前回のSnowflakeのクラスタリングに関する記事では、テーブルのクラスタリング方法を決めるうえで、テーブルの利用パターンを把握することがいかに重要かを解説しました。あるフィールドが where 句で頻繁に使われているなら、それはクラスターキーの有力な候補になります。では、クラスタリングの恩恵を受けられそうな where 述語が他にも複数ある場合は、どうすればよいのでしょうか。
本記事では、次の3つの選択肢を比較します。1. 複数列クラスターキーを設定した単一テーブル 2. 列ごとにクラスタリングした個別テーブルを保守する方法 3. クラスタリング済みのマテリアライズドビューを用いて、Snowflake の強力な自動プルーニング機能を活用する方法
複数列クラスターキーの限界
単一テーブルにクラスターキーを定義する際、Snowflakeでは複数の列を指定できます。15億件のレコードを持つ orders テーブルがあるとしましょう。
-- 1,500,000,000 records
create table orders as (
select
o_orderdate,
o_orderkey,
o_custkey,
o_clerk
from snowflake_sample_data.tpch_sf1000.orders
)
よくあるシナリオは次のようなものです。財務チームは売上規模を把握するために、このテーブルに対して特定の日付範囲で定期的にクエリを実行します。エンジニアリングチームは個別の注文を調査するためにこのテーブルを参照します。さらにマーケティングチームは、特定の顧客の全注文履歴を確認したいと考えています。
つまりアクセスパターンは3種類あり、結果としてクラスタリングしたい列も o_orderdate、o_custkey、o_orderkey の3つになります。Snowflake のドキュメントにあるとおり、cluster by 式に3列すべてを指定して複数列クラスターキーを定義できます
1。
create table orders cluster by (o_orderdate, o_custkey, o_orderkey) as (
select
o_orderdate, -- 2,406 distinct values
o_orderkey, -- 1,500,000,000 distinct values
o_custkey, -- 99,999,998 distinct values
o_clerk
from snowflake_sample_data.tpch_sf1000.orders
)
アクセスパターン 1: 日付で検索
select
o_orderdate,
count(*) as cnt
from orders
where o_orderdate between '1993-03-01' and '1993-03-31'
group by 1
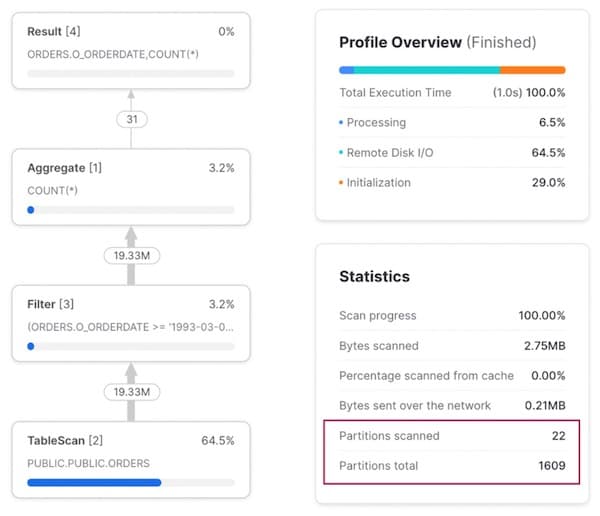
日付範囲を指定したクエリを実行すると、クエリプロファイルからクエリプルーニングが極めて効果的に機能していることが分かります。1,609個のマイクロパーティションのうち、スキャンされたのはわずか22個でした。
アクセスパターン 2: 特定の顧客で検索
select *
from orders
where o_custkey = 52671775
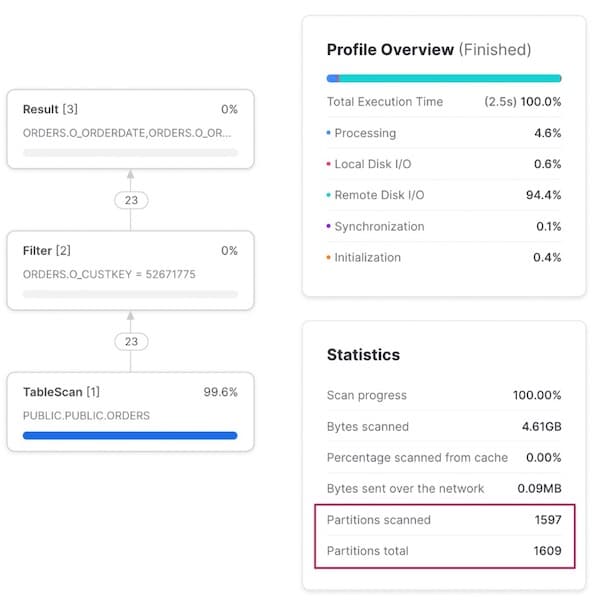
クエリを変更して特定の顧客の注文をすべて検索しようとすると、プルーニングはほとんど効かず、マイクロパーティション全体の99%がスキャンされてしまいます。
アクセスパターン 3: 特定の注文で検索
select *
from orders
where o_orderkey = 5019980134
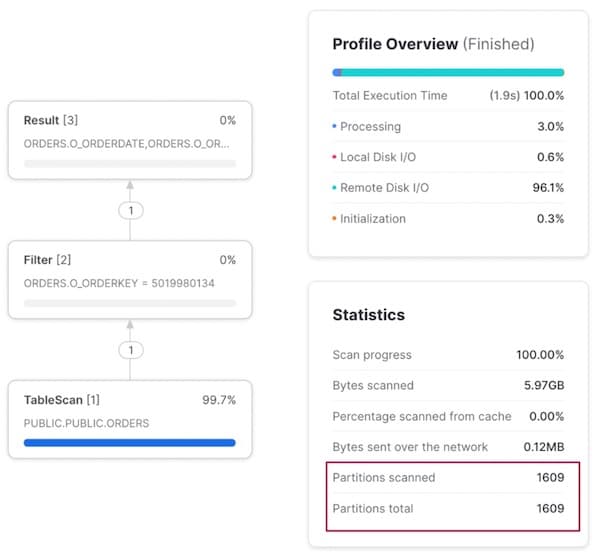
クラスターキーの3列目にあたる注文キーで検索する場合、プルーニングはまったく効かず、1件のレコードを見つけるためにすべてのマイクロパーティションがスキャンされます。
