Saber carregar dados na sua conta Snowflake de forma eficiente é fundamental. O Snowflake oferece diversas opções de ingestão, cada uma com seus prós, contras e pontos de atenção.
Há várias alternativas tanto para carga em batch quanto para carga contínua ou em tempo real, e todas escalam para suportar grandes volumes de dados. A escolha certa influencia custo, performance, confiabilidade e facilidade de manutenção — e cada um desses fatores precisa entrar na conta.
Neste post, mergulho nas cinco opções de carga de dados e mostro os tradeoffs envolvidos: latência, custo, manutenção e nível técnico exigido. Você também vai ver boas práticas para cada método. No final, resumo as opções e dou algumas diretrizes para te ajudar a decidir.
Carga em batch
A carga em batch é a abordagem de ingestão mais comum em qualquer data warehouse. Nela, os dados são carregados em massa no data warehouse seguindo uma programação fixa (uma vez por dia, uma vez por hora, a cada 4 horas etc.). Costuma ser a opção mais simples, mas tem um grande tradeoff: a latência. Se seus dados são carregados uma vez por dia, eles podem ficar mais de 24 horas desatualizados até a próxima carga.
Na prática, a ingestão em batch costuma pegar arquivos do cloud storage (um bucket do Amazon S3, Microsoft Azure Blob Storage ou Google Cloud Storage) e usar algum processo ou ferramenta de orquestração para carregá-los automaticamente no Snowflake em uma programação definida.
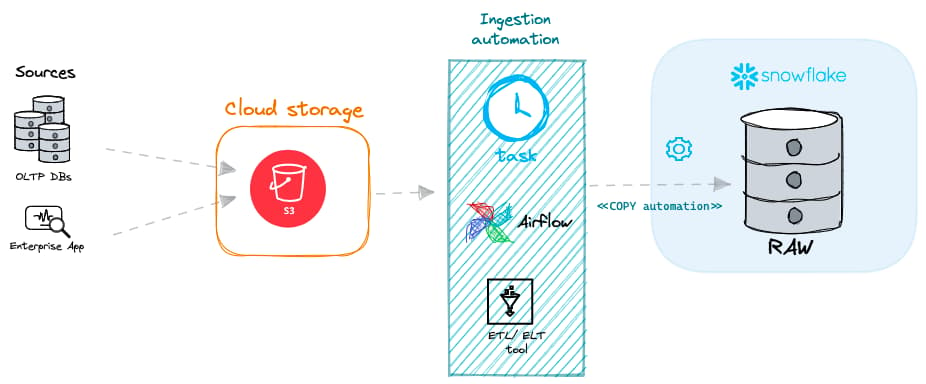
No Snowflake, há duas abordagens principais para ingestão em batch.
Carga em batch com seu próprio virtual warehouse
Pela minha experiência, a forma mais comum de carregar dados no Snowflake é executando o comando COPY INTO em um dos seus próprios virtual warehouses gerenciados.
Esse comando pega arquivos previamente enviados para um stage interno ou externo do Snowflake e os ingere na tabela de destino. Podem ser CSV, dados JSON ou qualquer outro formato de arquivo suportado.
O comando COPY roda em um dos seus virtual warehouses gerenciados, ou seja, é você quem cria e dimensiona o virtual warehouse corretamente (dica: comece sempre com um warehouse X-SMALL e aumente o tamanho só se for preciso para atender ao seu SLA).
Considerações de custo e eficiência
Ao carregar dados com o COPY INTO no Snowflake, você paga por cada segundo em que o virtual warehouse fica ativo. Os virtual warehouses do Snowflake têm cobrança mínima de 60 segundos sempre que são retomados, então o ideal é que seu processo de carga dure perto desses 60 segundos a cada execução.
O menor virtual warehouse consegue ingerir 8 arquivos em paralelo, e esse número dobra a cada aumento de tamanho. Por exemplo, para aproveitar plenamente um warehouse medium, você precisa de 32 arquivos. Se um arquivo for bem maior que os outros, as demais threads podem ficar ociosas enquanto apenas uma trabalha.
A carga em batch no seu próprio virtual warehouse pode ser uma das formas mais econômicas de carregar dados no Snowflake — desde que você tenha arquivos e dados suficientes para saturar o warehouse e não acabe pagando por compute ocioso. Vale conferir nosso outro post sobre boas práticas de carga em batch.
