Daten effizient in Ihren Snowflake-Account zu laden, ist entscheidend. Snowflake bietet dafür verschiedene Ingestion-Optionen – jede mit eigenen Vor- und Nachteilen sowie wichtigen Aspekten, die zu beachten sind.
Kunden haben mehrere Möglichkeiten für Batch- sowie für kontinuierliches und Echtzeit-Laden. Alle skalieren so, dass sich auch große Datensätze verarbeiten lassen. Die Wahl der richtigen Option wirkt sich auf Kosten, Performance, Zuverlässigkeit und Wartungsaufwand aus – jeder dieser Faktoren sollte berücksichtigt werden.
In diesem Blogpost gehe ich detailliert auf die fünf Ladeoptionen ein und beleuchte die jeweiligen Trade-offs wie Latenz, Kosten, Wartung und erforderliches technisches Know-how. Außerdem erfahren Sie Best Practices zu jeder Methode. Am Ende fasse ich die Optionen zusammen und gebe Ihnen Leitlinien für die Entscheidung an die Hand.
Batch-Loading
Batch-Loading ist der gängigste Ingestion-Ansatz in Data Warehouses. Dabei werden Daten nach einem festen Zeitplan (z. B. einmal täglich, stündlich oder alle 4 Stunden) gebündelt ins Data Warehouse geladen. Batch-Loading ist meist die einfachste Option, bringt aber einen großen Trade-off mit sich: die Latenz. Werden Ihre Daten einmal täglich geladen, können sie bis zum nächsten Ladevorgang über 24 Stunden alt sein.
Typischerweise läuft Batch-Ingestion so ab: Dateien werden aus dem Cloud Storage (Amazon S3 Bucket, Microsoft Azure Blob Storage oder Google Cloud Storage) bezogen, und ein Prozess oder Orchestrierungstool lädt diese Daten zeitgesteuert automatisch in Snowflake.
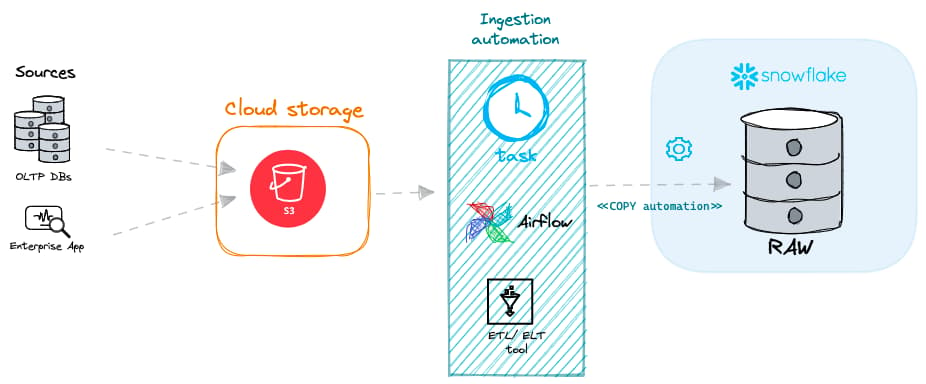
In Snowflake gibt es zwei Hauptansätze für die Batch-Ingestion.
Batch-Loading mit einem eigenen Virtual Warehouse
Erfahrungsgemäß ist die häufigste Methode, Daten in Snowflake zu laden, das Ausführen des COPY INTO-Befehls auf einem eigenen Virtual Warehouse.
Der Befehl nimmt Dateien, die zuvor in einen Internal Stage oder External Stage von Snowflake hochgeladen wurden, und lädt sie in die Zieltabelle. Das können CSV-Dateien, JSON-Daten oder andere unterstützte Dateiformate sein.
Der COPY-Befehl läuft auf einem Ihrer eigenen Virtual Warehouses. Das heißt: Sie sind dafür verantwortlich, das Warehouse zu erstellen und korrekt zu dimensionieren (Tipp: Starten Sie immer mit einem X-SMALL-Warehouse und skalieren Sie nur hoch, wenn Sie Ihr SLA sonst nicht einhalten können).