複数列クラスターキーで性能が落ちる理由
ここまで見てきたように、2列目・3列目の列に対する述語(フィルター)では、プルーニング性能が大きく低下します。
その理由を理解するには、Snowflake の複数列クラスターキーの仕組みを押さえておく必要があります。最もシンプルなイメージは、データを「箱の中の箱」として整理する考え方です。Snowflake はまずデータを o_orderdate でまとめます。次に、それぞれの「日付」の箱の中を o_custkey で分け、さらにその箱の中を o_orderkey で分割していきます。
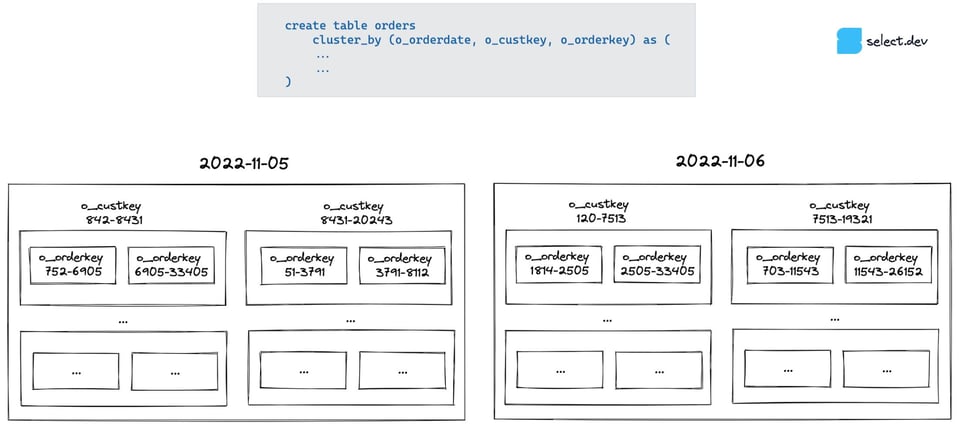
Snowflake のクエリプルーニングは、各マイクロパーティションが保持する列の最小値・最大値メタデータを参照することで機能します。日付で検索する場合は日付ごとに専用の箱があるため、関係のない箱をすばやく除外(プルーニング)できます。一方、顧客や注文キーで検索する場合、これらの列の最小値・最大値の範囲は非常に広く(同じ日に多数の異なる顧客が注文しており、注文キーはランダムなIDで注文日に応じて昇順になっているわけでもない)、すべての最上位「日付の箱」を確認せざるを得ず、結果としてどの箱も除外できません。
クラスターキー別に同じテーブルの複製を作る
代替案として、クラスターキーごとに別々のテーブルを作成・保守する方法もあります。
create table orders_clustered_by_date cluster by (o_orderdate) as (
select
o_orderdate,
o_orderkey,
o_custkey,
o_clerk
from snowflake_sample_data.tpch_sf1000.orders
)
create table orders_clustered_by_customer cluster by (o_custkey) as (
select
o_orderdate,
o_orderkey,
o_custkey,
o_clerk
Expand Code
この方法には明らかな欠点があります。ユーザーは3つのテーブルを把握し、どのクエリパターンでどのテーブルを使うべきかを常に意識しなければなりません。広く使われているテーブルでは現実的ではないでしょう。さらに、ETL/ELT パイプラインの中で、同じテーブルの3つのコピーを並行して保守する必要も出てきます。
もっとよい方法はないのでしょうか。
クラスタリング済みマテリアライズドビューで Snowflake の自動プルーニング最適化を活かす
マテリアライズドビューとは
マテリアライズドビューとは、クエリ定義から導出した結果セットをあらかじめ計算し、後から利用できるように保存しておくものです
2。具体的なユースケースは別記事で取り上げますが、現時点では詳しく解説されたSnowflake のドキュメントを参照してください。次のようなマテリアライズドビューを作成すると、Snowflake がその派生データセットを自動で管理します。ベーステーブル(orders)にデータが追加・変更されると、Snowflake がマテリアライズドビューを自動的に更新します。
create materialized view orders_aggregated_by_date as (
select
o_orderdate,
count(*) as cnt
from orders
group by 1
)
これで、誰かがベーステーブルに対して次のクエリを実行した場合でも、
select
o_orderdate,
count(*) as cnt
from orders
group by 1
Snowflake はデータセット全体を再計算せず、事前計算済みのマテリアライズドビューを自動的にスキャンします。
自動クラスタリングされたマテリアライズドビューを作る
