Dans notre précédent article sur le clustering Snowflake, nous avons souligné l'importance de bien comprendre les usages d'une table avant de choisir sa stratégie de clustering. Si un champ apparaît fréquemment dans les clauses where, il fait un excellent candidat comme clé de clustering. Mais que faire lorsque d'autres prédicats where couramment utilisés pourraient eux aussi tirer parti du clustering ?
Dans cet article, nous comparons trois options : 1. Une table unique avec une clé de clustering multi-colonnes 2. Le maintien de tables distinctes, chacune clusterisée sur une colonne précise 3. L'utilisation de vues matérialisées clusterisées pour exploiter la puissante fonctionnalité de pruning automatique de Snowflake
Les limites des clés de clustering multi-colonnes
Lors de la définition d'une clé de clustering pour une table, Snowflake permet d'utiliser plusieurs colonnes. Prenons une table de commandes contenant 1,5 milliard d'enregistrements :
-- 1,500,000,000 records
create table orders as (
select
o_orderdate,
o_orderkey,
o_custkey,
o_clerk
from snowflake_sample_data.tpch_sf1000.orders
)
Voici un scénario classique. L'équipe finance interroge régulièrement cette table sur des plages de dates précises pour analyser le volume des ventes. Les équipes Engineers s'en servent aussi pour examiner des commandes en particulier. Et le marketing, de son côté, souhaite consulter l'historique complet des commandes d'un client donné.
Cela représente trois schémas d'accès, et donc trois colonnes différentes sur lesquelles nous voudrions clusteriser notre table : o_orderdate, o_custkey et o_orderkey. Comme l'indique la documentation Snowflake, nous pouvons définir une clé de clustering multi-colonnes en spécifiant les trois colonnes dans l'expression cluster by
1 :
create table orders cluster by (o_orderdate, o_custkey, o_orderkey) as (
select
o_orderdate, -- 2,406 distinct values
o_orderkey, -- 1,500,000,000 distinct values
o_custkey, -- 99,999,998 distinct values
o_clerk
from snowflake_sample_data.tpch_sf1000.orders
)
Schéma d'accès 1 : requête par date
select
o_orderdate,
count(*) as cnt
from orders
where o_orderdate between '1993-03-01' and '1993-03-31'
group by 1
En exécutant une requête sur une plage de dates, le profil de requête révèle un excellent pruning. Seules 22 micro-partitions sur 1 609 sont scannées.
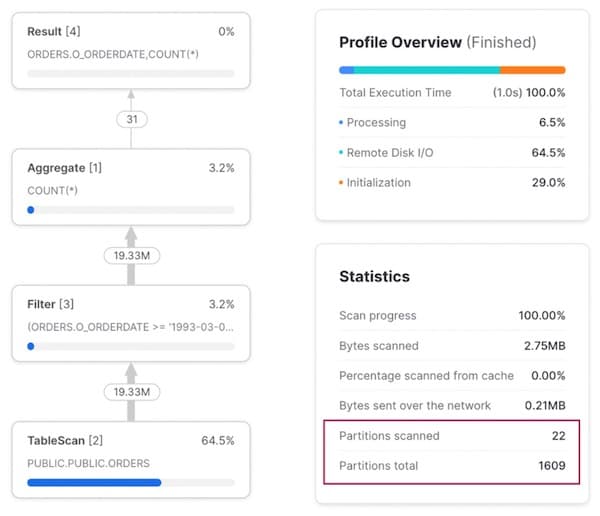
Schéma d'accès 2 : requête pour un client spécifique
select *
from orders
where o_custkey = 52671775
Dès que la requête cherche toutes les commandes d'un client donné, le pruning devient inefficace : 99 % des micro-partitions sont scannées.
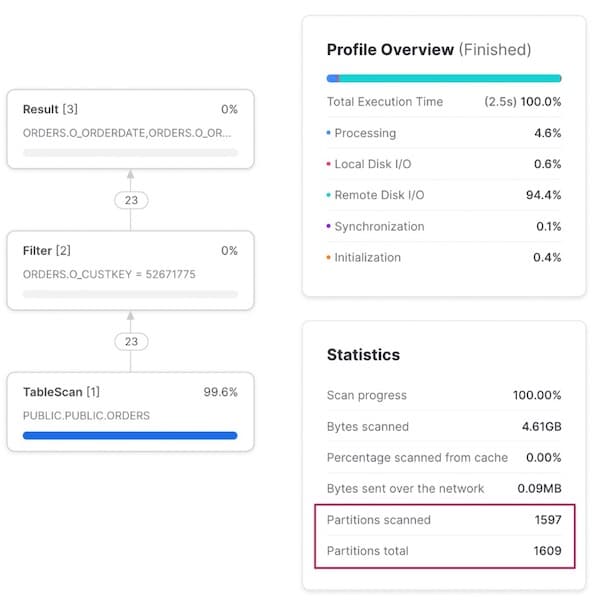
Schéma d'accès 3 : requête pour une commande spécifique
select *
from orders
where o_orderkey = 5019980134
Pour la recherche par commande — la troisième colonne de notre clé de clustering — le pruning est totalement absent : toutes les micro-partitions sont scannées pour retrouver un seul enregistrement.
