In unserem vorherigen Beitrag zum Snowflake Clustering haben wir gezeigt, warum es entscheidend ist, die Nutzungsmuster einer Tabelle zu kennen, bevor man sich für ein Clustering entscheidet. Wird ein bestimmtes Feld häufig in where-Klauseln verwendet, eignet es sich gut als Cluster Key. Doch was tun, wenn weitere häufig genutzte where-Prädikate ebenfalls von Clustering profitieren würden?
In diesem Beitrag vergleichen wir drei Optionen: 1. Eine einzelne Tabelle mit mehrspaltigen Cluster Keys 2. Mehrere separate Tabellen, jeweils nach einer Spalte geclustert 3. Geclusterte Materialized Views, um das leistungsstarke automatische Pruning von Snowflake zu nutzen
Die Grenzen mehrspaltiger Cluster Keys
Beim Definieren eines Cluster Keys für eine einzelne Tabelle lässt Snowflake auch mehrere Spalten zu. Nehmen wir eine Orders-Tabelle mit 1,5 Milliarden Datensätzen:
-- 1,500,000,000 records
create table orders as (
select
o_orderdate,
o_orderkey,
o_custkey,
o_clerk
from snowflake_sample_data.tpch_sf1000.orders
)
Ein typisches Szenario: Das Finance-Team fragt regelmäßig bestimmte Datumsbereiche dieser Tabelle ab, um das Umsatzvolumen zu analysieren. Parallel durchsuchen die Engineering-Teams die Tabelle, um einzelne Bestellungen nachzuvollziehen. Und das Marketing möchte sämtliche historischen Bestellungen eines bestimmten Kunden einsehen können.
Das sind drei unterschiedliche Zugriffsmuster und damit drei unterschiedliche Spalten, nach denen wir clustern wollen: o_orderdate, o_custkey und o_orderkey. Wie in der Snowflake-Dokumentation beschrieben, lässt sich ein mehrspaltiger Cluster Key definieren, indem alle drei Spalten in der cluster by-Klausel angegeben werden
1:
create table orders cluster by (o_orderdate, o_custkey, o_orderkey) as (
select
o_orderdate, -- 2,406 distinct values
o_orderkey, -- 1,500,000,000 distinct values
o_custkey, -- 99,999,998 distinct values
o_clerk
from snowflake_sample_data.tpch_sf1000.orders
)
Zugriffsmuster 1: Abfrage nach Datum
select
o_orderdate,
count(*) as cnt
from orders
where o_orderdate between '1993-03-01' and '1993-03-31'
group by 1
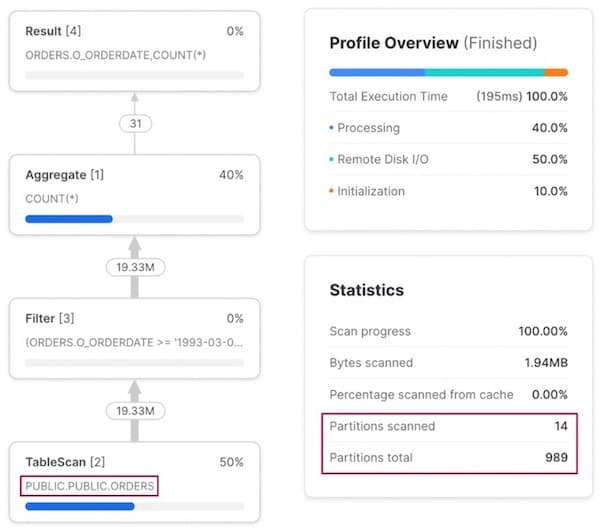
Bei einer Abfrage über einen Datumsbereich zeigt das Query Profile, dass das Query Pruning hervorragend greift. Nur 22 von 1609 Micro-Partitionen werden gescannt.
