Nel precedente articolo sul clustering in Snowflake abbiamo sottolineato quanto sia importante conoscere i pattern di utilizzo di una tabella prima di scegliere come effettuarne il clustering. Se un determinato campo compare spesso nelle clausole where, è un ottimo candidato come cluster key. Ma cosa fare quando anche altri predicati where ricorrenti trarrebbero beneficio dal clustering?
In questo articolo mettiamo a confronto tre opzioni: 1. Una singola tabella con cluster key multi-colonna 2. Più tabelle separate, ciascuna con clustering su una colonna diversa 3. Viste materializzate con clustering, per sfruttare la potente funzionalità di pruning automatico di Snowflake
I limiti delle cluster key multi-colonna
Quando si definisce una cluster key per una singola tabella, Snowflake permette di utilizzare più di una colonna. Supponiamo di avere una tabella orders con 1,5 miliardi di record:
-- 1,500,000,000 records
create table orders as (
select
o_orderdate,
o_orderkey,
o_custkey,
o_clerk
from snowflake_sample_data.tpch_sf1000.orders
)
Lo scenario tipico è questo. Il team finance interroga regolarmente intervalli di date specifici per analizzare il volume di vendite. I team di engineering, dal canto loro, consultano la stessa tabella per indagare su ordini specifici. In più, il marketing vuole poter vedere tutti gli ordini storici di un determinato cliente.
Abbiamo quindi tre pattern di accesso diversi e, di conseguenza, tre colonne diverse su cui vorremmo effettuare il clustering: o_orderdate, o_custkey e o_orderkey. Come illustrato nella documentazione di Snowflake, possiamo definire una cluster key multi-colonna usando tutte e tre le colonne nell'espressione cluster by
1:
create table orders cluster by (o_orderdate, o_custkey, o_orderkey) as (
select
o_orderdate, -- 2,406 distinct values
o_orderkey, -- 1,500,000,000 distinct values
o_custkey, -- 99,999,998 distinct values
o_clerk
from snowflake_sample_data.tpch_sf1000.orders
)
Pattern di accesso 1: query per data
select
o_orderdate,
count(*) as cnt
from orders
where o_orderdate between '1993-03-01' and '1993-03-31'
group by 1
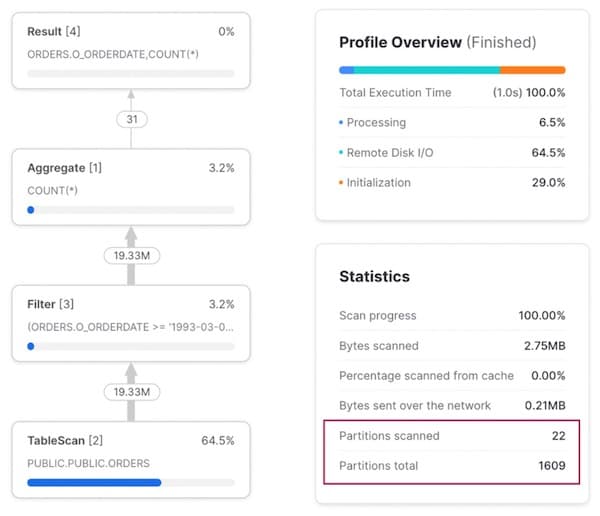
Eseguendo una query su un intervallo di date, dal query profile si vede che il pruning funziona benissimo: vengono scansionate solo 22 micro-partizioni su 1.609.
Pattern di accesso 2: query per un cliente specifico
select *
from orders
where o_custkey = 52671775
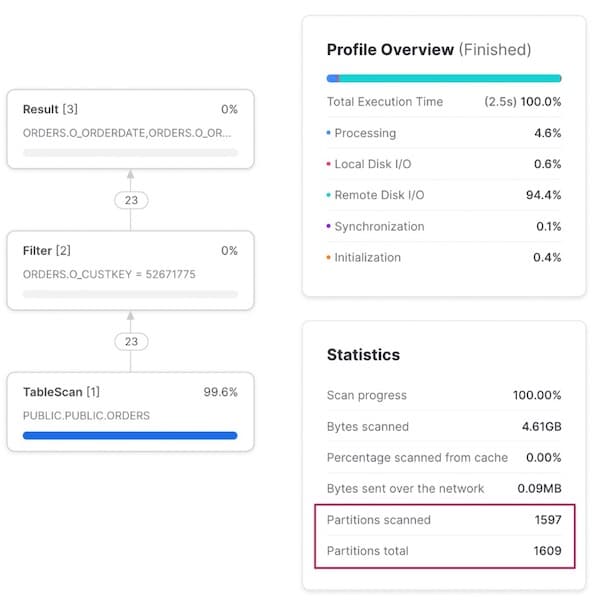
Se invece cerchiamo tutti gli ordini di un determinato cliente, il pruning diventa inefficace: viene scansionato il 99% delle micro-partizioni.
