Para la mayoría de los clientes de Snowflake, los costos de cómputo (los cargos de los virtual warehouses) concentran la mayor parte de la factura. Para reducir ese gasto y gestionar los costos de forma efectiva, hay que identificar con precisión las queries más caras.
A los clientes de Snowflake se les cobra 1 por cada segundo que un virtual warehouse está activo, con un cargo mínimo de 60 segundos cada vez que se reanuda. Hoy la interfaz de Snowflake muestra el desglose del costo por virtual warehouse, pero no atribuye el gasto a un nivel más granular, por query. Este artículo presenta una visión detallada y comparativa de distintas formas de atribuir los costos del warehouse a cada query, con el código necesario para hacerlo.
Si quieres saltar directo a la implementación en SQL del enfoque recomendado, ve al final.
Enfoque simple
Empecemos con un enfoque simple: multiplicar el tiempo de ejecución de una query por el costo del warehouse donde corrió. Por ejemplo, supongamos que una query corrió durante 10 minutos en un warehouse tamaño medium. Un warehouse medium cuesta 4 créditos por hora y, con un costo de $3 por crédito
2, esta query costaría $2 (10/60 horas * 4 créditos / hora * $3/crédito).
Implementación en SQL
Podemos hacerlo en SQL aprovechando la vista snowflake.account_usage.query_history, que contiene todas las queries del último año junto con metadatos clave como el tiempo total de ejecución y el tamaño del warehouse donde se ejecutó cada una:
WITH
warehouse_sizes AS (
SELECT 'X-Small' AS warehouse_size, 1 AS credits_per_hour UNION ALL
SELECT 'Small' AS warehouse_size, 2 AS credits_per_hour UNION ALL
SELECT 'Medium' AS warehouse_size, 4 AS credits_per_hour UNION ALL
SELECT 'Large' AS warehouse_size, 8 AS credits_per_hour UNION ALL
SELECT 'X-Large' AS warehouse_size, 16 AS credits_per_hour UNION ALL
SELECT '2X-Large' AS warehouse_size, 32 AS credits_per_hour UNION ALL
SELECT '3X-Large' AS warehouse_size, 64 AS credits_per_hour UNION ALL
SELECT '4X-Large' AS warehouse_size, 128 AS credits_per_hour
)
SELECT
qh.query_id,
qh.query_text,
qh.execution_time/(1000*60*60)*wh.credits_per_hour AS query_cost
Expandir código
Con esto se obtiene un costo estimado por cada query_id. Para contemplar que una misma query se ejecuta varias veces en un período, podemos agregar por query_text:
WITH
warehouse_sizes AS (
// igual que arriba
),
queries AS (
SELECT
qh.query_id,
qh.query_text,
qh.execution_time/(1000*60*60)*wh.credits_per_hour AS query_cost
FROM snowflake.account_usage.query_history AS qh
INNER JOIN warehouse_sizes AS wh
ON qh.warehouse_size=wh.warehouse_size
WHERE
start_time >= CURRENT_DATE - 30
)
Expandir código
Oportunidades de mejora
Es simple y fácil de entender, pero tiene un problema clave: Snowflake no cobra por segundo de ejecución de la query. Cobra por cada segundo que el warehouse está activo. Una query puede reanudar automáticamente el warehouse, correr 6 segundos y luego dejarlo en idle hasta que se suspende automáticamente. Snowflake factura ese tiempo en idle, por lo que conviene "cargárselo" a la query. De forma similar, si dos queries corren en paralelo durante los mismos 20 minutos en un warehouse, Snowflake factura 20 minutos, no 40. El tiempo en idle y la concurrencia son, por lo tanto, factores clave en la atribución de costos y en los esfuerzos de optimización.
Al agregar por query_text para obtener el costo total del período, agrupamos por el texto sin procesar de la query. En la práctica, es habitual que los sistemas que generan estas queries inyecten metadatos únicos en cada una. Looker, por ejemplo, suma contexto a cada query. La primera vez que se ejecuta puede verse así:
SELECT
id,
created_at
FROM orders
-- Looker Query Context '{"user_id":181,"history_slug":"9dcf35a","instance_slug":"aab1f6"}'
Y en la siguiente ejecución, esos metadatos cambian:
SELECT
id,
created_at
FROM orders
-- Looker Query Context '{"user_id":181,"history_slug":"1kal99e","instance_slug":"jju3q8"}'
Igual que Looker, dbt agrega sus propios metadatos y le asigna a cada query un invocation_id único:
SELECT
id,
created_at
FROM orders
/*{
"app": "dbt",
"invocation_id": "52c47806ae6d",
"node_id": "model.jaffle_shop.orders",
...
