En nuestro post anterior sobre clustering en Snowflake, hablamos de lo importante que es entender los patrones de uso de una tabla antes de decidir cómo clusterizarla. Si un campo se usa con frecuencia en cláusulas where, es un excelente candidato a cluster key. Pero ¿qué pasa cuando hay otros predicados where de uso frecuente que también ganarían con el clustering?
En este post comparamos tres opciones: 1. Una sola tabla con cluster keys de varias columnas 2. Mantener tablas separadas, cada una clusterizada por una columna distinta 3. Usar vistas materializadas clusterizadas para aprovechar la potente función de pruning automático de Snowflake
Las limitaciones de las cluster keys de varias columnas
Al definir una cluster key para una tabla, Snowflake te permite usar más de una columna. Supongamos que tenemos una tabla de orders con 1.500 millones de registros:
-- 1,500,000,000 records
create table orders as (
select
o_orderdate,
o_orderkey,
o_custkey,
o_clerk
from snowflake_sample_data.tpch_sf1000.orders
)
Un escenario habitual es el siguiente. El equipo de finanzas consulta con regularidad rangos de fechas específicos sobre esta tabla para entender el volumen de ventas. También tenemos a los equipos de Engineering consultándola para investigar órdenes puntuales. Y, por si fuera poco, marketing quiere poder ver todo el historial de órdenes de un cliente determinado.
Son tres patrones de acceso distintos y, por lo tanto, tres columnas diferentes por las que nos gustaría clusterizar la tabla: o_orderdate, o_custkey y o_orderkey. Como se muestra en la documentación de Snowflake, podemos definir una cluster key de varias columnas usando las tres en la expresión cluster by
1:
create table orders cluster by (o_orderdate, o_custkey, o_orderkey) as (
select
o_orderdate, -- 2,406 distinct values
o_orderkey, -- 1,500,000,000 distinct values
o_custkey, -- 99,999,998 distinct values
o_clerk
from snowflake_sample_data.tpch_sf1000.orders
)
Patrón de acceso 1: Consulta por fecha
select
o_orderdate,
count(*) as cnt
from orders
where o_orderdate between '1993-03-01' and '1993-03-31'
group by 1
Al ejecutar una consulta sobre un rango de fechas, en el query profile se ve un excelente pruning: solo se escanean 22 de 1.609 micro-particiones.
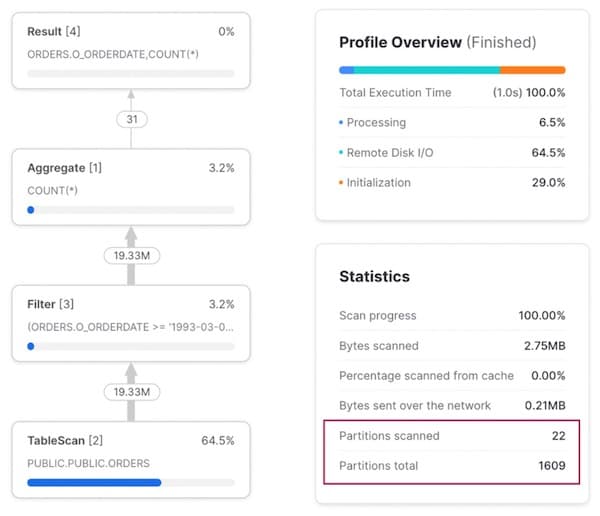
Patrón de acceso 2: Consulta por un cliente específico
select *
from orders
where o_custkey = 52671775
Cuando modificamos la consulta para buscar todas las órdenes de un cliente en particular, el pruning deja de ser eficaz: se escanea el 99 % de las micro-particiones.
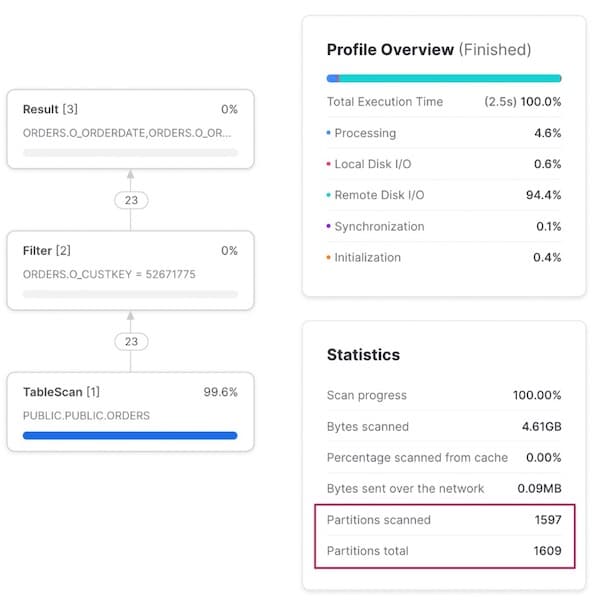
Patrón de acceso 3: Consulta por una orden específica
select *
from orders
where o_orderkey = 5019980134
En la búsqueda por orden —la tercera columna de la cluster key— no hay pruning de ningún tipo: se escanean todas las micro-particiones para encontrar un único registro.
