Saber cómo cargar datos de forma eficiente en tu cuenta de Snowflake es clave. Snowflake ofrece distintas opciones de ingesta de datos, cada una con sus pros, contras y consideraciones importantes.
Existen varias alternativas tanto para la carga por lotes como para la carga continua o en tiempo real, todas escalables para soportar grandes volúmenes de datos. Elegir bien puede impactar el costo, el rendimiento, la confiabilidad y la facilidad de mantenimiento. Cada uno de estos factores hay que tomarlo en cuenta.
En este blog haré un análisis a fondo de las cinco opciones de carga de datos y mostraré los distintos tradeoffs: latencia, costo, mantenimiento y nivel técnico requerido. También vas a conocer algunas buenas prácticas para cada método. Al final resumiré las opciones y te daré algunas pautas generales para ayudarte a elegir.
Carga por lotes
La carga por lotes es el enfoque de ingesta más común en todos los data warehouses. Con este método, los datos se cargan de forma masiva en el data warehouse según un horario fijo (por ejemplo, una vez al día, una vez por hora, cada 4 horas, etc.). Suele ser la opción más sencilla, pero implica un gran tradeoff: la latencia. Si tus datos se cargan una vez al día, pueden tener una antigüedad de más de 24 horas antes de la siguiente carga.
La ingesta por lotes generalmente toma archivos desde el cloud storage (un bucket de Amazon S3, Microsoft Azure Blob Storage o Google Cloud Storage) y, mediante algún proceso o herramienta de orquestación, los carga automáticamente en Snowflake según un horario definido.
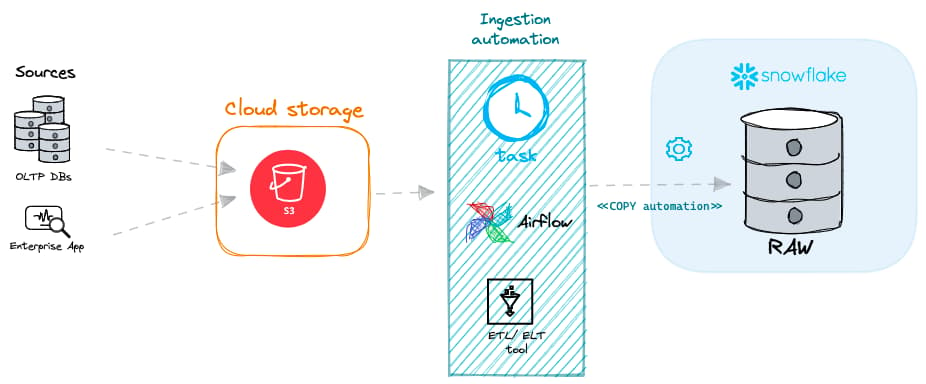
En Snowflake hay dos enfoques principales para la ingesta de datos por lotes.
Carga por lotes con tu propio virtual warehouse
En mi experiencia, la forma más común de cargar datos en Snowflake es ejecutando el comando COPY INTO en alguno de tus propios virtual warehouses administrados.
Este comando toma archivos previamente cargados en un internal stage o external stage de Snowflake y los ingesta en la tabla destino. Los archivos pueden ser CSV, datos JSON o cualquier otra opción de formato de archivo soportada.
El comando COPY se ejecuta en uno de tus virtual warehouses administrados, lo que significa que eres responsable de crearlo y dimensionarlo correctamente (consejo: siempre empieza con un warehouse X-SMALL y escala solo si es necesario para cumplir tu SLA).
Consideraciones de costo y eficiencia
Cuando cargas datos con el comando COPY INTO en Snowflake, pagas por cada segundo que el virtual warehouse está activo. Los virtual warehouses de Snowflake se facturan con un mínimo de 60 segundos cada vez que se reanudan, así que conviene asegurarte de que tu proceso de carga dure cerca de esos 60 segundos en cada ejecución.
El virtual warehouse más pequeño puede ingestar 8 archivos en paralelo. Este número se duplica con cada incremento de tamaño. Por ejemplo, para aprovechar al máximo un warehouse mediano necesitarías 32 archivos. Si uno es mucho más grande que los demás, es posible que los otros hilos queden ociosos mientras solo uno hace el trabajo.
Cargar datos por lotes en tu propio virtual warehouse puede ser una de las formas más rentables de ingestar datos en Snowflake, siempre y cuando tengas suficientes archivos y datos para saturar el warehouse y no termines pagando por compute ocioso. No te pierdas nuestro otro blog sobre buenas prácticas para la carga de datos por lotes.
