Snowflake offre grande flessibilità nella configurazione del compute. In questo articolo vediamo come il dimensionamento dei virtual warehouse incide sulla velocità delle query e quali tecniche usare per trovare quello giusto.
I tempi dei ridimensionamenti di cluster lenti e complicati sono ormai alle spalle: con Snowflake si avvia un nuovo virtual warehouse o se ne ridimensiona uno esistente in pochi secondi. Le conseguenze sono due:
- Una netta riduzione dei tempi morti del compute (auto-suspend e scale-in per i warehouse multi-cluster)
- Un migliore abbinamento tra potenza di calcolo e workloads (provisioning, de-provisioning e modifica dei warehouse semplificati)
Poter assegnare con facilità i workloads a configurazioni di warehouse diverse significa query più rapide, spesa più efficiente e un'esperienza migliore per i team dati e i loro stakeholder. Da qui la domanda:
Quale dimensione di warehouse conviene usare?
Prima di rispondere, vediamo cos'è un virtual warehouse e in che modo la sua dimensione influisce sulle risorse disponibili e sulla velocità di elaborazione delle query.
Cos'è un virtual warehouse in Snowflake?
Snowflake costruisce i warehouse a partire da nodi di calcolo. L'X-Small ne usa uno solo, lo Small due, il Medium quattro e così via. Ogni nodo dispone di 8 core/thread, indipendentemente dal cloud provider. Snowflake non pubblica le specifiche, ma è ormai risaputo che su AWS ogni nodo (eccetto per i warehouse 5XL e 6XL) corrisponde a un'istanza EC2 c5d.2xlarge, con 16GB di RAM e un SSD da 200GB. Le specifiche variano da un cloud provider all'altro e sono state scelte per garantire prestazioni equivalenti su tutti i cloud.
Pur essendo fisicamente separati, i nodi di ciascun warehouse operano in modo coordinato e Snowflake può sfruttarli tutti per una singola query. Possiamo quindi assumere che ogni aumento di dimensione del warehouse raddoppi core di calcolo, RAM e spazio su disco disponibili.
Quali dimensioni di virtual warehouse sono disponibili?
Snowflake adotta per i warehouse la nomenclatura delle taglie delle magliette ma, a differenza delle magliette, ogni taglia in più corrisponde al raddoppio di risorse e consumo di credit. Le dimensioni vanno dall'X-Small al 6X-Large. La maggior parte degli utenti Snowflake si limiterà a usare il warehouse più piccolo, l'X-Small, che è sufficientemente potente per gran parte dei dataset fino a qualche decina di gigabyte, a seconda della complessità dei workloads.
| Dimensione warehouse | Credit / ora | Credit Snowpark-Optimized / ora |
|---|---|---|
| X-Small | 1 | N/D |
| Small | 2 | N/D |
| Medium | 4 | 6 |
| Large | 8 | 12 |
| X-Large | 16 | 24 |
| 2X-Large | 32 | 48 |
| 3X-Large | 64 | 96 |
| 4X-Large | 128 | 192 |
| 5X-Large | 256 | 384 |
| 6X-Large | 512 | 768 |
L'impatto della dimensione del warehouse sulla velocità delle query Snowflake
1. Potenza di elaborazione
Snowflake ricorre all'elaborazione parallela per eseguire una query su più core ogni volta che ciò consente di velocizzarla. Più core significano più potenza di elaborazione: ecco perché le query risultano spesso più rapide sui warehouse più grandi.
Distribuire una query su più core e poi ricomporne il set di risultati comporta però un overhead, al punto che, per una certa quantità di dati, eseguire una query su più core può rivelarsi addirittura più lento. Quando ciò accade, Snowflake non distribuirà la query su ulteriori core e aumentare la dimensione del warehouse non porterà miglioramenti in velocità.
Purtroppo Snowflake non fornisce dati sull'utilizzo dei core di calcolo. L'unico parametro utilizzabile è il numero di micro-partizioni scansionate da una query: ciascuna può essere recuperata da un singolo core. Se una query scansiona meno micro-partizioni dei core disponibili nel warehouse, il warehouse risulterà sottoutilizzato nella fase di scansione della tabella. I solutions architect di Snowflake consigliano spesso di scegliere una dimensione di warehouse tale che a ogni core corrispondano circa quattro micro-partizioni scansionate. Il numero di micro-partizioni scansionate è visibile nel query profile oppure nelle view e nelle funzioni tabellari query_history.