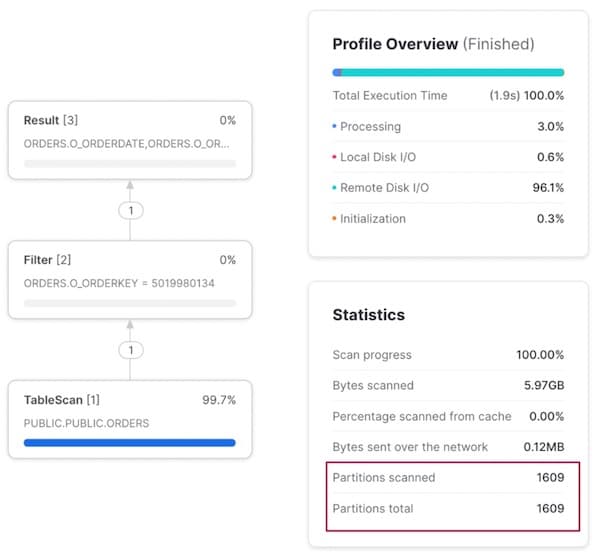
Por qué se degrada el rendimiento con cluster keys de varias columnas
Como acabamos de ver, el rendimiento del pruning cae considerablemente para los predicados (filtros) sobre la segunda y la tercera columna.
Para entender por qué, conviene saber cómo funciona el clustering de Snowflake con cluster keys de varias columnas. El modelo mental más simple es pensar cómo organizarías los datos en "cajas dentro de cajas". Snowflake primero agrupa los datos por o_orderdate. Luego, dentro de cada caja de "fecha", los divide por o_custkey. Y dentro de cada una de esas cajas, los divide por o_orderkey.
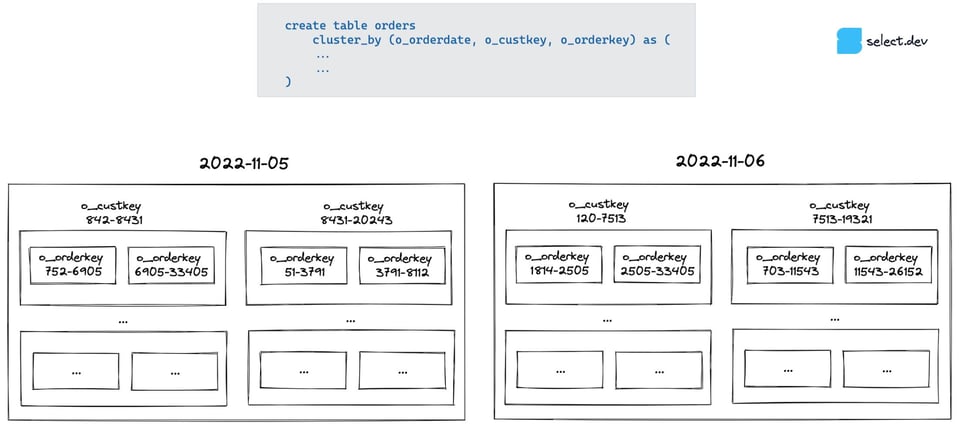
El pruning de Snowflake se basa en revisar los metadatos de min/max de la columna en cada micro-partición. Al consultar por fecha, cada fecha tiene su propia caja, así que se descartan rápidamente las cajas irrelevantes. En cambio, al consultar por cliente o por order key, hay que revisar cada caja de fecha de nivel superior porque el rango de min/max en esas columnas es muy amplio (cada día hay clientes muy variados haciendo órdenes y los order keys son IDs aleatorios, no ascendentes con la fecha), así que no se puede descartar ninguna caja.
