Saper caricare i dati nel proprio account Snowflake in modo efficiente è fondamentale. Snowflake offre diverse opzioni di data ingestion, ognuna con i propri vantaggi, svantaggi e aspetti da valutare con attenzione.
Sono disponibili più opzioni sia per il caricamento batch sia per quello continuo o in tempo reale, tutte scalabili per gestire dataset di grandi dimensioni. La scelta dell'opzione giusta incide su costi, performance, affidabilità e facilità di manutenzione: aspetti che vanno tutti considerati con cura.
In questo articolo analizzerò in dettaglio le cinque opzioni di caricamento dati, mettendo in luce i diversi trade-off in termini di latenza, costo, manutenzione e competenze tecniche richieste. Vedrà inoltre alcune best practice per ciascun metodo. In chiusura riassumerò le opzioni e fornirò linee guida generali per orientare la scelta.
Caricamento batch
Il caricamento batch è l'approccio di data ingestion più diffuso in tutti i data warehouse. Con il batch loading, i dati vengono caricati in blocco nel data warehouse secondo una pianificazione fissa (ad esempio una volta al giorno, una volta all'ora, ogni 4 ore e così via). È solitamente l'opzione più semplice, ma con un grande trade-off: la latenza. Se i dati vengono caricati una volta al giorno, possono risultare obsoleti fino a oltre 24 ore prima del caricamento successivo.
Tipicamente l'ingestion batch preleva i file dal cloud storage (un bucket Amazon S3, Microsoft Azure Blob Storage o Google Cloud Storage) e li carica automaticamente in Snowflake tramite un processo o uno strumento di orchestrazione, secondo una pianificazione.
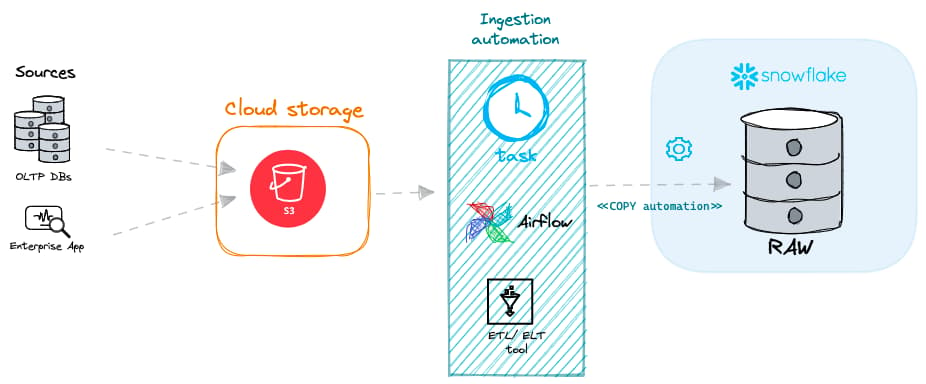
In Snowflake esistono due approcci principali al batch loading.
Batch loading con un proprio virtual warehouse
Nella mia esperienza, il modo più comune per caricare dati in Snowflake è eseguire il comando COPY INTO su uno dei propri virtual warehouse gestiti.
Questo comando prende i file caricati in precedenza in uno stage interno o esterno di Snowflake e li ingerisce nella tabella di destinazione. I file possono essere CSV, dati JSON o qualsiasi altra opzione di formato file supportata.
Il comando COPY viene eseguito su uno dei propri virtual warehouse gestiti: spetta quindi a lei creare e dimensionare correttamente il virtual warehouse (suggerimento: parta sempre da un warehouse X-SMALL e aumenti la taglia solo se necessario per rispettare il proprio SLA).
Costi ed efficienza
Quando si caricano dati con il comando COPY INTO in Snowflake, si paga per ogni secondo in cui il virtual warehouse è attivo. I virtual warehouse di Snowflake vengono fatturati con un minimo di 60 secondi ogni volta che vengono riattivati: è quindi opportuno fare in modo che ciascuna esecuzione del processo di caricamento si avvicini il più possibile a questa soglia minima.
Il virtual warehouse più piccolo è in grado di ingerire 8 file in parallelo. Questo numero raddoppia a ogni incremento di taglia. Per sfruttare appieno un warehouse medium, ad esempio, servirebbero 32 file. Se uno dei file è molto più grande degli altri, può accadere che gli altri thread restino inattivi mentre uno solo continua a lavorare.