2. RAM e storage locale
L'elaborazione dei dati richiede uno spazio in cui conservare i dataset intermedi. Al di là delle cache della CPU, la RAM è il luogo più veloce per memorizzare e recuperare dati. Una volta esaurita, Snowflake inizia a usare lo storage locale SSD per mantenere i dati tra una fase di esecuzione e l'altra. Questo comportamento prende il nome di "spillage to local storage": lo storage locale è comunque rapido, ma non quanto la RAM. Se anche lo storage locale si esaurisce, si passa allo storage remoto, ovvero l'object store del cloud provider (S3 nel caso di AWS). L'accesso allo storage remoto è decisamente più lento rispetto a quello locale, ma è praticamente illimitato: in questo modo Snowflake non interromperà mai una query per errori di out of memory. Lo spillage verso lo storage remoto è il segnale più chiaro di un warehouse sottodimensionato, e aumentarne la dimensione può velocizzare la query anche di oltre il doppio. Anche in questo caso, i volumi di spillage locale e remoto sono consultabili nel query profile oppure nelle view e nelle funzioni tabellari query_history.
Costo vs prestazioni
Le query CPU-bound raddoppiano in velocità all'aumentare della dimensione del warehouse, fino al punto in cui non riescono più a sfruttarne appieno le risorse. Trascurando i tempi di inattività dovuti alle soglie di auto-suspend, una query che gira due volte più velocemente su un Medium rispetto a uno Small avrà lo stesso costo, poiché costo = durata x tasso di consumo dei credit. Il grafico seguente illustra proprio questo: oltre un certo punto, il tempo di esecuzione sui warehouse più grandi resta invariato mentre il costo cresce. Come trovare allora il punto di equilibrio tra massime prestazioni e costo minimo?
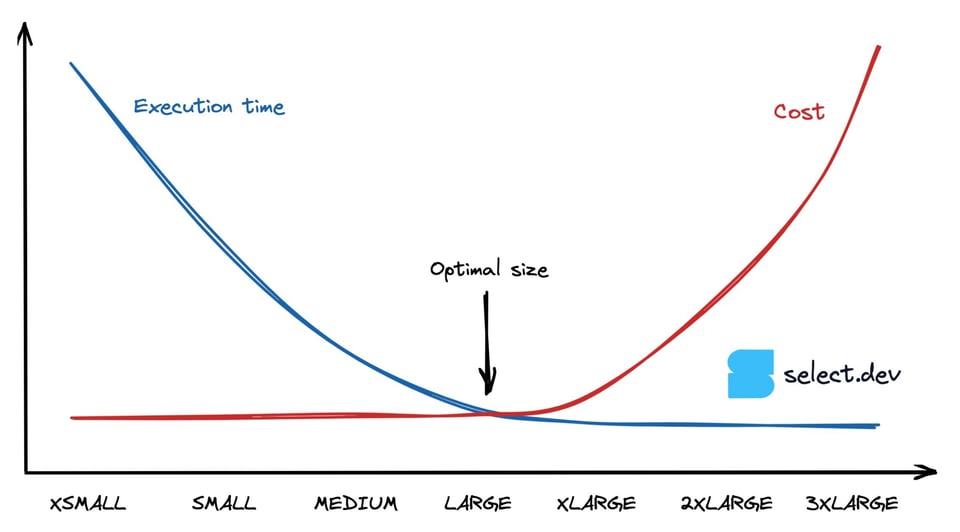
Come individuare la dimensione di warehouse migliore per una query Snowflake
Ecco il processo che consigliamo:
- Partire sempre da un X-Small.
- Aumentare la dimensione del warehouse finché la durata della query non smette di dimezzarsi. Quando questo accade, il warehouse non è più pienamente utilizzato.
- Per il miglior rapporto costo-prestazioni, scegliere la dimensione immediatamente inferiore. Per esempio, se passando da un Medium a un Large il tempo della query si riduce solo del 25%, conviene restare sul Medium. Se servono prestazioni più elevate, si può salire di taglia, ma a quel punto i ritorni saranno decrescenti.