Crear varias copias de la misma tabla con distintas cluster keys
Como alternativa, podríamos crear y mantener una tabla independiente para cada cluster key:
create table orders_clustered_by_date cluster by (o_orderdate) as (
select
o_orderdate,
o_orderkey,
o_custkey,
o_clerk
from snowflake_sample_data.tpch_sf1000.orders
)
create table orders_clustered_by_customer cluster by (o_custkey) as (
select
o_orderdate,
o_orderkey,
o_custkey,
o_clerk
Expandir código
Este enfoque tiene desventajas claras. Los usuarios deben llevar el control de tres tablas distintas y recordar cuál corresponde a cada escenario. Poco práctico para una tabla de uso extendido. Además, tendrías que mantener las tres copias por separado en tus pipelines de ETL/ELT.
¿Habrá una forma mejor?
Usar vistas materializadas clusterizadas para aprovechar el pruning automático de Snowflake
¿Qué son las vistas materializadas?
Una vista materializada es un conjunto de datos precomputado, derivado de una especificación de consulta y almacenado para uso posterior
2. Hablaremos de sus casos de uso en un próximo post, pero por ahora puedes consultar la documentación de Snowflake, que las cubre en detalle. Cuando creas una vista materializada como la siguiente, Snowflake se encarga de mantener ese conjunto de datos derivado por ti. Si se agregan o modifican datos en la tabla base (orders), Snowflake actualiza la vista materializada automáticamente.
create materialized view orders_aggregated_by_date as (
select
o_orderdate,
count(*) as cnt
from orders
group by 1
)
Ahora, si alguien ejecuta esta consulta contra la tabla base:
select
o_orderdate,
count(*) as cnt
from orders
group by 1
Snowflake escaneará automáticamente la vista materializada precomputada en vez de volver a calcular todo el conjunto de datos.
Cómo crear vistas materializadas con clustering automático
Las vistas materializadas soportan clustering automático. Aprovechándolo, podemos crear dos nuevas vistas materializadas que clustericen por separado la tabla orders por o_custkey y por o_orderkey, y así obtener el mejor rendimiento:
-- these will take some time to execute, since the entire dataset is
-- being materialized (created) for the first time
create materialized view orders_clustered_by_customer cluster by(o_custkey) as (
select
o_orderdate,
o_orderkey,
o_custkey,
o_clerk
from orders
)
;
create materialized view orders_clustered_by_order cluster by(o_orderkey) as (
select
o_orderdate,
Expandir código
En teoría, podríamos crear una tercera vista materializada clusterizada por o_orderdate. En su lugar, optamos por el enfoque más rentable: aprovechar el ordenamiento manual sobre la tabla orders base:
create table orders as (
select
o_orderdate,
o_orderkey,
o_custkey,
o_clerk
from snowflake_sample_data.tpch_sf1000.orders
-- sort and therefore cluster the table by o_orderdate
order by o_orderdate
)
Probemos otra vez los tres patrones de acceso
Patrón de acceso 1: Consulta por fecha
select
o_orderdate,
count(*) as cnt
from orders
where
o_orderdate between date'1993-03-01' and date'1993-03-31'
group by 1
Al ejecutar una consulta con un filtro sobre o_orderdate, se usa la tabla orders base original, ya que está naturalmente clusterizada por esa columna.
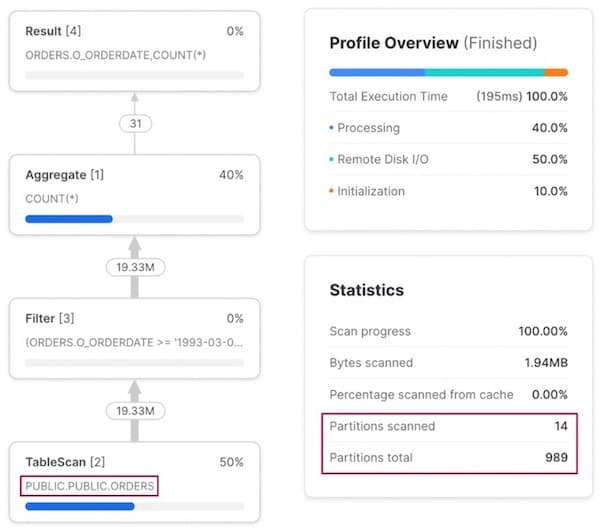
Patrón de acceso 2: Consulta por cliente
select *
from orders
where
o_custkey=52671775
Cuando filtramos por o_custkey, el optimizador de Snowflake detecta que hay una vista materializada clusterizada por esa columna y, de forma inteligente, indica al plan de ejecución que lea desde esa vista.
