Savoir charger efficacement des données dans votre compte Snowflake est essentiel. Snowflake propose plusieurs options d'ingestion, chacune avec ses avantages, ses inconvénients et ses points de vigilance.
Les clients disposent de plusieurs options, aussi bien pour le chargement en batch que pour le chargement continu ou en temps réel, toutes capables de monter en charge pour gérer de gros volumes de données. Le choix de la bonne option a un impact direct sur le coût, la performance, la fiabilité et la facilité de maintenance. Chacun de ces facteurs mérite réflexion.
Dans cet article, j'explore en profondeur les cinq options de chargement de données et mets en lumière leurs compromis : latence, coût, maintenance et expertise technique requise. Vous découvrirez aussi quelques bonnes pratiques pour chaque méthode. Pour conclure, je récapitulerai les différentes options et donnerai quelques repères pour vous aider à choisir.
Chargement par batch
Le chargement par batch est l'approche d'ingestion la plus courante dans tous les data warehouses. Avec cette méthode, les données sont chargées en masse dans le data warehouse selon un planning fixe (une fois par jour, une fois par heure, toutes les 4 heures, etc.). C'est généralement l'option la plus simple, mais elle implique un compromis majeur : la latence. Si vos données sont chargées une fois par jour, elles peuvent accuser jusqu'à 24 heures de retard avant le prochain chargement.
L'ingestion par batch consiste typiquement à récupérer des fichiers depuis un stockage cloud (un bucket Amazon S3, Microsoft Azure Blob Storage ou Google Cloud Storage), via un processus ou un outil d'orchestration qui charge automatiquement ces données dans Snowflake selon un planning défini.
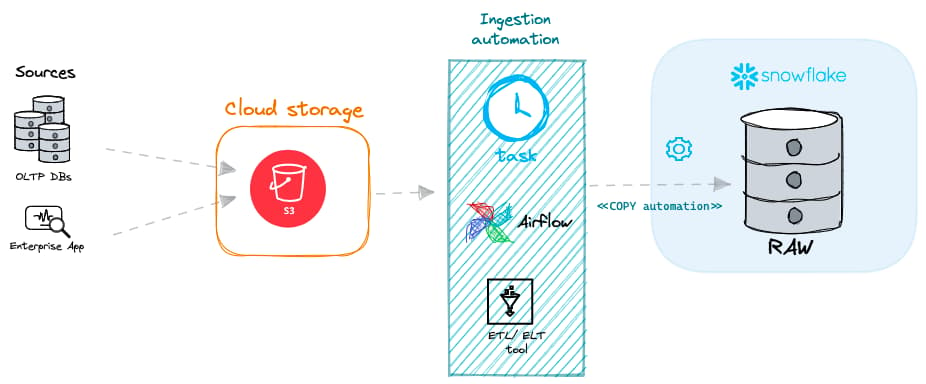
Dans Snowflake, il existe deux approches principales pour l'ingestion par batch.
Chargement par batch avec votre propre virtual warehouse
D'après mon expérience, la manière la plus courante de charger des données dans Snowflake consiste à exécuter la commande COPY INTO sur l'un de vos virtual warehouses gérés.
Cette commande prend des fichiers préalablement chargés dans un stage interne ou externe de Snowflake et les ingère dans la table cible. Les fichiers peuvent être au format CSV, JSON ou tout autre format pris en charge.
La commande COPY s'exécute sur l'un de vos virtual warehouses gérés, ce qui signifie que vous êtes responsable de sa création et de son dimensionnement (astuce : commencez toujours par un warehouse X-SMALL et augmentez la taille uniquement si nécessaire pour tenir votre SLA).
Coût et efficacité
Lorsque vous chargez des données avec la commande COPY INTO dans Snowflake, vous payez chaque seconde durant laquelle le virtual warehouse est actif. Les virtual warehouses Snowflake sont facturés pour un minimum de 60 secondes à chaque reprise : assurez-vous donc que votre processus de chargement dure au moins une minute à chaque exécution.
Le plus petit virtual warehouse peut ingérer 8 fichiers en parallèle. Ce nombre double à chaque taille supérieure. Par exemple, pour exploiter pleinement un warehouse Medium, il vous faut 32 fichiers. Si l'un des fichiers est nettement plus volumineux que les autres, les autres threads peuvent rester inactifs pendant qu'un seul travaille.
