Snowflakeはコンピュート構成の自由度が高いのが魅力です。本記事では、仮想ウェアハウスのサイズがクエリ速度に与える影響と、最適なサイズを見極める手法をご紹介します。
クラスタのリサイズに時間がかかった時代はもう終わりました。Snowflakeなら、新しい仮想ウェアハウスの起動も既存ウェアハウスのリサイズも数秒で完了します。これによって得られるメリットは次のとおりです。
- コンピュートのアイドル時間を大幅に削減(自動サスペンドおよびマルチクラスタウェアハウスのスケールイン)
- workloadsに対するコンピュートパワーの最適な割り当て(ウェアハウスのプロビジョニング、解除、変更が容易)
workloadsをウェアハウス構成ごとに柔軟に振り分けられるようになれば、クエリ実行時間の短縮、コスト効率の向上、そしてデータチームとそのステークホルダーにとってのユーザー体験の改善が実現します。そこで気になるのが、次の問いです。
どのウェアハウスサイズを使うべきか?
この問いに答える前に、まずは仮想ウェアハウスとは何か、そしてサイズが利用可能なリソースとクエリ処理速度にどう影響するのかを押さえておきましょう。
Snowflakeの仮想ウェアハウスとは
Snowflakeはコンピュートノードを組み合わせてウェアハウスを構成します。X-Smallは1ノード、Smallは2ノード、Mediumは4ノード、と倍々で増えていきます。各ノードはクラウドプロバイダーを問わず8コア/スレッド構成です。仕様自体はSnowflakeから公式に公開されていませんが、AWS上では各ノード(5XLと6XLウェアハウスを除く)がc5d.2xlarge EC2インスタンスで、16GBのRAMと200GBのSSDを搭載しているのはよく知られています。仕様はクラウドプロバイダーごとに異なりますが、クラウド間で同等のパフォーマンスが得られるよう調整されています。
ウェアハウス内のノードは物理的には分離されていますが連携して動作し、Snowflakeは単一のクエリに対してすべてのノードを活用できます。したがって、ウェアハウスサイズが1段階上がるごとに、利用可能なコア数・RAM・ディスク容量が倍増するものと考えて差し支えありません。
利用できる仮想ウェアハウスサイズ
Snowflakeはウェアハウスにtシャツサイズの名称を採用していますが、tシャツと違って1サイズ上がるごとにリソースとクレジット消費量が倍になります。サイズはX-Smallから6X-Largeまで用意されています。多くのSnowflakeユーザーは最小サイズのX-Smallしか使いません。workloadsの複雑さにもよりますが、数十ギガバイト程度までのデータセットであればX-Smallで十分なパワーが得られるからです。
| ウェアハウスサイズ | クレジット/時間 | Snowpark最適化クレジット/時間 |
|---|---|---|
| X-Small | 1 | N/A |
| Small | 2 | N/A |
| Medium | 4 | 6 |
| Large | 8 | 12 |
| X-Large | 16 | 24 |
| 2X-Large | 32 | 48 |
| 3X-Large | 64 | 96 |
| 4X-Large | 128 | 192 |
| 5X-Large | 256 | 384 |
| 6X-Large | 512 | 768 |
ウェアハウスサイズがSnowflakeのクエリ速度に与える影響
1. 処理能力
Snowflakeは並列処理を活用し、高速化が見込める場面では複数コアにクエリを分散して実行します。コア数が増えれば処理能力も高まるため、ウェアハウスが大きいほどクエリが速く完了しやすいのです。
ただし、クエリを複数コアに分散して最後に結果セットを統合する処理にはオーバーヘッドが伴います。そのため、データ量によってはコアを増やして分散するほうがかえって遅くなる場合もあります。そうしたケースではSnowflakeはそれ以上分散せず、ウェアハウスサイズを上げても速度向上は得られません。