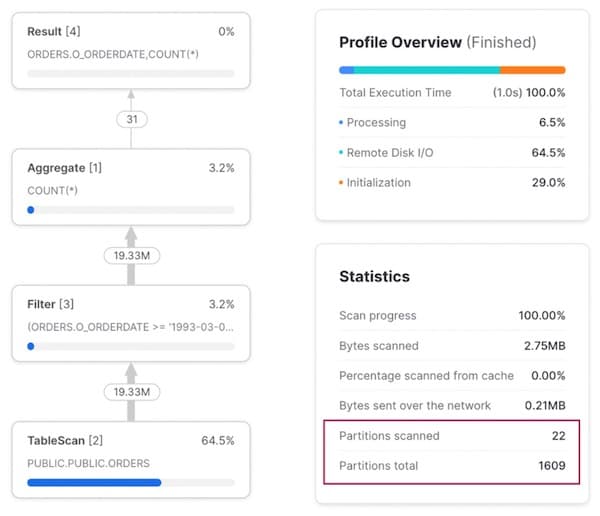
Zugriffsmuster 2: Abfrage nach einem bestimmten Kunden
select *
from orders
where o_custkey = 52671775
Ändern wir die Abfrage auf alle Bestellungen eines bestimmten Kunden, greift das Query Pruning kaum noch: 99 % aller Micro-Partitionen müssen gescannt werden.
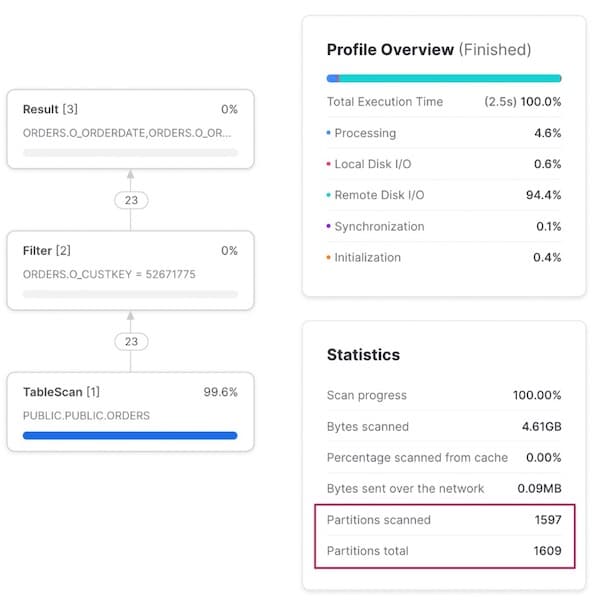
Zugriffsmuster 3: Abfrage nach einer bestimmten Bestellung
select *
from orders
where o_orderkey = 5019980134
Bei der Suche nach einer einzelnen Bestellung – der dritten Spalte unseres Cluster Keys – findet überhaupt kein Pruning mehr statt: Sämtliche Micro-Partitionen werden gescannt, nur um diesen einen Datensatz zu finden.
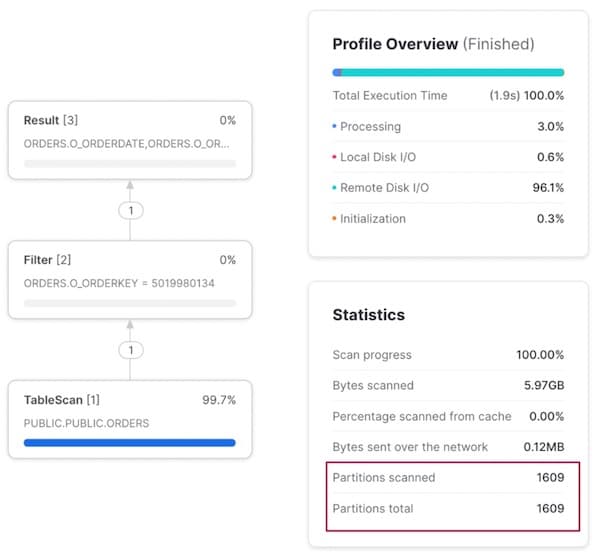
Warum mehrspaltige Cluster Keys an Leistung verlieren
Wie oben zu sehen, lässt die Pruning-Leistung bei Prädikaten (Filtern) auf der zweiten und dritten Spalte deutlich nach.