Habilidades necessárias
Usar o comando COPY não exige nada além de conhecimento básico de SQL.
Com essa opção, você vai precisar de alguma ferramenta de agendamento ou orquestração que execute o COPY na frequência desejada.
Carga em batch com serverless tasks
As serverless tasks permitem que os usuários do Snowflake executem comandos SQL em uma programação definida usando recursos de compute do próprio Snowflake, em vez do seu virtual warehouse gerenciado. Dá para configurar uma serverless task que rode o COPY INTO na frequência que você quiser.
Assim como ao rodar o COPY INTO no seu próprio warehouse, a latência ou desatualização dos dados vai depender de quão frequentemente o COPY roda para carregar novos dados.
Considerações de custo e eficiência
Como você só paga por segundo de compute utilizado, as serverless tasks ajudam a resolver o problema de compute subutilizado que aparece na carga em batch com seu próprio virtual warehouse. Se seu processo de carga leva só 10 segundos cada vez que roda, no seu warehouse gerenciado você acabaria pagando por mais 50 segundos de compute toda vez.
O compute das serverless tasks é cobrado a 1,5x o valor de um virtual warehouse equivalente gerenciado por você. Por isso, do ponto de vista de eficiência de custo, elas só fazem sentido se você não conseguir saturar plenamente um virtual warehouse por pelo menos 40s dos 60 segundos mínimos do período de cobrança.
Habilidades necessárias
Carregar dados no Snowflake com uma serverless task é provavelmente a opção mais simples de ingestão disponível. Basta um conhecimento prático de SQL, sem precisar de nenhuma ferramenta de orquestração de terceiros.
Carga contínua com Snowpipe
Diferentemente do processamento em batch, que roda em uma programação fixa, a carga contínua processa dados a partir de algum evento — em geral, um novo arquivo chegando ao cloud storage. Esses arquivos podem vir de várias fontes, desde um serviço de change data capture que registra dados de um banco relacional até eventos de uma aplicação web. Cada novo arquivo dispara uma notificação de evento, que aciona automaticamente o processo de carga. Serviços de mensageria em nuvem como AWS SNS ou SQS costumam ser usados para essas notificações. Eles se integram diretamente ao Snowflake e avisam a plataforma sobre os arquivos recém-chegados.
Com a carga contínua, a latência dos dados cai bastante, já que novos dados são carregados a todo momento, assim que ficam disponíveis.
Para simplificar a carga de dados e viabilizar o processamento contínuo, o Snowflake oferece um recurso poderoso chamado Snowpipe. Ele é integrado a um serviço de notificação de eventos do lado do provedor de nuvem (por exemplo, AWS SNS/SQS). Cada objeto Snowpipe também tem um comando COPY associado. As notificações de evento avisam o Snowpipe sobre novos arquivos carregados em um stage externo, o que dispara a execução do COPY correspondente.
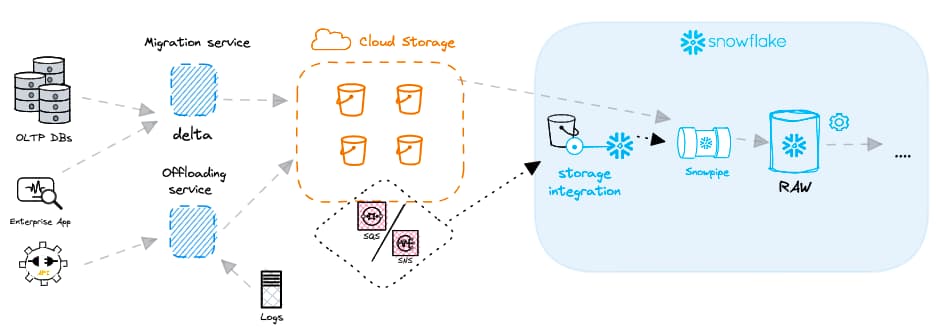
A maioria dos clientes usa o recurso "auto-ingest" do Snowpipe, em que os arquivos são carregados automaticamente assim que chegam. Mas vale lembrar que também existe uma REST API do Snowpipe, que permite escolher quando um objeto Snowpipe é acionado.
