Les utilisateurs de Snowflake disposent d'une grande flexibilité pour configurer leur compute. Dans cet article, nous revenons sur l'impact du dimensionnement des virtual warehouses sur la vitesse des requêtes et partageons quelques techniques pour trouver la bonne taille.
L'époque des redimensionnements de clusters complexes et lents est révolue : Snowflake permet de lancer un nouveau virtual warehouse ou d'en redimensionner un existant en quelques secondes. Concrètement, cela se traduit par :
- Une réduction significative du compute inactif (auto-suspend et scale-in pour les warehouses multi-clusters)
- Une meilleure adéquation entre la puissance de compute et les workloads (facilité de provisioning, de déprovisioning et de modification des warehouses)
Pouvoir affecter facilement les workloads à différentes configurations de warehouse, c'est gagner en temps d'exécution, en efficacité budgétaire, et offrir une meilleure expérience aux équipes data et à leurs interlocuteurs. D'où la question :
Quelle taille de warehouse choisir ?
Avant d'y répondre, commençons par comprendre ce qu'est un virtual warehouse, et l'impact de sa taille sur les ressources disponibles et la vitesse de traitement des requêtes.
Qu'est-ce qu'un virtual warehouse dans Snowflake ?
Snowflake construit ses warehouses à partir de nœuds de compute. Le X-Small utilise un seul nœud, un warehouse Small en utilise deux, un Medium quatre, et ainsi de suite. Chaque nœud dispose de 8 cœurs/threads, quel que soit le cloud provider. Les spécifications ne sont pas publiées par Snowflake, mais il est désormais bien établi que sur AWS chaque nœud (à l'exception des warehouses 5XL et 6XL) est une instance EC2 c5d.2xlarge, dotée de 16 Go de RAM et de 200 Go de SSD. Les spécifications varient selon les cloud providers et ont été choisies pour offrir une parité de performance entre les clouds.
Bien que les nœuds de chaque warehouse soient physiquement séparés, ils fonctionnent de concert, et Snowflake peut mobiliser l'ensemble des nœuds pour une seule requête. On peut donc considérer que chaque palier de taille de warehouse double les cœurs de compute, la RAM et l'espace disque disponibles.
Quelles tailles de virtual warehouse sont disponibles ?
Snowflake utilise une nomenclature de tailles inspirée des tailles de t-shirt, mais contrairement aux t-shirts, chaque palier supérieur correspond à un doublement des ressources et de la consommation de crédits. Les tailles vont du X-Small au 6X-Large. La plupart des utilisateurs de Snowflake n'utiliseront jamais autre chose que le plus petit warehouse, le X-Small, car il est suffisamment puissant pour la majorité des jeux de données allant jusqu'à plusieurs dizaines de gigaoctets, selon la complexité des workloads.
| Taille de warehouse | Crédits / heure | Crédits Snowpark-Optimized / heure |
|---|---|---|
| X-Small | 1 | N/A |
| Small | 2 | N/A |
| Medium | 4 | 6 |
| Large | 8 | 12 |
| X-Large | 16 | 24 |
| 2X-Large | 32 | 48 |
| 3X-Large | 64 | 96 |
| 4X-Large | 128 | 192 |
| 5X-Large | 256 | 384 |
| 6X-Large | 512 | 768 |
L'impact de la taille du warehouse sur la vitesse des requêtes Snowflake
1. Puissance de traitement
Snowflake recourt au traitement parallèle pour exécuter une requête sur plusieurs cœurs dès lors que cela accélère le résultat. Plus il y a de cœurs, plus la puissance de traitement est élevée, et c'est pourquoi les requêtes s'exécutent souvent plus vite sur des warehouses plus grands.
La distribution d'une requête sur plusieurs cœurs, puis la consolidation du jeu de résultats à la fin, engendre toutefois un overhead. À partir d'un certain volume de données, exécuter une requête sur davantage de cœurs peut donc s'avérer plus lent. Le cas échéant, Snowflake cesse de distribuer la requête sur des cœurs supplémentaires, et augmenter la taille du warehouse n'apportera aucun gain de vitesse.
Malheureusement, Snowflake ne fournit pas de données sur l'utilisation des cœurs de compute. Le seul indicateur exploitable est le nombre de micro-partitions scannées par une requête. Chaque micro-partition peut être récupérée par un cœur individuel. Si une requête scanne moins de micro-partitions qu'il n'y a de cœurs dans le warehouse, ce dernier sera sous-utilisé lors de l'étape de scan de table. Les architectes solutions Snowflake recommandent souvent de choisir une taille de warehouse telle qu'il y ait environ quatre micro-partitions scannées par cœur. Le nombre de micro-partitions scannées est visible dans le query profile, ou via la vue et les fonctions de table query_history.
