No nosso post anterior sobre clustering no Snowflake, falamos sobre a importância de entender os padrões de uso de uma tabela na hora de decidir como fazer o clustering. Quando um campo aparece com frequência em cláusulas where, ele costuma ser um ótimo candidato a cluster key. Mas e se houver outros predicados where frequentes que também poderiam se beneficiar do clustering?
Neste post comparamos três opções: 1. Uma única tabela com cluster keys de várias colunas 2. Manter tabelas separadas, cada uma com clustering por uma coluna 3. Usar materialized views com clustering para tirar proveito do poderoso pruning automático do Snowflake
As limitações das cluster keys de várias colunas
Ao definir uma cluster key para uma tabela, o Snowflake permite usar mais de uma coluna. Suponha que temos uma tabela de pedidos com 1,5 bilhão de registros:
-- 1,500,000,000 records
create table orders as (
select
o_orderdate,
o_orderkey,
o_custkey,
o_clerk
from snowflake_sample_data.tpch_sf1000.orders
)
Um cenário comum é o seguinte: o time financeiro consulta regularmente intervalos de datas específicos dessa tabela para entender o volume de vendas. Os times de engenharia também consultam essa tabela para investigar pedidos específicos. E o marketing quer poder ver todo o histórico de pedidos de um determinado cliente.
São três padrões de acesso diferentes e, portanto, três colunas distintas pelas quais gostaríamos de fazer o clustering: o_orderdate, o_custkey e o_orderkey. Como mostra a documentação do Snowflake, dá para definir uma cluster key de várias colunas usando as três na expressão cluster by
1:
create table orders cluster by (o_orderdate, o_custkey, o_orderkey) as (
select
o_orderdate, -- 2,406 distinct values
o_orderkey, -- 1,500,000,000 distinct values
o_custkey, -- 99,999,998 distinct values
o_clerk
from snowflake_sample_data.tpch_sf1000.orders
)
Padrão de acesso 1: consulta por data
select
o_orderdate,
count(*) as cnt
from orders
where o_orderdate between '1993-03-01' and '1993-03-31'
group by 1
Ao rodar uma consulta sobre um intervalo de datas, dá para ver pelo query profile que o query pruning está excelente. Apenas 22 das 1.609 micro-partições são escaneadas.
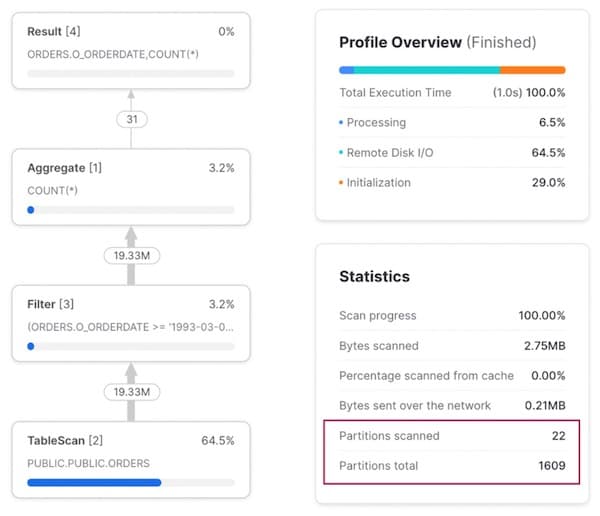
Padrão de acesso 2: consulta por um cliente específico
select *
from orders
where o_custkey = 52671775
Quando alteramos a consulta para buscar todos os pedidos de um cliente específico, o query pruning deixa de ser eficaz: 99% das micro-partições acabam sendo escaneadas.
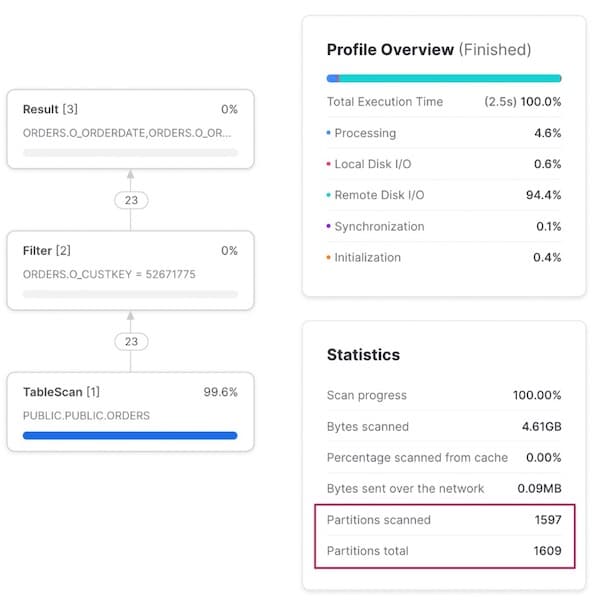
Padrão de acesso 3: consulta por um pedido específico
select *
from orders
where o_orderkey = 5019980134
Na busca por pedido, terceira coluna da nossa cluster key, não há pruning nenhum: todas as micro-partições são escaneadas para encontrar 1 único registro.