Habilidades necesarias
Usar el comando COPY no requiere habilidades adicionales más allá de un conocimiento básico de SQL.
Con esta opción, necesitarás alguna herramienta de orquestación o programación que ejecute el comando COPY en el horario deseado.
Carga por lotes con serverless tasks
Las serverless tasks permiten a los usuarios de Snowflake ejecutar comandos SQL en un horario definido usando los recursos de cómputo de Snowflake en lugar de su propio virtual warehouse administrado. Puedes configurar una serverless task para ejecutar el comando COPY INTO con la frecuencia que necesites.
Al igual que cuando ejecutas COPY INTO en tu propio warehouse administrado, la latencia o antigüedad de tus datos dependerá de la frecuencia con la que corras el comando COPY para cargar nuevos datos.
Consideraciones de costo y eficiencia
Como solo pagas por segundo de cómputo utilizado, las serverless tasks pueden ayudar a resolver el problema de subutilización del cómputo que aparece al hacer carga por lotes en tu propio virtual warehouse. Si tu proceso de carga tarda solo 10 segundos por ejecución, terminarás pagando 50 segundos adicionales de cómputo cada vez (cuando se ejecuta en tu warehouse administrado).
Los costos de cómputo de las serverless tasks se facturan a 1.5X el precio de un virtual warehouse equivalente administrado por ti. Por eso, desde el punto de vista de la eficiencia de costo, solo conviene usarlas si no puedes saturar por completo un virtual warehouse durante al menos 40s del período mínimo de facturación de 60 segundos.
Habilidades necesarias
Cargar datos en Snowflake con una serverless task es, sin duda, una de las opciones de ingesta más sencillas. Solo requiere un conocimiento práctico de SQL y no necesita herramientas de orquestación de terceros.
Carga continua con Snowpipe
A diferencia del procesamiento por lotes, que corre en un horario fijo, la carga continua procesa los datos a partir de algún evento, normalmente un nuevo archivo que llega al cloud storage. El origen de estos archivos puede ser desde un servicio de change data capture que registra los movimientos de una base de datos relacional hasta datos de eventos de aplicaciones web. Cada archivo nuevo dispara una notificación de evento que inicia automáticamente el proceso de carga. Los servicios de mensajería en la nube como AWS SNS o SQS suelen usarse para enviar estas notificaciones. Pueden integrarse directamente con Snowflake e informar a la plataforma sobre los archivos recién llegados.
Con la carga continua, la latencia de los datos es mucho menor, ya que los datos nuevos se cargan constantemente apenas están disponibles.
Para agilizar la carga de datos y permitir el procesamiento continuo, Snowflake ofrece una funcionalidad muy potente llamada Snowpipe. Snowpipe se integra con un servicio de notificación de eventos del proveedor de nube (por ejemplo, AWS SNS/SQS). Cada objeto Snowpipe tiene además un comando COPY asociado. Las notificaciones de eventos avisan al objeto Snowpipe sobre los nuevos archivos de datos cargados en un external stage, lo que dispara la ejecución del comando COPY correspondiente.
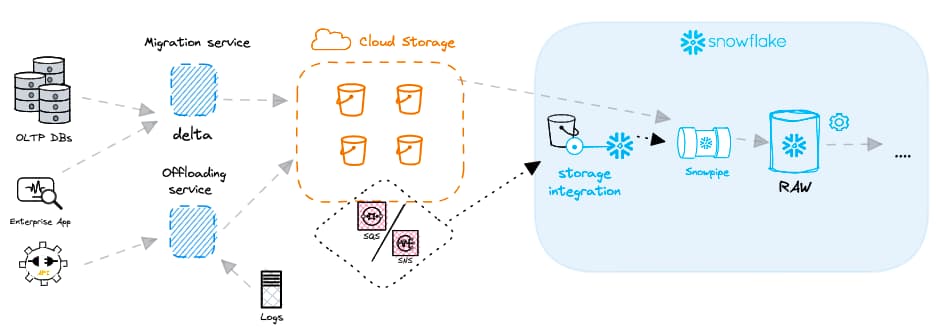
La mayoría de los clientes usan la función "auto-ingest" de Snowpipe, es decir, los archivos se cargan automáticamente apenas llegan. Pero vale la pena mencionar que también existe una API REST para Snowpipe que te permite elegir cuándo se dispara un objeto Snowpipe.
