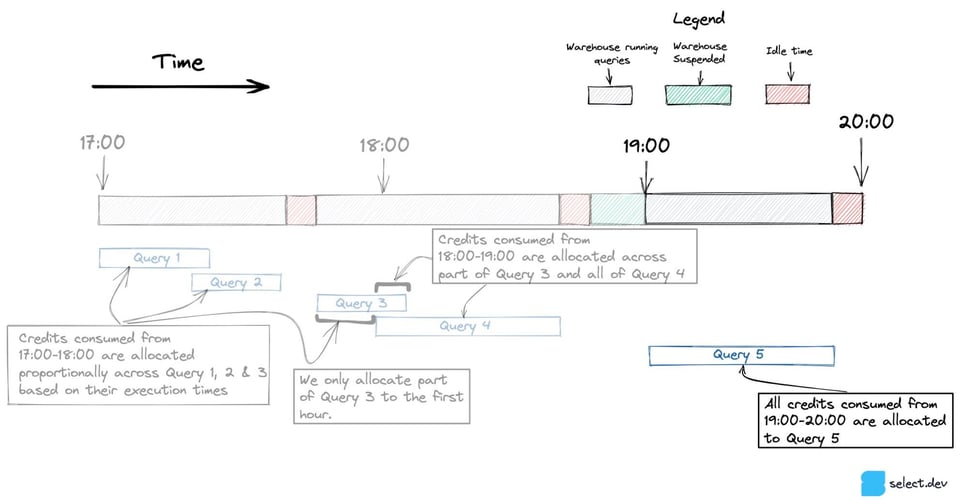
下図のクエリ5のように、1時間に1つのクエリしか実行されない場合は、ウェアハウスがアイドル状態で消費したクレジットも含めて、すべてがそのクエリに割り当てられます。
SQL実装
クエリの中には、ウェアハウス上では実行されず、クラウドサービス層だけで処理されるものもあります。これらを除外するため、warehouse_size IS NULL のクエリをフィルタします
3。あわせて、クエリがウェアハウス上で実際に実行を開始した正確な時刻を表す新しいタイムスタンプ execution_start_time も算出します
4。
SELECT
query_id,
query_text,
warehouse_id,
TIMEADD(
'millisecond',
queued_overload_time + compilation_time +
queued_provisioning_time + queued_repair_time +
list_external_files_time,
start_time
) AS execution_start_time,
end_time
FROM snowflake.account_usage.query_history AS q
WHERE TRUE
AND warehouse_size IS NOT NULL
AND start_time >= CURRENT_DATE - 30
次に、各クエリが各時間帯にどれだけ実行されたかを算出します。1時間内に収まったクエリと、ある時間帯に始まり別の時間帯に終わったクエリの、2つのケースを考えてみましょう。
| query_id | execution_start_time | end_time |
|---|---|---|
| 123 | 2022-10-08 08:27:51.234 | 2022-10-08 08:30:20.812 |
| 456 | 2022-10-08 08:30:11.941 | 2022-10-08 09:01:56.000 |
クエリが実行された時間帯ごとに1行を持つテーブルを生成します。
| query_id | execution_start_time | end_time | hour_start | hour_end |
|---|---|---|---|---|
| 123 | 2022-10-08 08:27:51.234 | 2022-10-08 08:30:20.812 | 2022-10-08 08:00:00.000 | 2022-10-08 09:00:00.000 |
| 456 | 2022-10-08 08:30:11.941 | 2022-10-08 09:01:56.000 | 2022-10-08 08:00:00.000 | 2022-10-08 09:00:00.000 |
| 456 | 2022-10-08 08:30:11.941 | 2022-10-08 09:01:56.000 | 2022-10-08 09:00:00.000 | 2022-10-08 10:00:00.000 |
SQLで実現するため、対象期間である30日間の各時間帯ごとに1行を持つCTE hours_list を作成します。続いて filtered_queries と範囲結合を行い、クエリが実行された各時間帯につき1行を持つCTE query_hours を生成します。
WITH
filtered_queries AS (
SELECT
query_id,
query_text,
warehouse_id,
TIMEADD(
'millisecond',
queued_overload_time + compilation_time +
queued_provisioning_time + queued_repair_time +
list_external_files_time,
start_time
) AS execution_start_time,
end_time
FROM snowflake.account_usage.query_history AS q
WHERE TRUE
AND warehouse_size IS NOT NULL
AND start_time >= DATEADD('day', -30, DATEADD('day', -1, CURRENT_DATE))
),
hours_list AS (
SELECT
DATEADD(
'hour',
'-' || row_number() over (order by null),
DATEADD('day', '+1', CURRENT_DATE)
) as hour_start,
DATEADD('hour', '+1', hour_start) AS hour_end
FROM TABLE(generator(rowcount => (24*31))) t
),
-- クエリが実行された1時間あたり1行
query_hours AS (
SELECT
hl.hour_start,
hl.hour_end,
queries.*
FROM hours_list AS hl
INNER JOIN filtered_queries AS queries
ON hl.hour_start >= DATE_TRUNC('hour', queries.execution_start_time)
AND hl.hour_start < queries.end_time
),
続いて、DATEDIFF関数を使って、各クエリが各時間帯に実行されたミリ秒数と、全クエリに対する割合を算出します。
query_seconds_per_hour AS (
SELECT
*,