}*/
Al agrupar por query_text, las dos ejecuciones de la query anterior no quedarán vinculadas, porque esos metadatos las hacen únicas. Esto puede provocar que una fuente única y potencialmente fácil de resolver de queries costosas (un dashboard, por ejemplo) pase desapercibida.
Incluso podríamos ir más allá y agrupar los costos a un nivel más alto. Los modelos de dbt suelen estar compuestos por varias queries que corren juntas: un CREATE TEMPORARY TABLE seguido de un MERGE. Un dashboard puede disparar 5 queries distintas cada vez que se refresca. Poder agrupar el conjunto entero de queries que viene de un mismo origen resulta muy útil para atribuir el gasto y, después, enfocar las mejoras de manera eficiente.
Con esas oportunidades sobre la mesa, ¿podemos hacerlo mejor?
Nuevo enfoque
Para poder conciliar el costo total atribuido a las queries con la factura final, conviene partir de los cargos exactos de cada warehouse. La decisión de usar una granularidad horaria viene de snowflake.account_usage.warehouse_metering_history, la fuente de verdad para los cargos del warehouse, que reporta el consumo de créditos a nivel horario. A partir de ahí podemos calcular cuántos segundos pasó cada query ejecutándose dentro de la hora y asignar los créditos de forma proporcional según la fracción del tiempo total de ejecución que aportó cada query. Así contabilizamos el tiempo en idle distribuyéndolo entre las queries que corrieron en el período. La concurrencia también queda cubierta, ya que cuantas más queries se ejecuten, menor suele ser el costo promedio por query.
Vamos con un ejemplo: supongamos que TRANSFORMING_WAREHOUSE consumió 100 créditos en una sola hora. Durante ese rato corrieron tres queries: 2 durante 10 minutos y 1 durante 20 minutos, para un total de 40 minutos de ejecución. En este escenario, los créditos se asignarían así:
- Query 1 (10 minutos) -> 25 créditos
- Query 2 (20 minutos) -> 50 créditos
- Query 3 (10 minutos) -> 25 créditos
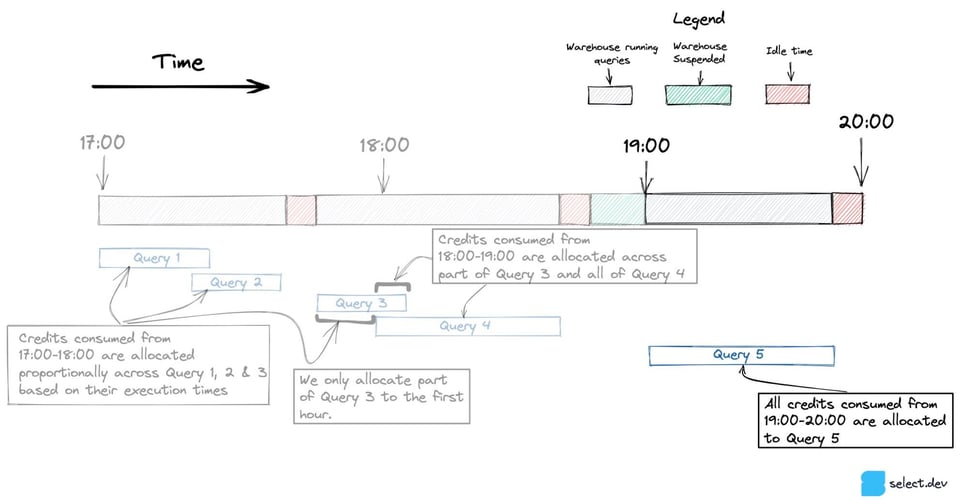
En el diagrama de abajo, la query 3 empieza entre las 17:00 y las 18:00 y termina después de las 18:00. Para las queries que abarcan varias horas, solo incluimos la porción que se ejecutó en cada hora.