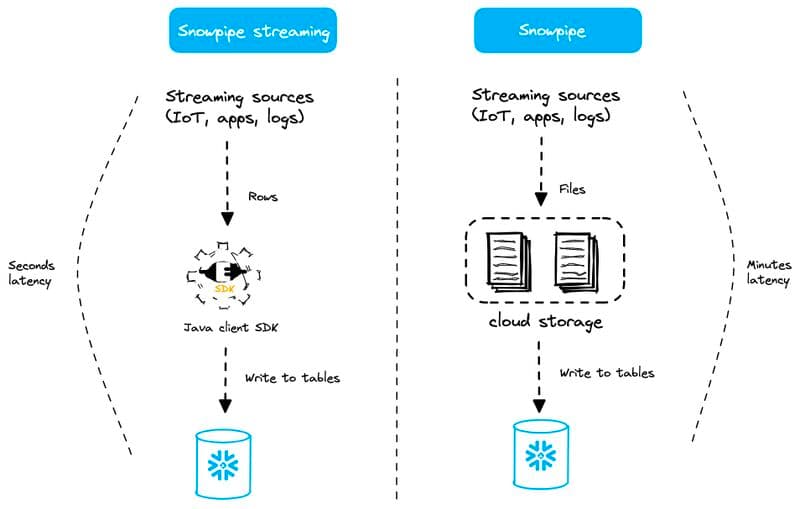
Snowpipe es una funcionalidad serverless, así que no tienes que preocuparte por qué virtual warehouse usar ni por su dimensionamiento. El cómputo lo mantiene y administra completamente Snowflake. En términos de latencia, Snowpipe normalmente ingesta los archivos en cuestión de minutos desde que llegan al cloud storage.
Consideraciones de costo y eficiencia
El mayor impacto en la eficiencia de costo de Snowpipe es el tamaño del archivo. Snowpipe cobra un overhead de 0.06 créditos por cada 1000 archivos procesados. Por eso, el costo de cargar 100GB puede variar bastante según el tamaño del archivo, ya que esto influye en la cantidad de archivos. Los recursos de cómputo de Snowpipe se cobran a 1.25 créditos por hora de cómputo.
Snowflake recomienda apuntar a archivos comprimidos de entre 100 y 250MB. Si tus aplicaciones upstream envían con frecuencia datos en archivos pequeños, conviene implementar un proceso que los agregue en lotes de mayor tamaño. Un servicio habitual para esto es Amazon Kinesis Firehose. Como alternativa, se pueden considerar otras opciones de procesamiento de datos en tiempo real como Snowpipe Streaming (que veremos más adelante).
Habilidades necesarias
Para configurar un trabajo de carga con Snowpipe, necesitarás acceso a tu proveedor de nube para crear el servicio de notificación de eventos requerido.
Una vez configurados el cloud storage upstream y los servicios de notificación de eventos, la configuración del objeto Snowpipe puede hacerse íntegramente en SQL.
Carga en tiempo real con Kafka
Hay muchos casos de uso en distintas industrias que requieren datos en tiempo real: scoring crediticio, análisis de fraude o incluso analítica orientada al usuario final. Entregar datos con baja latencia normalmente se logra con un message broker como Apache Kafka. En lugar de archivos, Kafka recibe mensajes de diversos "productores de datos" y los envía a distintos "consumidores de datos". En el contexto de la carga de datos, Snowflake se convierte en un consumidor de datos.
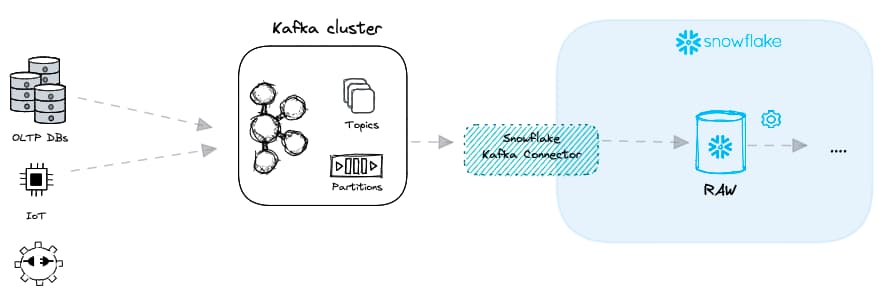
Usar Kafka con Snowflake para lograr una carga de datos con baja latencia puede hacerse de dos formas distintas:
- "Modo Snowpipe", que combina Kafka con los métodos tradicionales de Snowpipe que ya vimos.
