Snowflakeアカウントへ効率よくデータをロードする方法を知っておくことは欠かせません。Snowflakeにはさまざまなデータ取り込みオプションが用意されており、それぞれにメリット・デメリットと押さえておきたいポイントがあります。
バッチ処理にも継続的/リアルタイムロードにも複数の選択肢があり、いずれも大規模データセットの取り込みに耐えるスケーラビリティを備えています。どれを選ぶかによって、コスト、パフォーマンス、信頼性、運用のしやすさが変わってくるため、これらの要素を総合的に判断する必要があります。
本記事では、5つのデータロード方式を掘り下げ、レイテンシ、コスト、運用負荷、必要となる技術スキルといった観点でのトレードオフを解説します。各手法のベストプラクティスもあわせて紹介し、最後に全体を整理して選択の指針となる一般的なガイドラインをまとめます。
バッチロード
バッチロードは、あらゆるデータウェアハウスで最も広く使われているデータ取り込み手法です。決まったスケジュール(1日1回、1時間に1回、4時間ごとなど)でデータをまとめてウェアハウスにロードします。最もシンプルな方法ですが、レイテンシという大きなトレードオフがあります。1日1回のロードであれば、次のロードまでに最大24時間以上、データが古いままになる可能性があります。
バッチ取り込みは通常、クラウドストレージ(Amazon S3バケット、Microsoft Azure Blob Storage、Google Cloud Storage)からファイルを取得し、プロセスやオーケストレーションツールがスケジュールに沿って自動的にSnowflakeへロードするという流れで動きます。
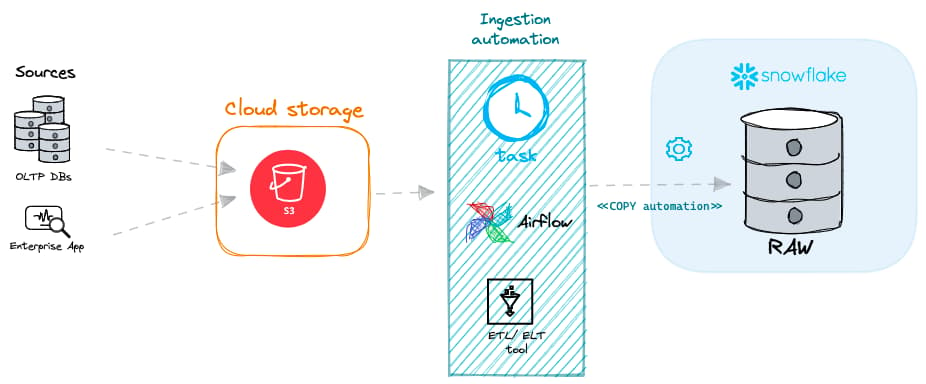
Snowflakeにおけるバッチデータ取り込みのアプローチは、大きく2つに分かれます。
自前の仮想ウェアハウスを使ったバッチロード
筆者の経験上、Snowflakeへのデータロードで最も一般的なのは、自分で管理している仮想ウェアハウス上でCOPY INTOコマンドを実行する方法です。
このコマンドは、Snowflakeの内部ステージや外部ステージにあらかじめアップロードしておいたファイルを対象テーブルに取り込みます。ファイル形式はCSV、JSONデータ、その他サポートされているファイル形式のいずれでも構いません。
COPYコマンドは自分で管理する仮想ウェアハウス上で動くため、ウェアハウスの作成と適切なサイジングはユーザーの責任になります(ヒント:まずはX-SMALLから始め、SLAを満たせない場合のみサイズを上げましょう)。
コストと効率の考慮ポイント
SnowflakeでCOPY INTOコマンドを使ってデータをロードする場合、仮想ウェアハウスが稼働している秒数に対して課金されます。Snowflakeの仮想ウェアハウスは再開のたびに最低60秒分が課金されるため、ロード処理が毎回60秒近くかかるよう設計するのが望ましいです。
最小サイズの仮想ウェアハウスは8ファイルを並列で取り込めます。この並列数はウェアハウスのサイズが1段階上がるごとに倍になります。たとえばMediumサイズを使い切るには32ファイルが必要です。1つのファイルが極端に大きい場合、1スレッドだけが処理を続け、他のスレッドが遊んでしまうこともあります。