Pattern di accesso 3: query per un ordine specifico
select *
from orders
where o_orderkey = 5019980134
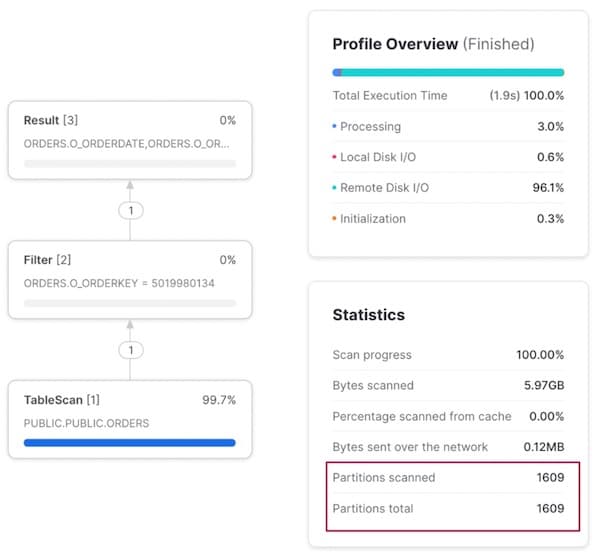
Per la ricerca sull'ordine — la terza colonna della cluster key — non si ha alcun pruning: vengono scansionate tutte le micro-partizioni per trovare un solo record.
Perché le cluster key multi-colonna peggiorano le performance
Come visto sopra, le performance di pruning peggiorano sensibilmente per i predicati (filtri) sulla seconda e sulla terza colonna.
Per capirne il motivo, bisogna sapere come funziona il clustering di Snowflake con cluster key multi-colonna. Il modello mentale più semplice è immaginare i dati organizzati in "scatole dentro scatole". Snowflake raggruppa i dati prima per o_orderdate. All'interno di ogni scatola "data", li suddivide poi per o_custkey. E in ognuna di queste sotto-scatole li suddivide ulteriormente per o_orderkey.
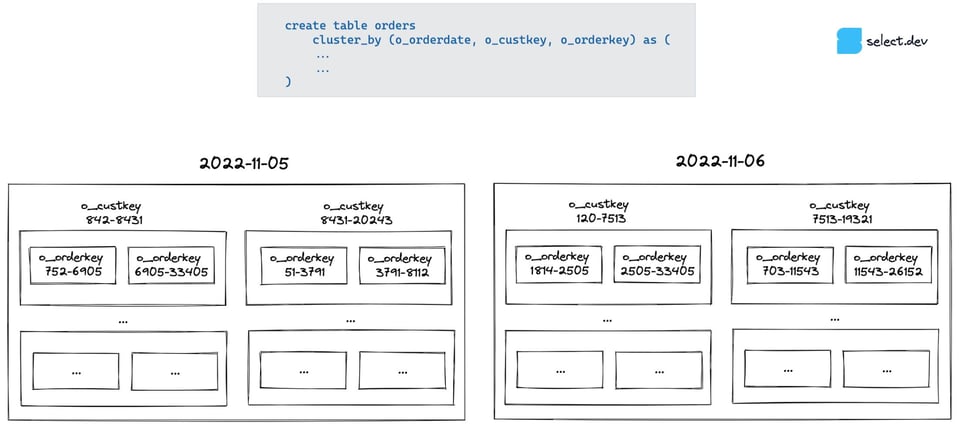
Il pruning di Snowflake si basa sul controllo dei metadati min/max della colonna in ciascuna micro-partizione. Quando si filtra per data, ogni data ha la propria scatola dedicata, quindi è facile scartare (eseguire pruning su) quelle non pertinenti. Quando invece si filtra per cliente o per chiave d'ordine, bisogna controllare tutte le scatole di primo livello (per data), perché il valore min/max di queste colonne copre un intervallo molto ampio (ogni giorno ordinano clienti diversi e le chiavi d'ordine sono ID casuali, non crescenti con la data dell'ordine): non è quindi possibile escludere nessuna scatola.