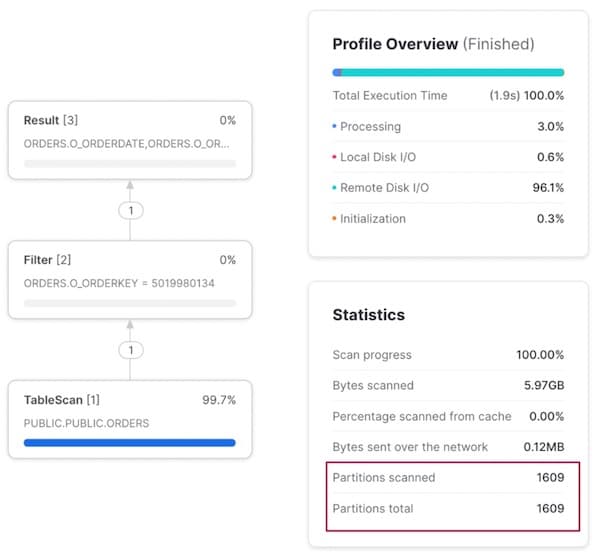
Entendendo a queda de desempenho das cluster keys de várias colunas
Como mostramos acima, o desempenho do query pruning cai bastante para predicados (filtros) sobre a segunda e a terceira colunas.
Para entender o porquê, é importante saber como funciona o clustering do Snowflake quando a cluster key tem várias colunas. O modelo mental mais simples é imaginar como você organizaria os dados em "caixas dentro de caixas". O Snowflake primeiro agrupa os dados por o_orderdate. Em seguida, dentro de cada caixa de "data", divide os dados por o_custkey. E, dentro de cada uma dessas caixas, divide novamente por o_orderkey.
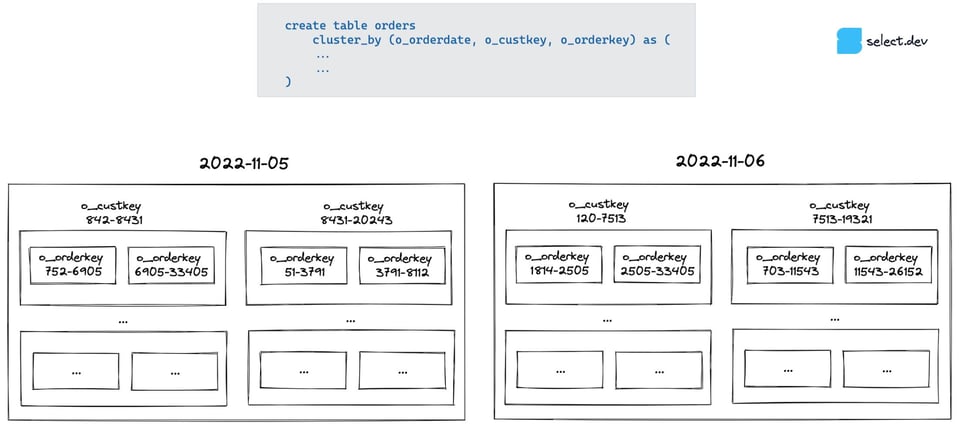
O query pruning do Snowflake funciona checando os metadados de mínimo/máximo da coluna em cada micro-partição. Quando consultamos por data, cada data tem sua própria caixa, então dá para descartar (fazer pruning) rapidamente as caixas irrelevantes. Já quando consultamos por cliente ou por order key, é preciso checar todas as caixas de data do nível superior, porque o intervalo mínimo/máximo dessas colunas é muito amplo (vários clientes fazem pedidos todo dia e as order keys são IDs aleatórios, que não crescem junto com a data do pedido). Resultado: não dá para descartar nenhuma caixa.