自前の仮想ウェアハウスでのバッチロードは、ウェアハウスを使い切れるだけのファイル数とデータ量があり、アイドル時間に余計な課金が発生しない限り、Snowflakeへのデータロード方法の中でも特にコスト効率が高い選択肢です。詳しくはバッチデータロードのベストプラクティスに関する記事もあわせてご覧ください。
必要なスキル
COPYコマンドの利用には、基本的なSQL知識以外に特別なスキルは必要ありません。
ただし、希望のスケジュールでCOPYコマンドを動かすためのスケジューラやオーケストレーションツールは別途用意する必要があります。
サーバーレスタスクによるバッチロード
サーバーレスタスクを使えば、自分で管理する仮想ウェアハウスではなく、Snowflake側のコンピュートリソースで、定めたスケジュール通りにSQLコマンドを実行できます。サーバーレスタスクでCOPY INTOコマンドを任意の頻度で実行するよう設定することも可能です。
自前ウェアハウスでCOPY INTOを実行する場合と同様、データのレイテンシ(鮮度)はCOPYコマンドの実行頻度に左右されます。
コストと効率の考慮ポイント
サーバーレスタスクは使用したコンピュートの秒数分だけ課金されるため、自前ウェアハウスでのバッチロードで起こりがちな「コンピュートを使い切れない問題」を回避できます。ロード処理が毎回10秒で終わるような場合、自前ウェアハウスでは毎回50秒分の余計なコンピュート費用を払うことになります。
サーバーレスタスクのコンピュートコストは、同等サイズのユーザー管理仮想ウェアハウスの1.5倍のレートで課金されます。そのため、コスト効率の観点では、最低課金単位である60秒のうち少なくとも40秒間、仮想ウェアハウスを使い切れない場合にのみ採用するのが妥当です。
必要なスキル
サーバーレスタスクによるSnowflakeへのデータロードは、おそらく最も手軽な取り込み方法です。SQLの基本知識さえあればよく、サードパーティのオーケストレーションツールも不要です。
Snowpipeによる継続的ロード
固定スケジュールで動くバッチ処理とは異なり、継続的ロードは何らかのイベント(通常はクラウドストレージへの新規ファイル到着)をきっかけにデータを処理します。ファイルのソースは、リレーショナルデータベースの変更を記録するCDC(変更データキャプチャ)サービスから、Webアプリケーションのイベントデータまでさまざまです。新しいファイルが届くたびにイベント通知が発火し、ロード処理が自動的に開始されます。通知のトリガーには、AWS SNSやSQSといったクラウドベースのメッセージングサービスがよく使われます。これらはSnowflakeと直接連携でき、新しく到着したファイルの存在をプラットフォームに伝えられます。
継続的ロードでは、新しいデータが利用可能になり次第すぐに取り込まれるため、データのレイテンシを大幅に抑えられます。