残念ながら、Snowflakeはコンピュートコアの利用率に関するデータを提供していません。判断材料となるのは、クエリがスキャンしたマイクロパーティション数のみです。各マイクロパーティションは1つのコアで取得できます。スキャンするマイクロパーティション数がウェアハウスのコア数より少ない場合、テーブルスキャンの段階でウェアハウスは十分に活用されません。Snowflakeのソリューションアーキテクトは、1コアあたりおよそ4マイクロパーティションがスキャンされる程度のウェアハウスサイズを選ぶことを推奨しています。スキャンされたマイクロパーティション数はクエリプロファイル、またはquery_historyビューおよびテーブル関数で確認できます。
2. RAMとローカルストレージ
データ処理には、中間データセットを置く場所が必要になります。CPUキャッシュを除けば、RAMが最も高速な読み書き先です。RAMを使い切ると、Snowflakeはクエリ実行ステップ間でデータを保持するためにSSDのローカルストレージを使い始めます。これが「ローカルストレージへのスピレッジ」と呼ばれる挙動で、ローカルストレージへのアクセスは十分に高速ではあるものの、RAMには及びません。ローカルストレージも尽きると、今度はリモートストレージが使われます。リモートストレージとはクラウドプロバイダーのオブジェクトストア(AWSであればS3)を指します。リモートストレージはローカルストレージよりかなりアクセスが遅いものの、容量は事実上無制限であるため、Snowflakeがメモリ不足エラーでクエリを中断することはありません。リモートストレージへのスピレッジは、ウェアハウスが小さすぎることを示す最も明確なサインで、サイズを上げるとクエリ速度が2倍以上向上することもあります。ローカル・リモートのスピレッジ量はいずれもクエリプロファイル、またはquery_historyビューおよびテーブル関数で確認できます。
コストとパフォーマンスのバランス
CPUバウンドのクエリはウェアハウスサイズを上げるごとに速度が倍になり、ウェアハウスのリソースを使い切れなくなった時点で頭打ちになります。自動サスペンドの閾値によるアイドル時間を無視すれば、MediumウェアハウスでSmallの2倍の速さで完了するクエリのコストは、Smallで実行した場合と同じです(コスト = 実行時間 × クレジット消費レートのため)。下のグラフはこの挙動を示しており、ある地点を超えるとウェアハウスを大きくしても実行時間は変わらず、コストだけが膨らんでいきます。では、最小コストで最大のパフォーマンスを得られる「スイートスポット」はどう見つければよいのでしょうか。
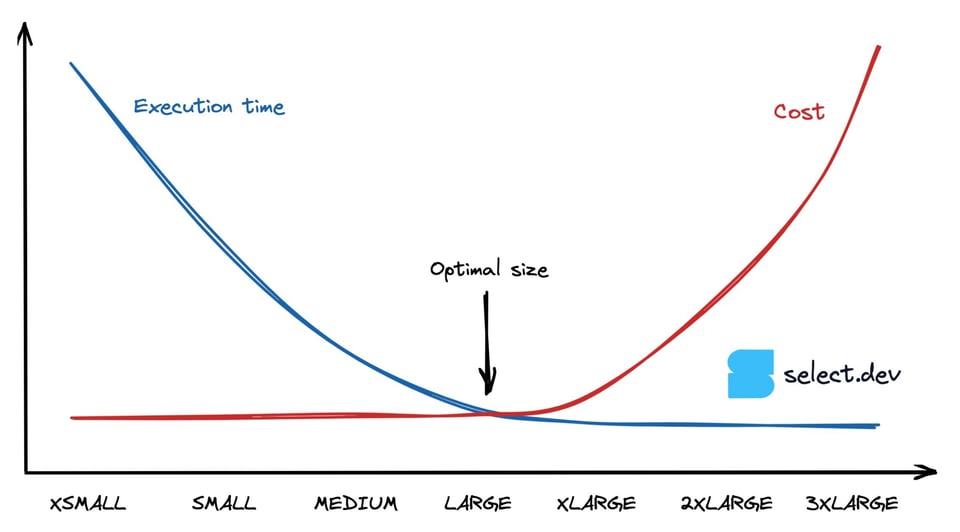
Snowflakeクエリに最適なウェアハウスサイズを見極める
おすすめの進め方は次のとおりです。
- まずは必ずX-Smallから始める。
- クエリ実行時間が半減しなくなるまでウェアハウスサイズを上げる。半減しなくなったら、ウェアハウスのリソースを使い切れていないサインです。
- コストパフォーマンスを最大化するなら、その1つ下のサイズを選びます。たとえばMediumからLargeに上げてもクエリ時間が25%しか短くならないのであれば、Mediumを使うのが正解です。さらに速さが必要であればより大きなサイズを使う選択もありますが、この段階では収穫逓減になる点に注意してください。
ウェアハウスは複数のクエリを同時に実行できるため、可能な限りフル稼働させ、軽いキューイングがある状態を保つのが効率最大化のポイントです。トランスフォーメーションパイプラインなどユーザー操作以外のクエリ用ウェアハウスは、キューイングへの許容度が高い分、より高い効率で運用しやすい傾向にあります。
サイズが合っていないウェアハウスを見抜くヒューリスティック
最適なウェアハウスサイズを正確に判断するには実験が欠かせませんが、経験から得たいくつかの判断材料を紹介します。
リモートディスクへのスピレッジは発生していないか?