- "Modo Snowpipe Streaming", una nueva oferta lanzada por Snowflake en 2023.
Kafka Connector - modo Snowpipe
El modo Snowpipe del conector de Kafka usa una combinación de micro-batching de archivos y Snowpipes. Los mensajes de Kafka se vuelcan en archivos temporales que luego se ingestan vía Snowpipe.
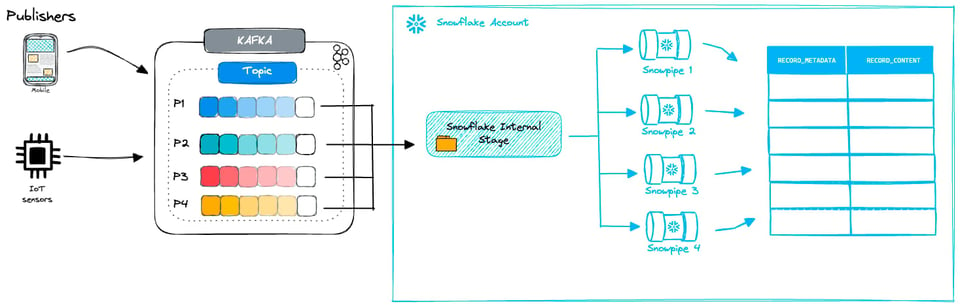
Con el conector de Kafka puedes configurar la frecuencia con la que se crean los nuevos archivos. Como mencionamos antes, al usar Snowpipes regulares conviene apuntar a archivos de 100-250MB. Mantener este tamaño óptimo puede volverse complicado considerando los demás factores que entran en juego:
- Con qué frecuencia tu origen genera datos y qué tan rápido necesitas que esos datos lleguen a Snowflake
- El flush rate: con qué frecuencia se vuelcan los datos a los archivos, configurable en las opciones del conector de Kafka
- La cantidad de particiones en tu clúster de Kafka
Consideraciones de costo
Con esta opción solo se te cobra por la ingesta de Snowpipe, con los mismos cargos y matices descritos antes.
Habilidades necesarias
Usar esta opción de carga de datos requiere un entorno de Kafka en funcionamiento y los conocimientos necesarios para crear y administrar esa infraestructura, lo que puede ser una barrera importante para muchos equipos.
Snowpipe Streaming
Snowpipe Streaming es la incorporación más reciente entre las funcionalidades de Snowflake relacionadas con streaming de datos. Esta opción ofrece una latencia aún mejor (en segundos) que el modo Snowpipe (mencionado arriba).
Con Snowpipe Streaming no hay stage, no hay archivos y no hay objetos Snowpipe (lo cual reconozco que es confuso, ya que el nombre incluye "Snowpipe"). Con Snowpipe Streaming, los datos se cargan fila por fila en lugar de usar archivos.
Consideraciones de costo
Al igual que el Snowpipe regular, Snowpipe Streaming usa un modelo de cómputo serverless. Snowflake administra los recursos de cómputo automáticamente según la carga del streaming. Para estimar los cargos, lo mejor es experimentar con un workload de streaming típico.
El cómputo de Snowpipe Streaming tiene un precio menor que el Snowpipe regular: 1 crédito por hora de cómputo (Snowpipe cuesta 1.25). No hay cargos por cloud services, pero Snowflake sí cobra una tarifa por hora de 0.01 créditos por cada cliente de streaming. Por eso es importante prestar atención al número de clientes que creas. Si un usuario crea 100 clientes, este overhead costaría 22,000 USD al año asumiendo un precio de 2.5 USD por crédito (100*0.01*24*365*2.5).
Según Snowflake y otras fuentes, este método es la forma más rentable de cargar datos en Snowflake.
Habilidades necesarias
Snowpipe Streaming es la opción de carga de datos más atractiva por ofrecer la mejor eficiencia de costo y la menor latencia. Pero también es la que tiene la mayor barrera de habilidades. La API de Snowpipe Streaming forma parte del SDK de Java, lo que significa que debes estar familiarizado con Java para poder usarla.
Cómo elegir una opción de carga de datos
Ahora que ya repasamos todas las opciones de carga de datos, seguramente te estés preguntando cómo elegir la correcta. Al final, deberás tener en cuenta todos los aspectos que vimos:
- ¿Qué latencia requiere tu caso de uso?
