Los usuarios de Snowflake cuentan con mucha flexibilidad para configurar el cómputo. En este post analizamos cómo el tamaño del virtual warehouse incide en la velocidad de las queries y compartimos algunas técnicas para elegir el adecuado.
Los tiempos del redimensionamiento de clústeres lento y complejo quedaron atrás: con Snowflake se puede levantar un nuevo virtual warehouse o redimensionar uno existente en cuestión de segundos. Las implicancias son:
- Una reducción significativa del cómputo ocioso (auto-suspend y scale-in para warehouses multi-clúster)
- Un mejor ajuste de la capacidad de cómputo a los workloads (facilidad para aprovisionar, desaprovisionar y modificar warehouses)
Poder asignar workloads fácilmente a distintas configuraciones de warehouse se traduce en queries más rápidas, mayor eficiencia en el gasto y una mejor experiencia para los equipos de datos y sus stakeholders. De ahí surge la pregunta:
¿Qué tamaño de warehouse debería usar?
Antes de responder, veamos primero qué es un virtual warehouse y cómo su tamaño afecta los recursos disponibles y la velocidad de procesamiento de las queries.
¿Qué es un virtual warehouse en Snowflake?
Snowflake arma los warehouses a partir de nodos de cómputo. Un X-Small usa un único nodo, un Small usa dos, un Medium cuatro, y así sucesivamente. Cada nodo tiene 8 cores/threads, sin importar el proveedor de nube. Snowflake no publica las especificaciones, pero es bastante conocido que en AWS cada nodo (salvo en los warehouses 5XL y 6XL) corresponde a una instancia EC2 c5d.2xlarge, con 16 GB de RAM y un SSD de 200 GB. Las especificaciones varían según el proveedor de nube y se eligieron para ofrecer un rendimiento equivalente entre nubes.
Aunque los nodos de cada warehouse están físicamente separados, operan de forma coordinada, y Snowflake puede aprovechar todos los nodos para una sola query. Por lo tanto, podemos asumir que cada aumento de tamaño del warehouse duplica los cores de cómputo, la RAM y el espacio en disco disponibles.
¿Qué tamaños de virtual warehouse existen?
Snowflake usa nombres tipo tallas de camiseta para sus warehouses, pero a diferencia de la ropa, cada salto representa una duplicación de recursos y de consumo de créditos. Los tamaños van desde X-Small hasta 6X-Large. La mayoría de los usuarios de Snowflake solo necesitará el warehouse más chico, el X-Small, ya que es lo suficientemente potente para la mayoría de los datasets de hasta decenas de gigabytes, según la complejidad de los workloads.
| Tamaño del warehouse | Créditos / Hora | Créditos Snowpark-Optimized / Hora |
|---|---|---|
| X-Small | 1 | N/A |
| Small | 2 | N/A |
| Medium | 4 | 6 |
| Large | 8 | 12 |
| X-Large | 16 | 24 |
| 2X-Large | 32 | 48 |
| 3X-Large | 64 | 96 |
| 4X-Large | 128 | 192 |
| 5X-Large | 256 | 384 |
| 6X-Large | 512 | 768 |
Cómo influye el tamaño del warehouse en la velocidad de las queries en Snowflake
1. Capacidad de procesamiento
Snowflake usa procesamiento en paralelo para ejecutar una query a través de múltiples cores siempre que resulte más rápido. Más cores significan más capacidad de procesamiento, por eso las queries suelen correr más rápido en warehouses más grandes.
Sin embargo, distribuir una query entre varios cores y luego combinar el resultado final implica un costo adicional, lo que significa que, para cierto tamaño de datos, puede resultar más lento ejecutar una query repartida en más cores. Cuando eso pasa, Snowflake deja de distribuir la query entre más cores y aumentar el tamaño del warehouse no se traduce en mejoras de velocidad.
Lamentablemente, Snowflake no proporciona datos sobre la utilización de los cores de cómputo. El único factor disponible es la cantidad de micro-particiones escaneadas por una query. Cada micro-partición puede ser recuperada por un core individual. Si una query escanea menos micro-particiones que cores tiene el warehouse, el warehouse quedará subutilizado durante el paso de escaneo de la tabla. Los solutions architects de Snowflake suelen recomendar elegir un tamaño de warehouse tal que por cada core se escaneen aproximadamente cuatro micro-particiones. La cantidad de micro-particiones escaneadas se puede ver en el query profile, o en la vista y funciones de tabla query_history.