Um zu verstehen, woran das liegt, muss man wissen, wie Snowflakes Clustering bei mehrspaltigen Cluster Keys arbeitet. Das einfachste Gedankenmodell sind "Schachteln in Schachteln": Snowflake gruppiert die Daten zunächst nach o_orderdate. Innerhalb jeder "Datums-Schachtel" werden die Daten dann nach o_custkey aufgeteilt, und innerhalb dieser Schachteln noch einmal nach o_orderkey.
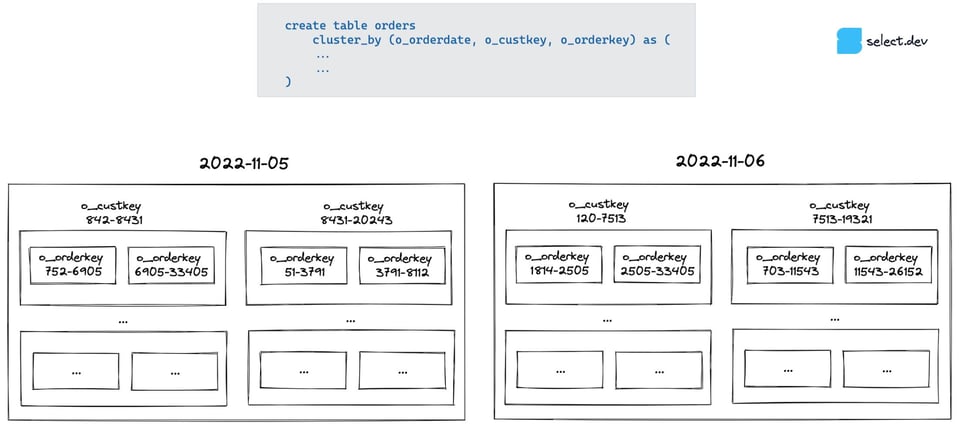
Snowflakes Query Pruning prüft je Micro-Partition die Min-/Max-Metadaten der jeweiligen Spalte. Bei einer Abfrage nach Datum hat jedes Datum seine eigene Schachtel, sodass sich irrelevante Schachteln schnell verwerfen (prunen) lassen. Bei einer Abfrage nach Kunde oder Bestellnummer muss dagegen jede Datums-Schachtel auf oberster Ebene geprüft werden: Die Min-/Max-Werte dieser Spalten streuen extrem breit (an jedem Tag bestellen viele verschiedene Kunden, und Bestellnummern sind zufällige IDs, nicht aufsteigend zum Bestelldatum). Es lassen sich also keine Schachteln ausschließen.
Mehrere Kopien derselben Tabelle mit unterschiedlichen Cluster Keys anlegen
Als Alternative könnten wir für jeden Cluster Key eine eigene Tabelle anlegen und pflegen:
create table orders_clustered_by_date cluster by (o_orderdate) as (
select
o_orderdate,
o_orderkey,
o_custkey,
o_clerk
from snowflake_sample_data.tpch_sf1000.orders
)
create table orders_clustered_by_customer cluster by (o_custkey) as (
select
o_orderdate,
o_orderkey,
o_custkey,
o_clerk
Code erweitern
Dieser Ansatz hat klare Nachteile: Anwender müssen drei verschiedene Tabellen im Kopf behalten und wissen, welche für welches Abfrageszenario gedacht ist. Bei einer breit genutzten Tabelle ist das nicht praktikabel. Zudem müssten Sie alle drei Kopien in Ihren ETL/ELT-Pipelines pflegen.
Geht das nicht eleganter?
Geclusterte Materialized Views: Snowflakes automatisches Pruning voll ausschöpfen
Was sind Materialized Views?