Creare più copie della stessa tabella con cluster key diverse
Un approccio alternativo è creare e mantenere una tabella separata per ciascuna cluster key:
create table orders_clustered_by_date cluster by (o_orderdate) as (
select
o_orderdate,
o_orderkey,
o_custkey,
o_clerk
from snowflake_sample_data.tpch_sf1000.orders
)
create table orders_clustered_by_customer cluster by (o_custkey) as (
select
o_orderdate,
o_orderkey,
o_custkey,
o_clerk
Espandi codice
Questa soluzione ha svantaggi evidenti. Gli utenti devono tenere a mente tre tabelle diverse e ricordare quale usare in ciascuno scenario di query: poco pratico per una tabella ampiamente utilizzata. Inoltre, ricade su di te la manutenzione delle tre copie all'interno delle pipeline ETL/ELT.
C'è forse un approccio migliore?
Viste materializzate con clustering: il pruning automatico di Snowflake al massimo delle sue potenzialità
Cosa sono le viste materializzate?
Una vista materializzata è un set di dati pre-calcolato, derivato da una specifica di query e memorizzato per un uso successivo
2. Approfondiremo i casi d'uso in un prossimo articolo; per ora puoi consultare la documentazione di Snowflake, che li tratta in modo molto dettagliato. Quando crei una vista materializzata come quella qui sotto, Snowflake mantiene automaticamente per te il dataset derivato. Ogni volta che i dati della tabella di base (orders) vengono aggiunti o modificati, Snowflake aggiorna automaticamente la vista materializzata.
create materialized view orders_aggregated_by_date as (
select
o_orderdate,
count(*) as cnt
from orders
group by 1
)
Ora, se qualcuno lancia questa query sulla tabella di base:
select
o_orderdate,
count(*) as cnt
from orders
group by 1
Snowflake eseguirà automaticamente la scansione della vista materializzata pre-calcolata, invece di ricalcolare l'intero dataset.
Creare viste materializzate con clustering automatico
Le viste materializzate supportano il clustering automatico. Sfruttando questa funzionalità, possiamo creare due nuove viste materializzate che effettuano separatamente il clustering della tabella orders su o_custkey e o_orderkey, ottenendo performance ottimali:
-- these will take some time to execute, since the entire dataset is
-- being materialized (created) for the first time
create materialized view orders_clustered_by_customer cluster by(o_custkey) as (
select
o_orderdate,
o_orderkey,
o_custkey,
o_clerk
from orders
)
;
create materialized view orders_clustered_by_order cluster by(o_orderkey) as (
select
o_orderdate,
Espandi codice
In teoria, potremmo creare anche una terza vista materializzata con clustering su o_orderdate. Scegliamo però l'approccio più conveniente in termini di costi, sfruttando l'ordinamento manuale sulla tabella orders di base:
create table orders as (
select
o_orderdate,
o_orderkey,
o_custkey,
o_clerk
from snowflake_sample_data.tpch_sf1000.orders
-- sort and therefore cluster the table by o_orderdate
order by o_orderdate
)
Rimettiamo alla prova i tre pattern di accesso
Pattern di accesso 1: query per data
select
o_orderdate,
count(*) as cnt
from orders
where
o_orderdate between date'1993-03-01' and date'1993-03-31'
group by 1
Con un filtro su o_orderdate, viene utilizzata la tabella orders di base originale, dato che è già naturalmente clusterizzata su questa colonna.