Kosten- und Effizienzaspekte
Beim Laden von Daten mit dem COPY INTO-Befehl zahlen Sie für jede Sekunde, in der das Virtual Warehouse aktiv ist. Snowflake-Warehouses werden bei jedem Start für mindestens 60 Sekunden abgerechnet – Sie sollten also darauf achten, dass Ihr Ladeprozess möglichst nahe an diese 60 Sekunden herankommt.
Das kleinste Virtual Warehouse kann 8 Dateien parallel verarbeiten. Diese Zahl verdoppelt sich mit jeder Warehouse-Größe. Um ein Medium-Warehouse vollständig auszulasten, bräuchten Sie also 32 Dateien. Ist eine Datei deutlich größer als die anderen, kann es passieren, dass die übrigen Threads ungenutzt bleiben, während nur ein Thread arbeitet.
Batch-Loading auf einem eigenen Virtual Warehouse kann eine der kosteneffizientesten Möglichkeiten sein, Daten in Snowflake zu laden – vorausgesetzt, Sie haben genug Dateien und Daten, um das Warehouse voll auszulasten, und zahlen nicht für Leerlauf. Werfen Sie unbedingt auch einen Blick in unseren Blogpost zu Best Practices für das Batch-Loading.
Erforderliche Skills
Für den COPY-Befehl brauchen Sie über grundlegende SQL-Kenntnisse hinaus keine weiteren Skills.
Sie benötigen lediglich ein Scheduling- oder Orchestrierungstool, das den COPY-Befehl im gewünschten Takt ausführt.
Batch-Loading mit Serverless Tasks
Serverless Tasks ermöglichen es Snowflake-Nutzern, SQL-Befehle nach einem definierten Zeitplan auf Snowflake-Compute-Ressourcen statt auf einem eigenen Virtual Warehouse auszuführen. Sie können einen Serverless Task einrichten, der den COPY INTO-Befehl in der gewünschten Frequenz ausführt.
Wie beim Ausführen des COPY INTO-Befehls auf einem eigenen Warehouse ist die Latenz bzw. Aktualität Ihrer Daten daran gekoppelt, wie häufig Sie den COPY-Befehl zum Laden neuer Daten ausführen.
Kosten- und Effizienzaspekte
Da Sie nur pro Sekunde tatsächlich genutzter Compute-Leistung zahlen, entschärfen Serverless Tasks das Problem ungenutzter Compute-Kapazität, das beim Batch-Loading auf einem eigenen Warehouse entstehen kann. Dauert Ihr Ladeprozess pro Lauf nur 10 Sekunden, zahlen Sie auf einem eigenen Warehouse jedes Mal 50 Sekunden Compute zusätzlich.
Die Compute-Kosten für Serverless Tasks werden mit dem 1,5-fachen Satz eines vergleichbar großen, selbst verwalteten Virtual Warehouse berechnet. Aus reiner Kostensicht sollten Sie sie daher nur einsetzen, wenn Sie ein Virtual Warehouse nicht für mindestens 40 Sekunden des 60-Sekunden-Mindestabrechnungszeitraums auslasten können.
Erforderliche Skills
Das Laden von Daten in Snowflake mit einem Serverless Task ist wohl die einfachste Ingestion-Option überhaupt. Sie benötigen lediglich solide SQL-Kenntnisse und keine externen Orchestrierungstools.
Kontinuierliches Laden mit Snowpipe
Anders als das Batch-Processing, das nach einem festen Zeitplan läuft, verarbeitet das kontinuierliche Laden Daten ereignisbasiert – meist, sobald eine neue Datei im Cloud Storage eintrifft. Die Quellen können vielfältig sein: ein Change-Data-Capture-Service, der Änderungen in einer relationalen Datenbank protokolliert, oder Event-Daten aus Webanwendungen. Jede neue Datei löst eine Event-Notification aus, die den Ladeprozess automatisch anstößt. Cloudbasierte Messaging-Dienste wie AWS SNS oder SQS werden häufig genutzt, um diese Benachrichtigungen zu versenden. Sie lassen sich direkt mit Snowflake integrieren und informieren die Plattform über neu eingetroffene Dateien.
