Snowflake-Nutzer profitieren bei der Compute-Konfiguration von viel Flexibilität. In diesem Beitrag zeigen wir, wie sich die Größe des Virtual Warehouse auf die Query-Geschwindigkeit auswirkt – und mit welchen Methoden Sie die passende Größe ermitteln.
Die Zeiten komplexer und langwieriger Cluster-Anpassungen sind vorbei: Mit Snowflake lässt sich ein neues Virtual Warehouse in Sekunden hochfahren oder in der Größe ändern. Das hat zwei Konsequenzen:
- Deutlich weniger Compute-Leerlauf (Auto-Suspend und Scale-In bei Multi-Cluster-Warehouses)
- Bessere Abstimmung der Rechenleistung auf die Workloads (einfaches Provisionieren, Deprovisionieren und Anpassen von Warehouses)
Workloads flexibel verschiedenen Warehouse-Konfigurationen zuweisen zu können, bedeutet kürzere Query-Laufzeiten, eine bessere Kosteneffizienz und ein angenehmeres Nutzungserlebnis für Datenteams und ihre Stakeholder. Damit stellt sich die entscheidende Frage:
Welche Warehouse-Größe sollte ich verwenden?
Bevor wir diese Frage beantworten, klären wir zunächst, was ein Virtual Warehouse überhaupt ist und wie sich seine Größe auf die verfügbaren Ressourcen und die Verarbeitungsgeschwindigkeit von Queries auswirkt.
Was ist ein Virtual Warehouse in Snowflake?
Snowflake baut Warehouses aus Compute-Nodes auf. Ein X-Small nutzt einen einzigen Compute-Node, ein Small-Warehouse zwei Nodes, ein Medium vier Nodes und so weiter. Jeder Node verfügt – unabhängig vom Cloud-Anbieter – über 8 Cores/Threads. Snowflake veröffentlicht die Spezifikationen nicht offiziell, doch es ist allgemein bekannt, dass jeder Node auf AWS (mit Ausnahme der 5XL- und 6XL-Warehouses) einer c5d.2xlarge-EC2-Instanz mit 16 GB RAM und einer 200 GB SSD entspricht. Bei anderen Cloud-Anbietern weichen die Spezifikationen ab, sind aber so gewählt, dass eine vergleichbare Performance über alle Clouds hinweg gewährleistet ist.
Auch wenn die Nodes eines Warehouses physisch voneinander getrennt sind, arbeiten sie im Verbund – Snowflake kann alle Nodes für eine einzelne Query nutzen. Wir können also davon ausgehen, dass jede Vergrößerung der Warehouse-Größe die verfügbaren Compute-Cores, den RAM und den Speicherplatz verdoppelt.
Welche Virtual-Warehouse-Größen gibt es?
Snowflake verwendet T-Shirt-Größen für seine Warehouses – anders als bei T-Shirts bedeutet jede Stufe jedoch eine Verdopplung von Ressourcen und Credit-Verbrauch. Die Größen reichen von X-Small bis 6X-Large. Die meisten Snowflake-Nutzer kommen mit dem kleinsten Warehouse, dem X-Small, problemlos aus, da es je nach Komplexität der Workloads für Datensätze bis zu mehreren zehn Gigabyte ausreichend leistungsfähig ist.
| Warehouse-Größe | Credits / Stunde | Snowpark-Optimized Credits / Stunde |
|---|---|---|
| X-Small | 1 | N/A |
| Small | 2 | N/A |
| Medium | 4 | 6 |
| Large | 8 | 12 |
| X-Large | 16 | 24 |
| 2X-Large | 32 | 48 |
| 3X-Large | 64 | 96 |
| 4X-Large | 128 | 192 |
| 5X-Large | 256 | 384 |
| 6X-Large | 512 | 768 |
Wie die Warehouse-Größe die Query-Geschwindigkeit in Snowflake beeinflusst
1. Rechenleistung
Snowflake nutzt Parallelverarbeitung, um eine Query über mehrere Cores hinweg auszuführen, sofern das schneller ist. Mehr Cores bedeuten mehr Rechenleistung – deshalb laufen Queries auf größeren Warehouses oft schneller.