リモートディスクへのスピレッジが大量に発生しているクエリは、通常ウェアハウスサイズを上げるだけで速度が少なくとも2倍になります。リモートディスクへのスピレッジは非常に時間がかかる処理であり、より多くのRAMとローカルストレージを割り当てて解消すれば大幅な速度向上が得られます。実行時間が半分以下になれば、コストも下げられます。
ローカルディスクへのスピレッジは発生していないか?
ローカルディスクへのスピレッジはリモートディスクほど深刻ではありませんが、それでもクエリは遅くなります。ウェアハウスサイズを上げればクエリは速くなりますが、CPUバウンドでもない限り、2倍まで速くなる可能性は低めです。それでも試す価値はあります。
クエリの実行時間は10秒未満か?
その場合、クエリはウェアハウスのリソースを使い切れていない可能性が高く、より小さなウェアハウスでコスト効率よく実行できます。
オーバーサイズのウェアハウスを見つけるためのビュー例
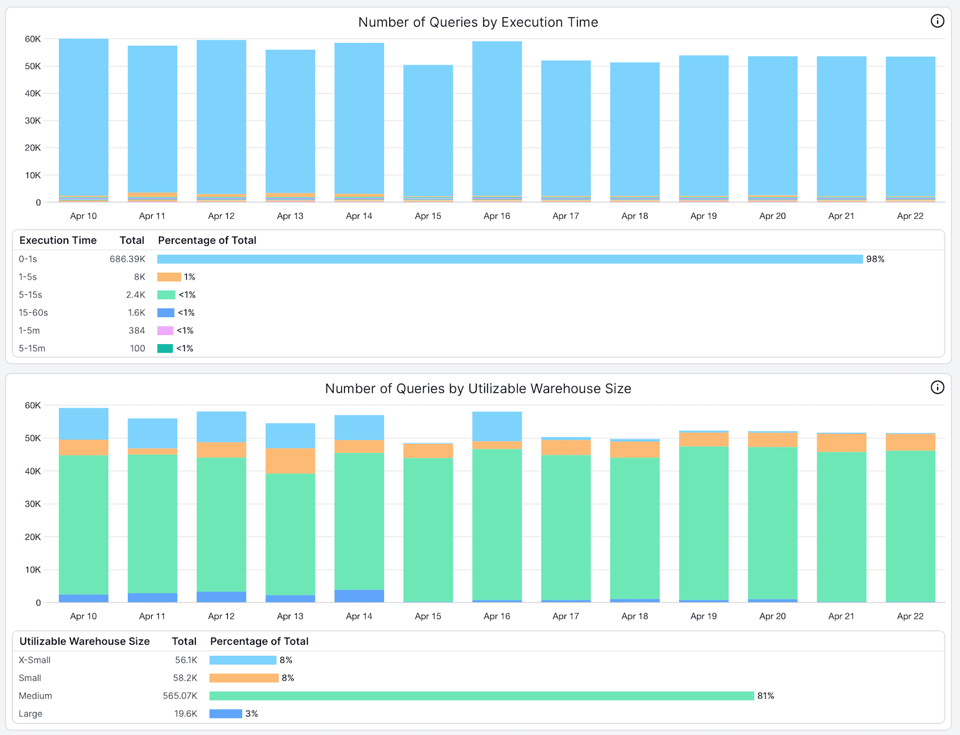
SELECTでは、ウェアハウスのサイジングを支援するために以下の2つのビューを活用しています。
- 実行時間別のクエリ数。この例では、当該ウェアハウスで実行されているクエリの98%以上が1秒未満で完了していることがわかります。
- 活用可能なウェアハウスサイズ別のクエリ数。「活用可能なウェアハウスサイズ」とは、そのクエリが完全に使い切れるウェアハウスサイズを指します。多くのクエリがウェアハウスのサイズを使い切れていない場合、それはウェアハウスがオーバーサイズであるか、より小さなウェアハウスで実行すべきであることを示します。この例では、Largeウェアハウスで実行されているクエリの96%以上が、利用可能な8ノードをすべて使えていません。
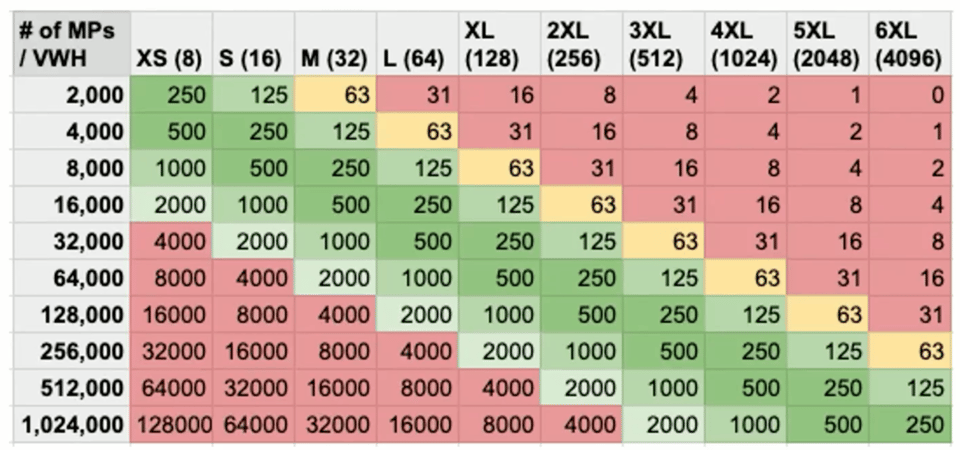
スキャンしたパーティション数を判断材料にする
もう1つ役立つ手法が、クエリがスキャンするマイクロパーティションの数を確認し、それに基づいてウェアハウスサイズを選ぶ方法です。これはSnowflakeの常駐ソリューションアーキテクトであるScott Redding氏が提唱しています。