Beim kontinuierlichen Laden ist die Datenlatenz deutlich geringer, da neue Daten geladen werden, sobald sie verfügbar sind.
Um das Laden zu vereinfachen und kontinuierliches Verarbeiten zu ermöglichen, bietet Snowflake ein leistungsstarkes Feature namens Snowpipe. Snowpipe ist mit einem Event-Notification-Service des Cloud-Anbieters (z. B. AWS SNS/SQS) integriert. Zu jedem Snowpipe-Objekt gehört ein zugeordneter COPY-Befehl. Die Event-Notifications informieren das Snowpipe-Objekt über neu eingetroffene Dateien in einem External Stage, woraufhin der entsprechende COPY-Befehl ausgeführt wird.
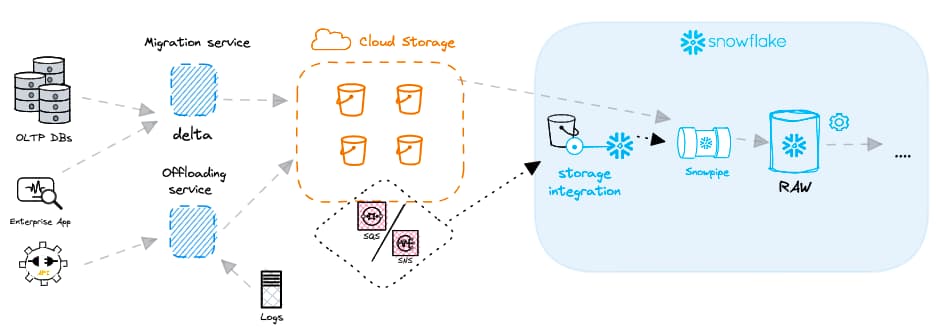
Die meisten Kunden nutzen das "Auto-Ingest"-Feature von Snowpipe, bei dem Dateien automatisch geladen werden, sobald sie eintreffen. Es gibt aber auch eine REST-API für Snowpipe, mit der Sie selbst bestimmen, wann ein Snowpipe-Objekt ausgelöst wird.
Snowpipe ist ein Serverless-Feature: Sie müssen sich weder um die Auswahl noch um die richtige Dimensionierung eines Virtual Warehouse kümmern. Die Compute-Ressourcen werden vollständig von Snowflake verwaltet. Bei der Latenz lädt Snowpipe Dateien typischerweise innerhalb weniger Minuten nach dem Eintreffen im Cloud Storage.
Kosten- und Effizienzaspekte
Den größten Einfluss auf die Kosteneffizienz von Snowpipe hat die Dateigröße. Snowpipe berechnet eine Overhead-Gebühr von 0,06 Credits pro 1.000 verarbeitete Dateien. Die Kosten für das Laden von 100 GB können deshalb je nach Dateigröße erheblich variieren, da diese die Anzahl der Dateien bestimmt. Compute-Ressourcen werden bei Snowpipe mit 1,25 Credits pro Compute-Stunde abgerechnet.
Snowflake empfiehlt eine komprimierte Dateigröße von 100–250 MB. Wenn Ihre vorgelagerten Anwendungen häufig kleine Dateien liefern, sollten Sie einen Prozess implementieren, der die Dateien zu größeren Batches aggregiert. Ein gängiger Dienst dafür ist Amazon Kinesis Firehose. Alternativ kommen andere Echtzeit-Verarbeitungsoptionen wie Snowpipe Streaming (siehe unten) infrage.
Erforderliche Skills
Um einen Snowpipe-Ladejob einzurichten, benötigen Sie Zugriff auf Ihren Cloud-Anbieter, um den erforderlichen Event-Notification-Service zu konfigurieren.
Sobald Cloud Storage und Event-Notification-Service eingerichtet sind, lässt sich das Snowpipe-Objekt vollständig in SQL konfigurieren.