このデータロードの効率化と継続的処理を実現するために、SnowflakeはSnowpipeという強力な機能を提供しています。Snowpipeはクラウドプロバイダー側のイベント通知サービス(AWS SNS/SQSなど)と連携し、各Snowpipeオブジェクトには対応するCOPYコマンドが紐づきます。イベント通知によって外部ステージへの新規ファイル到着がSnowpipeオブジェクトに伝わると、紐づいたCOPYコマンドが実行される仕組みです。
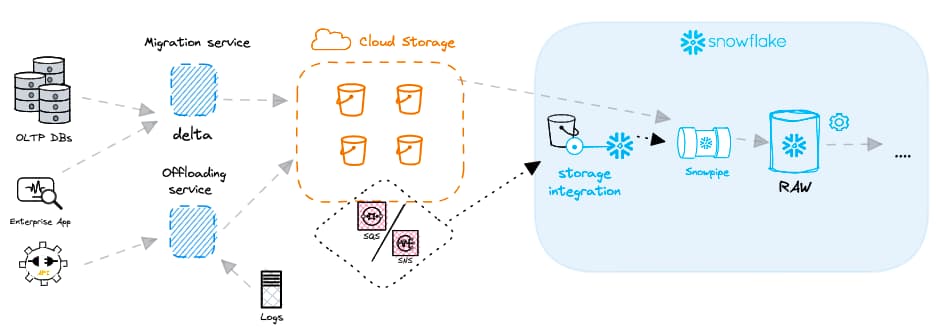
多くのユーザーはSnowpipeの「auto-ingest」機能を利用しており、ファイルが到着すると自動的にロードされます。一方で、Snowpipeオブジェクトを発火させるタイミングを自分で指定できるSnowpipe用REST APIも用意されています。
Snowpipeはサーバーレス機能のため、どの仮想ウェアハウスを使うか、サイズが適切かといった点を気にする必要はありません。コンピュートはすべてSnowflakeが管理・運用します。レイテンシの面では、Snowpipeは通常、ファイルがクラウドストレージに到着してから数分以内に取り込みを完了します。
コストと効率の考慮ポイント
Snowpipeのコスト効率に最も大きく影響するのはファイルサイズです。Snowpipeは1,000ファイル処理ごとに0.06クレジットのオーバーヘッド料金がかかります。そのため、100GBをロードするコストはファイルサイズ(=ファイル数)によって大きく変動します。Snowpipeのコンピュートリソースはコンピュート時間あたり1.25クレジットで課金されます。
Snowflakeは、ファイルサイズを圧縮後100〜250MBにすることを推奨しています。上流アプリケーションが小さなファイルを頻繁に送ってくる場合は、ファイルを集約してより大きなバッチを作るプロセスの導入を検討するとよいでしょう。この用途にはAmazon Kinesis Firehoseがよく使われます。もしくは、後述のSnowpipe Streamingなど、他のリアルタイムデータ処理オプションを選ぶ手もあります。
必要なスキル
Snowpipeのロードジョブを構築するには、必要なイベント通知サービスを作成するためにクラウドプロバイダー側へアクセスできることが前提となります。
上流のクラウドストレージとイベント通知サービスの設定さえ済めば、Snowpipeオブジェクトの作成はすべてSQLで完結します。
Kafkaによるリアルタイムロード
クレジットスコアリング、不正検知、ユーザー向け分析など、さまざまな業界でリアルタイムデータを必要とするユースケースが存在します。低レイテンシでデータを届けるには、通常Apache Kafkaのようなメッセージブローカーが使われます。Kafkaはファイルではなく、さまざまな「データプロデューサー」からメッセージを受け取り、それを異なる「データコンシューマー」へ配信します。データロードの文脈では、Snowflakeがデータコンシューマーの役割を担います。
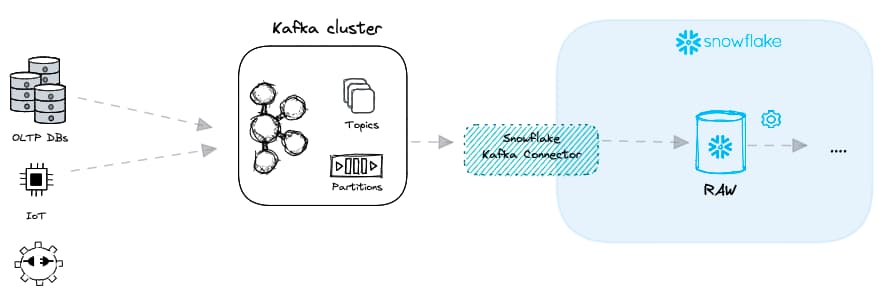
KafkaとSnowflakeを組み合わせて低レイテンシのデータロードを実現する方法は、大きく2通りあります。
- 「Snowpipeモード」:Kafkaと、先ほど解説した従来のSnowpipe方式を組み合わせる方法。