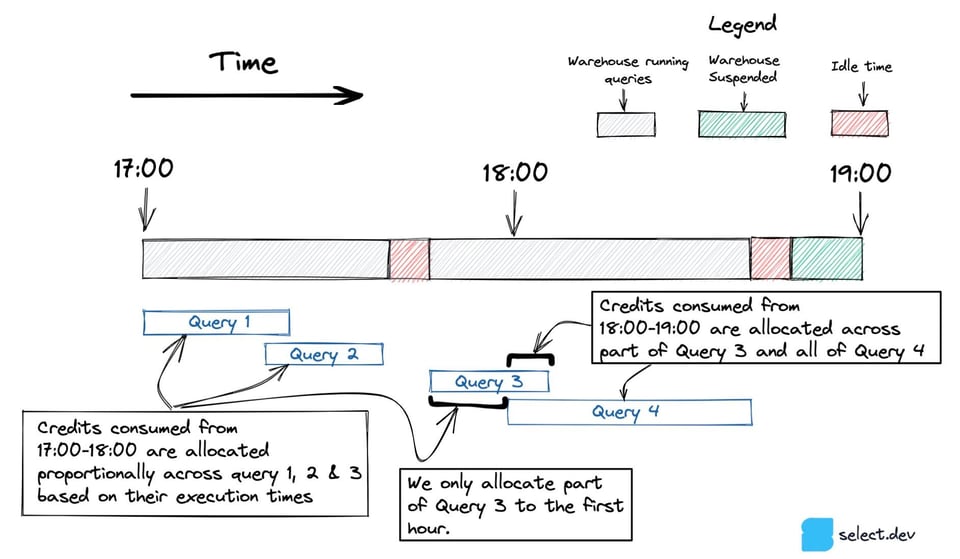
Cuando en una hora corre una sola query, como la Query 5 de abajo, todo el consumo de créditos se le atribuye a esa query, incluidos los que se consumieron mientras el warehouse estuvo en idle.
Implementación en SQL
Algunas queries no se ejecutan en un warehouse, sino que las procesa íntegramente la capa de cloud services. Para filtrarlas, descartamos las queries con warehouse_size IS NULL
3. También calcularemos un nuevo timestamp, execution_start_time, que marca el momento exacto en que la query empezó a correr en el warehouse
4.
SELECT
query_id,
query_text,
warehouse_id,
TIMEADD(
'millisecond',
queued_overload_time + compilation_time +
queued_provisioning_time + queued_repair_time +
list_external_files_time,
start_time
) AS execution_start_time,
end_time
FROM snowflake.account_usage.query_history AS q
WHERE TRUE
AND warehouse_size IS NOT NULL
AND start_time >= CURRENT_DATE - 30
Lo siguiente es determinar cuánto tiempo corrió cada query en cada hora. Supongamos dos queries: una que se ejecutó dentro de la misma hora y otra que arrancó en una hora y terminó en otra.
| query_id | execution_start_time | end_time |
|---|---|---|
| 123 | 2022-10-08 08:27:51.234 | 2022-10-08 08:30:20.812 |
| 456 | 2022-10-08 08:30:11.941 | 2022-10-08 09:01:56.000 |
Necesitamos generar una tabla con una fila por cada hora en la que la query estuvo activa.
| query_id | execution_start_time | end_time | hour_start | hour_end |
|---|---|---|---|---|
| 123 | 2022-10-08 08:27:51.234 | 2022-10-08 08:30:20.812 | 2022-10-08 08:00:00.000 | 2022-10-08 09:00:00.000 |
| 456 | 2022-10-08 08:30:11.941 | 2022-10-08 09:01:56.000 | 2022-10-08 08:00:00.000 | 2022-10-08 09:00:00.000 |
| 456 | 2022-10-08 08:30:11.941 | 2022-10-08 09:01:56.000 | 2022-10-08 09:00:00.000 | 2022-10-08 10:00:00.000 |
Para hacerlo en SQL, generamos un CTE, hours_list, con 1 fila por hora dentro del rango de 30 días que estamos analizando. Después hacemos un range join con filtered_queries para obtener un CTE, query_hours, con 1 fila por cada hora en la que se ejecutó una query.