この手法の考え方は、ウェアハウスサイズが1段階上がるごとに利用可能なスレッド数が倍増し、各スレッドは一度に1つのマイクロパーティションを処理できる、というものです。クエリ実行中、各スレッドが処理すべき作業(ファイル)を十分に持っている状態を目指します。
このチャートの読み方として、1スレッドあたり250マイクロパーティションを目安にします。たとえばクエリが2000マイクロパーティションをスキャンする必要がある場合、X-Smallで実行すれば各スレッドに250マイクロパーティション(ファイル)が割り当てられ、ちょうど良いバランスになります。一方、3XLウェアハウスで実行すると512スレッドあるため、各スレッドに割り当てられるのはわずか4マイクロパーティションだけで、多くのスレッドが遊んでしまう結果になりがちです。
このアプローチの落とし穴は、スキャンしたマイクロパーティション数はクエリ実行を左右する重要な要素ではあるものの、クエリの複雑さ、結合による行数の爆発、ソート対象のデータ量など、他の要因も必要な処理能力に影響を与えるという点です。
まとめ
Snowflakeを使えば、workloadsとウェアハウス構成のマッチングは容易です。私たちは、適切なウェアハウスサイズを選ぶだけでクエリ速度が2倍以上になり、しかもコストが下がる事例を数多く見てきました。とはいえ、クエリを高速化する手段はウェアハウスサイズの拡大だけではありません。ボトルネックを特定して解消すれば、多くのクエリはさらに効率よく実行できるようになります。クエリ最適化の詳しいガイドは今後の記事で取り上げる予定ですが、まだの方はぜひ前回のクラスタリングに関する記事もご覧ください。
今後の記事公開のお知らせを受け取りたい方は、下記のメーリングリストにご登録ください。
Niall Woodward・Co-founder & CTO of SELECT
NiallはSaaS型のSnowflakeコスト管理・最適化プラットフォームSELECTの共同創業者兼CTOです。SELECT創業前は、Brooklyn Data Companyや複数のスタートアップでデータエンジニアを務めていました。オープンソース愛好家でもあり、SQLFluffのメンテナーを務めるほか、3つのdbtパッケージ(dbt_artifacts、dbt_snowflake_monitoring、dbt_query_tags)の作者でもあります。