Quem usa Snowflake tem muita flexibilidade para configurar o compute. Neste post, mostramos como o dimensionamento do virtual warehouse afeta a velocidade das queries e compartilhamos algumas técnicas para definir o tamanho ideal.
O tempo de redimensionar clusters de forma lenta e complicada ficou para trás: o Snowflake permite subir um novo virtual warehouse ou redimensionar um existente em questão de segundos. Isso traz dois efeitos importantes:
- Queda significativa no compute ocioso (com auto-suspend e scale-in para warehouses multi-cluster)
- Melhor encaixe entre poder de compute e workloads (mais facilidade para provisionar, desprovisionar e ajustar warehouses)
Conseguir alocar workloads facilmente em diferentes configurações de warehouse se traduz em queries mais rápidas, gasto mais eficiente e uma experiência melhor para os times de dados e suas áreas parceiras. O que leva à pergunta:
Qual tamanho de warehouse devo usar?
Antes de responder, vamos entender o que é um virtual warehouse e como o tamanho dele impacta os recursos disponíveis e a velocidade de processamento das queries.
O que é um virtual warehouse no Snowflake?
O Snowflake monta os warehouses a partir de nós de compute. O X-Small usa um único nó, o Small usa dois, o Medium usa quatro, e assim por diante. Cada nó tem 8 cores/threads, independentemente do provedor de nuvem. As especificações não são divulgadas pelo Snowflake, mas é amplamente conhecido que, na AWS, cada nó (exceto nos warehouses 5XL e 6XL) é uma instância EC2 c5d.2xlarge, com 16GB de RAM e SSD de 200GB. As especificações variam entre provedores de nuvem e foram escolhidas para entregar performance equivalente em todas elas.
Apesar de fisicamente separados, os nós de cada warehouse trabalham em conjunto, e o Snowflake pode usar todos eles para uma única query. Por isso, podemos partir do princípio de que cada degrau no tamanho do warehouse dobra a quantidade disponível de cores de compute, RAM e espaço em disco.
Quais tamanhos de virtual warehouse estão disponíveis?
O Snowflake nomeia os warehouses como tamanhos de camiseta, mas, diferentemente das camisetas, cada degrau acima representa o dobro de recursos e de consumo de créditos. Os tamanhos vão de X-Small a 6X-Large. A maioria dos usuários do Snowflake só vai precisar do menor deles, o X-Small, já que ele dá conta da maioria dos datasets de até dezenas de gigabytes, dependendo da complexidade dos workloads.
| Tamanho do Warehouse | Créditos / Hora | Créditos Snowpark-Optimized / Hora |
|---|---|---|
| X-Small | 1 | N/D |
| Small | 2 | N/D |
| Medium | 4 | 6 |
| Large | 8 | 12 |
| X-Large | 16 | 24 |
| 2X-Large | 32 | 48 |
| 3X-Large | 64 | 96 |
| 4X-Large | 128 | 192 |
| 5X-Large | 256 | 384 |
| 6X-Large | 512 | 768 |
O impacto do tamanho do warehouse na velocidade das queries no Snowflake
1. Poder de processamento
O Snowflake usa processamento paralelo para executar uma query em vários cores sempre que isso for mais rápido. Mais cores significam mais poder de processamento, e é por isso que as queries costumam rodar mais rápido em warehouses maiores.
Só que existe um overhead para distribuir uma query entre vários cores e depois juntar o resultado no fim. Ou seja, dependendo do volume de dados, pode até ficar mais lento rodar a query em mais cores. Quando isso acontece, o Snowflake para de distribuir a query para cores adicionais, e aumentar o tamanho do warehouse não traz ganho de velocidade.
Infelizmente, o Snowflake não disponibiliza dados sobre a utilização dos cores de compute. O único indicador disponível é o número de micro-partições escaneadas pela query. Cada micro-partição pode ser lida por um core individual. Se a query escaneia menos micro-partições do que o número de cores do warehouse, ele ficará subutilizado na etapa de table scan. Os solutions architects do Snowflake costumam recomendar escolher um tamanho de warehouse em que cada core processe, em média, quatro micro-partições. Esse número pode ser conferido no query profile ou na view e nas table functions de query_history.