DATEDIFF('millisecond', GREATEST(execution_start_time, hour_start), LEAST(end_time, hour_end)) AS num_milliseconds_query_ran,
SUM(num_milliseconds_query_ran) OVER (PARTITION BY warehouse_id, hour_start) AS total_query_milliseconds_in_hour,
num_milliseconds_query_ran/total_query_milliseconds_in_hour AS fraction_of_total_query_time_in_hour,
hour_start AS hour
FROM query_hours
),
最後に、snowflake.account_usage.warehouse_metering_history から実際の消費クレジットを取得し、各クエリの実行時間が全体に占める割合に応じて配分します。仕上げにもう一度集計を行い、データセットをクエリごと1行の形に戻します。
credits_billed_per_hour AS (
SELECT
start_time AS hour,
warehouse_id,
credits_used_compute
FROM snowflake.account_usage.warehouse_metering_history
),
query_cost AS (
SELECT
query.*,
credits.credits_used_compute*2.28 AS actual_warehouse_cost,
credits.credits_used_compute*fraction_of_total_query_time_in_hour*2.28 AS query_allocated_cost_in_hour
FROM query_seconds_per_hour AS query
INNER JOIN credits_billed_per_hour AS credits
ON query.warehouse_id=credits.warehouse_id
AND query.hour=credits.hour
)
-- クエリごと1行に集計し直す
SELECT
query_id,
ANY_VALUE(MD5(query_text)) AS query_signature,
ANY_VALUE(query_text) AS query_text,
SUM(query_allocated_cost_in_hour) AS query_cost,
ANY_VALUE(warehouse_id) AS warehouse_id,
SUM(num_milliseconds_query_ran) / 1000 AS execution_time_s
FROM query_cost
GROUP BY 1
クエリテキストの処理
先述のとおり、多くのクエリにはコメントとしてカスタムメタデータが付加されており、これが同一クエリのグルーピングを妨げます。SQLのコメントには2種類あります。
--で始まる1行コメント/* <コメント本文> */形式の単一行または複数行コメント
-- これは有効なSQLコメントです
SELECT
id,
total_price, -- これも有効です
created_at /* これも有効! */
FROM orders
/*
これも有効なSQLコメントです。
やった!
*/
これらのコメントは、Snowflakeの REGEXP_REPLACE 関数で除去できます5。
SELECT
query_text AS original_query_text,
-- まず、/* <コメント本文> */ で囲まれたコメントを除去
REGEXP_REPLACE(query_text, '(/\*.*\*/)') AS _cleaned_query_text,
-- 次に、-- で始まり、改行または文字列末尾で終わる
-- 1行コメントを除去
REGEXP_REPLACE(_cleaned_query_text, '(--.*$)|(--.*\n)') AS cleaned_query_text,
FROM snowflake.account_usage.query_history AS q
特定の期間で最もコストの高いクエリを特定する際は、元の query_text ではなく cleaned_query_text で集計できるようになりました。この cleaned_query_text を用いたSQL実装の最終版は、付録をご覧ください。
改善の余地
この手法はシンプルなアプローチに比べて大きく前進していますが、まだ改良の余地があります。ウェアハウスのアイドル時間に紐づくクレジットは、その時間内に実行されたすべてのクエリに分配されていますが、これをアイドルを直接引き起こしたクエリだけに割り当てられれば、モデルの精度が高まり、コスト削減の指針としての有効性も増します。
また、このアプローチは最低60秒の課金ルールも考慮していません。同じ1時間内に別々に実行された2つのクエリがあり、一方は1秒、もう一方は60秒で完了したとすると、実際にはどちらも60秒分のクレジットを消費しているにもかかわらず、後者が前者の60倍のコストに見えてしまいます。
query_text の処理手法にも改善の余地があります。インクリメンタルなデータモデルでは、実行のたびに変わる日付がSQLにハードコードされているケースが少なくありません。たとえば次のような例です。
-- 2022-10-03に実行されたクエリ
CREATE TEMPORARY TABLE orders AS (
SELECT
...