Echtzeit-Laden mit Kafka
In vielen Branchen gibt es Anwendungsfälle, die Echtzeitdaten erfordern: Kreditbewertung, Betrugsanalyse oder nutzerseitige Analytics. Daten mit niedriger Latenz bereitzustellen, gelingt typischerweise über einen Message Broker wie Apache Kafka. Statt Dateien empfängt Kafka Nachrichten von verschiedenen "Data Producern" und liefert diese an unterschiedliche "Data Consumer" aus. Beim Datenladen wird Snowflake zum Data Consumer.
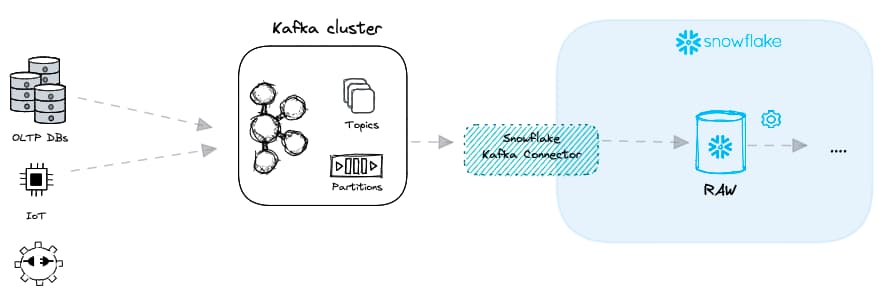
Kafka in Kombination mit Snowflake für Low-Latency-Datenladen lässt sich auf zwei Arten umsetzen:
- "Snowpipe Mode" kombiniert Kafka mit den oben beschriebenen klassischen Snowpipe-Methoden.
- "Snowpipe Streaming" – ein neues Angebot, das Snowflake 2023 veröffentlicht hat.
Kafka Connector – Snowpipe Mode
Der Snowpipe Mode des Kafka Connectors kombiniert Micro-Batching von Dateien mit Snowpipes. Kafka-Nachrichten werden in temporäre Dateien geschrieben und per Snowpipe ingestiert.
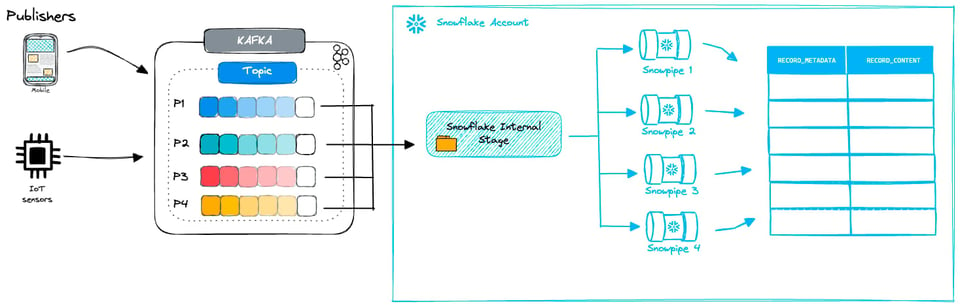
Mit dem Kafka Connector legen Sie fest, wie häufig neue Dateien erzeugt werden. Wie bereits erwähnt, sollten Sie bei klassischen Snowpipes Dateien zwischen 100 und 250 MB anstreben. Diese optimale Dateigröße einzuhalten, kann angesichts weiterer Einflussfaktoren herausfordernd sein:
- Wie häufig Ihre Quelle Daten erzeugt und wie schnell diese in Snowflake landen müssen
- Die Flush-Rate: wie häufig die Daten in Dateien geschrieben werden – konfigurierbar in den Optionen des Kafka Connectors
- Die Partitionsanzahl in Ihrem Kafka-Cluster
Kostenaspekte
Bei dieser Option wird Ihnen nur die Snowpipe-Ingestion in Rechnung gestellt – mit denselben Gebühren und Besonderheiten wie oben beschrieben.
Erforderliche Skills
Diese Option setzt eine lauffähige Kafka-Umgebung sowie das nötige Know-how zum Aufbau und Betrieb dieser Infrastruktur voraus – für viele Teams eine nicht zu unterschätzende Hürde.