Il batch loading sul proprio virtual warehouse può essere uno dei modi più convenienti per caricare dati in Snowflake, a condizione di avere file e volumi sufficienti a saturare il warehouse e di non finire a pagare compute inattivo. Le consigliamo di leggere anche l'articolo dedicato alle best practice per il batch data loading.
Competenze richieste
L'uso del comando COPY non richiede competenze aggiuntive oltre alle conoscenze base di SQL.
Con questa opzione servirà uno strumento di scheduling/orchestrazione che esegua il comando COPY alla cadenza desiderata.
Batch loading con serverless tasks
I serverless tasks permettono agli utenti Snowflake di eseguire comandi SQL secondo una pianificazione definita, sfruttando le risorse di compute di Snowflake invece del proprio virtual warehouse. È possibile configurare un serverless task per eseguire il comando COPY INTO alla frequenza desiderata.
Come per l'esecuzione del comando COPY INTO sul proprio warehouse gestito, la latenza o l'obsolescenza dei dati dipenderà dalla frequenza con cui viene eseguito il comando COPY per caricare nuovi dati.
Costi ed efficienza
Dato che si paga solo per i secondi di compute effettivamente utilizzati, i serverless tasks aiutano a risolvere il problema del sottoutilizzo del compute tipico del batch loading sul proprio virtual warehouse. Se il caricamento richiede solo 10 secondi a esecuzione, sul proprio warehouse gestito si finirebbe per pagare ogni volta 50 secondi aggiuntivi di compute.
Il compute dei serverless tasks viene fatturato a 1,5 volte la tariffa di un virtual warehouse di taglia equivalente gestito da lei. In ottica di efficienza dei costi, conviene quindi usarli solo quando non si riesce a saturare un virtual warehouse per almeno 40 secondi del periodo minimo di fatturazione di 60 secondi.
Competenze richieste
Caricare dati in Snowflake con un serverless task è probabilmente l'opzione di data ingestion più semplice in assoluto. Richiede solo una conoscenza pratica di SQL, senza alcuno strumento di orchestrazione di terze parti.
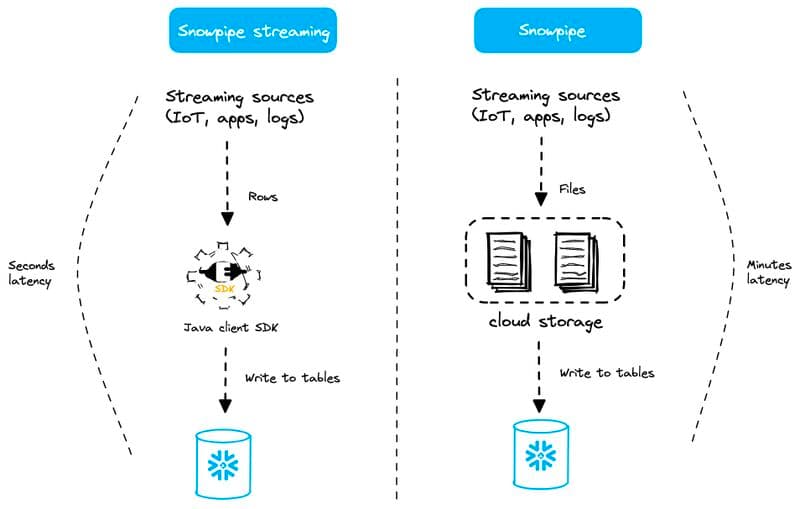
Caricamento continuo con Snowpipe
A differenza del batch, che segue una pianificazione fissa, il caricamento continuo elabora i dati a fronte di un evento, di norma l'arrivo di un nuovo file nel cloud storage. La fonte di questi file può essere qualsiasi: un servizio di change data capture che traccia i record di un database relazionale, dati di eventi di una web application e così via. Ogni nuovo file genera una notifica di evento che avvia automaticamente il processo di caricamento. Servizi di messaggistica cloud come AWS SNS o SQS vengono spesso usati per inviare queste notifiche e possono essere integrati direttamente con Snowflake, informando la piattaforma dei file appena arrivati.
Con il caricamento continuo la latenza dei dati è molto più bassa, perché i nuovi dati vengono caricati man mano che diventano disponibili.
Per semplificare il caricamento e abilitare l'elaborazione continua, Snowflake offre una funzionalità potente: Snowpipe. Snowpipe si integra con un servizio di notifica eventi lato cloud provider (ad esempio AWS SNS/SQS). A ogni oggetto Snowpipe è inoltre associato un comando COPY. Le notifiche di evento avvisano l'oggetto Snowpipe della presenza di nuovi file in uno stage esterno, attivando l'esecuzione del relativo comando COPY.