WITH
filtered_queries AS (
SELECT
query_id,
query_text,
warehouse_id,
TIMEADD(
'millisecond',
queued_overload_time + compilation_time +
queued_provisioning_time + queued_repair_time +
list_external_files_time,
start_time
) AS execution_start_time,
end_time
FROM snowflake.account_usage.query_history AS q
WHERE TRUE
AND warehouse_size IS NOT NULL
AND start_time >= DATEADD('day', -30, DATEADD('day', -1, CURRENT_DATE))
),
hours_list AS (
SELECT
DATEADD(
'hour',
'-' || row_number() over (order by null),
DATEADD('day', '+1', CURRENT_DATE)
) as hour_start,
DATEADD('hour', '+1', hour_start) AS hour_end
FROM TABLE(generator(rowcount => (24*31))) t
),
-- 1 fila por hora en la que se ejecutó una query
query_hours AS (
SELECT
hl.hour_start,
hl.hour_end,
queries.*
FROM hours_list AS hl
INNER JOIN filtered_queries AS queries
ON hl.hour_start >= DATE_TRUNC('hour', queries.execution_start_time)
AND hl.hour_start < queries.end_time
),
Ahora podemos calcular cuántos milisegundos estuvo corriendo cada query dentro de cada hora, junto con su proporción respecto al resto de queries, aprovechando la función DATEDIFF.
query_seconds_per_hour AS (
SELECT
*,
DATEDIFF('millisecond', GREATEST(execution_start_time, hour_start), LEAST(end_time, hour_end)) AS num_milliseconds_query_ran,
SUM(num_milliseconds_query_ran) OVER (PARTITION BY warehouse_id, hour_start) AS total_query_milliseconds_in_hour,
num_milliseconds_query_ran/total_query_milliseconds_in_hour AS fraction_of_total_query_time_in_hour,
hour_start AS hour
FROM query_hours
),
Por último, tomamos los créditos realmente consumidos de snowflake.account_usage.warehouse_metering_history y los asignamos a cada query según la fracción del tiempo total de ejecución que aportó. Hacemos una agregación final para volver al formato de una fila por query.
credits_billed_per_hour AS (
SELECT
start_time AS hour,
warehouse_id,
credits_used_compute
FROM snowflake.account_usage.warehouse_metering_history
),
query_cost AS (
SELECT
query.*,
credits.credits_used_compute*2.28 AS actual_warehouse_cost,
credits.credits_used_compute*fraction_of_total_query_time_in_hour*2.28 AS query_allocated_cost_in_hour
FROM query_seconds_per_hour AS query
INNER JOIN credits_billed_per_hour AS credits
ON query.warehouse_id=credits.warehouse_id
AND query.hour=credits.hour
)
-- Volvemos a agregar a 1 fila por query
SELECT
query_id,
ANY_VALUE(MD5(query_text)) AS query_signature,
ANY_VALUE(query_text) AS query_text,
SUM(query_allocated_cost_in_hour) AS query_cost,
ANY_VALUE(warehouse_id) AS warehouse_id,
SUM(num_milliseconds_query_ran) / 1000 AS execution_time_s
FROM query_cost
GROUP BY 1
Procesar el texto de la query
Como comentamos antes, muchas queries traen metadatos personalizados como comentarios, lo que limita nuestra capacidad de agrupar queries idénticas. En SQL los comentarios tienen dos formas:
- Comentarios de una sola línea que empiezan con
-- - Comentarios de una o varias líneas con el formato
/* <texto del comentario> */
-- Esto es un comentario SQL válido
SELECT
id,
total_price, -- Esto también
created_at /* ¡Y esto! */
FROM orders
/*
Esto también es un comentario SQL válido.
¡Genial!
*/
Cada uno de estos tipos de comentario se puede eliminar con la función REGEXP_REPLACE de Snowflake5.
SELECT
query_text AS original_query_text,
-- Primero eliminamos los comentarios encerrados por /* <texto del comentario> */
REGEXP_REPLACE(query_text, '(/\*.*\*/)') AS _cleaned_query_text,
-- Después eliminamos los comentarios de una sola línea que empiezan con --
-- y terminan con un salto de línea o con el final del string
REGEXP_REPLACE(_cleaned_query_text, '(--.*$)|(--.*\n)') AS cleaned_query_text,
FROM snowflake.account_usage.query_history AS q
Ahora podemos agregar por cleaned_query_text en lugar del query_text original para identificar las queries más costosas en un período determinado. Si quieres ver la versión final de la implementación en SQL con este cleaned_query_text, ve al apéndice.
Oportunidades de mejora
Este método es una gran mejora respecto al enfoque simple, pero aún hay margen para afinarlo. Los créditos asociados al tiempo en idle del warehouse se reparten entre todas las queries que corrieron en una hora dada. En cambio, atribuir el gasto en idle solo a la query o queries que lo provocaron directamente mejorará la precisión del modelo y, por lo tanto, su utilidad para orientar los esfuerzos de reducción de costos.