O Snowpipe é um recurso serverless, então você não precisa se preocupar em escolher o virtual warehouse nem em dimensioná-lo: o compute é totalmente mantido e gerenciado pelo Snowflake. Em termos de latência, o Snowpipe normalmente ingere os arquivos em poucos minutos depois que eles chegam ao cloud storage.
Considerações de custo e eficiência
O fator que mais afeta a eficiência de custo do Snowpipe é o tamanho do arquivo. O Snowpipe cobra uma taxa de overhead de 0,06 crédito a cada 1.000 arquivos processados. Por isso, o custo de carregar 100GB pode variar bastante conforme o tamanho dos arquivos, já que isso muda a quantidade total. O compute do Snowpipe é cobrado a 1,25 crédito por compute-hour.
O Snowflake recomenda mirar em arquivos de 100 a 250MB compactados. Se suas aplicações upstream costumam mandar dados em arquivos pequenos, considere implementar um processo que agregue esses arquivos em lotes maiores. Um serviço bastante usado para isso é o Amazon Kinesis Firehose. Como alternativa, dá para avaliar outras opções de processamento em tempo real, como o Snowpipe Streaming (que veremos a seguir).
Habilidades necessárias
Para configurar um job de carga com Snowpipe, você vai precisar acessar seu provedor de nuvem para criar o serviço de notificação de eventos necessário.
Depois que o cloud storage e os serviços de notificação upstream estiverem configurados, a criação do objeto Snowpipe pode ser feita inteiramente em SQL.
Carga em tempo real com Kafka
Vários casos de uso, em diferentes setores, exigem dados em tempo real: credit scoring, análise de fraude ou até analytics voltado ao usuário final. Entregar dados com baixa latência costuma envolver um message broker como o Apache Kafka. Em vez de arquivos, o Kafka recebe mensagens de diversos "data producers" e as encaminha para diferentes "data consumers". No contexto da carga de dados, o Snowflake assume o papel de data consumer.
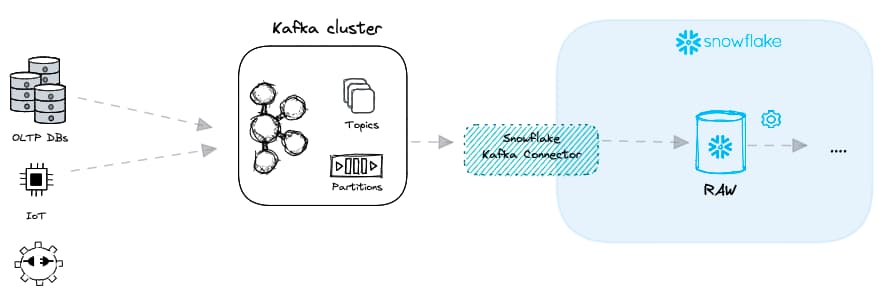
Usar o Kafka com o Snowflake para chegar a uma carga de dados de baixa latência pode ser feito de duas formas:
- Modo "Snowpipe", que combina o Kafka com os métodos tradicionais de Snowpipe que discutimos acima.
- Modo "Snowpipe Streaming", uma novidade lançada pelo Snowflake em 2023.
Kafka Connector — modo Snowpipe
O modo Snowpipe do Kafka connector combina micro-batching de arquivos com Snowpipes. As mensagens do Kafka são descarregadas em arquivos temporários e ingeridas via Snowpipe.
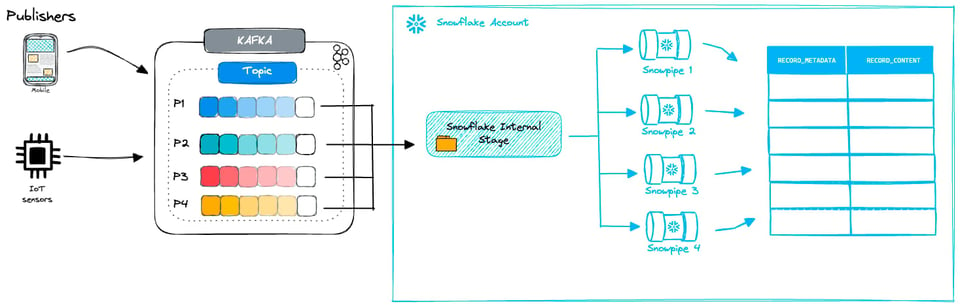
Com o Kafka connector, dá para configurar a frequência com que novos arquivos serão criados. Como vimos antes, ao usar Snowpipes tradicionais o ideal é mirar em arquivos de 100 a 250MB. Manter esse tamanho ótimo pode ser desafiador diante de outros fatores em jogo:
- Com que frequência sua origem gera dados e em quanto tempo eles precisam estar no Snowflake
- O flush rate: com que frequência os dados são descarregados nos arquivos — configurável nas opções do Kafka connector
- A quantidade de partições no seu cluster Kafka
Considerações de custo
Com essa opção, você é cobrado apenas pela ingestão via Snowpipe, com os mesmos valores e nuances já discutidos.