- 「Snowpipe Streaming」モード:2023年にSnowflakeが提供を開始した新方式。
Kafkaコネクタ — Snowpipeモード
KafkaコネクタのSnowpipeモードは、マイクロバッチ化したファイルとSnowpipeを組み合わせて動作します。Kafkaのメッセージは一時ファイルにフラッシュされ、Snowpipe経由で取り込まれます。
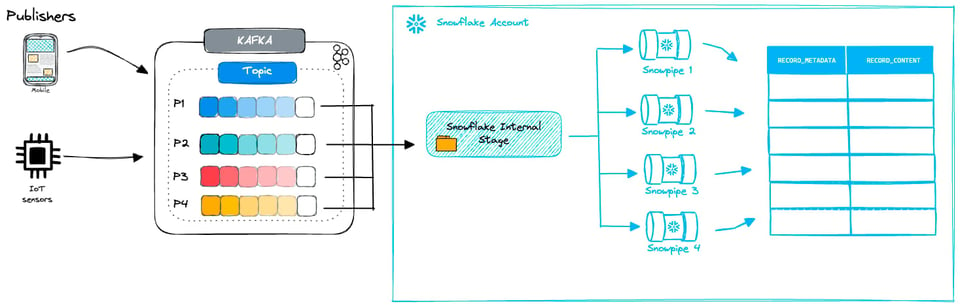
Kafkaコネクタでは、新しいファイルが作成される頻度を設定できます。先述のとおり、通常のSnowpipeを使う場合は100〜250MBのファイルサイズを目指したいところですが、以下のような要素が絡むため、最適なサイズを維持するのは簡単ではありません。
- ソースがどの程度の頻度でデータを生成し、Snowflakeへどれくらい早くロードする必要があるか
- フラッシュレート:データをファイルに書き出す頻度(Kafkaコネクタのオプションで設定可能)
- Kafkaクラスタのパーティション数
コストの考慮ポイント
このオプションで課金されるのはSnowpipeの取り込み分のみで、先述と同じ料金体系・注意点が当てはまります。
必要なスキル
このデータロード方式を使うには、稼働中のKafka環境と、それを構築・運用できる知識が必要です。これは多くのチームにとって大きなハードルになり得ます。
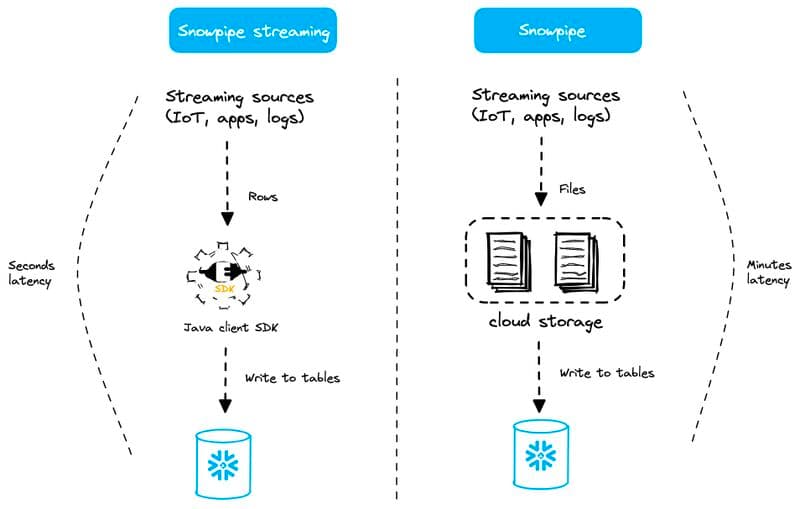
Snowpipe Streaming
Snowpipe Streamingは、Snowflakeのデータストリーミング関連機能の中でも最新のものです。先述のSnowpipeモードよりもさらに低い秒単位のレイテンシを実現できます。
Snowpipe Streamingではステージもファイルも、Snowpipeオブジェクトも存在しません(名前に「Snowpipe」が入っているので紛らわしい点ですが)。ファイルを介さず、行単位でデータをロードする仕組みです。
コストの考慮ポイント
通常のSnowpipeと同様、Snowpipe Streamingもサーバーレスのコンピュートモデルを採用しており、Snowflakeがストリーミング負荷に応じてコンピュートリソースを自動で管理します。料金を見積もるには、実際のストリーミングワークロードで試してみるのが最も確実です。
Snowpipe Streamingのコンピュート単価は通常のSnowpipe(1.25クレジット)より安く、コンピュート時間あたり1クレジットです。クラウドサービスの課金はありませんが、Snowflakeはストリーミングクライアント1つあたり1時間で0.01クレジットを課金します。そのため、作成するクライアント数には注意が必要です。仮に100クライアントを作成した場合、このオーバーヘッド管理料金だけで年間22,000ドルになります(1クレジット2.5ドルの場合:100*0.01*24*365*2.5)。
Snowflake自身や他の情報源によれば、この方式はSnowflakeへのデータロードで最もコスト効率の高い選択肢とされています。
必要なスキル