Este enfoque tampoco contempla el cargo mínimo de facturación de 60 segundos. Si en una hora corren dos queries por separado y una tarda 1 segundo y la otra 60, la segunda parecerá 60 veces más cara que la primera, aunque la primera consuma 60 segundos de créditos.
La técnica de procesamiento del query_text también se puede pulir. No es raro que los modelos de datos incrementales tengan fechas hardcodeadas en el SQL que cambian en cada ejecución. Por ejemplo:
-- Query ejecutada el 2022-10-03
CREATE TEMPORARY TABLE orders AS (
SELECT
...
FROM orders
WHERE
created_at BETWEEN DATE'2022-10-01' AND DATE'2022-10-02'
)
Lo mismo pasa con queries parametrizadas de dashboards. Por ejemplo, un dashboard de marketing puede exponer una query con template:
SELECT
id,
email
FROM customers
WHERE
country_code = {{ selected_country_code }}
AND signup_date >= CURRENT_DATE - {{ signup_days_back }}
Cada vez que se ejecuta, esta misma query se completa con valores distintos:
SELECT
id,
email
FROM customers
WHERE
country_code = 'CA'
AND signup_date >= CURRENT_DATE - 90
Las queries parametrizadas se pueden resolver con un procesamiento de texto SQL más avanzado, pero el idle y los tiempos mínimos de facturación son más complejos. A fin de cuentas, el objetivo de atribuir los costos del warehouse a las queries es ayudarte a decidir dónde enfocar tu tiempo. Y creemos firmemente que, con este enfoque, vas a poder lograrlo. Todos los modelos son incorrectos, pero algunos son útiles.
Mejoras previstas a futuro
Además del procesamiento de texto SQL más avanzado que mencionamos antes, tenemos previstas otras mejoras para este enfoque:
- Si los créditos de cloud services superan el 10% de tus créditos de cómputo diarios, Snowflake empezará a cobrártelos. Para hacer el modelo más robusto, hay que considerar los créditos de cloud services asociados a cada query que corrió en un warehouse, así como las queries que no corrieron en ninguno. Queries simples como
SHOW TABLES, que solo corren en cloud services, pueden terminar consumiendo créditos si se ejecutan con mucha frecuencia. Mira este artículo sobre cómo las queries de metadata de Metabase llegaban a costar $500/mes en créditos de cloud services. - Extender el modelo para calcular el costo por data asset, en vez de costo por query. Para calcular el costo por modelo de dbt, habrá que parsear los metadatos JSON que dbt inyecta automáticamente en cada query SQL que genera. También podría implicar conectarse a los metadatos de herramientas de BI para calcular cosas como "costo por dashboard".
- Tenemos previsto empaquetar este código en un nuevo paquete de dbt para que cualquier usuario pueda ganar mayor visibilidad sobre su gasto en Snowflake de forma sencilla.
Cómo identificar queries costosas
Una vez calculado el costo por query y guardado en una nueva tabla (por ejemplo, query_history_enriched), puedes identificar rápido las 100 queries más costosas de tu cuenta con esta consulta:
with
max_date as (
select max(date(end_time)) as date
from query_history_enriched
)
select
md5(query_parameterized_hash) as query_parameterized_hash,
sum(query_cost) as total_cost_last_30d,
total_cost_last_30d*12 as estimated_annual_cost,
max_by(query_text, start_time) as latest_query_text,
max_by(warehouse_name, start_time) as latest_warehouse_name,
max_by(warehouse_size, start_time) as latest_warehouse_size,
max_by(query_id, start_time) as latest_query_id,
avg(execution_time/1000) as avg_execution_time_s,
count(*) as num_executions
Expandir código
Notas
Snowflake usa el concepto de créditos para la mayoría de sus servicios facturables. Mientras los warehouses están activos, consumen créditos. El ritmo al que se consumen los créditos se duplica cada vez que aumenta el tamaño del warehouse. Un warehouse X-Small cuesta 1 crédito por hora, un Small cuesta 2, un Medium cuesta 4, y así sucesivamente. Cada cliente de Snowflake paga un costo fijo por crédito, y eso determina el monto final en dólares de la factura mensual.
El costo por crédito varía según el plan que tengas (Standard, Enterprise, Business Critical, etc.) y tu contrato. Los clientes on demand normalmente pagan $2/crédito en Standard y $3/crédito en Enterprise. Si firmas un contrato anual con Snowflake, ese costo se descuenta según cuántos créditos compres por adelantado. Todos los ejemplos están en dólares estadounidenses.