Habilidades necessárias
Usar essa opção de carga de dados exige um ambiente Kafka funcional e o conhecimento correspondente para criar e gerenciar essa infraestrutura — o que pode ser uma barreira considerável para muitos times.
Snowpipe Streaming
O Snowpipe Streaming é a adição mais recente entre os recursos do Snowflake voltados a streaming de dados. Essa opção oferece latência ainda melhor (na casa dos segundos) do que o modo Snowpipe descrito acima.
Com o Snowpipe Streaming, não existe stage, não existem arquivos e não existem objetos Snowpipe (o que, reconheço, é confuso, já que o nome inclui "Snowpipe"). Aqui os dados são carregados linha a linha, em vez de via arquivos.
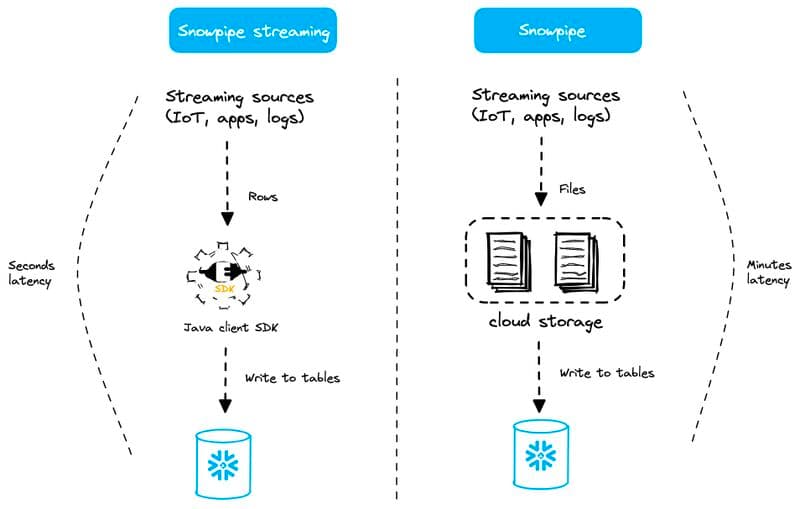
Considerações de custo
Assim como o Snowpipe tradicional, o Snowpipe Streaming usa um modelo de compute serverless. O Snowflake gerencia os recursos de compute automaticamente conforme a carga de streaming. Para estimar os custos, o melhor é fazer um teste com um workload de streaming típico.
O compute do Snowpipe Streaming é mais barato que o do Snowpipe tradicional: 1 crédito por compute-hour, contra 1,25 do Snowpipe. Não há cobrança por cloud services, mas o Snowflake cobra uma taxa horária de 0,01 crédito por cliente de streaming. Por isso, fique de olho na quantidade de clientes que você cria. Se um usuário criar 100 clientes, essa taxa de overhead chegaria a US$ 22.000 por ano, considerando um preço de US$ 2,50 por crédito (100*0,01*24*365*2,5).
Segundo o próprio Snowflake e outras fontes, esse é o método mais econômico de carregar dados no Snowflake.
Habilidades necessárias
O Snowpipe Streaming é a opção de carga mais atraente em termos de eficiência de custo e menor latência. Mas é também a que exige mais conhecimento técnico. A API do Snowpipe Streaming faz parte do Java SDK, ou seja, você precisa ter familiaridade com Java para usar o recurso.
Como escolher a opção de carga de dados
Agora que cobrimos todas as opções de carga, você deve estar se perguntando como escolher a certa. No fim das contas, é preciso levar em conta todos os aspectos que discutimos:
- Que latência seu caso de uso exige?
- Você busca a opção mais econômica?