Criando várias cópias da mesma tabela com cluster keys diferentes
Como abordagem alternativa, poderíamos criar e manter uma tabela separada para cada cluster key:
create table orders_clustered_by_date cluster by (o_orderdate) as (
select
o_orderdate,
o_orderkey,
o_custkey,
o_clerk
from snowflake_sample_data.tpch_sf1000.orders
)
create table orders_clustered_by_customer cluster by (o_custkey) as (
select
o_orderdate,
o_orderkey,
o_custkey,
o_clerk
Expandir código
Essa abordagem tem desvantagens evidentes. Os usuários passam a ter de acompanhar três tabelas diferentes e lembrar qual delas usar em cada cenário de consulta. Pouco prático para uma tabela amplamente usada. Além disso, você ficaria responsável por manter as três cópias dessa tabela nos seus pipelines de ETL/ELT.
Será que existe um jeito melhor?
Materialized views com clustering: aproveitando o poderoso pruning automático do Snowflake
O que são materialized views?
Uma materialized view é um conjunto de dados pré-computado, derivado de uma especificação de consulta e armazenado para uso posterior
2. Vamos falar mais sobre os casos de uso em um próximo post, mas, por enquanto, vale a leitura da documentação do Snowflake, que cobre o assunto em detalhes. Quando você cria uma materialized view como a do exemplo abaixo, o Snowflake cuida da manutenção desse dataset derivado automaticamente. Sempre que os dados da tabela base (orders) são adicionados ou alterados, o Snowflake atualiza a materialized view por conta própria.
create materialized view orders_aggregated_by_date as (
select
o_orderdate,
count(*) as cnt
from orders
group by 1
)
Agora, se alguém rodar esta consulta na tabela base:
select
o_orderdate,
count(*) as cnt
from orders
group by 1
O Snowflake vai escanear automaticamente a materialized view pré-computada, em vez de recalcular o dataset inteiro.
Criando materialized views com clustering automático
As materialized views suportam clustering automático. Com isso, podemos criar duas novas materialized views que fazem o clustering da tabela orders separadamente por o_custkey e o_orderkey, para extrair o melhor desempenho:
-- these will take some time to execute, since the entire dataset is
-- being materialized (created) for the first time
create materialized view orders_clustered_by_customer cluster by(o_custkey) as (
select
o_orderdate,
o_orderkey,
o_custkey,
o_clerk
from orders
)
;
create materialized view orders_clustered_by_order cluster by(o_orderkey) as (
select
o_orderdate,
Expandir código
Tecnicamente, poderíamos criar uma terceira materialized view com clustering por o_orderdate. Mas, em vez disso, vamos adotar a alternativa mais econômica de aplicar ordenação manual na tabela base de pedidos:
create table orders as (
select
o_orderdate,
o_orderkey,
o_custkey,
o_clerk
from snowflake_sample_data.tpch_sf1000.orders
-- sort and therefore cluster the table by o_orderdate
order by o_orderdate
)
Testando de novo os três padrões de acesso
Padrão de acesso 1: consulta por data
select
o_orderdate,
count(*) as cnt
from orders
where
o_orderdate between date'1993-03-01' and date'1993-03-31'
group by 1
Quando rodamos uma consulta com filtro em o_orderdate, a tabela base orders original é usada, já que ela está naturalmente clusterizada por essa coluna.
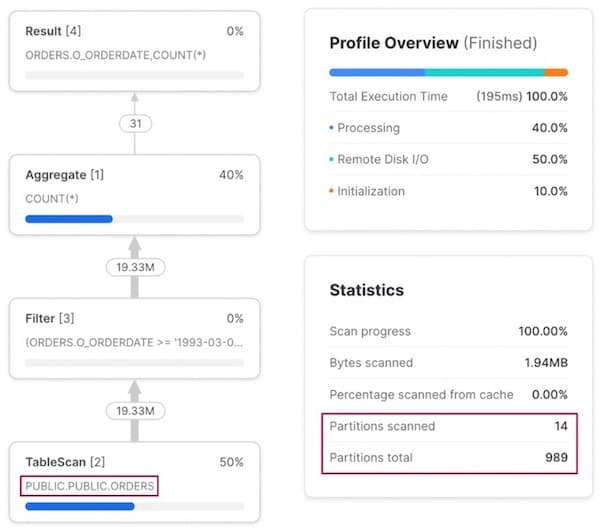
Padrão de acesso 2: consulta por cliente
select *
from orders
where
o_custkey=52671775
Quando filtramos por o_custkey, o otimizador do Snowflake percebe que existe uma materialized view clusterizada por essa coluna e, de forma inteligente, direciona o plano de execução para ler da materialized view.