2. RAM y almacenamiento local
El procesamiento de datos requiere un lugar donde guardar los conjuntos de datos intermedios. Más allá de la caché de la CPU, la RAM es el lugar más rápido para almacenar y recuperar datos. Cuando se agota, Snowflake empieza a usar el SSD local para persistir datos entre los pasos de ejecución. Este comportamiento se conoce como "spillage to local storage": el almacenamiento local sigue siendo rápido de acceder, pero no tanto como la RAM. Si Snowflake se queda sin almacenamiento local, recurrirá al almacenamiento remoto. El almacenamiento remoto se refiere al object store del proveedor de nube, es decir, S3 en AWS. Es considerablemente más lento que el local, pero es infinito, lo que significa que Snowflake nunca abortará una query por errores de falta de memoria. El spillage al almacenamiento remoto es el indicador más claro de que un warehouse está subdimensionado, y aumentar su tamaño puede mejorar la velocidad de la query más del doble. Tanto los volúmenes de spillage local como remoto también se pueden consultar en el query profile, o en la vista y funciones de tabla query_history.
Costo vs rendimiento
Las queries limitadas por CPU duplicarán su velocidad a medida que aumenta el tamaño del warehouse, hasta el punto en que dejan de aprovechar al máximo sus recursos. Si dejamos de lado los tiempos de inactividad del warehouse por los umbrales de auto-suspend, una query que corre el doble de rápido en un Medium que en un Small cuesta lo mismo, ya que costo = duración x tasa de consumo de créditos. El siguiente gráfico ilustra este comportamiento y muestra que, a partir de cierto punto, el tiempo de ejecución en warehouses más grandes se mantiene igual mientras el costo sigue subiendo. Entonces, ¿cómo encontramos ese punto óptimo de máximo rendimiento al menor costo?
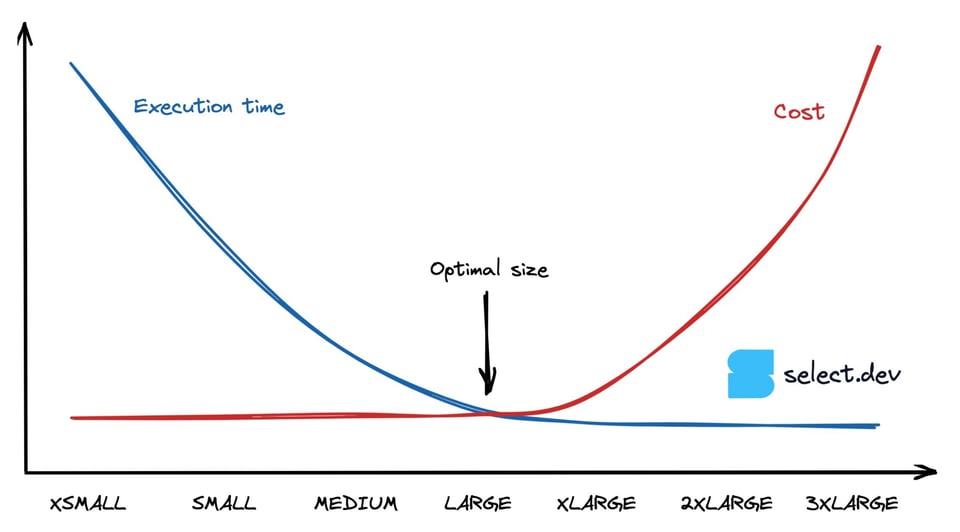
Cómo determinar el mejor tamaño de warehouse para una query de Snowflake
Este es el proceso que recomendamos:
- Empieza siempre con un X-Small.
- Aumenta el tamaño del warehouse hasta que la duración de la query deje de reducirse a la mitad. Cuando eso ocurra, el warehouse ya no se está aprovechando al máximo.
- Para la mejor relación costo-rendimiento, elige un tamaño menor. Por ejemplo, si al pasar de un Medium a un Large la query solo se acelera un 25 %, quédate con el Medium. Si necesitas más velocidad, usa un warehouse más grande, pero ten presente que a partir de ese punto los rendimientos son decrecientes.