マテリアライズドビューは自動クラスタリングに対応しています。これを利用して、orders テーブルを o_custkey と o_orderkey でそれぞれ個別にクラスタリングする2つの新しいマテリアライズドビューを作成し、最適なパフォーマンスを実現できます。
-- these will take some time to execute, since the entire dataset is
-- being materialized (created) for the first time
create materialized view orders_clustered_by_customer cluster by(o_custkey) as (
select
o_orderdate,
o_orderkey,
o_custkey,
o_clerk
from orders
)
;
create materialized view orders_clustered_by_order cluster by(o_orderkey) as (
select
o_orderdate,
Expand Code
厳密には o_orderdate でクラスタリングした3つ目のマテリアライズドビューも作成可能ですが、ここではよりコスト効率のよい方法として、ベースの orders テーブルで手動ソートを活用します。
create table orders as (
select
o_orderdate,
o_orderkey,
o_custkey,
o_clerk
from snowflake_sample_data.tpch_sf1000.orders
-- sort and therefore cluster the table by o_orderdate
order by o_orderdate
)
3つのアクセスパターンを再検証する
アクセスパターン 1: 日付で検索
select
o_orderdate,
count(*) as cnt
from orders
where
o_orderdate between date'1993-03-01' and date'1993-03-31'
group by 1
o_orderdate でフィルターをかけたクエリを実行すると、ベースの orders テーブル自体がこの列で自然にクラスタリングされているため、そのまま参照されます。
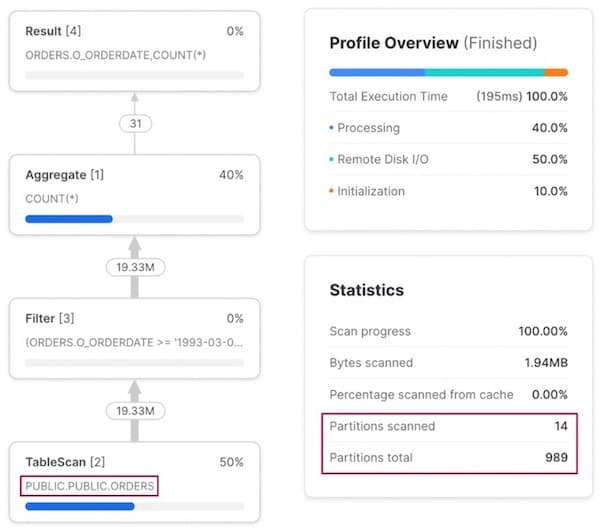
アクセスパターン 2: 顧客で検索
select *
from orders
where
o_custkey=52671775
一方、o_custkey でフィルターをかけると、Snowflake のオプティマイザはこの列でクラスタリングされたマテリアライズドビューが存在することを認識し、実行プランがそのマテリアライズドビューから読み込むよう適切に判断します。
マテリアライズドビューを参照させるためにクエリを書き換える必要はなく、Snowflake が内部で自動的に処理してくれます。ユーザーはシナリオごとにどのデータセットを参照すべきかを覚えておく必要がありません。
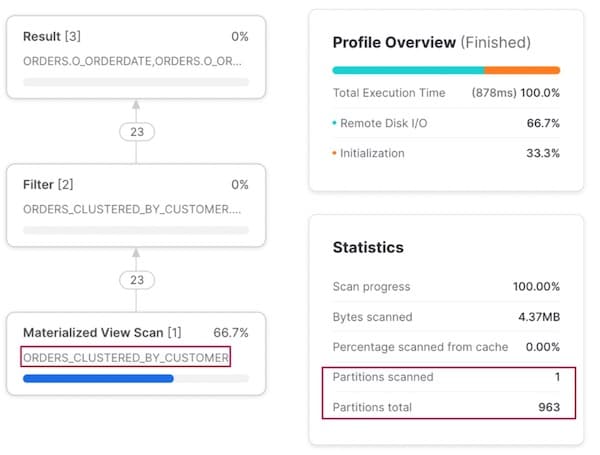
アクセスパターン 3: 注文で検索
select *
from orders
where
o_orderkey = 5019980134
o_orderkey でのフィルタリングでも同様の挙動となり、Snowflake はクエリ実行をベースの orders テーブルではなく、もう一方のマテリアライズドビューへと「振り向け」てくれます。
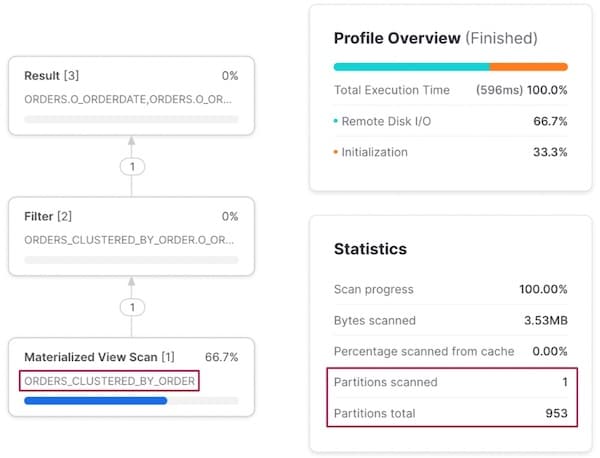
クラスタリング済みマテリアライズドビューのコストに関する考慮点
マテリアライズドビューを使う最大のデメリットは、別個のマテリアライズドビューを維持するための追加コストです。検討すべき要素は次の3つです。
- 新しいデータセットにかかるストレージコスト