Das Verteilen einer Query auf mehrere Cores und das anschließende Zusammenführen der Ergebnisse verursacht jedoch einen Overhead. Das heißt: Ab einer bestimmten Datenmenge kann die Verteilung auf noch mehr Cores eine Query sogar ausbremsen. In diesem Fall verteilt Snowflake die Query nicht weiter, und eine größere Warehouse-Größe bringt keinen Geschwindigkeitsgewinn mehr.
Leider stellt Snowflake keine Daten zur Auslastung der Compute-Cores bereit. Der einzige verfügbare Indikator ist die Anzahl der von einer Query gescannten Micro-Partitions. Jede Micro-Partition kann von einem einzelnen Core abgerufen werden. Scannt eine Query weniger Micro-Partitions als das Warehouse Cores hat, ist das Warehouse beim Table-Scan-Schritt nicht voll ausgelastet. Snowflake Solutions Architects empfehlen häufig, die Warehouse-Größe so zu wählen, dass pro Core etwa vier Micro-Partitions gescannt werden. Die Anzahl der gescannten Micro-Partitions sehen Sie im Query Profile oder über die query_history-View und die zugehörigen Table Functions.
2. RAM und lokaler Speicher
Bei der Datenverarbeitung müssen Zwischenergebnisse irgendwo abgelegt werden. Nach den CPU-Caches ist RAM der schnellste Speicherort. Ist der RAM aufgebraucht, weicht Snowflake auf den lokalen SSD-Speicher aus, um Daten zwischen den Query-Schritten zu persistieren. Dieses Verhalten heißt "spillage to local storage" – auf lokalen Speicher lässt sich zwar noch schnell zugreifen, aber nicht so schnell wie auf RAM. Reicht auch der lokale Speicher nicht aus, greift Snowflake auf Remote Storage zurück. Damit ist der Object Store des Cloud-Anbieters gemeint, also etwa S3 bei AWS. Der Zugriff auf Remote Storage ist deutlich langsamer als auf lokalen Speicher, dafür aber praktisch unbegrenzt – Snowflake bricht also nie eine Query wegen Out-of-Memory-Fehlern ab. Spillage zu Remote Storage ist das deutlichste Anzeichen dafür, dass ein Warehouse unterdimensioniert ist; eine größere Warehouse-Größe kann die Query-Geschwindigkeit dann oft mehr als verdoppeln. Auch die Volumina von lokalem und Remote-Spillage finden Sie im Query Profile oder über die query_history-View und die zugehörigen Table Functions.
Kosten vs. Performance
CPU-gebundene Queries verdoppeln ihre Geschwindigkeit mit jeder Vergrößerung der Warehouse-Größe – bis zu dem Punkt, an dem sie die Ressourcen des Warehouses nicht mehr voll ausschöpfen. Lässt man Warehouse-Leerlaufzeiten durch Auto-Suspend-Schwellen außer Acht, kostet eine Query, die auf einem Medium doppelt so schnell läuft wie auf einem Small, gleich viel – denn Kosten = Dauer x Credit-Verbrauchsrate. Die folgende Grafik veranschaulicht dieses Verhalten: Ab einem bestimmten Punkt bleibt die Ausführungszeit bei größeren Warehouses gleich, während die Kosten weiter steigen. Wie findet man also den Sweet Spot aus maximaler Performance bei möglichst niedrigen Kosten?