- ¿Buscas la opción más rentable?
- ¿Qué experiencia técnica tiene tu equipo y cómo encaja la opción de carga en tu stack actual?
- ¿Qué sistema produce los datos y archivos que necesitas cargar, y tienes control sobre él?
Resumamos todo en una tabla para destacar las distintas consideraciones de cada opción:
| Método | Opción | Latencia mínima posible | Habilidades necesarias |
|---|---|---|---|
| BATCH | Comando COPY | Minutos | SQL |
| BATCH | Serverless task | Minutos | SQL |
| CONTINUA | Snowpipe | Minutos | SQL + cloud |
| TIEMPO REAL | Kafka modo Snowpipe | Minutos | SQL + cloud + Kafka |
| TIEMPO REAL | Kafka Snowpipe streaming | Segundos | SQL + cloud + Java |
Si prefieres un árbol de decisión visual, mira el diagrama de abajo. Ten en cuenta que no incluye todos los casos límite ni todas las consideraciones posibles. Por ejemplo, algunos usuarios pueden seguir usando Snowpipe de forma muy rentable incluso con archivos de menos de 100MB, siempre que no sean demasiados.
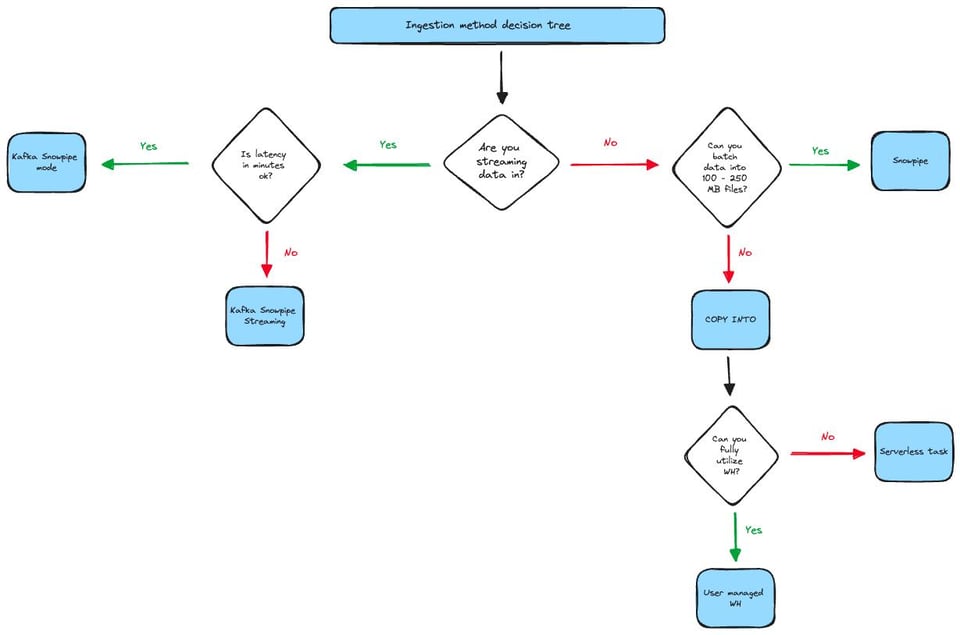
Este diagrama de flujo considera principalmente la latencia y el tamaño del archivo como las dos variables clave. Mirando la parte izquierda del árbol, si te conformas con una latencia en minutos pero tu equipo se siente cómodo usando el SDK de Java, entonces Snowpipe Streaming será la mejor opción, ya que entrega los datos más rápido y a un menor costo.
Recursos adicionales
Si quieres profundizar, Snowflake tiene documentación muy completa sobre Snowpipe Streaming y los demás métodos de carga de datos. También recomiendo mucho ver esta presentación de Snowflake, que hace un benchmarking detallado de las distintas opciones de carga de datos con datos reales.
Tomáš Sobotík·Senior Data Engineer y Snowflake SME en Norlys
Tomas es un reconocido Snowflake Data SuperHero y experto en Snowflake. Su amplia trayectoria en el mundo de los datos abarca más de una década, durante la cual se ha desempeñado como data engineer, arquitecto y administrador de Snowflake en distintos proyectos de diversas industrias y tecnologías. Tomas es un miembro central de la comunidad, comparte activamente su experiencia e inspira a otros. También es instructor en O'Reilly, donde dirige sesiones de capacitación en vivo en línea.