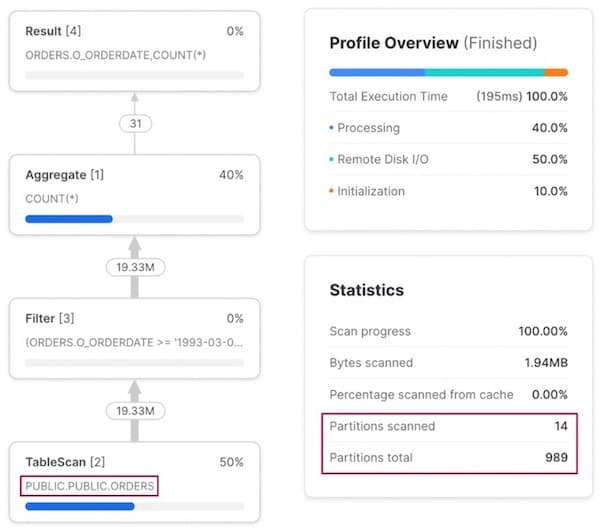
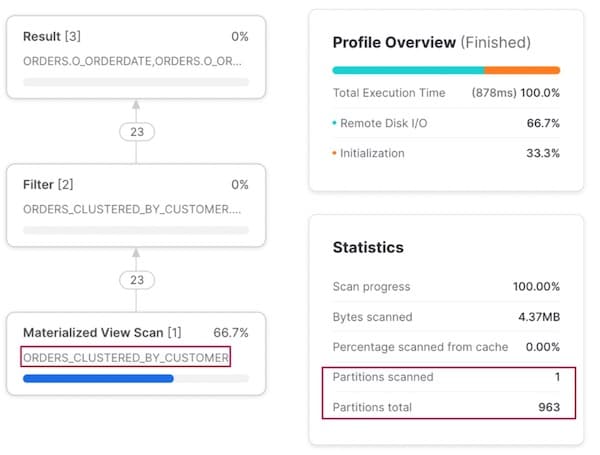
Pattern di accesso 2: query per cliente
select *
from orders
where
o_custkey=52671775
Filtrando invece per o_custkey, l'ottimizzatore di Snowflake rileva l'esistenza di una vista materializzata con clustering su questa colonna e indirizza in modo intelligente il piano di esecuzione affinché legga dalla vista materializzata.
Notare che non serve riscrivere la query per dire esplicitamente a Snowflake di interrogare la vista materializzata: lo fa in modo trasparente. Gli utenti non devono ricordare quale dataset interrogare nei diversi scenari!
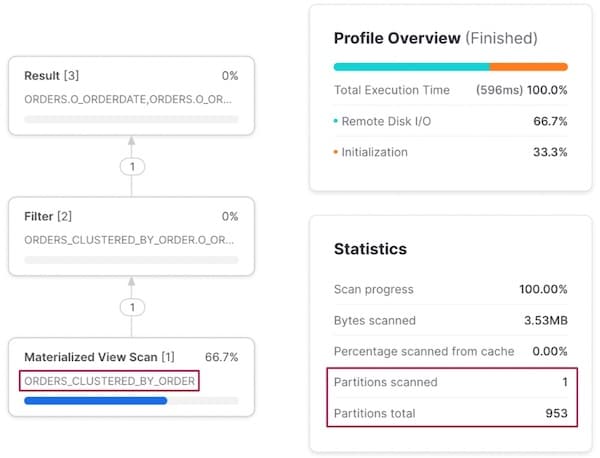
Pattern di accesso 3: query per ordine
select *
from orders
where
o_orderkey = 5019980134
Con un filtro su o_orderkey il comportamento è analogo: Snowflake "reindirizza" l'esecuzione della query verso l'altra vista materializzata, invece che sulla tabella orders di base.
Considerazioni sui costi delle viste materializzate con clustering
Il principale svantaggio delle viste materializzate è il costo aggiuntivo legato al loro mantenimento. Le componenti da considerare sono tre:
- I costi di storage associati ai nuovi dataset.
- I costi dei refresh gestiti di ciascuna vista materializzata. Per evitare che le viste materializzate diventino obsolete, Snowflake esegue una manutenzione automatica in background. Quando la tabella di base cambia, tutte le viste materializzate definite su di essa vengono aggiornate da un servizio in background che utilizza risorse di compute fornite da Snowflake.
- I costi del clustering automatico di ciascuna vista materializzata. Se la vista materializzata ha un clustering diverso da quello della tabella di base, il numero di micro-partizioni modificate nella vista può essere nettamente superiore al numero di micro-partizioni modificate nella tabella di base.
Daremo indicazioni più dettagliate in un prossimo articolo; per ora consigliamo di monitorare i costi di manutenzione 3 e i costi del clustering automatico 4 associati alle viste materializzate. I costi di storage si possono stimare a priori, partendo dalla dimensione della tabella e dalle proprie tariffe di storage 5.
È fondamentale che gli utenti Snowflake tengano conto di questi costi aggiuntivi. Potrebbero essere interamente compensati da query downstream più veloci e quindi da minori costi di compute. Oppure potrebbero essere pienamente giustificati dal fatto di abilitare query molto più rapide. Ma è impossibile decidere senza prima calcolare i costi reali.
Viste materializzate su una tabella con clustering
Ogni aggiornamento della tabella di base attiva un refresh di tutte le viste materializzate associate. Cosa succede, allora, se sia la tabella di base sia la vista materializzata hanno il clustering su colonne diverse?
- Vengono aggiunti nuovi dati alla tabella di base.
- Si attiva un refresh della vista materializzata.