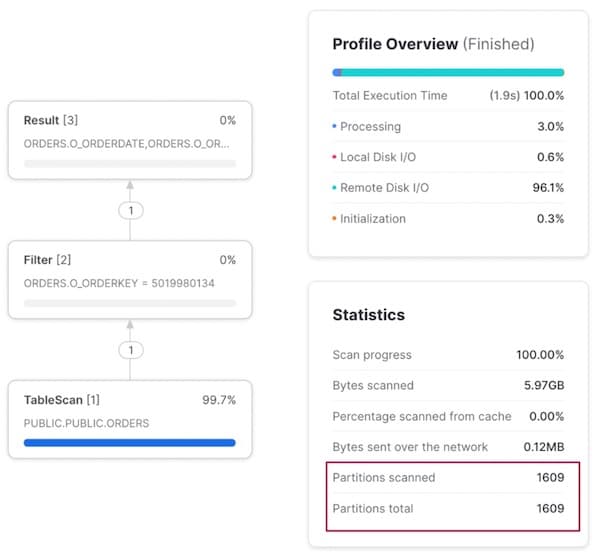
Comprendre la dégradation des performances avec les clés multi-colonnes
Comme on l'a vu, les performances du pruning se dégradent fortement pour les prédicats (filtres) portant sur la deuxième et la troisième colonne.
Pour comprendre pourquoi, il faut saisir le fonctionnement du clustering Snowflake avec des clés multi-colonnes. Le modèle mental le plus simple consiste à imaginer une organisation des données en boîtes de boîtes. Snowflake regroupe d'abord les données par o_orderdate. Puis, à l'intérieur de chaque boîte date, il les subdivise par o_custkey. Et dans chacune de ces sous-boîtes, il les subdivise à nouveau par o_orderkey.
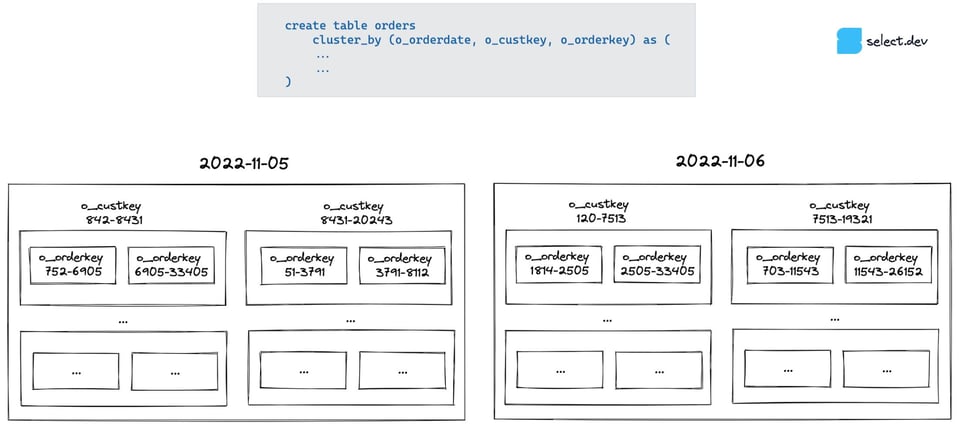
Le pruning Snowflake repose sur les métadonnées min/max de chaque colonne dans chaque micro-partition. Lorsqu'on interroge par date, chaque date dispose de sa propre boîte, ce qui permet d'écarter (pruner) rapidement les boîtes non pertinentes. En revanche, lorsqu'on interroge par client ou par clé de commande, il faut inspecter chaque boîte date de premier niveau, car la plage min/max de ces colonnes est très étendue (de nombreux clients passent commande chaque jour, et les clés de commande sont des identifiants aléatoires, sans corrélation avec la date) — il devient alors impossible d'exclure des boîtes.