- Qual é a expertise técnica do seu time e como a opção de carga se encaixa no seu stack atual?
- Qual sistema produz os dados e arquivos que você precisa carregar — e você tem controle sobre ele?
Vamos resumir tudo em uma tabela para destacar as considerações de cada opção:
| Método | Opção | Menor latência possível | Habilidades necessárias |
|---|---|---|---|
| BATCH | Comando COPY | Minutos | SQL |
| BATCH | Serverless task | Minutos | SQL |
| CONTÍNUO | Snowpipe | Minutos | SQL + cloud |
| TEMPO REAL | Kafka modo Snowpipe | Minutos | SQL + cloud + Kafka |
| TEMPO REAL | Kafka Snowpipe Streaming | Segundos | SQL + cloud + Java |
Se você prefere uma árvore de decisão visual, dê uma olhada no diagrama abaixo. Vale notar que ele não cobre todos os casos de borda nem todas as considerações possíveis. Por exemplo, alguns usuários conseguem usar o Snowpipe de forma bem econômica mesmo com arquivos menores que 100MB, desde que não sejam muitos.
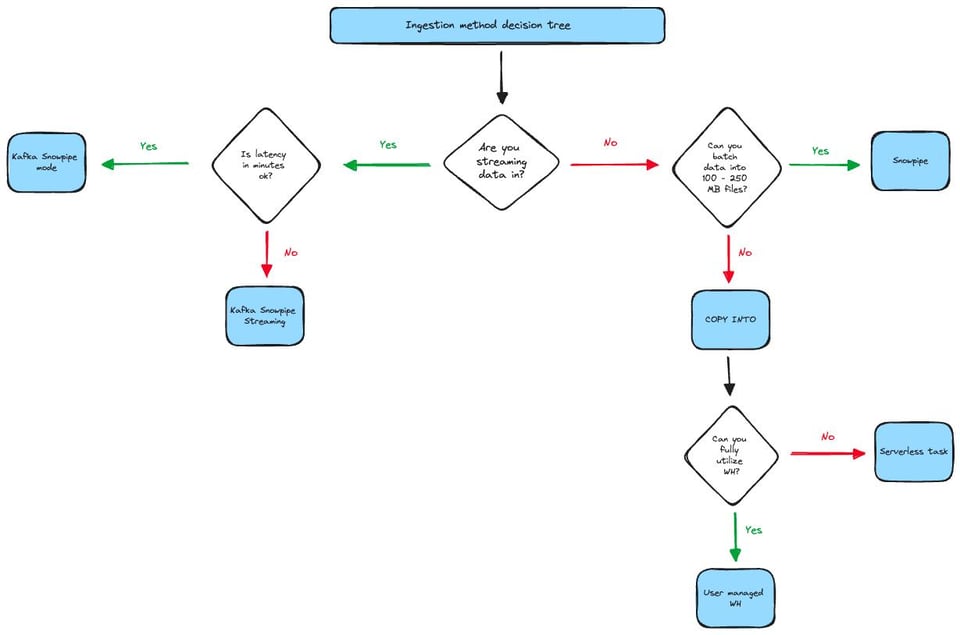
Esse fluxograma considera principalmente latência e tamanho de arquivo como os dois critérios-chave. Olhando para o lado esquerdo da árvore: se latência em minutos não é problema, mas seu time tem traquejo com o Java SDK, então o Snowpipe Streaming é a melhor opção, porque entrega os dados mais rápido e a um custo menor.
Recursos adicionais
Se quiser se aprofundar, o Snowflake tem uma documentação bem completa sobre Snowpipe Streaming e os demais métodos de carga de dados. Também recomendo muito assistir a esta apresentação do Snowflake, que faz um benchmark detalhado das diferentes opções de carga com dados reais.
Tomáš Sobotík · Senior Data Engineer e Snowflake SME na Norlys
Tomas é Snowflake Data SuperHero há bastante tempo e referência geral em Snowflake. Sua experiência no mundo dos dados passa de uma década, período em que atuou como data engineer, arquiteto e admin de Snowflake em projetos de diferentes setores e tecnologias. Tomas é membro ativo da comunidade, sempre compartilhando seu conhecimento e inspirando outros profissionais. Também é instrutor da O'Reilly, conduzindo treinamentos ao vivo online.