Un warehouse puede ejecutar más de una query a la vez, así que cuando sea posible mantén los warehouses bien cargados, incluso con algo de queueing leve, para lograr la máxima eficiencia. Los warehouses para queries que no son de usuarios, como los pipelines de transformación, suelen poder correr con mayor eficiencia gracias a su tolerancia al queueing.
Heurísticas para identificar warehouses mal dimensionados
La experimentación es la única forma de determinar con exactitud el mejor tamaño de warehouse, pero hay algunos indicadores que hemos aprendido con la experiencia:
¿Hay spillage a disco remoto?
Una query con un spillage significativo a disco remoto suele duplicar su velocidad como mínimo cuando se aumenta el tamaño del warehouse. El spillage a disco remoto consume mucho tiempo, y eliminarlo aportando más RAM y almacenamiento local a la query da un gran impulso de velocidad y, además, ahorra dinero si la query se ejecuta en menos de la mitad del tiempo.
¿Hay spillage a disco local?
El spillage a disco local no es ni cerca tan grave como el remoto, pero igual ralentiza las queries. Aumentar el tamaño del warehouse acelerará la query, aunque es menos probable que duplique su velocidad, salvo que la query también esté limitada por CPU. ¡De todas formas, vale la pena intentarlo!
¿La query corre en menos de 10 segundos?
Lo más probable es que la query no esté aprovechando al máximo los recursos del warehouse, lo que significa que podría ejecutarse de forma más rentable en uno más chico.
Vistas de ejemplo para identificar warehouses sobredimensionados
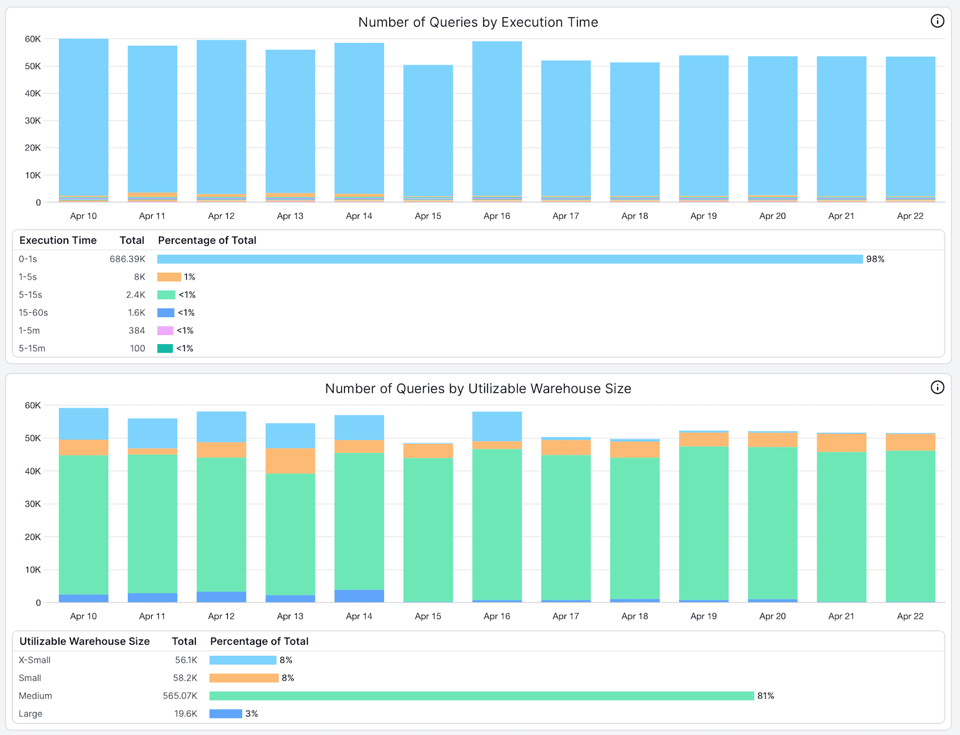
Estas son dos vistas útiles que aprovechamos en el producto SELECT para ayudar a los clientes con el dimensionamiento de warehouses:
- La cantidad de queries por tiempo de ejecución. Aquí puedes ver que más del 98 % de las queries que corren en este warehouse tardan menos de 1 segundo en ejecutarse.