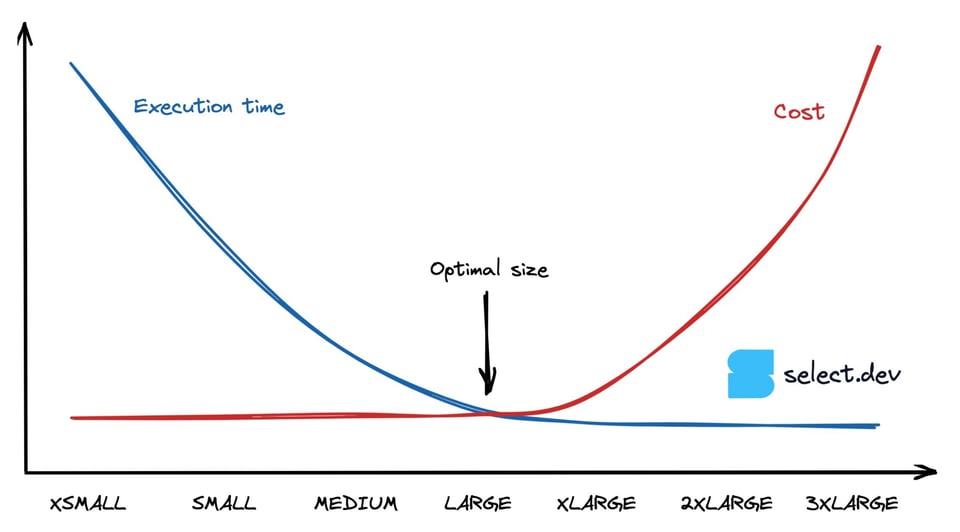
Die beste Warehouse-Größe für eine Snowflake-Query ermitteln
So gehen wir vor:
- Starten Sie immer mit einem X-Small.
- Vergrößern Sie das Warehouse so lange, bis sich die Query-Dauer nicht mehr halbiert. Tritt das ein, ist das Warehouse nicht mehr voll ausgelastet.
- Für das beste Kosten-Performance-Verhältnis wählen Sie eine Größe kleiner. Wenn der Wechsel von Medium auf Large die Query-Zeit z. B. nur um 25 % verkürzt, bleiben Sie beim Medium-Warehouse. Wird mehr Geschwindigkeit benötigt, nehmen Sie ein größeres Warehouse – beachten Sie aber, dass der Nutzen ab diesem Punkt deutlich abnimmt.
Ein Warehouse kann mehrere Queries gleichzeitig ausführen. Halten Sie Warehouses daher möglichst voll ausgelastet – selbst mit leichtem Queueing erreichen Sie maximale Effizienz. Warehouses für nicht-interaktive Queries wie Transformations-Pipelines lassen sich dank höherer Queueing-Toleranz häufig besonders effizient betreiben.
Heuristiken zur Erkennung falsch dimensionierter Warehouses
Die exakt passende Warehouse-Größe lässt sich nur durch Experimentieren bestimmen. Hier sind aber einige Indikatoren aus unserer Praxis:
Gibt es Remote-Disk-Spillage?
Eine Query mit deutlichem Remote-Disk-Spillage verdoppelt ihre Geschwindigkeit in der Regel mindestens, wenn die Warehouse-Größe steigt. Remote-Disk-Spillage ist sehr zeitintensiv – schafft man ihn durch mehr RAM und lokalen Speicher aus dem Weg, ergibt das einen großen Geschwindigkeitsschub und spart sogar Geld, wenn die Query in weniger als der halben Zeit läuft.
Gibt es Local-Disk-Spillage?
Local-Disk-Spillage ist bei Weitem nicht so kritisch wie Remote-Disk-Spillage, bremst Queries aber dennoch aus. Eine größere Warehouse-Größe beschleunigt die Query – eine Verdopplung der Geschwindigkeit ist allerdings unwahrscheinlich, sofern die Query nicht zusätzlich CPU-gebunden ist. Einen Versuch ist es trotzdem wert!
Läuft die Query in weniger als 10 Sekunden?
Dann nutzt sie die Ressourcen des Warehouses wahrscheinlich nicht voll aus und lässt sich kostengünstiger auf einem kleineren Warehouse ausführen.