2. RAM et stockage local
Le traitement des données nécessite un espace où stocker les jeux de données intermédiaires. Au-delà des caches CPU, la RAM est l'emplacement le plus rapide pour stocker et récupérer des données. Une fois celle-ci saturée, Snowflake bascule sur le stockage local SSD pour conserver les données entre les étapes d'exécution de la requête. Ce comportement est appelé spillage to local storage : le stockage local reste rapide d'accès, mais moins que la RAM. Si Snowflake épuise le stockage local, il utilisera alors le stockage distant. Le stockage distant correspond à l'object store du cloud provider, soit S3 pour AWS. Son accès est considérablement plus lent que celui du stockage local, mais sa capacité est infinie : Snowflake n'interrompra donc jamais une requête pour cause d'erreur de mémoire insuffisante. Le spillage vers le stockage distant est l'indicateur le plus net qu'un warehouse est sous-dimensionné, et augmenter sa taille peut améliorer la vitesse de la requête de plus du double. Les volumes de spillage local et distant sont eux aussi visibles dans le query profile, ou via la vue et les fonctions de table query_history.
Coût vs performance
Les requêtes CPU-bound voient leur vitesse doubler à chaque augmentation de la taille du warehouse, jusqu'au point où elles n'exploitent plus pleinement ses ressources. Si l'on ignore les temps d'inactivité liés aux seuils d'auto-suspend, une requête qui s'exécute deux fois plus vite sur un Medium que sur un Small coûtera le même montant à l'exécution, puisque coût = durée x taux de consommation de crédits. Le graphique ci-dessous illustre ce comportement : à partir d'un certain point, le temps d'exécution sur des warehouses plus grands reste identique tandis que le coût continue d'augmenter. Comment trouver, alors, ce point d'équilibre entre performance maximale et coût minimal ?
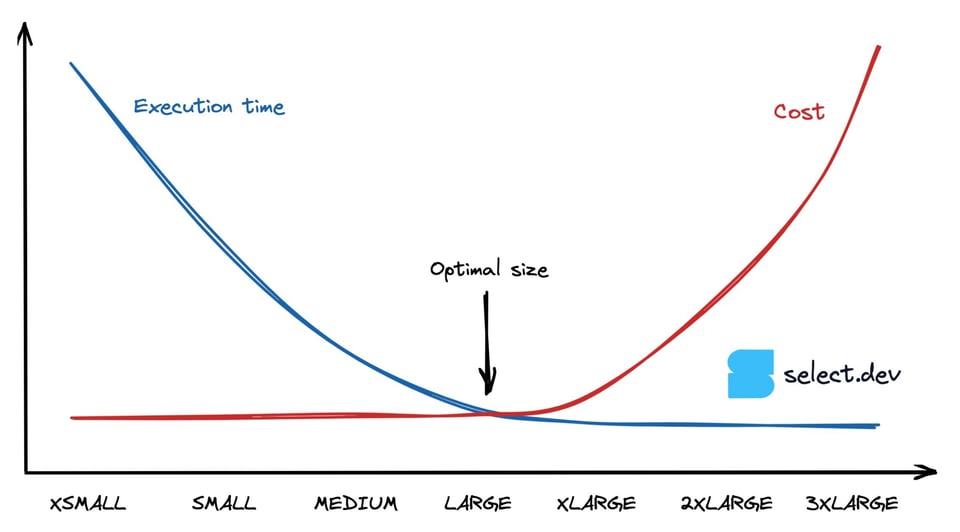
Déterminer la meilleure taille de warehouse pour une requête Snowflake
Voici la démarche que nous recommandons :
- Commencez toujours par un X-Small.
- Augmentez la taille du warehouse jusqu'à ce que la durée de la requête cesse d'être divisée par deux. À ce stade, le warehouse n'est plus pleinement exploité.
- Pour le meilleur rapport coût/performance, choisissez la taille de warehouse immédiatement inférieure. Par exemple, si passer d'un Medium à un Large ne réduit le temps de requête que de 25 %, restez sur le Medium. Si vous avez besoin de meilleures performances, optez pour un warehouse plus grand, en gardant à l'esprit que les gains seront décroissants à partir de ce stade.