2. RAM e armazenamento local
O processamento de dados precisa de um lugar para guardar conjuntos intermediários. Tirando os caches da CPU, a RAM é o local mais rápido para gravar e ler dados. Quando ela acaba, o Snowflake passa a usar o armazenamento local em SSD para manter dados entre as etapas de execução da query. Esse comportamento é chamado de "spillage to local storage" — o armazenamento local ainda é rápido, mas não tanto quanto a RAM. Se o armazenamento local também se esgotar, entra em cena o armazenamento remoto, ou seja, o object store do provedor de nuvem (o S3, no caso da AWS). O acesso ao armazenamento remoto é bem mais lento do que ao local, mas é infinito, o que significa que o Snowflake nunca aborta uma query por falta de memória. Spillage para armazenamento remoto é o sinal mais claro de que o warehouse está subdimensionado, e aumentar o tamanho pode mais do que dobrar a velocidade da query. Os volumes de spillage local e remoto também aparecem no query profile ou na view e nas table functions de query_history.
Custo vs. performance
Queries CPU-bound dobram de velocidade conforme o warehouse cresce, até o ponto em que deixam de aproveitar todos os recursos disponíveis. Desconsiderando o tempo ocioso causado pelos limites de auto-suspend, uma query que roda duas vezes mais rápido em um Medium do que em um Small custa o mesmo, já que custo = duração x taxa de consumo de créditos. O gráfico abaixo ilustra esse comportamento: a partir de certo ponto, o tempo de execução em warehouses maiores se mantém igual enquanto o custo continua subindo. Então, como encontrar o ponto ideal de performance máxima pelo menor custo?
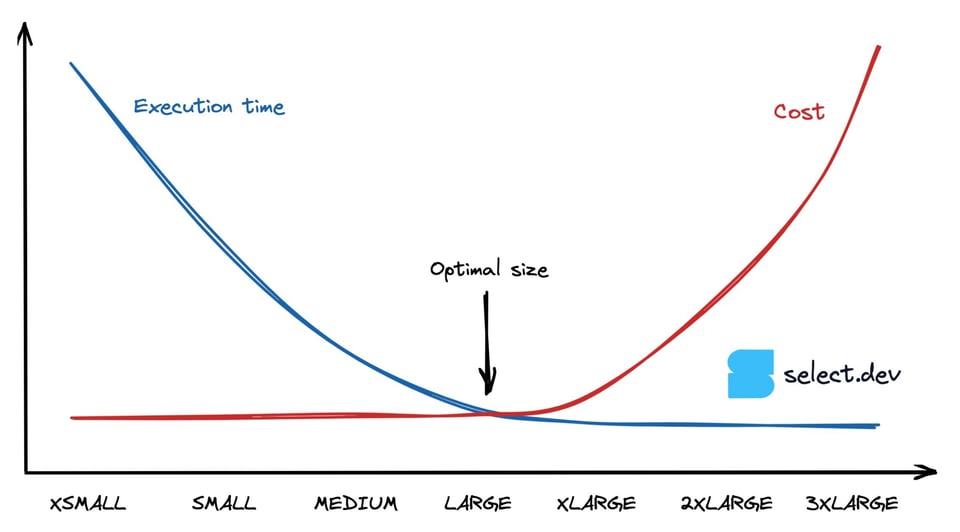
Como definir o melhor tamanho de warehouse para uma query no Snowflake
O processo que recomendamos é o seguinte:
- Comece sempre com um X-Small.
- Aumente o tamanho do warehouse até que a duração da query pare de cair pela metade. Quando isso acontece, o warehouse já não está sendo aproveitado por completo.
- Para a melhor relação custo-performance, escolha o tamanho imediatamente anterior. Por exemplo, se ir de Medium para Large reduz o tempo da query em apenas 25%, fique com o Medium. Se precisar de mais performance, use um warehouse maior, mas tenha em mente que, a partir desse ponto, os ganhos vão diminuindo.