Un warehouse può eseguire più query in parallelo: per la massima efficienza, dove possibile, conviene tenerli pienamente carichi, anche con un po' di queueing. I warehouse dedicati a query non-utente, come le pipeline di trasformazione, possono spesso girare con efficienza ancora maggiore proprio perché tollerano meglio il queueing.
Euristiche per riconoscere warehouse dimensionati male
L'unico modo per determinare con precisione la dimensione ottimale è sperimentare, ma l'esperienza ci ha insegnato alcuni segnali utili:
C'è spillage su disco remoto?
Una query con uno spillage su disco remoto rilevante raddoppia in genere la propria velocità quando si aumenta la dimensione del warehouse. Lo spillage su disco remoto è molto costoso in termini di tempo: eliminarlo fornendo più RAM e storage locale produce un grosso incremento di velocità e, se la query gira in meno della metà del tempo, si traduce anche in un risparmio.
C'è spillage su disco locale?
Lo spillage su disco locale non è grave come quello remoto, ma rallenta comunque le query. Aumentare la dimensione del warehouse le velocizzerà, ma difficilmente ne raddoppierà la rapidità, a meno che la query non sia anche CPU-bound. Vale comunque la pena provare.
La query gira in meno di 10 secondi?
Probabilmente non sta sfruttando appieno le risorse del warehouse, quindi può essere eseguita su un warehouse più piccolo in modo più conveniente.
Viste di esempio per riconoscere warehouse sovradimensionati
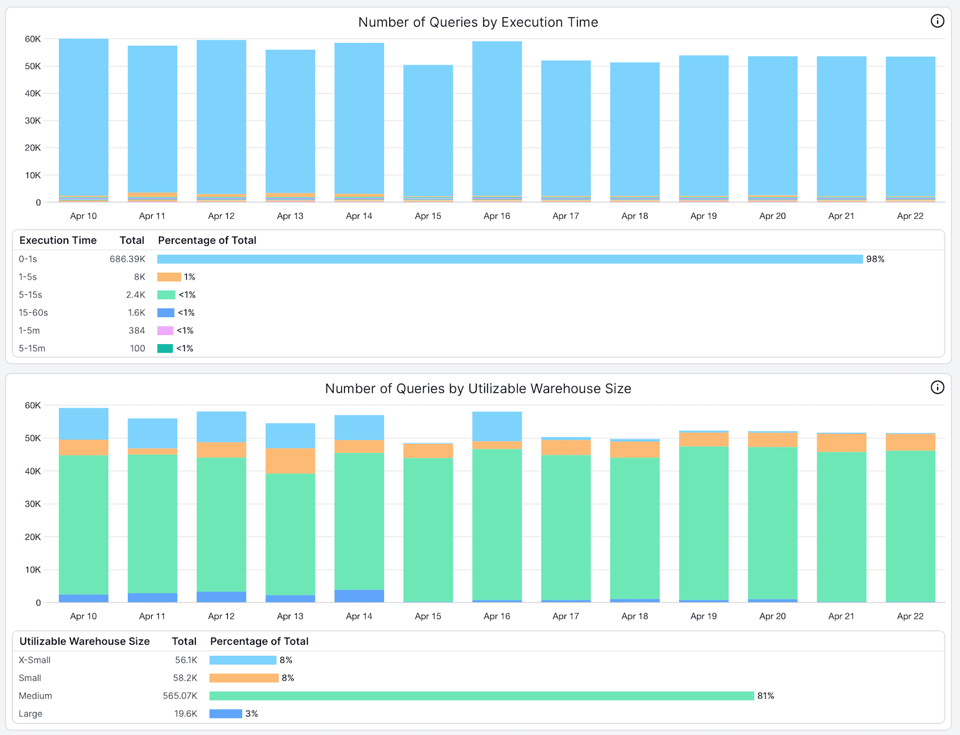
Ecco due viste utili che sfruttiamo nel prodotto SELECT per aiutare i clienti a dimensionare i warehouse:
- Il numero di query per tempo di esecuzione. Qui si nota che oltre il 98% delle query in esecuzione su questo warehouse impiega meno di 1 secondo.
- Il numero di query per dimensione di warehouse utilizzabile. La dimensione di warehouse utilizzabile rappresenta la taglia che una query è in grado di sfruttare appieno. Quando molte query non utilizzano interamente la dimensione del warehouse, significa che il warehouse è sovradimensionato o che quelle query andrebbero eseguite su un warehouse più piccolo. In questo esempio, oltre il 96% delle query eseguite sul warehouse non utilizza tutti gli 8 nodi disponibili nel warehouse Large.