Créer plusieurs copies de la même table avec différentes clés de clustering
Autre approche possible : créer et maintenir une table distincte pour chaque clé de clustering.
create table orders_clustered_by_date cluster by (o_orderdate) as (
select
o_orderdate,
o_orderkey,
o_custkey,
o_clerk
from snowflake_sample_data.tpch_sf1000.orders
)
create table orders_clustered_by_customer cluster by (o_custkey) as (
select
o_orderdate,
o_orderkey,
o_custkey,
o_clerk
Développer le code
Cette approche a des inconvénients évidents. Les utilisateurs doivent désormais jongler entre trois tables et se souvenir de celle à utiliser selon le scénario. Peu pratique pour une table largement sollicitée. Il faut aussi maintenir les trois copies de cette table dans vos pipelines ETL/ELT.
N'y aurait-il pas une meilleure solution ?
Utiliser les vues matérialisées clusterisées pour exploiter le pruning automatique de Snowflake
Qu'est-ce qu'une vue matérialisée ?
Une vue matérialisée est un jeu de données pré-calculé, issu d'une spécification de requête et stocké pour un usage ultérieur
2. Nous reviendrons sur leurs cas d'usage dans un prochain article ; en attendant, la documentation Snowflake les couvre en détail. Quand vous créez une vue matérialisée comme celle ci-dessous, Snowflake maintient automatiquement ce jeu de données dérivé pour vous. Dès que des données sont ajoutées ou modifiées dans la table de base (orders), Snowflake met à jour la vue matérialisée.
create materialized view orders_aggregated_by_date as (
select
o_orderdate,
count(*) as cnt
from orders
group by 1
)
Désormais, si quelqu'un exécute cette requête sur la table de base :
select
o_orderdate,
count(*) as cnt
from orders
group by 1
Snowflake va scanner automatiquement la vue matérialisée pré-calculée plutôt que de recalculer l'ensemble du jeu de données.
Créer des vues matérialisées clusterisées automatiquement
Les vues matérialisées prennent en charge le clustering automatique. Nous pouvons donc créer deux nouvelles vues matérialisées qui clusterisent séparément notre table orders par o_custkey et o_orderkey, pour des performances optimales :
-- these will take some time to execute, since the entire dataset is
-- being materialized (created) for the first time
create materialized view orders_clustered_by_customer cluster by(o_custkey) as (
select
o_orderdate,
o_orderkey,
o_custkey,
o_clerk
from orders
)
;
create materialized view orders_clustered_by_order cluster by(o_orderkey) as (
select
o_orderdate,
Développer le code
Techniquement, nous pourrions créer une troisième vue matérialisée clusterisée par o_orderdate. À la place, optons pour une solution plus économique en exploitant le tri manuel sur la table de base :
create table orders as (
select
o_orderdate,
o_orderkey,
o_custkey,
o_clerk
from snowflake_sample_data.tpch_sf1000.orders
-- sort and therefore cluster the table by o_orderdate
order by o_orderdate
)
Nouveau test sur nos trois schémas d'accès
Schéma d'accès 1 : requête par date
select
o_orderdate,
count(*) as cnt
from orders
where
o_orderdate between date'1993-03-01' and date'1993-03-31'
group by 1
Lorsqu'une requête filtre sur o_orderdate, c'est la table de base orders qui est utilisée, puisqu'elle est naturellement clusterisée sur cette colonne.
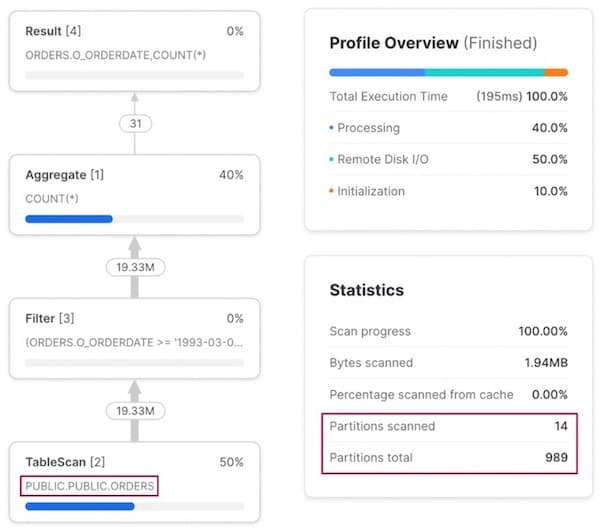
Schéma d'accès 2 : requête par client
select *
from orders
where
o_custkey=52671775
Lorsqu'on filtre par o_custkey, l'optimiseur de Snowflake détecte qu'il existe une vue matérialisée clusterisée sur cette colonne et redirige intelligemment le plan d'exécution vers cette vue.