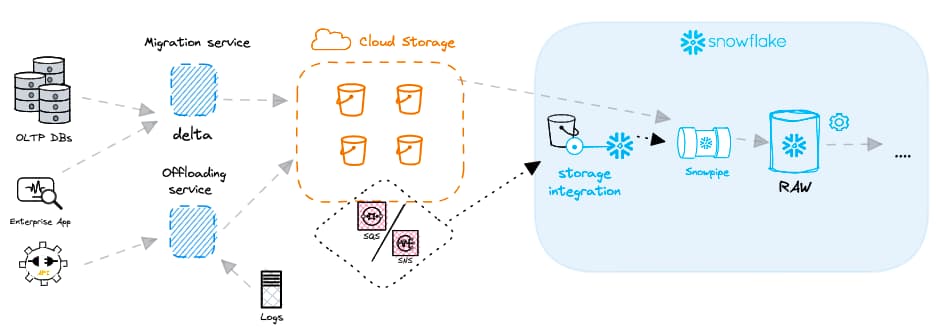
La maggior parte dei clienti utilizza la modalità "auto-ingest" di Snowpipe, con cui i file vengono caricati automaticamente appena arrivano. Vale però la pena ricordare che esiste anche una REST API per Snowpipe che consente di decidere quando attivare un oggetto Snowpipe.
Snowpipe è una funzionalità serverless: non deve quindi preoccuparsi di scegliere il virtual warehouse né di dimensionarlo correttamente. Il compute è interamente gestito da Snowflake. Quanto alla latenza, Snowpipe ingerisce in genere i file entro pochi minuti dal loro arrivo nel cloud storage.
Costi ed efficienza
Il fattore con l'impatto maggiore sull'efficienza dei costi di Snowpipe è la dimensione dei file. Snowpipe applica un costo aggiuntivo di 0,06 credit ogni 1000 file elaborati: di conseguenza, il costo per caricare 100GB può variare sensibilmente in base alla dimensione dei file, che ne determina il numero. Le risorse di compute di Snowpipe vengono fatturate a 1,25 credit per compute-hour.
Snowflake consiglia di puntare a file compressi da 100-250MB. Se le applicazioni a monte inviano spesso dati in file di piccole dimensioni, conviene prevedere un processo che aggreghi i file in batch più grandi. Un servizio comunemente usato a questo scopo è Amazon Kinesis Firehose. In alternativa, si possono valutare altre opzioni di elaborazione in tempo reale come Snowpipe Streaming (di cui parleremo più avanti).
Competenze richieste
Per configurare un job di caricamento Snowpipe è necessario poter accedere al proprio cloud provider per creare il servizio di notifica eventi richiesto.
Una volta configurati il cloud storage a monte e il servizio di notifica eventi, la creazione dell'oggetto Snowpipe può avvenire interamente in SQL.
Caricamento in tempo reale con Kafka
Sono molti i casi d'uso, in svariati settori, che richiedono dati in tempo reale: credit scoring, analisi delle frodi o persino analytics rivolte all'utente finale. Per consegnare i dati con bassa latenza si ricorre tipicamente a un message broker come Apache Kafka. Invece dei file, Kafka riceve messaggi da diversi "data producer" e li inoltra ai vari "data consumer". Nel contesto del caricamento dati, Snowflake assume il ruolo di data consumer.
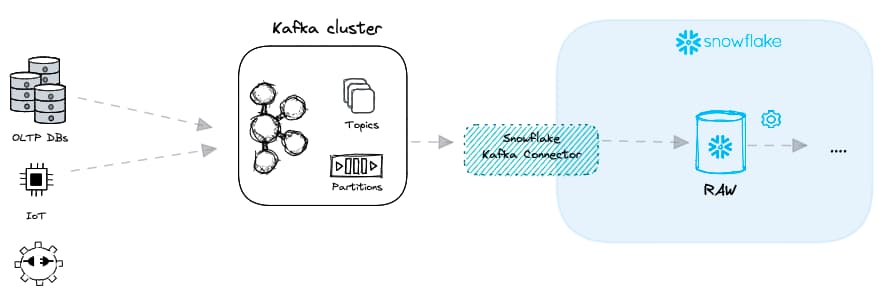
L'integrazione di Kafka con Snowflake per ottenere caricamenti a bassa latenza può essere realizzata in due modi:
- "Snowpipe mode", che combina Kafka con i metodi Snowpipe tradizionali visti sopra.