Beispielansichten zur Erkennung überdimensionierter Warehouses
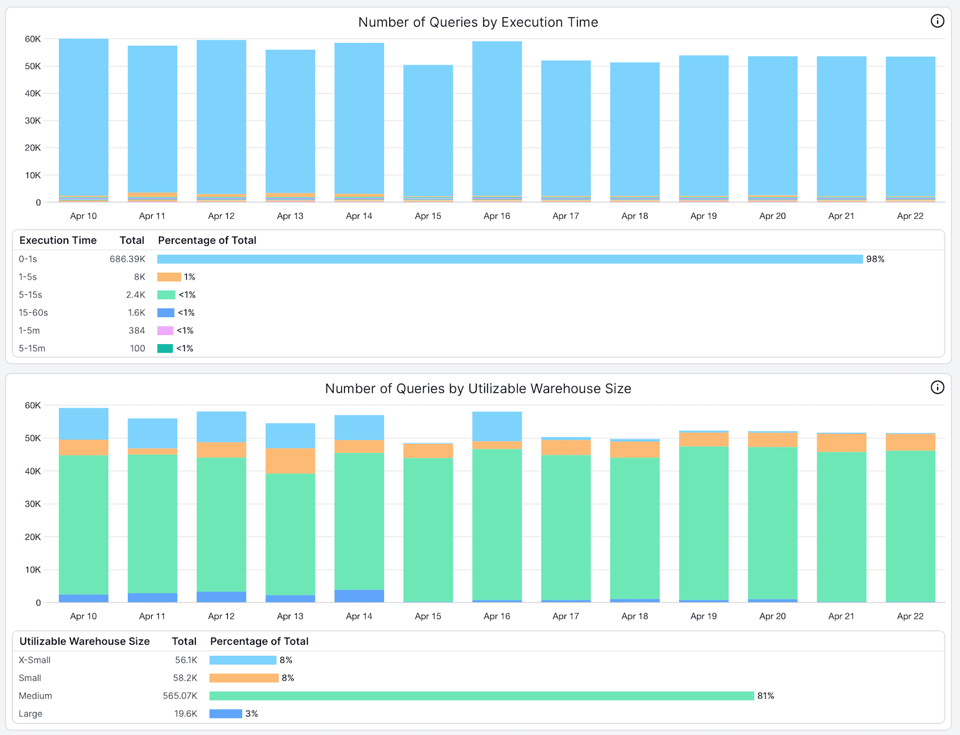
Hier sind zwei hilfreiche Ansichten, die wir im SELECT-Produkt nutzen, um Kunden beim Warehouse-Sizing zu unterstützen:
- Die Anzahl der Queries nach Ausführungszeit. Sie erkennen hier, dass über 98 % der Queries auf diesem Warehouse in weniger als 1 Sekunde ausgeführt werden.
- Die Anzahl der Queries nach nutzbarer Warehouse-Größe. Die nutzbare Warehouse-Größe gibt an, welche Warehouse-Größe eine Query maximal voll ausschöpfen kann. Wenn viele Queries die Warehouse-Größe nicht ausnutzen, ist das Warehouse überdimensioniert – oder die Queries sollten auf einem kleineren Warehouse laufen. In diesem Beispiel nutzen über 96 % der ausgeführten Queries nicht alle 8 verfügbaren Nodes des Large-Warehouses.