Repare que não precisamos reescrever a consulta para dizer ao Snowflake que ele deve usar a materialized view — isso acontece nos bastidores. Os usuários não precisam decorar qual dataset consultar em cada cenário!
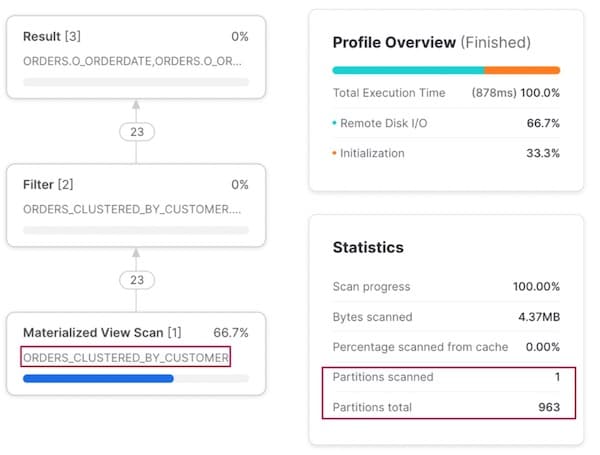
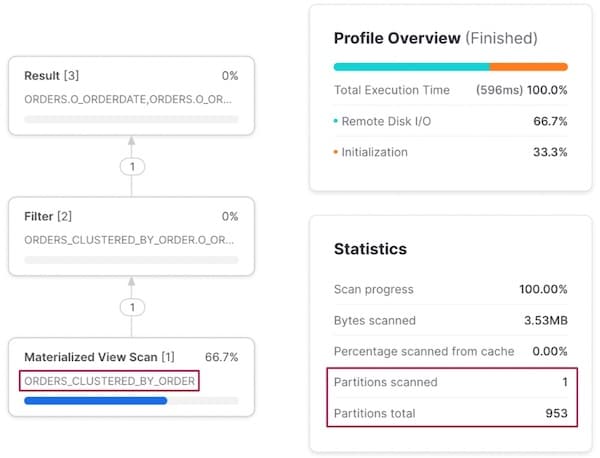
Padrão de acesso 3: consulta por pedido
select *
from orders
where
o_orderkey = 5019980134
O filtro em o_orderkey tem comportamento parecido: o Snowflake "redireciona" a execução para escanear a outra materialized view, em vez da tabela base orders.
Considerações de custo de materialized views com clustering
A principal desvantagem das materialized views é o custo extra para mantê-las. São três componentes a considerar:
- Custos de armazenamento dos novos datasets
- Cobranças pelas atualizações gerenciadas de cada materialized view. Para que as materialized views não fiquem desatualizadas, o Snowflake executa manutenção automática em background. Quando a tabela base muda, todas as materialized views definidas sobre ela são atualizadas por um serviço em background que usa recursos de computação fornecidos pelo Snowflake.
- Cobranças pelo clustering automático em cada materialized view. Se uma materialized view está clusterizada de forma diferente da tabela base, o número de micro-partições alteradas na materialized view pode ser bem maior do que o número de micro-partições alteradas na tabela base.
Vamos dar mais orientações sobre isso em um próximo post, mas, por ora, recomendamos monitorar os custos de manutenção 3 e os custos de clustering automático 4 das suas materialized views. Os custos de armazenamento dá para estimar previamente, a partir do tamanho da tabela e do seu custo de storage 5.
É fundamental que os usuários do Snowflake levem esses custos adicionais em conta. Pode ser que eles sejam totalmente compensados por consultas downstream mais rápidas e, com isso, por custos de computação menores. Também pode ser que o custo se justifique pelo ganho expressivo em tempo de resposta. Só que é impossível tomar essa decisão sem antes calcular os custos reais.
Materialized view sobre uma tabela com clustering
Toda atualização na tabela base dispara um refresh de todas as materialized views associadas. E o que acontece quando tanto a tabela base quanto a materialized view estão clusterizadas em colunas diferentes?