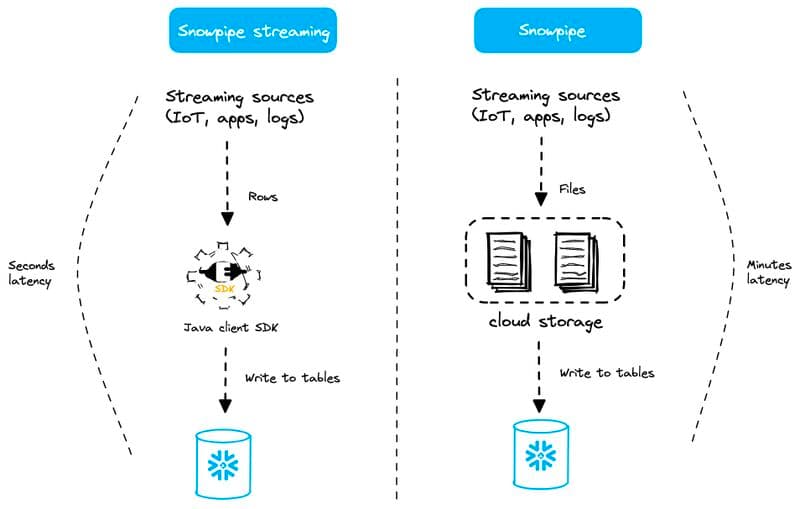
Snowpipe Streaming
Snowpipe Streaming ist die jüngste Erweiterung der Snowflake-Features rund um Data Streaming. Diese Option bietet eine noch geringere Latenz (im Sekundenbereich) als der oben beschriebene Snowpipe Mode.
Mit Snowpipe Streaming gibt es weder Stages noch Dateien noch Snowpipe-Objekte (was zugegebenermaßen verwirrend ist, da der Name "Snowpipe" enthält). Daten werden zeilenweise geladen – nicht über Dateien.
Kostenaspekte
Wie das klassische Snowpipe nutzt auch Snowpipe Streaming ein Serverless-Compute-Modell. Snowflake verwaltet die Compute-Ressourcen automatisch auf Basis der Streaming-Last. Um die Kosten realistisch einzuschätzen, empfiehlt es sich, einen typischen Streaming-Workload zu testen.
Snowpipe Streaming Compute ist mit 1 Credit pro Compute-Stunde günstiger als klassisches Snowpipe (1,25). Für Cloud Services fallen keine Gebühren an, allerdings berechnet Snowflake einen Stundensatz von 0,01 Credits pro Streaming-Client. Achten Sie deshalb auf die Anzahl der Clients, die Sie anlegen. Bei 100 Clients beläuft sich diese Verwaltungsgebühr auf 22.000 USD pro Jahr – bei einem Credit-Preis von 2,5 USD/Credit (100*0,01*24*365*2,5).
Laut Snowflake und weiteren Quellen ist diese Methode der kosteneffizienteste Weg, Daten in Snowflake zu laden.
Erforderliche Skills
Snowpipe Streaming ist die attraktivste Ladeoption in puncto Kosteneffizienz und Latenz. Sie hat aber auch die höchste Einstiegshürde: Die Snowpipe Streaming API ist Teil des Java SDK – ohne Java-Kenntnisse können Sie das Feature nicht nutzen.
Wie Sie die passende Ladeoption auswählen
Nachdem wir alle Ladeoptionen besprochen haben, stellt sich die Frage: Welche ist die richtige? Letztlich müssen Sie alle bisher diskutierten Aspekte abwägen:
- Welche Latenz benötigt Ihr Anwendungsfall?
- Suchen Sie die kosteneffizienteste Option?
- Welches technische Know-how hat Ihr Team, und wie passt die Ladeoption in Ihren bestehenden Stack?
- Welches System erzeugt die Daten und Dateien, die Sie laden möchten – und haben Sie darauf Einfluss?