- Il servizio di clustering automatico di Snowflake aggiorna la tabella di base per migliorarne il clustering.
- Il clustering automatico può scattare anche per la vista materializzata aggiornata al punto 2.
- Una volta completato il punto 3, si possono riattivare i punti 2 e 4 per la vista materializzata.
Presta molta attenzione quando aggiungi una vista materializzata sopra una tabella con clustering automatico, perché ne aumenterà sensibilmente i costi di manutenzione.
Viste materializzate e operazioni DML
È importante ricordare che i benefici prestazionali delle viste materializzate valgono solo per le query di tipo select. Le operazioni DML come update e delete non ne traggono vantaggio. Ad esempio, se esegui:
update orders
set o_clerk='new clerk'
where o_orderkey=5019980134
La query effettuerà una scansione completa della tabella orders di base e non utilizzerà la vista materializzata.
Note
- Hai notato che abbiamo ordinato le colonne di clustering dalla cardinalità più bassa a quella più alta? Dalla documentazione di Snowflake sulle cluster key multi-colonna:
Se stai definendo una clustering key multi-colonna per una tabella, l'ordine in cui le colonne compaiono nella clausola
CLUSTER BYè importante. Come regola generale, Snowflake consiglia di ordinare le colonne dalla cardinalità più bassa alla più alta. Mettere una colonna ad alta cardinalità prima di una a cardinalità più bassa riduce di norma l'efficacia del clustering sulla seconda colonna.
La cardinalità di una colonna è semplicemente il numero di valori distinti. La si può ottenere con una query:
select
count(*), -- 1,500,000,000
count(distinct o_orderdate), -- 2,406
count(distinct o_orderkey), -- 1,500,000,000
count(distinct o_custkey) -- 99,999,998
from public.orders
Di conseguenza, abbiamo scelto cluster by (o_orderdate, o_custkey, o_orderkey.
Le viste materializzate sono disponibili solo nell'edizione enterprise (o superiore) di Snowflake.
Puoi monitorare il costo dei refresh delle viste materializzate con questa query:
select
date_trunc(day, start_time) as date,
table_name as materialized_view_name,
sum(credits_used) as num_credits_used
from snowflake.account_usage.materialized_view_refresh_history
group by 1,2
order by 1,2
- Puoi monitorare il costo del clustering automatico sulla vista materializzata con questa query:
select
date_trunc(day, automatic_clustering_history.start_time) as date,
automatic_clustering_history.database_name || '.' || automatic_clustering_history.schema_name || '.' || automatic_clustering_history.table_name as materialized_view_name,
sum(credits_used) as num_credits_used
from snowflake.account_usage.automatic_clustering_history
inner join snowflake.account_usage.tables
on automatic_clustering_history.table_id=tables.table_id
and tables.table_type='MATERIALIZED VIEW'
group by 1,2
order by 1,2
- La maggior parte dei clienti su AWS paga 23 $/TB/mese. Quindi, se la tabella di base è di 10 TB, ogni vista materializzata aggiuntiva costerà 2.760 $/anno (
10*23*12).
Ian Whitestone·Co-founder & CEO di SELECT
Ian è Co-founder e CEO di SELECT, una piattaforma SaaS per la gestione e l'ottimizzazione dei costi di Snowflake. Prima di fondare SELECT, per 6 anni ha guidato team full stack di data science ed engineering in Shopify e Capital One. In Shopify ha guidato i progetti di ottimizzazione del data warehouse e di miglioramento dell'osservabilità dei costi.
In questo articolo abbiamo mostrato come sfruttare le viste materializzate per creare più versioni di una stessa tabella con cluster key diverse. Questa pratica può migliorare sensibilmente le performance delle query grazie a un pruning più efficace, e ridurre persino i costi di virtual warehouse associati. Come sempre in Snowflake, questi benefici vanno però valutati con attenzione rispetto ai costi sottostanti.
Nei prossimi articoli affronteremo temi importanti come: come individuare le cluster key ottimali per una tabella, come stimare i costi del clustering automatico su una tabella di grandi dimensioni, e come monitorare lo stato del clustering implementando una strategia di clustering automatico più conveniente. Approfondiremo inoltre la definizione di più cluster key su una singola tabella e i casi in cui ha davvero senso farlo.
Come sempre, non esitare a contattarci su Twitter o via email: saremo felici di rispondere alle tue domande o di approfondire questi argomenti. Se vuoi ricevere una notifica alla pubblicazione di un nuovo articolo, iscriviti alla nostra newsletter su Snowflake in fondo alla pagina.