Eine Materialized View ist ein vorab berechneter Datensatz, der aus einer Abfragedefinition abgeleitet und für die spätere Nutzung gespeichert wird
2. Auf die Anwendungsfälle gehen wir in einem späteren Beitrag detailliert ein – fürs Erste empfehlen wir die ausführliche Snowflake-Dokumentation. Wenn Sie eine Materialized View wie die folgende erstellen, pflegt Snowflake diesen abgeleiteten Datensatz automatisch. Werden in der Basistabelle (orders) Daten hinzugefügt oder geändert, aktualisiert Snowflake die Materialized View ebenfalls automatisch.
create materialized view orders_aggregated_by_date as (
select
o_orderdate,
count(*) as cnt
from orders
group by 1
)
Führt nun jemand diese Abfrage gegen die Basistabelle aus:
select
o_orderdate,
count(*) as cnt
from orders
group by 1
scannt Snowflake automatisch die vorab berechnete Materialized View, anstatt den gesamten Datensatz neu zu berechnen.
Automatisch geclusterte Materialized Views erstellen
Materialized Views unterstützen Automatic Clustering. Damit lassen sich zwei neue Materialized Views erstellen, die unsere orders-Tabelle separat nach o_custkey und o_orderkey clustern – für optimale Performance:
-- these will take some time to execute, since the entire dataset is
-- being materialized (created) for the first time
create materialized view orders_clustered_by_customer cluster by(o_custkey) as (
select
o_orderdate,
o_orderkey,
o_custkey,
o_clerk
from orders
)
;
create materialized view orders_clustered_by_order cluster by(o_orderkey) as (
select
o_orderdate,
Code erweitern
Technisch könnten wir eine dritte Materialized View anlegen, die nach o_orderdate geclustert ist. Stattdessen wählen wir den kostengünstigeren Weg und nutzen manuelles Sortieren auf der Basistabelle:
create table orders as (
select
o_orderdate,
o_orderkey,
o_custkey,
o_clerk
from snowflake_sample_data.tpch_sf1000.orders
-- sort and therefore cluster the table by o_orderdate
order by o_orderdate
)
Erneuter Test unserer drei Zugriffsmuster
Zugriffsmuster 1: Abfrage nach Datum
select
o_orderdate,
count(*) as cnt
from orders
where
o_orderdate between date'1993-03-01' and date'1993-03-31'
group by 1
Bei einer Abfrage mit Filter auf o_orderdate wird die ursprüngliche Basistabelle orders verwendet, da sie auf natürliche Weise nach dieser Spalte geclustert ist.
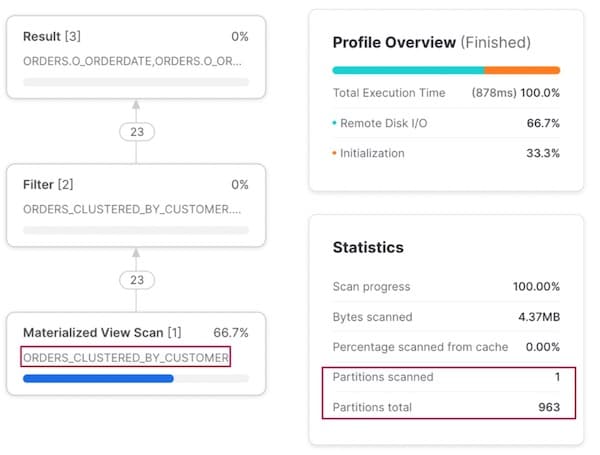
Zugriffsmuster 2: Abfrage nach Kunde
select *
from orders
where
o_custkey=52671775
Filtern wir hingegen nach o_custkey, erkennt der Snowflake-Optimizer, dass eine nach dieser Spalte geclusterte Materialized View existiert, und lenkt den Ausführungsplan entsprechend auf die Materialized View um.
Wichtig: Wir müssen die Abfrage nicht umschreiben, um Snowflake explizit zur Materialized View zu schicken – das geschieht im Hintergrund. Anwender müssen sich also nicht merken, welches Dataset sie in welchem Szenario abfragen sollen.