Notez qu'il n'est pas nécessaire de réécrire la requête pour indiquer explicitement à Snowflake d'interroger la vue matérialisée : il s'en charge en interne. Les utilisateurs n'ont pas à se souvenir du jeu de données à interroger selon les scénarios !
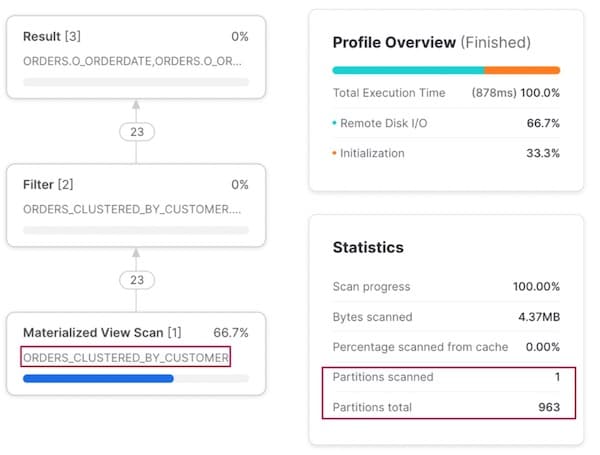
Schéma d'accès 3 : requête par commande
select *
from orders
where
o_orderkey = 5019980134
Le filtrage sur o_orderkey donne un comportement similaire : Snowflake réoriente l'exécution de la requête vers l'autre vue matérialisée plutôt que vers la table de base orders.
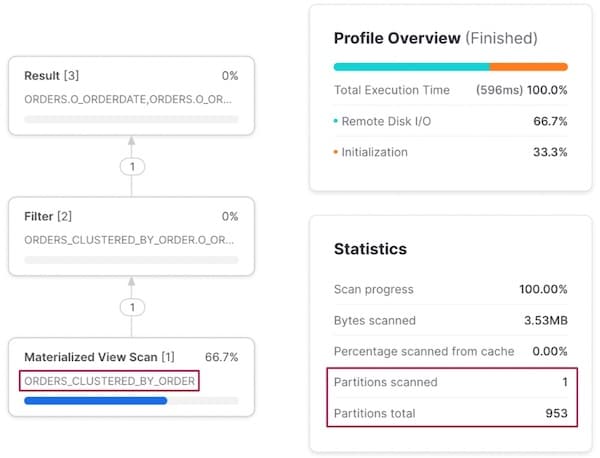
Considérations de coût pour les vues matérialisées clusterisées
Le principal inconvénient des vues matérialisées tient au coût supplémentaire de leur maintenance. Trois éléments sont à prendre en compte :
- Les coûts de stockage liés aux nouveaux jeux de données
- Les frais des rafraîchissements gérés de chaque vue matérialisée. Pour éviter qu'elles ne deviennent obsolètes, Snowflake effectue automatiquement leur maintenance en arrière-plan. Lorsque la table de base change, toutes les vues matérialisées qui en dépendent sont mises à jour par un service d'arrière-plan utilisant les ressources de calcul fournies par Snowflake.
- Les frais de clustering automatique de chaque vue matérialisée. Si une vue matérialisée est clusterisée différemment de la table de base, le nombre de micro-partitions modifiées dans la vue peut être nettement supérieur à celui des micro-partitions modifiées dans la table de base.
Nous donnerons davantage de recommandations à ce sujet dans un prochain article. Pour l'instant, nous conseillons de surveiller les coûts de maintenance 3 et les coûts de clustering automatique 4 associés à vos vues matérialisées. Vous pouvez estimer en amont vos coûts de stockage à partir de la taille de la table et de votre tarif de stockage 5.
Il est essentiel que les utilisateurs de Snowflake intègrent ces coûts supplémentaires dans leur réflexion. Ils peuvent être entièrement compensés par des requêtes en aval plus rapides, et donc des coûts de calcul réduits. Ils peuvent aussi être pleinement justifiés par les gains de performance obtenus. Mais impossible de trancher sans avoir au préalable chiffré le coût réel.
Vue matérialisée sur une table clusterisée
Chaque mise à jour de votre table de base déclenche un rafraîchissement de toutes les vues matérialisées associées. Que se passe-t-il alors si votre table de base et votre vue matérialisée sont clusterisées sur des colonnes différentes ?