FROM orders
WHERE
created_at BETWEEN DATE'2022-10-01' AND DATE'2022-10-02'
)
同様の挙動は、パラメータ化されたダッシュボードのクエリでも見られます。たとえば、マーケティングダッシュボードでは次のようなテンプレートクエリが使われることがあります。
SELECT
id,
email
FROM customers
WHERE
country_code = {{ selected_country_code }}
AND signup_date >= CURRENT_DATE - {{ signup_days_back }}
このクエリは実行のたびに、異なる値が埋め込まれます。
SELECT
id,
email
FROM customers
WHERE
country_code = 'CA'
AND signup_date >= CURRENT_DATE - 90
パラメータ化されたクエリはより高度なSQLテキスト処理で対応できますが、アイドル時間や最低課金時間の扱いはもう一段難しい問題です。結局のところ、ウェアハウスのコストをクエリに割り当てる目的は、利用者がどこに注力すべきかを判断できるようにすることです。今回のアプローチは、その目的を十分に果たせると私たちは確信しています。すべてのモデルは間違っているが、その中には役に立つものもあるのです。
今後の拡張予定
上述のより高度なSQLテキスト処理に加え、本アプローチには以下のような拡張を予定しています。
- クラウドサービスのクレジットが1日のコンピュートクレジットの10%を超えると、Snowflakeはその分の課金を開始します。モデルの堅牢性を高めるには、ウェアハウスで実行されたクエリと、ウェアハウスを使わなかったクエリの双方について、クラウドサービスのクレジット消費を考慮する必要があります。
SHOW TABLESのようなクラウドサービスのみで動くシンプルなクエリでも、頻繁に実行されればクレジットを消費します。Metabaseのメタデータクエリが月$500のクラウドサービスクレジットを消費していた事例については、こちらの投稿をご覧ください。 - クエリ単位だけでなく、データアセット単位でコストを算出できるようモデルを拡張します。dbtモデル単位のコスト算出には、dbtが各SQLクエリに自動挿入するJSONメタデータをパースする処理が必要になります。さらにBIツールのメタデータと連携すれば、「ダッシュボード単位のコスト」といった指標も算出可能になるでしょう。
- このコードを新しいdbtパッケージとして提供し、Snowflakeの支出をより簡単に可視化できるようにする予定です。
高コストなクエリを特定する方法
クエリ単位のコストを算出して新しいテーブル(例: query_history_enriched)に格納したら、次のクエリを実行するだけで、アカウント内で最もコストの高いクエリ上位100件を素早く特定できます。
with
max_date as (
select max(date(end_time)) as date
from query_history_enriched
)
select
md5(query_parameterized_hash) as query_parameterized_hash,
sum(query_cost) as total_cost_last_30d,
total_cost_last_30d*12 as estimated_annual_cost,
max_by(query_text, start_time) as latest_query_text,
max_by(warehouse_name, start_time) as latest_warehouse_name,
max_by(warehouse_size, start_time) as latest_warehouse_size,
max_by(query_id, start_time) as latest_query_id,
avg(execution_time/1000) as avg_execution_time_s,
count(*) as num_executions