- 各マテリアライズドビューのマネージドリフレッシュにかかる料金。マテリアライズドビューが古くならないよう、Snowflake はバックグラウンドで自動メンテナンスを実施します。ベーステーブルが変更されると、Snowflake が提供するコンピュートリソースを使うバックグラウンドサービスによって、そのテーブルに定義されたすべてのマテリアライズドビューが更新されます。
- 各マテリアライズドビューに対する自動クラスタリングの料金。マテリアライズドビューがベーステーブルと異なるクラスタリングになっている場合、マテリアライズドビュー側で変更されるマイクロパーティション数が、ベーステーブル側で変更される数を大きく上回ることがあります。
このあたりは別記事で詳しく取り上げる予定ですが、現時点ではマテリアライズドビューに関わるメンテナンスコスト 3 と自動クラスタリングコスト 4 をモニタリングすることをおすすめします。ストレージコストは、テーブルサイズとストレージ単価から事前に試算できます 5。
Snowflake ユーザーは、こうした追加コストを必ず織り込んで判断する必要があります。下流クエリの高速化と、それに伴うコンピュートコストの削減で完全に相殺できるケースもあれば、クエリの大幅な高速化によってコストが十分に正当化されるケースもあります。いずれにせよ、実コストを算出しない限り正しい判断はできません。
クラスタリング済みテーブル上のマテリアライズドビュー
ベーステーブルが更新されるたびに、関連するすべてのマテリアライズドビューでリフレッシュがトリガーされます。では、ベーステーブルとマテリアライズドビューが別々の列でクラスタリングされている場合は、どうなるのでしょうか。
- ベーステーブルに新しいデータが追加される
- マテリアライズドビューのリフレッシュがトリガーされる
- Snowflake の自動クラスタリングサービスがベーステーブルを更新し、クラスタリングを改善する
- ステップ2で更新されたマテリアライズドビューに対しても、自動クラスタリングが動く可能性がある
- ステップ3が完了すると、マテリアライズドビューに対してステップ2と4が再びトリガーされる可能性がある
自動クラスタリングされたテーブルの上にマテリアライズドビューを載せると、そのマテリアライズドビューのメンテナンスコストが大きく膨らむため、十分に注意してください。
マテリアライズドビューと DML 操作
マテリアライズドビューによるパフォーマンス向上の恩恵を受けられるのは select 系クエリのみで、update や delete などの DML 操作には適用されない点に注意が必要です。たとえば、次のクエリを実行した場合、
update orders
set o_clerk='new clerk'
where o_orderkey=5019980134
このクエリはベースの orders テーブルをフルスキャンし、マテリアライズドビューは利用しません。
注釈
- クラスタリングキーをカーディナリティの低い順から高い順に並べていることにお気づきでしょうか。複数列クラスターキーに関する Snowflake のドキュメントより引用します。
テーブルに複数列のクラスタリングキーを定義する場合、
CLUSTER BY句で列を指定する順序が重要です。一般的なルールとして、Snowflake は低いカーディナリティから高いカーディナリティの順に列を並べることを推奨しています。高カーディナリティの列を低カーディナリティの列より前に置くと、後者の列に対するクラスタリングの効果が一般に弱まります。
列のカーディナリティとは、その列が持つ異なる値の数のことです。次のクエリで確認できます。
select
count(*), -- 1,500,000,000
count(distinct o_orderdate), -- 2,406
count(distinct o_orderkey), -- 1,500,000,000
count(distinct o_custkey) -- 99,999,998
from public.orders