Es posible que algunas queries se ejecuten sin warehouse, aprovechando los metadatos en cloud services.
Antes de que una query pueda empezar a ejecutarse en un warehouse, tienen que ocurrir varias cosas: la compilación en cloud services y el provisioning del warehouse, entre otras. En un próximo artículo profundizaremos en el ciclo de vida de una query en Snowflake.
⚠️, el REGEX
'(/\*.*\*/)'no funcionará para dos comentarios en la misma línea, como/* hi */SELECT * FROM table/* hello there */
Apéndice
Query SQL completa
Para una cuenta de Snowflake con ~9 millones de queries al mes, la query de abajo tardó 93 segundos en un warehouse X-Small.
WITH
filtered_queries AS (
SELECT
query_id,
query_text AS original_query_text,
-- Primero eliminamos los comentarios encerrados por /* <texto del comentario> */
REGEXP_REPLACE(query_text, '(/\*.*\*/)') AS _cleaned_query_text,
-- Después eliminamos los comentarios de una sola línea que empiezan con --
-- y terminan con un salto de línea o con el final del string
REGEXP_REPLACE(_cleaned_query_text, '(--.*$)|(--.*\n)') AS cleaned_query_text,
warehouse_id,
TIMEADD(
'millisecond',
queued_overload_time + compilation_time +
Expandir código
Enfoque alternativo considerado
Antes de quedarnos con el enfoque final que presentamos arriba, evaluamos otro que manejaba la concurrencia y el tiempo en idle con mayor precisión, sobre todo en warehouses multi-cluster. En lugar de partir de los créditos realmente facturados por hora, este enfoque aprovechaba la vista snowflake.account_usage.warehouse_events_history para construir un dataset con 1 fila por segundo en el que cada cluster del warehouse estuvo activo. Con ese dataset, sumado al dato de qué query corrió en qué cluster del warehouse, se pueden atribuir créditos con más precisión a cada conjunto de queries, como muestra el diagrama de abajo.
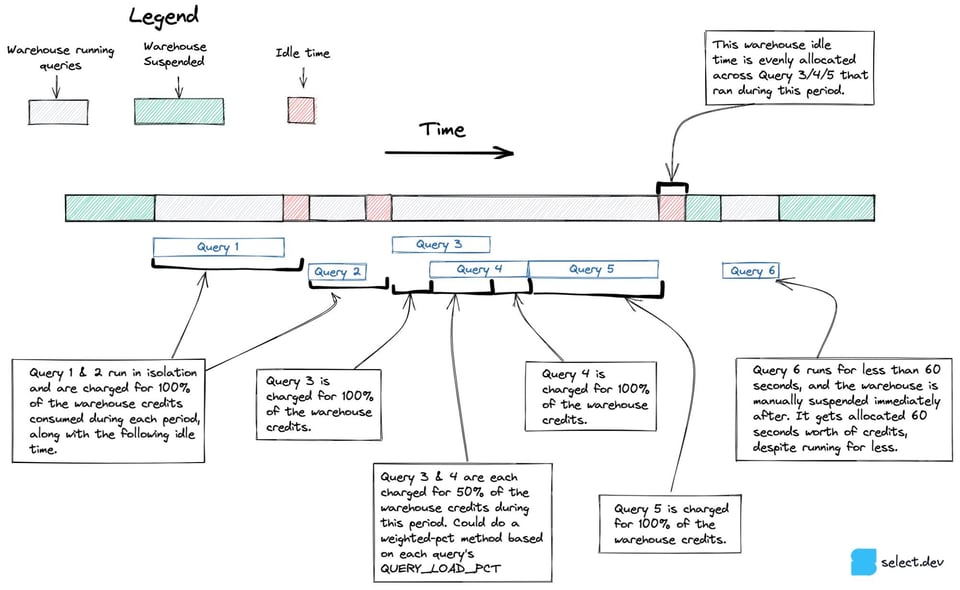
Por desgracia, descubrimos que warehouse_events_history no ofrece una representación perfecta de cuándo cada cluster del warehouse estuvo activo, así que descartamos este enfoque.
Ian Whitestone·Co-founder & CEO de SELECT
Ian es Co-founder y CEO de SELECT, una plataforma SaaS de gestión y optimización de costos para Snowflake. Antes de fundar SELECT, Ian pasó 6 años liderando equipos full stack de data science e ingeniería en Shopify y Capital One. En Shopify lideró los esfuerzos para optimizar el data warehouse y mejorar la observabilidad de los costos.