Snowpipe Streamingは、コスト効率と低レイテンシの両面で最も魅力的なデータロード方式です。一方で、スキル面のハードルも最も高くなります。Snowpipe Streaming APIはJava SDKの一部として提供されているため、利用にはJavaの知識が必須です。
データロード方式の選び方
ここまで主要なデータロード方式を一通り見てきました。では、どれを選べばよいのでしょうか。最終的には、これまで紹介してきた次のような観点を総合的に判断する必要があります。
- ユースケースで求められるレイテンシはどの程度か
- とにかくコスト効率を重視したいのか
- チームの技術スキルはどの程度で、その方式は既存スタックにどう組み込めるか
- ロード対象のデータやファイルを生成しているのはどのシステムで、それを自分たちでコントロールできるか
各方式の特徴を以下の表にまとめます。
| 方式 | オプション | 達成可能な最小レイテンシ | 必要なスキル |
|---|---|---|---|
| BATCH | COPYコマンド | 分単位 | SQL |
| BATCH | サーバーレスタスク | 分単位 | SQL |
| CONTINOUS | Snowpipe | 分単位 | SQL + クラウド |
| REAL TIME | Kafka Snowpipeモード | 分単位 | SQL + クラウド + Kafka |
| REAL TIME | Kafka Snowpipe Streaming | 秒単位 | SQL + クラウド + Java |
図で判断したい方は、以下のデシジョンツリーも参考になります。なお、この図はあらゆるエッジケースや考慮事項を網羅しているわけではありません。たとえば、100MB未満のファイルでも数が多すぎなければ、Snowpipeを十分コスト効率良く使えるケースもあります。
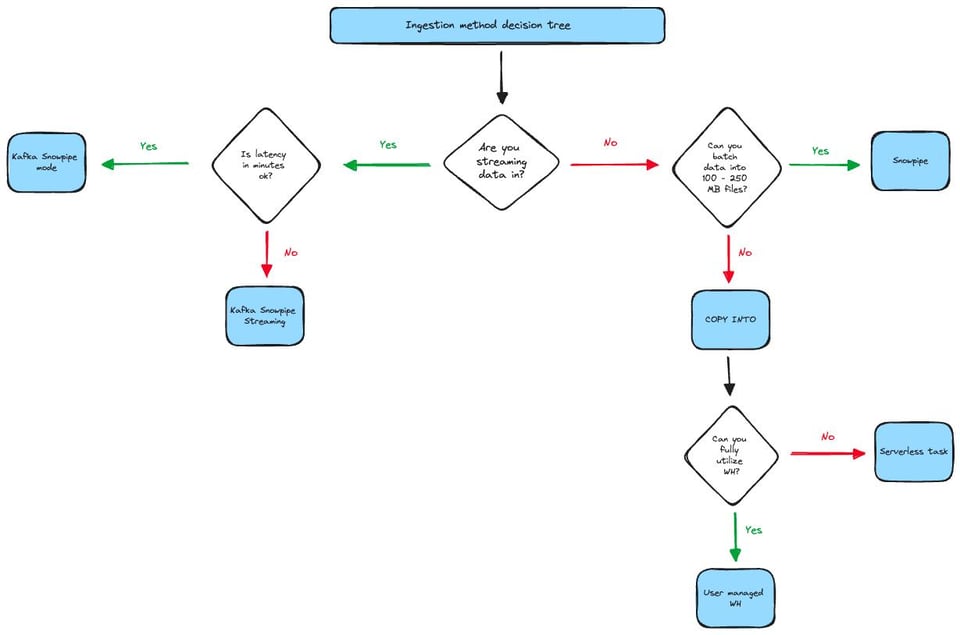
このフローチャートは、主にレイテンシとファイルサイズの2点を判断軸にしています。図の左側を見ると、レイテンシは分単位で問題なくても、チームがJava SDKを扱えるのであれば、より速くデータを届けられてコストも抑えられるSnowpipe Streamingを選んだ方が有利です。
参考情報
さらに詳しく学びたい方には、Snowflake公式のSnowpipe Streamingおよび各種データロード方式に関する充実したドキュメントがおすすめです。また、実データを使って各方式を詳細にベンチマークしているSnowflakeのこのプレゼンテーションもぜひご覧ください。
Tomáš Sobotík・Senior Data Engineer & Snowflake SME at Norlys
TomasはSnowflake Data SuperHeroとして長年活躍する、Snowflake全般のエキスパートです。10年以上にわたるデータ業界での経験を持ち、多様な業界・技術にまたがるプロジェクトでSnowflakeのデータエンジニア、アーキテクト、管理者を務めてきました。コミュニティのコアメンバーとして自らの知見を積極的に発信し、多くの人にインスピレーションを与えています。O'Reillyのインストラクターとしても、ライブのオンライントレーニングを担当しています。