- "Snowpipe Streaming", una nuova modalità rilasciata da Snowflake nel 2023.
Kafka Connector - Snowpipe mode
La Snowpipe mode del Kafka connector combina micro-batching di file e Snowpipe. I messaggi Kafka vengono scritti in file temporanei e poi ingeriti tramite Snowpipe.
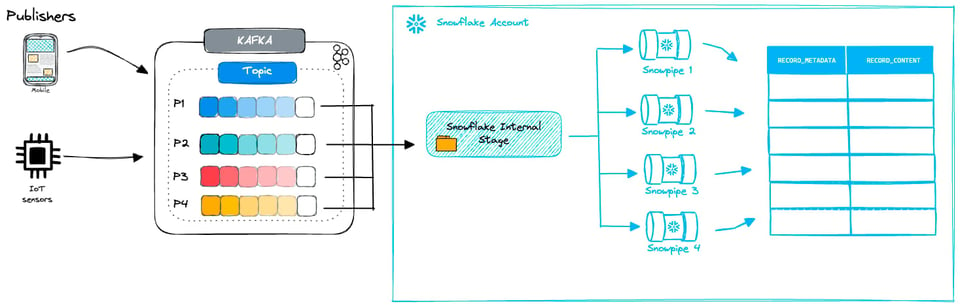
Con il Kafka connector è possibile configurare la frequenza di creazione dei nuovi file. Come anticipato, con i normali Snowpipe è bene puntare a file da 100-250MB. Mantenere questa dimensione ottimale può però risultare complicato, viste le diverse variabili in gioco:
- la frequenza con cui la sorgente genera dati e la rapidità con cui devono essere caricati in Snowflake;
- il flush rate: la frequenza con cui i dati vengono scaricati nei file, configurabile nelle opzioni del Kafka connector;
- il numero di partizioni del cluster Kafka.
Considerazioni sui costi
Con questa opzione viene addebitata solo l'ingestion Snowpipe, con gli stessi costi e le stesse sfumature descritte sopra.
Competenze richieste
Questa opzione di caricamento richiede un ambiente Kafka funzionante e le competenze necessarie per crearlo e gestirlo: per molti team può rappresentare un ostacolo significativo.
Snowpipe Streaming
Snowpipe Streaming è l'ultima aggiunta alle funzionalità Snowflake dedicate allo streaming dei dati. Questa opzione offre una latenza ancora migliore (nell'ordine dei secondi) rispetto alla Snowpipe mode vista sopra.
Con Snowpipe Streaming non ci sono stage, file né oggetti Snowpipe (cosa che, mi rendo conto, può creare confusione, dato che il nome contiene "Snowpipe"). I dati vengono caricati riga per riga, senza passare per i file.
Considerazioni sui costi
Come Snowpipe tradizionale, anche Snowpipe Streaming utilizza un modello di compute serverless. Snowflake gestisce automaticamente le risorse in base al carico di streaming. Per stimare i costi, conviene fare prove con un workload di streaming rappresentativo.
Il compute di Snowpipe Streaming costa meno di quello di Snowpipe tradizionale: 1 credit per compute-hour contro 1,25. Non ci sono addebiti per i cloud services, ma Snowflake applica una tariffa oraria di 0,01 credit per ogni streaming client. È quindi importante tenere d'occhio il numero di client creati: con 100 client, questa fee di gestione costerebbe 22.000 $/anno, ipotizzando un prezzo di 2,5 $/credit (100*0.01*24*365*2.5).
Secondo Snowflake e altre fonti, questo è il metodo più conveniente per caricare dati in Snowflake.
Competenze richieste
Snowpipe Streaming è l'opzione di caricamento dati più interessante in termini di efficienza dei costi e latenza minima, ma è anche quella con la barriera di competenze più alta. L'API di Snowpipe Streaming fa parte del Java SDK: per utilizzarla è quindi necessario avere familiarità con Java.
Come scegliere l'opzione di caricamento dati
Ora che abbiamo passato in rassegna tutte le opzioni di caricamento dati, probabilmente si starà chiedendo come scegliere quella giusta. In ultima analisi, occorre tenere conto di tutti gli aspetti che abbiamo visto:
- Quale latenza richiede il suo caso d'uso?