Le chargement par batch sur votre propre virtual warehouse peut être l'une des manières les plus économiques de charger des données dans Snowflake, à condition d'avoir suffisamment de fichiers et de données pour saturer le warehouse, et de ne pas payer pour du calcul inactif. Consultez aussi notre article dédié aux bonnes pratiques du chargement par batch.
Compétences requises
Utiliser la commande COPY ne demande aucune compétence supplémentaire au-delà de connaissances SQL de base.
Avec cette option, il vous faudra un outil de planification ou d'orchestration pour exécuter la commande COPY à la fréquence souhaitée.
Chargement par batch avec serverless tasks
Les serverless tasks permettent aux utilisateurs de Snowflake d'exécuter des commandes SQL selon un planning défini, en s'appuyant sur les ressources de calcul de Snowflake plutôt que sur un virtual warehouse géré. Vous pouvez configurer une serverless task pour exécuter la commande COPY INTO à la fréquence voulue.
Comme avec la commande COPY INTO sur votre propre warehouse, la latence (ou la fraîcheur) de vos données dépendra de la fréquence d'exécution de la commande COPY.
Coût et efficacité
Comme vous ne payez qu'à la seconde de calcul utilisée, les serverless tasks permettent de résoudre le problème de sous-utilisation lié au chargement par batch sur votre propre virtual warehouse. Si votre processus de chargement ne dure que 10 secondes, vous finirez par payer 50 secondes supplémentaires de calcul à chaque exécution (sur un warehouse géré).
Les coûts de calcul des serverless tasks sont facturés 1,5 fois le tarif d'un virtual warehouse géré de taille équivalente. Sur le plan de l'efficacité, elles ne sont donc pertinentes que si vous ne pouvez pas saturer pleinement un virtual warehouse pendant au moins 40 secondes sur la période minimale de facturation de 60 secondes.
Compétences requises
Charger des données dans Snowflake avec une serverless task est sans doute l'option d'ingestion la plus simple qui soit. Elle ne demande qu'une connaissance pratique de SQL et aucun outil d'orchestration tiers.
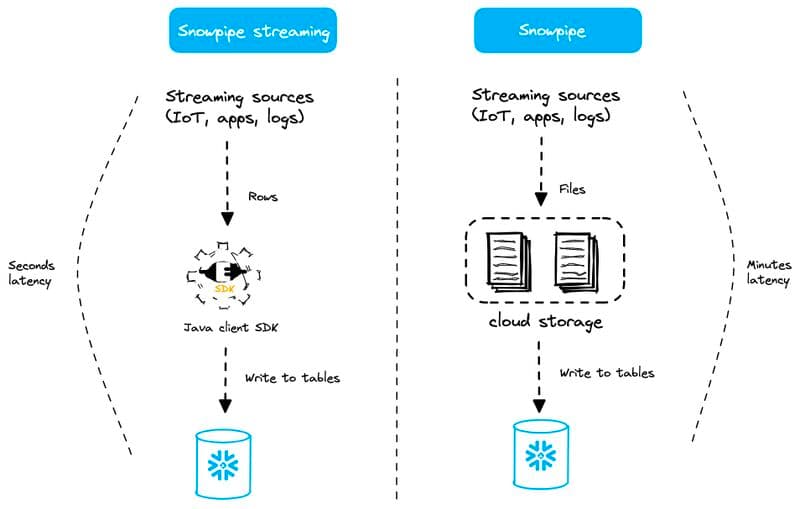
Chargement continu avec Snowpipe
Contrairement au traitement par batch qui suit un planning fixe, le chargement continu traite les données à partir d'un événement, généralement l'arrivée d'un nouveau fichier dans le stockage cloud. La source de ces fichiers peut aussi bien être un service de change data capture qui enregistre les modifications d'une base relationnelle que des données d'événements issues d'une application web. Chaque nouveau fichier déclenche une notification qui lance automatiquement le processus de chargement. Les services de messagerie cloud comme AWS SNS ou SQS sont fréquemment utilisés pour émettre ces notifications. Ils s'intègrent directement à Snowflake et informent la plateforme de l'arrivée de nouveaux fichiers.
Avec le chargement continu, la latence est bien plus faible, puisque les nouvelles données sont chargées au fil de l'eau dès qu'elles deviennent disponibles.
Pour fluidifier le chargement des données et permettre un traitement continu, Snowflake propose une fonctionnalité puissante : Snowpipe. Snowpipe s'intègre à un service de notification d'événements côté fournisseur cloud (par exemple AWS SNS/SQS). Chaque objet Snowpipe est associé à une commande COPY. Les notifications informent l'objet Snowpipe de l'arrivée de nouveaux fichiers dans un stage externe, ce qui déclenche l'exécution de la commande COPY correspondante.