- De nouvelles données sont ajoutées à la table de base
- Un rafraîchissement de la vue matérialisée est déclenché
- Le service de clustering automatique de Snowflake met à jour la table de base pour améliorer son clustering
- Le clustering automatique peut également s'enclencher pour la vue matérialisée mise à jour à l'étape 2
- Une fois l'étape 3 terminée, elle peut redéclencher les étapes 2 et 4 pour la vue matérialisée
Soyez très prudent lorsque vous ajoutez une vue matérialisée par-dessus une table clusterisée automatiquement : cela augmente sensiblement les coûts de maintenance de cette vue matérialisée.
Vues matérialisées et opérations DML
À noter : les gains de performance des vues matérialisées ne profitent qu'aux requêtes de type select. Les opérations DML telles que updates et deletes n'en bénéficient pas. Par exemple, si vous exécutez :
update orders
set o_clerk='new clerk'
where o_orderkey=5019980134
La requête effectuera un scan complet de la table de base orders, sans recourir à la vue matérialisée.
Notes
- Remarquez comment nous ordonnons les clés de clustering, de la plus faible à la plus forte cardinalité ? Extrait de la documentation Snowflake sur les clés de clustering multi-colonnes :
Si vous définissez une clé de clustering multi-colonnes pour une table, l'ordre dans lequel les colonnes sont spécifiées dans la clause
CLUSTER BYest important. En règle générale, Snowflake recommande d'ordonner les colonnes de la cardinalité la plus faible à la cardinalité la plus élevée. Placer une colonne à forte cardinalité avant une colonne à plus faible cardinalité réduit généralement l'efficacité du clustering sur cette dernière.
La cardinalité d'une colonne correspond simplement au nombre de valeurs distinctes. Vous pouvez l'obtenir avec la requête suivante :
select
count(*), -- 1,500,000,000
count(distinct o_orderdate), -- 2,406
count(distinct o_orderkey), -- 1,500,000,000
count(distinct o_custkey) -- 99,999,998
from public.orders
Par conséquent, nous utilisons cluster by (o_orderdate, o_custkey, o_orderkey.
Les vues matérialisées ne sont disponibles qu'à partir de l'édition Enterprise (ou supérieure) de Snowflake.
Vous pouvez surveiller le coût des rafraîchissements de vos vues matérialisées avec la requête suivante :
select
date_trunc(day, start_time) as date,
table_name as materialized_view_name,
sum(credits_used) as num_credits_used
from snowflake.account_usage.materialized_view_refresh_history
group by 1,2
order by 1,2
- Vous pouvez surveiller le coût du clustering automatique sur votre vue matérialisée avec la requête suivante :
select
date_trunc(day, automatic_clustering_history.start_time) as date,
automatic_clustering_history.database_name || '.' || automatic_clustering_history.schema_name || '.' || automatic_clustering_history.table_name as materialized_view_name,
sum(credits_used) as num_credits_used
from snowflake.account_usage.automatic_clustering_history
inner join snowflake.account_usage.tables
on automatic_clustering_history.table_id=tables.table_id
and tables.table_type='MATERIALIZED VIEW'
group by 1,2
order by 1,2
- La plupart des clients sur AWS paient 23 $/To/mois. Donc si votre table de base fait 10 To, chaque vue matérialisée supplémentaire coûtera 2 760 $/an (
10*23*12).
Ian Whitestone·Co-founder & CEO of SELECT
Ian est cofondateur et CEO de SELECT, une plateforme SaaS de gestion et d'optimisation des coûts Snowflake. Avant de lancer SELECT, Ian a passé 6 ans à diriger des équipes full stack data science & engineering chez Shopify et Capital One. Chez Shopify, il a piloté l'optimisation de l'entrepôt de données et l'amélioration de l'observabilité des coûts.
Dans cet article, nous avons vu comment exploiter les vues matérialisées pour disposer de plusieurs versions d'une même table avec des clés de clustering différentes. Cette pratique peut nettement améliorer les performances des requêtes grâce à un meilleur pruning, et même réduire les coûts de virtual warehouse associés. Comme pour tout ce qui touche à Snowflake, ces bénéfices doivent être mis en balance avec leurs coûts sous-jacents.
Dans de prochains articles, nous aborderons des sujets clés : comment déterminer les clés de clustering optimales pour votre table, comment estimer les coûts du clustering automatique sur une table volumineuse, ou encore comment surveiller la santé du clustering et mettre en place un clustering automatique plus économique. Nous approfondirons également la définition de plusieurs clés de clustering sur une même table et les cas où cette approche est pertinente.
Comme toujours, n'hésitez pas à nous contacter via Twitter ou par email : nous serons ravis de répondre à vos questions ou d'approfondir ces sujets avec vous. Pour être informé de la parution de nos prochains articles, inscrivez-vous à notre newsletter Snowflake en bas de cette page.