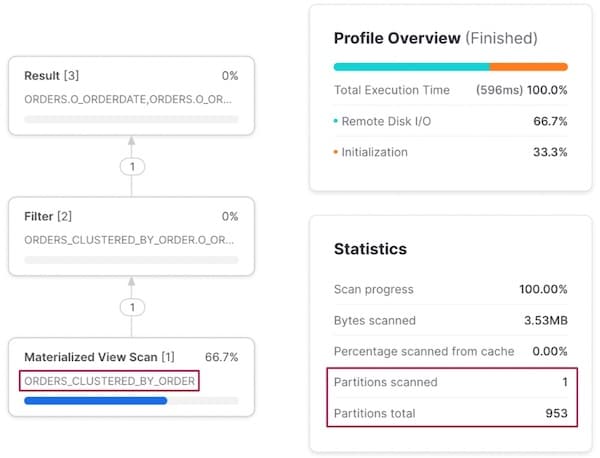
Zugriffsmuster 3: Abfrage nach Bestellung
select *
from orders
where
o_orderkey = 5019980134
Beim Filtern nach o_orderkey verhält es sich analog: Snowflake leitet die Ausführung um und scannt die andere Materialized View statt der Basistabelle orders.
Kostenaspekte geclusterter Materialized Views
Der wesentliche Nachteil von Materialized Views sind die zusätzlichen Kosten für deren Pflege. Drei Komponenten sind zu berücksichtigen:
- Speicherkosten für die neuen Datensätze
- Kosten für die verwalteten Refreshes jeder Materialized View. Damit Materialized Views nicht veralten, führt Snowflake im Hintergrund automatische Wartungsarbeiten durch. Ändert sich die Basistabelle, werden alle darauf definierten Materialized Views über einen Hintergrunddienst aktualisiert, der von Snowflake bereitgestellte Compute-Ressourcen nutzt.
- Kosten für das Automatic Clustering jeder Materialized View. Ist eine Materialized View anders geclustert als die Basistabelle, kann die Zahl der in der View geänderten Micro-Partitionen deutlich größer ausfallen als in der Basistabelle.
In einem späteren Beitrag liefern wir hierzu weitere Empfehlungen. Bis dahin raten wir, die Wartungskosten 3 und Automatic-Clustering-Kosten 4 Ihrer Materialized Views im Blick zu behalten. Die Speicherkosten lassen sich vorab anhand der Tabellengröße und Ihrer Speichertarife abschätzen 5.
Snowflake-Anwender sollten diese Zusatzkosten unbedingt im Auge behalten. Möglicherweise werden sie durch schnellere nachgelagerte Abfragen und entsprechend geringere Compute-Kosten vollständig kompensiert. Genauso gut können sie durch deutlich schnellere Abfragen klar gerechtfertigt sein. Ohne vorab die tatsächlichen Kosten zu berechnen, lässt sich diese Entscheidung jedoch nicht treffen.
Materialized View auf einer geclusterten Tabelle
Jede Änderung an Ihrer Basistabelle löst einen Refresh aller zugehörigen Materialized Views aus. Was passiert also, wenn Basistabelle und Materialized View nach unterschiedlichen Spalten geclustert sind?
- Neue Daten werden in die Basistabelle eingefügt
- Ein Refresh der Materialized View wird ausgelöst
- Snowflakes Automatic-Clustering-Dienst aktualisiert die Basistabelle, um deren Clustering zu verbessern
- Auch für die in Schritt 2 aktualisierte Materialized View kann Automatic Clustering anlaufen
- Sobald Schritt 3 abgeschlossen ist, kann dies die Schritte 2 und 4 für die Materialized View erneut anstoßen
Seien Sie also vorsichtig, wenn Sie eine Materialized View auf eine automatisch geclusterte Tabelle aufsetzen – die Wartungskosten dieser View steigen dadurch erheblich.
Materialized Views und DML-Operationen
Wichtig zu wissen: Performance-Vorteile durch Materialized Views erhalten Sie nur bei select-Abfragen. DML-Operationen wie update und delete profitieren nicht. Führen Sie zum Beispiel aus:
update orders
set o_clerk='new clerk'
where o_orderkey=5019980134
dann führt die Abfrage einen vollständigen Scan der Basistabelle orders durch und nutzt die Materialized View nicht.