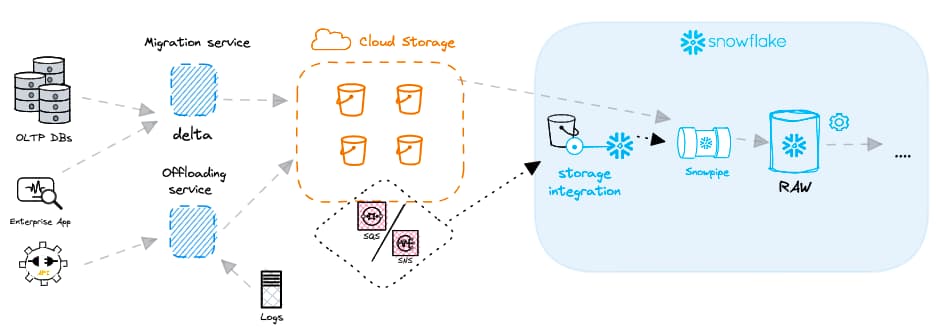
La plupart des clients utilisent la fonctionnalité auto-ingest de Snowpipe : les fichiers sont chargés automatiquement dès leur arrivée. Notez qu'il existe également une API REST pour Snowpipe qui vous permet de choisir quand un objet Snowpipe est déclenché.
Snowpipe est une fonctionnalité serverless : vous n'avez pas à vous soucier du choix du virtual warehouse ni de son dimensionnement. La ressource de calcul est entièrement gérée par Snowflake. Côté latence, Snowpipe ingère généralement les fichiers en quelques minutes après leur arrivée dans le stockage cloud.
Coût et efficacité
Le principal facteur d'efficacité économique de Snowpipe est la taille des fichiers. Snowpipe facture des frais de gestion de 0,06 crédit pour 1 000 fichiers traités. Le coût de chargement de 100 Go peut donc varier sensiblement selon la taille des fichiers, qui détermine leur nombre. Les ressources de calcul de Snowpipe sont facturées 1,25 crédit par heure de calcul.
Snowflake recommande de viser des fichiers de 100 à 250 Mo compressés. Si vos applications en amont envoient fréquemment des données dans de petits fichiers, il est judicieux de mettre en place un processus qui les agrège en lots plus volumineux. Un service couramment employé à cet effet est Amazon Kinesis Firehose. Vous pouvez aussi envisager d'autres options de traitement temps réel comme Snowpipe Streaming (présenté plus bas).
Compétences requises
Pour configurer un job Snowpipe, vous devrez pouvoir accéder à votre fournisseur cloud afin de créer le service de notification d'événements requis.
Une fois le stockage cloud en amont et les services de notification configurés, la mise en place de l'objet Snowpipe se fait entièrement en SQL.
Chargement en temps réel avec Kafka
De nombreux cas d'usage, dans des secteurs variés, exigent des données en temps réel : scoring de crédit, analyse de fraude ou encore analytics destinées aux utilisateurs finaux. Pour livrer des données à très faible latence, on s'appuie généralement sur un broker de messages comme Apache Kafka. Au lieu de fichiers, Kafka reçoit des messages depuis divers producteurs de données et les transmet à différents consommateurs de données. Dans le contexte du chargement de données, Snowflake joue le rôle de consommateur.
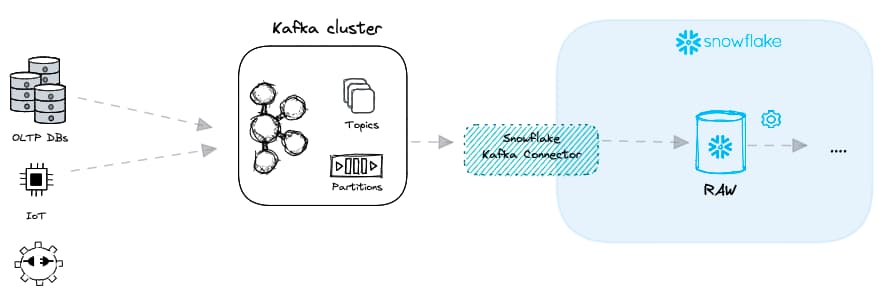
L'utilisation de Kafka avec Snowflake pour obtenir une faible latence peut se faire de deux manières :
- Le mode Snowpipe, qui combine Kafka avec les méthodes Snowpipe traditionnelles évoquées plus haut.