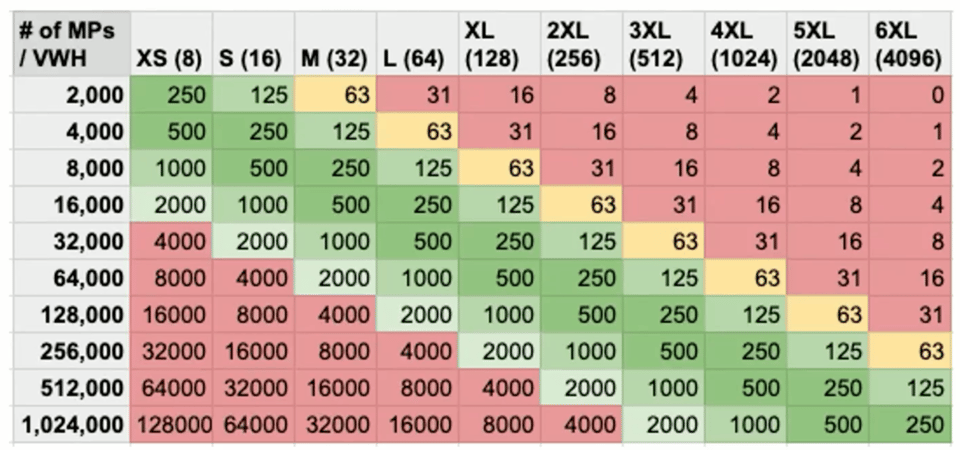
Le partizioni scansionate come euristica
Un'altra euristica utile è osservare quante micro-partizioni sta scansionando una query e scegliere la dimensione del warehouse di conseguenza. Questa strategia ci arriva da Scott Redding, resident solutions architect in Snowflake.
L'idea alla base è semplice: a ogni aumento di dimensione del warehouse il numero di thread disponibili per l'elaborazione raddoppia, e ciascun thread può elaborare una sola micro-partizione alla volta. L'obiettivo è fare in modo che ogni thread abbia lavoro a sufficienza (file da elaborare) per tutta la durata dell'esecuzione della query.
Per interpretare questo grafico, l'obiettivo è puntare a 250 micro-partizioni per thread. Se la query deve scansionare 2000 micro-partizioni, eseguirla su un X-Small assegnerà a ciascun thread 250 micro-partizioni (file) da elaborare, valore ideale. Eseguire invece la stessa query su un warehouse 3XL, che dispone di 512 thread, significa assegnare a ciascun thread solo 4 micro-partizioni: il risultato è che molti thread resteranno inutilizzati.
Il limite principale di questo approccio è che, pur essendo le micro-partizioni scansionate un fattore importante nell'esecuzione di una query, anche altri elementi come la complessità della query, gli exploding join e il volume di dati da ordinare incidono sulla potenza di elaborazione richiesta.
In chiusura
Snowflake rende semplice abbinare i workloads alle configurazioni di warehouse, e abbiamo visto query più che raddoppiare in velocità spendendo meno, semplicemente scegliendo la dimensione corretta. Aumentare la dimensione del warehouse non è però l'unica strada per velocizzare una query: molte query possono diventare più efficienti identificando e risolvendo i loro colli di bottiglia. Pubblicheremo una guida dettagliata sull'ottimizzazione delle query in un prossimo articolo; nel frattempo, se non l'ha ancora letto, dia un'occhiata al nostro articolo precedente sul clustering.
Se desidera essere avvisato alla pubblicazione dei prossimi articoli, si iscriva alla nostra mailing list qui sotto.
Niall Woodward·Co-founder & CTO di SELECT
Niall è Co-Founder & CTO di SELECT, piattaforma SaaS per la gestione e l'ottimizzazione dei costi su Snowflake. Prima di fondare SELECT, Niall è stato data engineer in Brooklyn Data Company e in diverse startup. Appassionato di open-source, è inoltre maintainer di SQLFluff e creatore di tre pacchetti dbt: dbt_artifacts, dbt_snowflake_monitoring e dbt_query_tags.