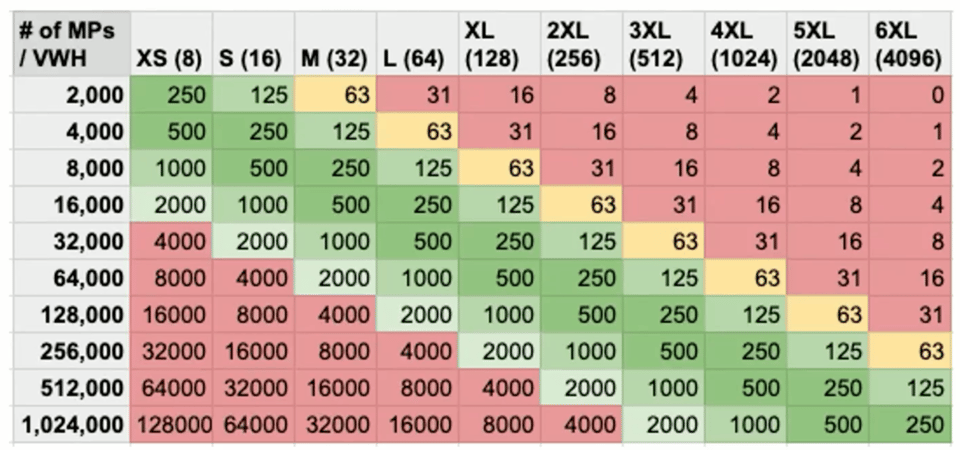
Gescannte Partitionen als Heuristik nutzen
Eine weitere nützliche Heuristik: Schauen Sie sich an, wie viele Micro-Partitions eine Query scannt, und wählen Sie die Warehouse-Größe auf dieser Basis. Diese Strategie stammt von Scott Redding, Resident Solutions Architect bei Snowflake.
Die Idee dahinter: Mit jeder Vergrößerung der Warehouse-Größe verdoppelt sich die Anzahl der für die Verarbeitung verfügbaren Threads, und jeder Thread kann immer nur eine Micro-Partition gleichzeitig verarbeiten. Ziel ist es, dass jeder Thread während der gesamten Query-Ausführung genügend Arbeit (zu verarbeitende Dateien) hat.
Beim Lesen dieser Grafik gilt: Streben Sie etwa 250 Micro-Partitions pro Thread an. Muss Ihre Query 2.000 Micro-Partitions scannen, erhält jeder Thread auf einem X-Small genau 250 Micro-Partitions (Dateien) zur Verarbeitung – das ist ideal. Im Vergleich dazu hat ein 3XL-Warehouse 512 Threads: Dort bekäme jeder Thread nur 4 Micro-Partitions, und viele Threads blieben wahrscheinlich ungenutzt.
Die größte Schwäche dieses Ansatzes: Die Anzahl der gescannten Micro-Partitions ist zwar ein wichtiger Faktor bei der Query-Ausführung, aber auch andere Aspekte wie Query-Komplexität, "exploding joins" und das Volumen sortierter Daten beeinflussen die benötigte Rechenleistung.
Fazit
Snowflake macht es einfach, Workloads passend zur Warehouse-Konfiguration zu betreiben. Wir haben Queries erlebt, die durch die richtige Warehouse-Größe mehr als doppelt so schnell liefen und gleichzeitig günstiger waren. Die Warehouse-Größe zu erhöhen, ist aber nicht der einzige Hebel, um eine Query zu beschleunigen – viele Queries lassen sich effizienter machen, indem man ihre Engpässe identifiziert und behebt. Einen ausführlichen Leitfaden zur Query-Optimierung gibt es in einem kommenden Beitrag. Falls Sie ihn noch nicht kennen, werfen Sie auch einen Blick auf unseren vorherigen Beitrag zum Thema Clustering.
Wenn Sie über künftige Beiträge informiert werden möchten, abonnieren Sie unten unseren Newsletter.
Niall Woodward · Co-Founder & CTO von SELECT
Niall ist Co-Founder & CTO von SELECT, einer SaaS-Plattform für Snowflake-Kostenmanagement und -Optimierung. Vor SELECT war Niall Data Engineer bei Brooklyn Data Company und mehreren Startups. Als Open-Source-Enthusiast ist er außerdem Maintainer von SQLFluff und Entwickler von drei dbt-Paketen: dbt_artifacts, dbt_snowflake_monitoring und dbt_query_tags.