- Le mode Snowpipe Streaming, une nouvelle offre lancée par Snowflake en 2023.
Connecteur Kafka — mode Snowpipe
Le mode Snowpipe du connecteur Kafka combine micro-batching de fichiers et Snowpipes. Les messages Kafka sont déversés dans des fichiers temporaires puis ingérés via Snowpipe.
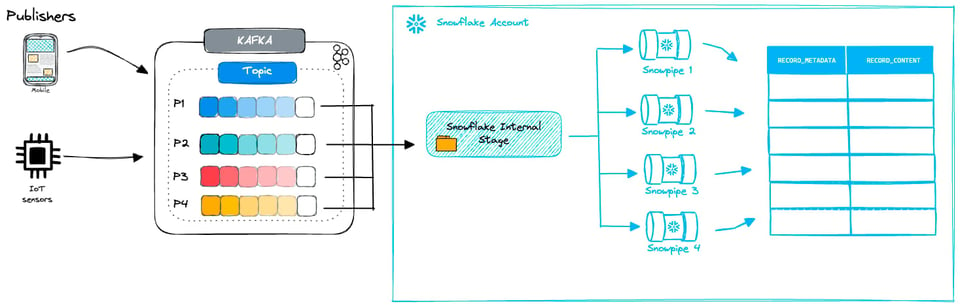
Avec le connecteur Kafka, vous pouvez configurer la fréquence de création de ces nouveaux fichiers. Comme vu plus haut, avec des Snowpipes classiques il faut viser des fichiers de 100 à 250 Mo. Maintenir cette taille optimale peut s'avérer complexe, compte tenu des autres facteurs en jeu :
- La fréquence à laquelle votre source génère des données et la rapidité avec laquelle vous devez les charger dans Snowflake
- Le taux de flush : la fréquence à laquelle les données sont déversées dans les fichiers, paramétrable dans les options du connecteur Kafka
- Le nombre de partitions de votre cluster Kafka
Coût
Avec cette option, vous ne payez que l'ingestion Snowpipe, selon les mêmes tarifs et nuances décrits plus haut.
Compétences requises
Cette option de chargement suppose un environnement Kafka opérationnel ainsi que les compétences nécessaires pour créer et gérer cette infrastructure, ce qui peut représenter un obstacle de taille pour de nombreuses équipes.
Snowpipe Streaming
Snowpipe Streaming est la dernière nouveauté de Snowflake dédiée au streaming de données. Cette option offre une latence encore meilleure (de l'ordre de la seconde) que le mode Snowpipe évoqué plus haut.
Avec Snowpipe Streaming, il n'y a ni stage, ni fichiers, ni objet Snowpipe (ce qui peut prêter à confusion, le nom contenant pourtant Snowpipe). Les données sont chargées ligne par ligne au lieu de transiter par des fichiers.
Coût
Comme Snowpipe classique, Snowpipe Streaming repose sur un modèle de calcul serverless. Snowflake gère automatiquement les ressources de calcul en fonction de la charge de streaming. Pour estimer les coûts, mieux vaut expérimenter avec un workload de streaming représentatif.
Le calcul Snowpipe Streaming est facturé moins cher que Snowpipe classique : 1 crédit par heure de calcul (contre 1,25 pour Snowpipe). Il n'y a pas de frais de services cloud, mais Snowflake facture un coût horaire de 0,01 crédit par client de streaming. Il est donc important de surveiller le nombre de clients créés. Si un utilisateur crée 100 clients, ce coût de gestion atteindrait 22 000 $ par an, en supposant un prix de 2,5 $ par crédit (100*0,01*24*365*2,5).
D'après Snowflake et d'autres sources, c'est la méthode la plus économique pour charger des données dans Snowflake.
Compétences requises
Snowpipe Streaming est l'option de chargement la plus attractive en matière d'efficacité économique et de latence minimale. Mais c'est aussi celle qui présente la plus haute barrière technique. L'API Snowpipe Streaming fait partie du SDK Java : vous devez donc maîtriser Java pour exploiter cette fonctionnalité.
Comment choisir une option de chargement
Maintenant que nous avons passé en revue toutes les options de chargement, vous vous demandez sans doute comment choisir la bonne. En définitive, il vous faudra prendre en compte tous les aspects évoqués :
- Quelle latence votre cas d'usage exige-t-il ?