Fassen wir alles in einer Tabelle zusammen, um die Unterschiede zu verdeutlichen:
| Methode | Option | Niedrigste mögliche Latenz | Erforderliche Skills |
|---|---|---|---|
| BATCH | COPY-Befehl | Minuten | SQL |
| BATCH | Serverless Task | Minuten | SQL |
| KONTINUIERLICH | Snowpipe | Minuten | SQL + Cloud |
| ECHTZEIT | Kafka Snowpipe Mode | Minuten | SQL + Cloud + Kafka |
| ECHTZEIT | Kafka Snowpipe Streaming | Sekunden | SQL + Cloud + Java |
Wenn Sie lieber visuell entscheiden, hilft Ihnen das folgende Diagramm. Es deckt nicht jeden Edge Case ab. Manche Nutzer können Snowpipe beispielsweise auch mit Dateien unter 100 MB sehr kosteneffizient einsetzen, solange es nicht zu viele werden.
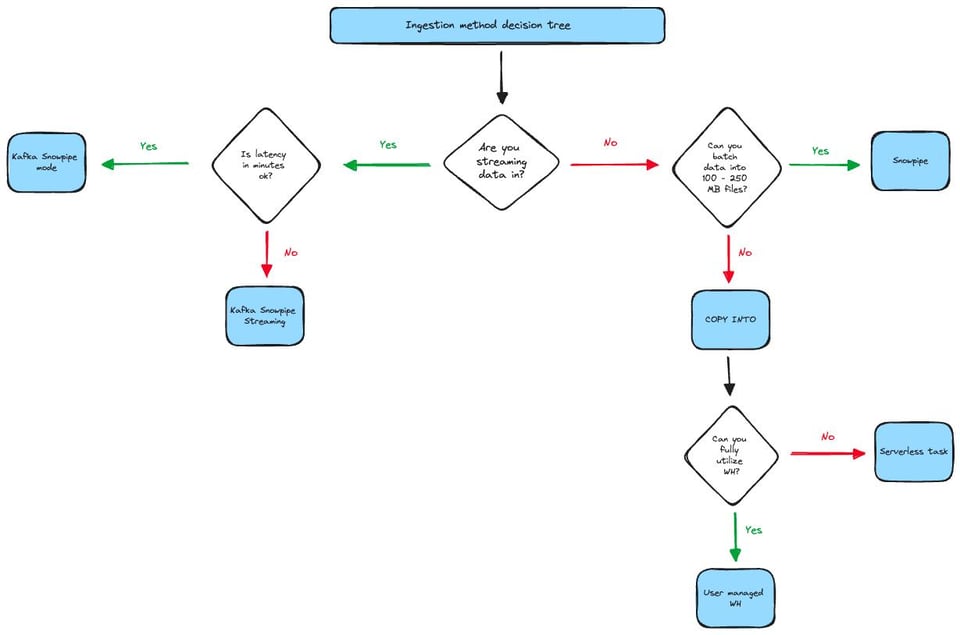
Das Flussdiagramm konzentriert sich vor allem auf Latenz und Dateigröße als die beiden zentralen Kriterien. Im linken Teil des Diagramms gilt: Wenn eine Latenz im Minutenbereich für Sie in Ordnung ist, Ihr Team aber mit dem Java SDK vertraut ist, ist Snowpipe Streaming die bessere Wahl – es liefert Daten schneller und zu niedrigeren Kosten.
Weiterführende Ressourcen
Wenn Sie tiefer einsteigen möchten: Snowflake bietet eine sehr umfassende Dokumentation zu Snowpipe Streaming und den anderen Ladeoptionen. Ebenfalls sehr empfehlenswert ist diese Snowflake-Präsentation, die ein detailliertes Benchmarking der verschiedenen Ladeoptionen anhand realer Daten zeigt.
Tomáš Sobotík · Senior Data Engineer & Snowflake SME bei Norlys
Tomas ist langjähriger Snowflake Data SuperHero und ausgewiesener Snowflake-Experte. Seine Erfahrung in der Datenwelt umfasst über ein Jahrzehnt, in dem er als Snowflake Data Engineer, Architekt und Administrator in zahlreichen Projekten unterschiedlichster Branchen und Technologien tätig war. Tomas ist ein zentrales Mitglied der Community, teilt sein Wissen aktiv und inspiriert andere. Außerdem ist er O'Reilly-Instructor und leitet Live-Online-Trainings.