- La cantidad de queries por tamaño de warehouse aprovechable. El tamaño de warehouse aprovechable representa el tamaño que una query puede usar al máximo. Cuando muchas queries no aprovechan el tamaño del warehouse, eso indica que está sobredimensionado o que las queries deberían correr en uno más chico. En este ejemplo, más del 96 % de las queries que corren en el warehouse no están usando los 8 nodos disponibles del warehouse Large.
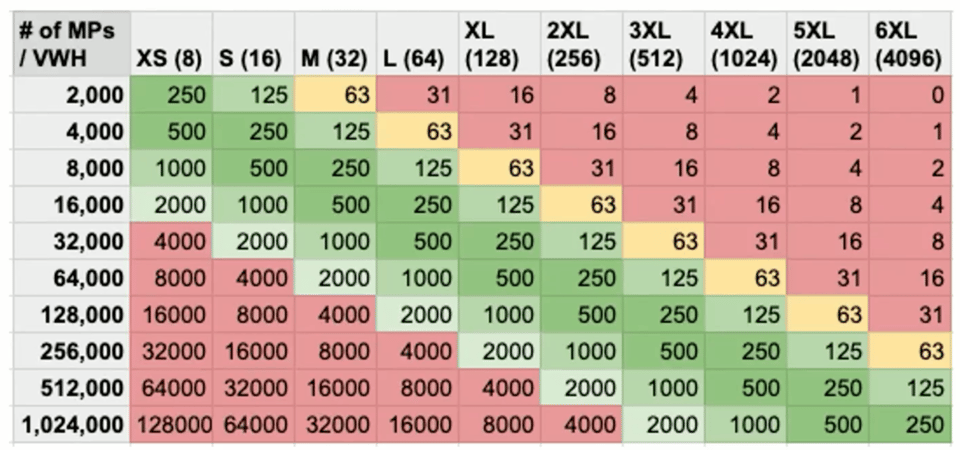
Las particiones escaneadas como heurística
Otra heurística útil consiste en revisar cuántas micro-particiones escanea una query y, a partir de eso, elegir el tamaño del warehouse. Esta estrategia viene de Scott Redding, resident solutions architect en Snowflake.
La intuición detrás de esta estrategia es que la cantidad de threads disponibles para el procesamiento se duplica con cada aumento de tamaño del warehouse, y cada thread puede procesar una sola micro-partición a la vez. La idea es asegurarte de que cada thread tenga trabajo suficiente (archivos para procesar) durante toda la ejecución de la query.
Para interpretar este gráfico, el objetivo es apuntar a 250 micro-particiones por thread. Si tu query necesita escanear 2000 micro-particiones, ejecutarla en un X-Small le dará a cada thread 250 micro-particiones (archivos) para procesar, lo cual es ideal. Compáralo con ejecutar la query en un warehouse 3XL, que tiene 512 threads: cada uno recibirá apenas 4 micro-particiones para procesar, lo que probablemente dejará muchos threads sin uso.
El principal inconveniente de este enfoque es que, si bien las micro-particiones escaneadas son un factor importante en la ejecución de la query, otros factores como la complejidad de la query, los exploding joins y el volumen de datos ordenados también inciden en la capacidad de procesamiento necesaria.
Cierre
Snowflake facilita ajustar los workloads a las configuraciones de warehouse, y hemos visto queries que más que duplican su velocidad y, además, cuestan menos con solo elegir el tamaño de warehouse correcto. Aumentar el tamaño del warehouse no es la única opción para que una query corra más rápido: muchas queries pueden ejecutarse de forma más eficiente identificando y resolviendo sus cuellos de botella. En un próximo post compartiremos una guía detallada sobre optimización de queries, pero si aún no lo has hecho, revisa nuestro post anterior sobre clustering.
Si quieres que te avisemos cuando publiquemos próximos posts, suscríbete a nuestra lista de correo a continuación.
Niall Woodward·Co-founder & CTO de SELECT
Niall es Co-Founder y CTO de SELECT, una plataforma SaaS de gestión y optimización de costos en Snowflake. Antes de fundar SELECT, Niall fue data engineer en Brooklyn Data Company y en varias startups. Como entusiasta del open-source, también es maintainer de SQLFluff y creador de tres paquetes de dbt: dbt_artifacts, dbt_snowflake_monitoring y dbt_query_tags.