Um warehouse pode rodar mais de uma query ao mesmo tempo, então, sempre que possível, mantenha os warehouses bem ocupados — e até com um pouco de fila — para máxima eficiência. Warehouses voltados a queries não interativas, como pipelines de transformação, costumam operar com eficiência ainda maior, pois toleram melhor o enfileiramento.
Heurísticas para identificar warehouses mal dimensionados
Só a experimentação determina com precisão o melhor tamanho de warehouse, mas alguns indicadores que aprendemos na prática ajudam bastante:
Há spillage para o disco remoto?
Uma query com spillage relevante para disco remoto costuma, no mínimo, dobrar de velocidade quando o warehouse aumenta. O spillage remoto consome muito tempo, e eliminá-lo oferecendo mais RAM e armazenamento local gera um grande ganho de velocidade — e ainda economiza dinheiro, se a query terminar em menos da metade do tempo.
Há spillage para o disco local?
O spillage local não chega nem perto de ser tão ruim quanto o remoto, mas mesmo assim deixa as queries mais lentas. Aumentar o tamanho do warehouse acelera a query, mas dificilmente dobra a velocidade, a não ser que ela também seja CPU-bound. Ainda assim, vale o teste!
A query roda em menos de 10 segundos?
Provavelmente ela não está aproveitando todos os recursos do warehouse, ou seja, dá para rodá-la em um warehouse menor de forma mais econômica.
Exemplos de views para identificar warehouses superdimensionados
Veja duas views úteis que usamos no produto SELECT para ajudar nossos clientes a dimensionar warehouses:
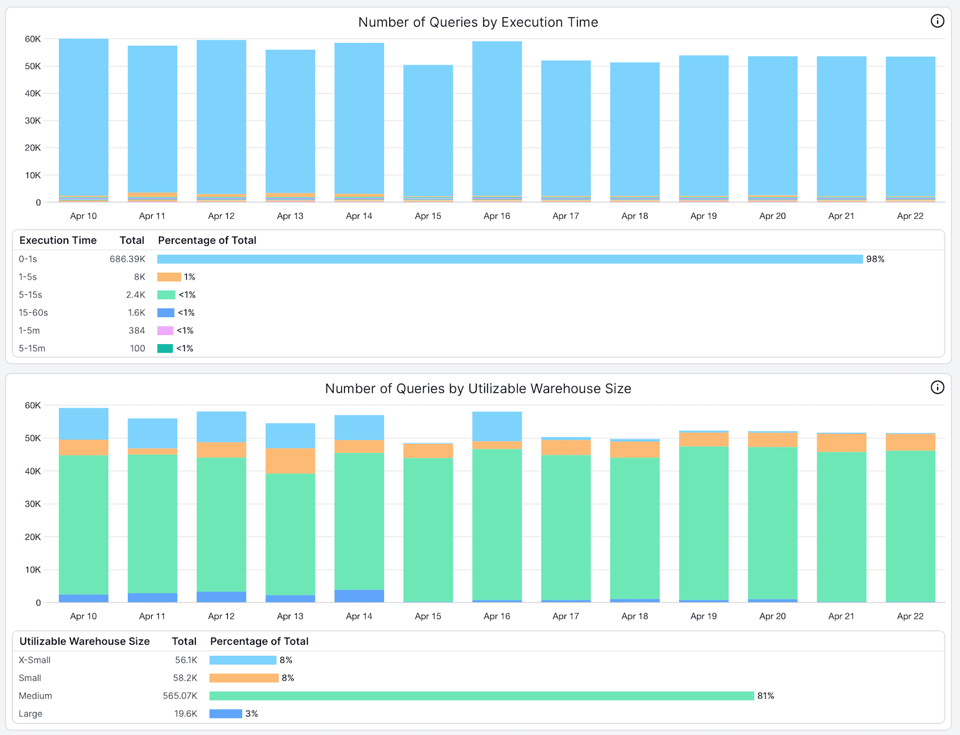
- Número de queries por tempo de execução. Aqui dá para ver que mais de 98% das queries rodando nesse warehouse demoram menos de 1 segundo para executar.