Un warehouse peut exécuter plusieurs requêtes simultanément : dans la mesure du possible, gardez vos warehouses pleinement chargés, voire avec une légère file d'attente, pour une efficacité maximale. Les warehouses dédiés aux requêtes non interactives, comme les pipelines de transformation, peuvent souvent tourner avec une efficacité accrue grâce à leur tolérance au queueing.
Heuristiques pour repérer les warehouses mal dimensionnés
Seule l'expérimentation permet de déterminer précisément la meilleure taille de warehouse, mais voici quelques indicateurs tirés de notre expérience :
Y a-t-il du spillage vers le disque distant ?
Une requête présentant un spillage distant significatif voit généralement sa vitesse au moins doubler lorsqu'on augmente la taille du warehouse. Le spillage vers le disque distant est très coûteux en temps, et l'éliminer en fournissant davantage de RAM et de stockage local à la requête apporte un gain de vitesse important tout en réduisant les coûts si la requête s'exécute en moins de la moitié du temps.
Y a-t-il du spillage vers le disque local ?
Le spillage vers le disque local est loin d'être aussi pénalisant que le spillage distant, mais il ralentit tout de même les requêtes. Augmenter la taille du warehouse accélérera la requête, mais a moins de chances d'en doubler la vitesse, sauf si la requête est également CPU-bound. Cela vaut tout de même la peine d'essayer !
La requête s'exécute-t-elle en moins de 10 secondes ?
La requête n'exploite probablement pas pleinement les ressources du warehouse, et peut donc être exécutée sur un warehouse plus petit de manière plus rentable.
Exemples de vues pour repérer les warehouses surdimensionnés
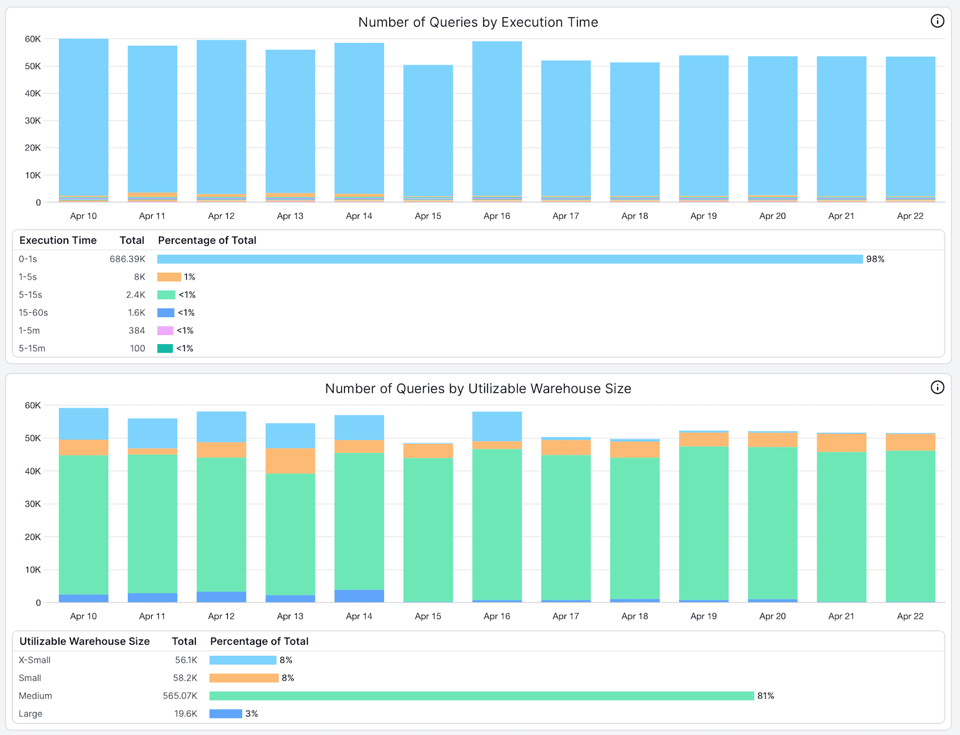
Voici deux vues très utiles que nous exploitons dans le produit SELECT pour aider nos clients à dimensionner leurs warehouses :
- Le nombre de requêtes par temps d'exécution. On constate ici que plus de 98 % des requêtes exécutées sur ce warehouse durent moins d'une seconde.