コードを展開
注記
Snowflakeは課金対象サービスの大半でクレジットという概念を用いています。ウェアハウスは稼働中にクレジットを消費し、その消費レートはウェアハウスサイズが1段階上がるごとに2倍になります。X-Smallは1時間あたり1クレジット、Smallは2クレジット、Mediumは4クレジット、というように増えていきます。Snowflakeの利用者ごとに1クレジットあたりの単価が固定されており、月次請求の最終金額はこの単価をもとに算出されます。
クレジット単価は、利用プラン(Standard、Enterprise、Business Criticalなど)と契約内容によって異なります。オンデマンド利用の場合、Standardでは$2/クレジット、Enterpriseでは$3/クレジットが一般的です。Snowflakeと年間契約を結ぶと、前払いで購入するクレジット数に応じて単価が割引されます。本記事の例はすべて米ドル建てです。
クラウドサービスのメタデータを活用することで、ウェアハウスを使わずにクエリを実行することも可能です。
クエリがウェアハウス上で実行を開始するまでには、クラウドサービスでのコンパイルやウェアハウスのプロビジョニングなど、いくつかの処理が発生します。Snowflakeクエリのライフサイクルについては、別記事で詳しく取り上げる予定です。
⚠️ 正規表現
'(/\*.*\*/)'は、同一行に2つのコメントがある場合(例:/* hi */SELECT * FROM table/* hello there */)には正しく機能しません。
付録
完全版SQLクエリ
月間約900万クエリが実行されるSnowflakeアカウントにおいて、下記のクエリはX-Smallウェアハウスで93秒で完了しました。
WITH
filtered_queries AS (
SELECT
query_id,
query_text AS original_query_text,
-- まず、/* <コメント本文> */ で囲まれたコメントを除去
REGEXP_REPLACE(query_text, '(/\*.*\*/)') AS _cleaned_query_text,
-- 次に、-- で始まり、改行または文字列末尾で終わる
-- 1行コメントを除去
REGEXP_REPLACE(_cleaned_query_text, '(--.*$)|(--.*\n)') AS cleaned_query_text,
warehouse_id,
TIMEADD(
'millisecond',
queued_overload_time + compilation_time +
コードを展開
検討した代替アプローチ
最終的に採用したアプローチに至る前に、特にマルチクラスタウェアハウスにおいて、並行実行とアイドル時間をより正確に扱う方法も検討しました。1時間ごとに実際に課金されたクレジットを起点にする代わりに、snowflake.account_usage.warehouse_events_history ビューを使い、各ウェアハウスクラスタが稼働していた1秒ごとに1行を持つデータセットを構築するアプローチです。このデータセットと、どのクエリがどのウェアハウスクラスタで実行されたかという情報を組み合わせれば、下図のように、より正確にクエリ群へクレジットを割り当てられます。
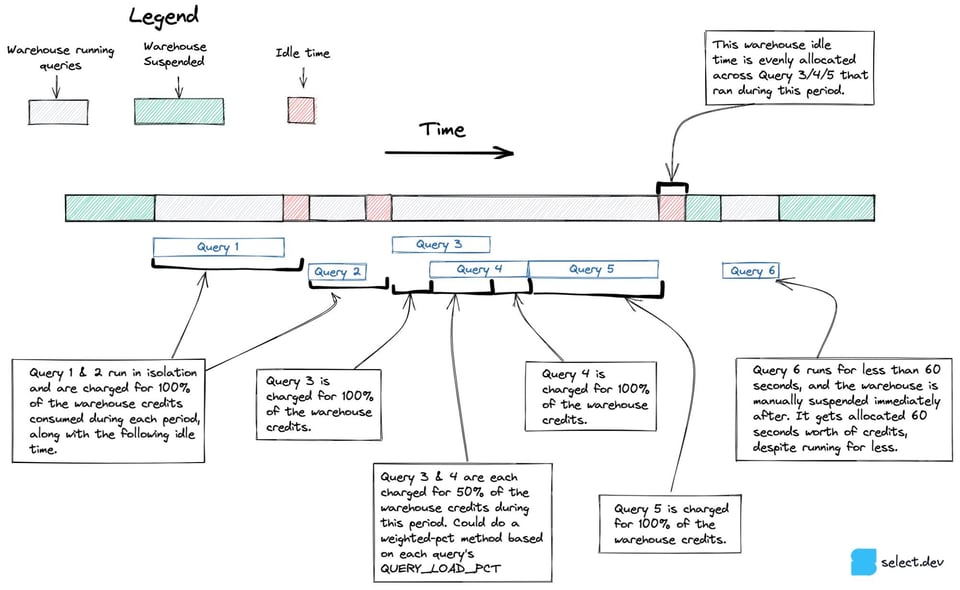
しかし残念ながら、warehouse_events_history では各ウェアハウスクラスタの稼働状況を完全には表現できないことが判明したため、このアプローチは断念しました。
Ian Whitestone・Co-founder & CEO of SELECT
IanはSnowflakeのコスト管理・最適化SaaSプラットフォームであるSELECTの共同創業者兼CEOです。SELECTを立ち上げる前は、ShopifyとCapital Oneで6年間にわたり、フルスタックのデータサイエンス・エンジニアリングチームを率いていました。Shopifyでは、データウェアハウスの最適化とコスト可視性向上の取り組みをリードしました。