- Novos dados são adicionados à tabela base
- Um refresh da materialized view é disparado
- O serviço de clustering automático do Snowflake atualiza a tabela base para melhorar seu clustering
- O clustering automático também pode entrar em ação para a materialized view atualizada no passo 2
- Quando o passo 3 termina, isso pode disparar de novo os passos 2 e 4 para a materialized view
Tenha bastante cuidado ao colocar uma materialized view sobre uma tabela com clustering automático, porque isso aumenta significativamente os custos de manutenção dessa materialized view.
Materialized views e operações DML
Vale destacar que os ganhos de desempenho das materialized views só aparecem em consultas do tipo select. Operações DML, como updates e deletes, não se beneficiam. Por exemplo, se você executar:
update orders
set o_clerk='new clerk'
where o_orderkey=5019980134
A consulta vai fazer um full table scan na tabela base orders e não vai usar a materialized view.
Notas
- Repare como ordenamos as cluster keys da menor para a maior cardinalidade? Da documentação do Snowflake sobre cluster keys de várias colunas:
Ao definir uma cluster key de várias colunas para uma tabela, a ordem em que as colunas aparecem na cláusula
CLUSTER BYé importante. Como regra geral, o Snowflake recomenda ordenar as colunas da menor para a maior cardinalidade. Colocar uma coluna de cardinalidade maior antes de uma de cardinalidade menor costuma reduzir a eficácia do clustering nessa última coluna.
A cardinalidade de uma coluna nada mais é do que o número de valores distintos. Para descobrir, basta rodar uma consulta:
select
count(*), -- 1,500,000,000
count(distinct o_orderdate), -- 2,406
count(distinct o_orderkey), -- 1,500,000,000
count(distinct o_custkey) -- 99,999,998
from public.orders
Por isso, usamos cluster by (o_orderdate, o_custkey, o_orderkey.
Só dá para usar materialized views se você estiver na edição enterprise (ou superior) do Snowflake.
Você pode monitorar o custo dos refreshes das suas materialized views com a consulta a seguir:
select
date_trunc(day, start_time) as date,
table_name as materialized_view_name,
sum(credits_used) as num_credits_used
from snowflake.account_usage.materialized_view_refresh_history
group by 1,2
order by 1,2
- Você pode monitorar o custo do clustering automático na sua materialized view com a consulta a seguir:
select
date_trunc(day, automatic_clustering_history.start_time) as date,
automatic_clustering_history.database_name || '.' || automatic_clustering_history.schema_name || '.' || automatic_clustering_history.table_name as materialized_view_name,
sum(credits_used) as num_credits_used
from snowflake.account_usage.automatic_clustering_history
inner join snowflake.account_usage.tables
on automatic_clustering_history.table_id=tables.table_id
and tables.table_type='MATERIALIZED VIEW'
group by 1,2
order by 1,2
- A maioria dos clientes na AWS paga US$ 23/TB/mês. Então, se a sua tabela base tem 10 TB, cada materialized view adicional vai custar US$ 2.760/ano (
10*23*12).
Ian Whitestone·Co-founder & CEO da SELECT
Ian é Co-founder & CEO da SELECT, uma plataforma SaaS de gestão e otimização de custos do Snowflake. Antes de fundar a SELECT, Ian passou 6 anos liderando times full stack de data science e engenharia na Shopify e na Capital One. Na Shopify, ele esteve à frente dos esforços para otimizar o data warehouse e ampliar a observabilidade de custos.
Neste post, mostramos como as materialized views podem ser usadas para criar várias versões de uma tabela com cluster keys diferentes. Essa prática pode melhorar bastante o desempenho das consultas, graças a um pruning melhor, e até reduzir os custos de virtual warehouse associados a elas. Como tudo no Snowflake, esses benefícios precisam ser cuidadosamente avaliados em relação aos custos envolvidos.
Nos próximos posts, vamos explorar temas importantes, como definir as cluster keys ideais para a sua tabela, estimar os custos de clustering automático em uma tabela grande, monitorar a saúde do clustering e implementar um clustering automático mais econômico. Também vamos nos aprofundar em quando faz sentido definir várias cluster keys em uma única tabela.
Como sempre, fique à vontade para entrar em contato pelo Twitter ou por email. Vamos adorar tirar dúvidas ou discutir esses temas com mais profundidade. E, se quiser ser avisado quando publicarmos um novo post, assine a nossa newsletter sobre Snowflake no rodapé desta página.