- Le nombre de requêtes par taille de warehouse réellement exploitable. La taille de warehouse exploitable correspond à la taille qu'une requête peut pleinement utiliser. Lorsque de nombreuses requêtes n'exploitent pas la taille du warehouse, cela indique que celui-ci est surdimensionné ou que ces requêtes devraient s'exécuter sur un warehouse plus petit. Dans cet exemple, plus de 96 % des requêtes exécutées n'utilisent pas l'ensemble des 8 nœuds du warehouse Large.
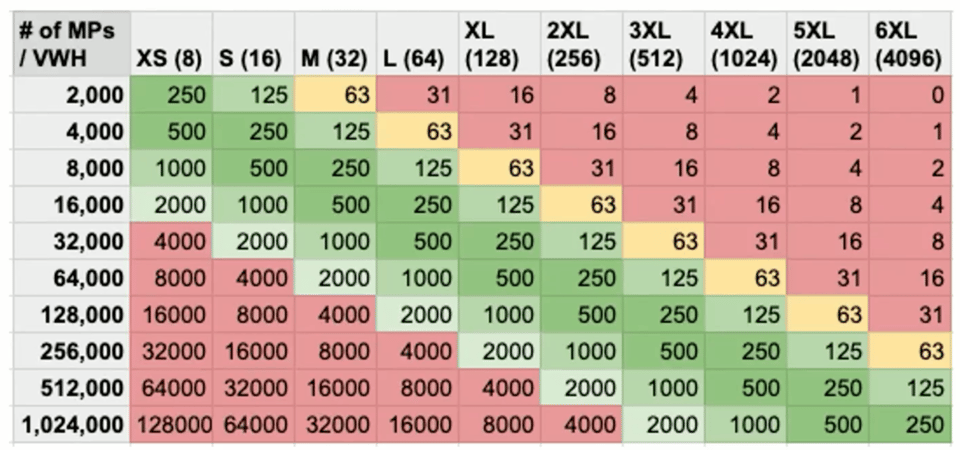
Utiliser les partitions scannées comme heuristique
Une autre heuristique utile consiste à regarder combien de micro-partitions une requête scanne, puis à choisir la taille du warehouse en conséquence. Cette approche nous vient de Scott Redding, resident solutions architect chez Snowflake.
L'intuition est la suivante : le nombre de threads disponibles pour le traitement double à chaque palier de taille de warehouse, et chaque thread peut traiter une seule micro-partition à la fois. L'objectif est donc de s'assurer que chaque thread ait suffisamment de travail (de fichiers à traiter) tout au long de l'exécution de la requête.
Pour interpréter ce graphique, l'objectif est de viser 250 micro-partitions par thread. Si votre requête doit scanner 2 000 micro-partitions, l'exécuter sur un X-Small donnera à chaque thread 250 micro-partitions (fichiers) à traiter, ce qui est idéal. À comparer avec une exécution sur un warehouse 3XL, qui dispose de 512 threads : chacun d'eux ne recevra que 4 micro-partitions, ce qui laissera probablement de nombreux threads inutilisés.
Principal écueil de cette approche : si les micro-partitions scannées jouent un rôle important dans l'exécution d'une requête, d'autres facteurs comme la complexité de la requête, les jointures explosives ou le volume de données triées influencent également la puissance de traitement nécessaire.
Pour conclure
Snowflake facilite l'adéquation entre workloads et configurations de warehouse, et nous avons vu des requêtes plus que doubler en vitesse tout en coûtant moins cher grâce au choix de la bonne taille de warehouse. Augmenter la taille du warehouse n'est toutefois pas la seule option pour accélérer une requête : nombre d'entre elles peuvent gagner en efficacité en identifiant et en résolvant leurs goulets d'étranglement. Nous publierons un guide détaillé sur l'optimisation des requêtes dans un prochain article ; d'ici là, si ce n'est pas déjà fait, consultez notre article précédent sur le clustering.
Pour être notifié lors de la publication de nos prochains articles, abonnez-vous à notre newsletter ci-dessous.
Niall Woodward·Co-fondateur & CTO de SELECT
Niall est le co-fondateur et CTO de SELECT, une plateforme SaaS de gestion et d'optimisation des coûts Snowflake. Avant de lancer SELECT, Niall était data engineer chez Brooklyn Data Company et dans plusieurs startups. Passionné d'open source, il est également mainteneur de SQLFluff et créateur de trois packages dbt : dbt_artifacts, dbt_snowflake_monitoring et dbt_query_tags.