- Número de queries por tamanho utilizável de warehouse. O tamanho utilizável representa o tamanho de warehouse que uma query consegue aproveitar por completo. Quando muitas queries não aproveitam o tamanho do warehouse, é sinal de que ele está superdimensionado ou de que essas queries deveriam rodar em um warehouse menor. Neste exemplo, mais de 96% das queries que rodam no warehouse não estão usando todos os 8 nós disponíveis no Large.
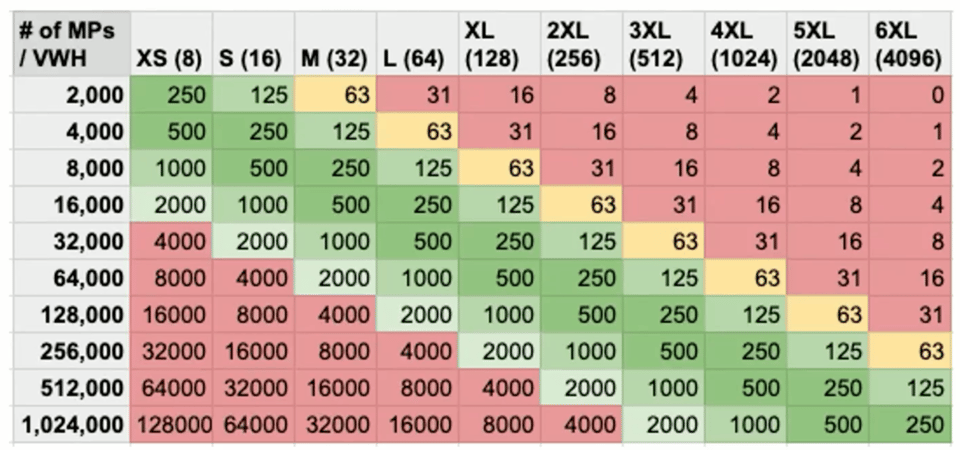
Usar partições escaneadas como heurística
Outra heurística útil é olhar quantas micro-partições a query está escaneando e, a partir disso, escolher o tamanho do warehouse. Essa estratégia vem do Scott Redding, resident solutions architect no Snowflake.
A lógica por trás dessa estratégia é que o número de threads disponíveis para processamento dobra a cada aumento de tamanho de warehouse, e cada thread consegue processar uma micro-partição por vez. A ideia é garantir que toda thread tenha bastante trabalho (arquivos para processar) durante toda a execução da query.
Para interpretar o gráfico, o alvo é 250 micro-partições por thread. Se sua query precisa escanear 2.000 micro-partições, rodá-la em um X-Small dá 250 micro-partições (arquivos) para cada thread processar — o cenário ideal. Compare com rodar a mesma query em um warehouse 3XL, que tem 512 threads: cada uma receberia só 4 micro-partições, deixando muitas threads ociosas.
A principal armadilha dessa abordagem é que, embora o número de micro-partições escaneadas seja um fator importante na execução da query, outros elementos — como complexidade da query, exploding joins e volume de dados ordenados — também influenciam o poder de processamento necessário.
Conclusão
O Snowflake facilita o ajuste dos workloads às configurações de warehouse, e já vimos queries mais do que dobrarem de velocidade — e ainda custarem menos — só com a escolha do tamanho certo. Mas aumentar o tamanho do warehouse não é a única forma de deixar uma query mais rápida: muitas podem ganhar eficiência quando seus gargalos são identificados e resolvidos. Vamos publicar um guia detalhado sobre otimização de queries em um próximo post, mas, se ainda não leu, dá uma olhada no nosso post anterior sobre clustering.
Se quiser receber um aviso quando publicarmos novos posts, assine nossa newsletter abaixo.
Niall Woodward · Co-founder e CTO do SELECT
Niall é Co-Founder e CTO do SELECT, uma plataforma SaaS de gestão e otimização de custos no Snowflake. Antes de fundar o SELECT, Niall foi data engineer na Brooklyn Data Company e em várias startups. Entusiasta de open-source, ele também é mantenedor do SQLFluff e criador de três pacotes dbt: dbt_artifacts, dbt_snowflake_monitoring e dbt_query_tags.