Anmerkungen
- Beachten Sie, dass wir die Clustering-Spalten von der geringsten zur höchsten Kardinalität anordnen. Aus der Snowflake-Dokumentation zu mehrspaltigen Cluster Keys:
Wenn Sie einen mehrspaltigen Clustering Key für eine Tabelle definieren, ist die Reihenfolge der Spalten in der
CLUSTER BY-Klausel wichtig. Als Faustregel empfiehlt Snowflake, die Spalten von der niedrigsten zur höchsten Kardinalität anzuordnen. Steht eine Spalte mit höherer Kardinalität vor einer mit niedrigerer Kardinalität, mindert das in der Regel die Effektivität des Clusterings für letztere.
Die Kardinalität einer Spalte ist schlicht die Anzahl ihrer unterschiedlichen Werte. Sie lässt sich mit folgender Abfrage ermitteln:
select
count(*), -- 1,500,000,000
count(distinct o_orderdate), -- 2,406
count(distinct o_orderkey), -- 1,500,000,000
count(distinct o_custkey) -- 99,999,998
from public.orders
Daraus ergibt sich cluster by (o_orderdate, o_custkey, o_orderkey.
Materialized Views lassen sich nur ab der Enterprise Edition von Snowflake nutzen.
Die Kosten Ihrer Materialized-View-Refreshes können Sie mit folgender Abfrage überwachen:
select
date_trunc(day, start_time) as date,
table_name as materialized_view_name,
sum(credits_used) as num_credits_used
from snowflake.account_usage.materialized_view_refresh_history
group by 1,2
order by 1,2
- Die Kosten des Automatic Clusterings auf Ihrer Materialized View überwachen Sie mit folgender Abfrage:
select
date_trunc(day, automatic_clustering_history.start_time) as date,
automatic_clustering_history.database_name || '.' || automatic_clustering_history.schema_name || '.' || automatic_clustering_history.table_name as materialized_view_name,
sum(credits_used) as num_credits_used
from snowflake.account_usage.automatic_clustering_history
inner join snowflake.account_usage.tables
on automatic_clustering_history.table_id=tables.table_id
and tables.table_type='MATERIALIZED VIEW'
group by 1,2
order by 1,2
- Die meisten AWS-Kunden zahlen 23 $/TB/Monat. Bei einer Basistabelle von 10 TB kostet jede zusätzliche Materialized View also 2.760 $/Jahr (
10*23*12).
Ian Whitestone · Co-Founder & CEO von SELECT
Ian ist Co-Founder und CEO von SELECT, einer SaaS-Plattform für Kostenmanagement und -optimierung in Snowflake. Vor der Gründung von SELECT leitete er sechs Jahre lang Full-Stack-Data-Science- und Engineering-Teams bei Shopify und Capital One. Bei Shopify verantwortete er die Optimierung des Data Warehouse und steigerte die Kostentransparenz.
In diesem Beitrag haben wir gezeigt, wie sich mit Materialized Views mehrere Versionen einer Tabelle mit unterschiedlichen Cluster Keys anlegen lassen. Dieses Vorgehen kann die Abfrage-Performance dank besserem Pruning deutlich verbessern und sogar die Kosten der zugehörigen Virtual Warehouses senken. Wie immer in Snowflake müssen diese Vorteile sorgfältig gegen die zugrunde liegenden Kosten abgewogen werden.
In künftigen Beiträgen widmen wir uns wichtigen Themen wie der Bestimmung optimaler Cluster Keys für eine Tabelle, der Kostenschätzung des Automatic Clusterings für große Tabellen sowie dem Monitoring der Clustering-Gesundheit und der Umsetzung eines kosteneffizienteren Automatic Clusterings. Außerdem gehen wir tiefer darauf ein, wann es sinnvoll ist, mehrere Cluster Keys auf einer einzelnen Tabelle zu definieren.
Melden Sie sich wie immer gerne über Twitter oder per E-Mail – wir beantworten Ihre Fragen oder vertiefen diese Themen gerne mit Ihnen. Wenn Sie über neue Beiträge informiert werden möchten, abonnieren Sie unseren Snowflake-Newsletter am Ende dieser Seite.