その結果として、cluster by (o_orderdate, o_custkey, o_orderkey としています。
マテリアライズドビューを利用できるのは、Snowflake の Enterprise エディション以上に限られます。
マテリアライズドビューのリフレッシュにかかるコストは、次のクエリでモニタリングできます。
select
date_trunc(day, start_time) as date,
table_name as materialized_view_name,
sum(credits_used) as num_credits_used
from snowflake.account_usage.materialized_view_refresh_history
group by 1,2
order by 1,2
- マテリアライズドビューに対する自動クラスタリングのコストは、次のクエリでモニタリングできます。
select
date_trunc(day, automatic_clustering_history.start_time) as date,
automatic_clustering_history.database_name || '.' || automatic_clustering_history.schema_name || '.' || automatic_clustering_history.table_name as materialized_view_name,
sum(credits_used) as num_credits_used
from snowflake.account_usage.automatic_clustering_history
inner join snowflake.account_usage.tables
on automatic_clustering_history.table_id=tables.table_id
and tables.table_type='MATERIALIZED VIEW'
group by 1,2
order by 1,2
- AWS 上のほとんどの顧客は $23/TB/月 を支払っています。ベーステーブルが 10TB なら、マテリアライズドビューを1つ追加するごとに年間 $2,760(
10*23*12)のコストが発生する計算になります。
Ian Whitestone・Co-founder & CEO of SELECT
Ian は SELECT(SaaS型の Snowflake コスト管理・最適化プラットフォーム)の Co-founder 兼 CEO です。SELECT を立ち上げる以前は、Shopify と Capital One でフルスタックのデータサイエンス&エンジニアリングチームを6年間率いていました。Shopify では、データウェアハウスの最適化とコスト可視化の取り組みをリードしました。
本記事では、マテリアライズドビューを活用することで、異なるクラスターキーを持つ複数バージョンのテーブルを作成する方法を紹介しました。この手法は、プルーニングの精度向上によってクエリ性能を大幅に高めるだけでなく、そのクエリにかかる仮想ウェアハウスのコスト削減にもつながります。Snowflake の他の機能と同様、こうしたメリットは背後にあるコストと慎重に比較したうえで判断する必要があります。
今後の記事では、テーブルに最適なクラスターキーを見極める方法、大規模テーブルにおける自動クラスタリングのコスト見積もり、クラスタリングの健全性のモニタリング、よりコスト効率の高い自動クラスタリングの実装方法など、重要なテーマを取り上げていく予定です。さらに、1つのテーブルに複数のクラスターキーを定義する方法と、それが妥当となるケースについても掘り下げます。
ご質問や、これらのトピックをさらに深掘りしたいというご要望があれば、いつでも Twitter またはメールでお気軽にご連絡ください。新しい記事の公開通知を受け取りたい方は、ぜひこのページの下部から Snowflake ニュースレターにご登録ください。