- Recherchez-vous l'option la plus économique ?
- Quelle est l'expertise technique de votre équipe et comment l'option s'intégrera-t-elle à votre stack existante ?
- Quel système produit les données et les fichiers à charger, et avez-vous la main dessus ?
Récapitulons le tout dans un tableau pour mettre en évidence les critères propres à chaque option :
| Méthode | Option | Latence minimale possible | Compétences requises |
|---|---|---|---|
| BATCH | Commande COPY | Minutes | SQL |
| BATCH | Serverless task | Minutes | SQL |
| CONTINU | Snowpipe | Minutes | SQL + cloud |
| TEMPS RÉEL | Kafka mode Snowpipe | Minutes | SQL + cloud + Kafka |
| TEMPS RÉEL | Kafka Snowpipe streaming | Secondes | SQL + cloud + Java |
Si vous préférez un arbre de décision visuel, jetez un œil au schéma ci-dessous. Notez qu'il ne couvre pas tous les cas particuliers ni tous les critères à prendre en compte. Par exemple, certains utilisateurs restent très efficaces en coût avec Snowpipe, même avec des fichiers de moins de 100 Mo, à condition qu'ils ne soient pas trop nombreux.
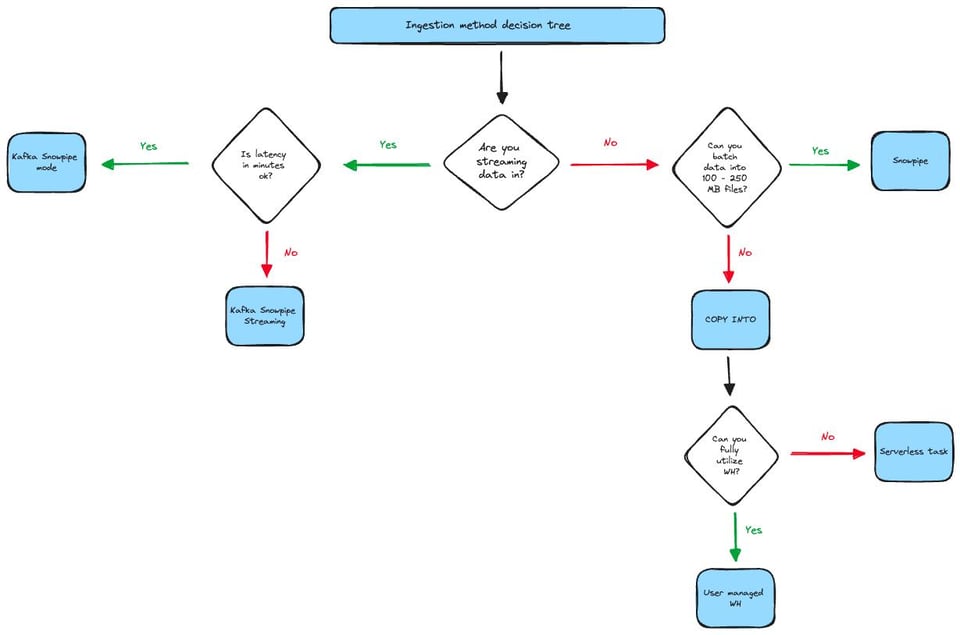
Cet organigramme repose principalement sur deux critères clés : la latence et la taille des fichiers. À gauche de l'arbre, si une latence de quelques minutes vous convient mais que votre équipe est à l'aise avec le SDK Java, Snowpipe Streaming sera la meilleure option : il livre les données plus rapidement et à un coût inférieur.
Ressources complémentaires
Pour approfondir le sujet, Snowflake propose une documentation très complète sur Snowpipe Streaming et les autres méthodes de chargement. Je recommande aussi vivement cette présentation Snowflake, qui propose un benchmark détaillé des différentes options de chargement à partir de données réelles.
Tomáš Sobotík·Senior Data Engineer & Snowflake SME chez Norlys
Tomas est un Snowflake Data SuperHero de longue date et un expert reconnu de Snowflake. Son expérience dans le monde de la data s'étend sur plus d'une décennie, durant laquelle il a occupé les rôles de data engineer, architecte et administrateur Snowflake sur des projets variés, dans des secteurs et avec des technologies divers. Tomas est un membre actif de la communauté : il partage volontiers son expertise et inspire les autres. Il est également formateur chez O'Reilly et anime des sessions de formation en ligne en direct.