- Sta cercando l'opzione più efficiente in termini di costi?
- Quali competenze tecniche ha il suo team e come si integra l'opzione di caricamento nello stack esistente?
- Quale sistema produce i dati e i file da caricare e quanto controllo ha su di esso?
Riassumiamo il tutto in una tabella, evidenziando le caratteristiche di ciascuna opzione:
| Metodo | Opzione | Latenza minima possibile | Competenze richieste |
|---|---|---|---|
| BATCH | Comando COPY | Minuti | SQL |
| BATCH | Serverless task | Minuti | SQL |
| CONTINUO | Snowpipe | Minuti | SQL + cloud |
| TEMPO REALE | Kafka Snowpipe mode | Minuti | SQL + cloud + Kafka |
| TEMPO REALE | Kafka Snowpipe Streaming | Secondi | SQL + cloud + Java |
Se preferisce un albero decisionale visivo, può fare riferimento al diagramma qui sotto. Si tenga presente che non copre tutti i casi limite o le considerazioni possibili. Ad esempio, alcuni utenti riescono a usare Snowpipe in modo molto efficiente anche con file inferiori a 100MB, purché non siano troppo numerosi.
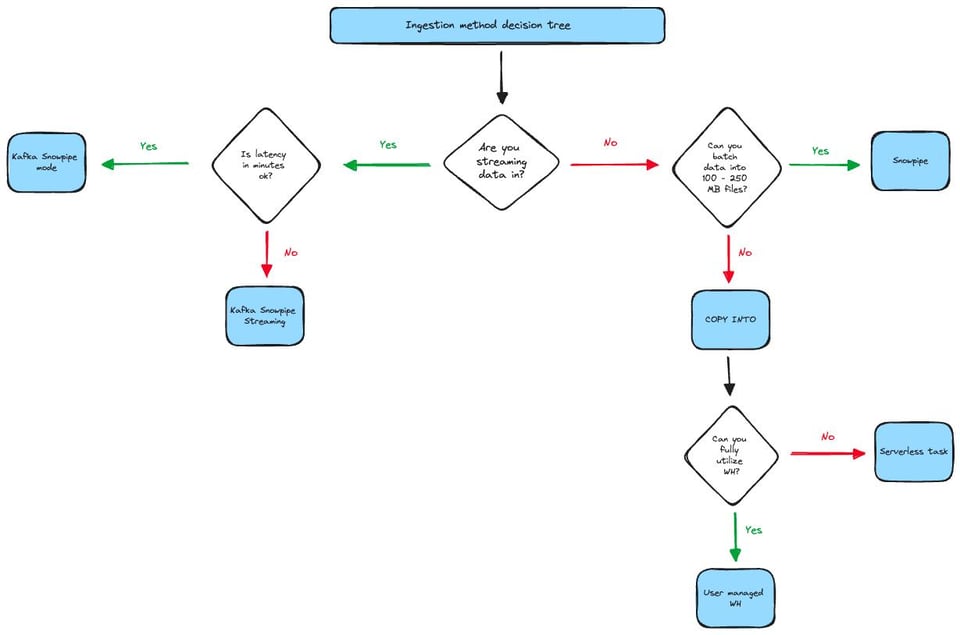
Il diagramma considera principalmente due variabili chiave: latenza e dimensione dei file. Guardando la parte sinistra dell'albero, se può accettare una latenza nell'ordine dei minuti ma il suo team ha dimestichezza con il Java SDK, allora Snowpipe Streaming è l'opzione migliore: consegna i dati più rapidamente e a un costo inferiore.
Risorse aggiuntive
Se vuole approfondire, Snowflake dispone di una documentazione molto completa su Snowpipe Streaming e sugli altri metodi di caricamento dati. Consiglio inoltre di guardare questa presentazione di Snowflake, che propone un benchmark dettagliato delle diverse opzioni di caricamento dati su dati reali.
Tomáš Sobotík·Senior Data Engineer & Snowflake SME presso Norlys
Tomas è da tempo uno Snowflake Data SuperHero ed esperto a tutto tondo della piattaforma. La sua esperienza nel mondo dei dati supera il decennio: ha lavorato come data engineer, architect e admin Snowflake su progetti diversi, in settori e tecnologie eterogenei. È un membro attivo della community, dove condivide la propria competenza e ispira gli altri. È inoltre istruttore O'Reilly e tiene sessioni di formazione live online.