Ojo: no hace falta reescribir la consulta para indicarle a Snowflake que use la vista materializada; lo hace por debajo. ¡Los usuarios no necesitan recordar qué dataset consultar en cada caso!
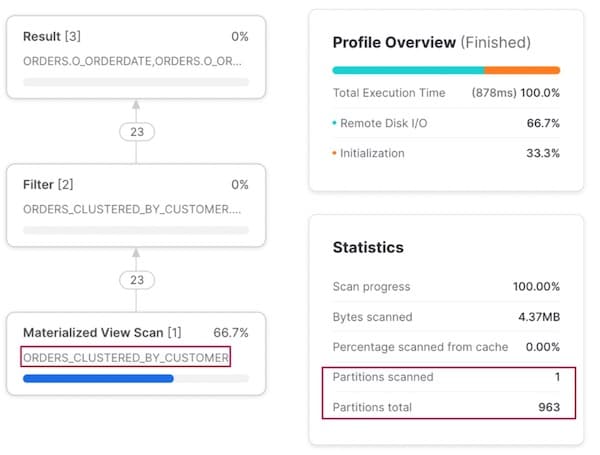
Patrón de acceso 3: Consulta por orden
select *
from orders
where
o_orderkey = 5019980134
El filtrado por o_orderkey se comporta de forma similar: Snowflake "redirige" la ejecución para escanear la otra vista materializada en lugar de la tabla orders base.
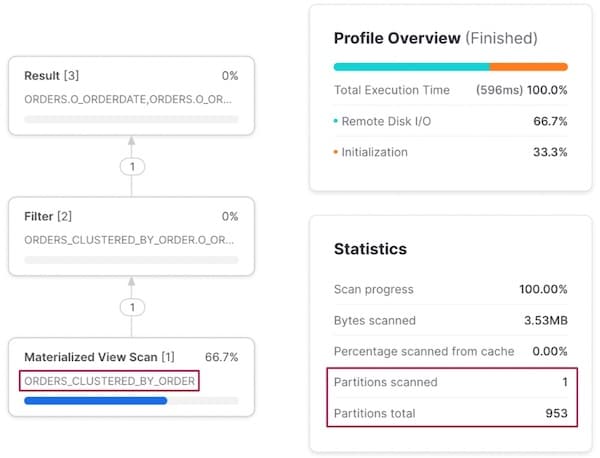
Consideraciones de costo de las vistas materializadas clusterizadas
La principal desventaja de usar vistas materializadas son los costos adicionales de mantener esas vistas por separado. Hay tres componentes a tener en cuenta:
- Costos de almacenamiento asociados a los nuevos datasets
- Cargos por los refreshes gestionados de cada vista materializada. Para evitar que queden desactualizadas, Snowflake realiza mantenimiento automático en segundo plano. Cuando la tabla base cambia, todas las vistas materializadas definidas sobre ella se actualizan mediante un servicio en segundo plano que consume recursos de cómputo provistos por Snowflake.
- Cargos por el clustering automático de cada vista materializada. Si una vista materializada está clusterizada de forma distinta a la tabla base, la cantidad de micro-particiones modificadas en la vista puede ser bastante mayor que la modificada en la tabla base.
Daremos más recomendaciones al respecto en un próximo post, pero por ahora conviene monitorear los costos de mantenimiento 3 y los costos de clustering automático 4 asociados a tus vistas materializadas. Los costos de almacenamiento se pueden estimar de entrada en función del tamaño de la tabla y tus Precios de almacenamiento 5.
Es fundamental que los usuarios de Snowflake tengan en cuenta estos costos adicionales. Es posible que se compensen por completo con consultas downstream más rápidas y, en consecuencia, menores costos de cómputo. También puede pasar que el costo esté plenamente justificado por habilitar consultas mucho más rápidas. Pero esa decisión no se puede tomar sin antes calcular los costos reales.
Vista materializada sobre una tabla clusterizada
Cada actualización de la tabla base dispara un refresh de todas las vistas materializadas asociadas. Entonces, ¿qué pasa si la tabla base y la vista materializada están clusterizadas por columnas diferentes?
- Se agregan nuevos datos a la tabla base
- Se dispara un refresh de la vista materializada
- El servicio de clustering automático de Snowflake actualiza la tabla base para mejorar su clustering
- El clustering automático también puede activarse sobre la vista materializada actualizada en el paso 2
- Una vez completado el paso 3, eso puede volver a disparar los pasos 2 y 4 sobre la vista materializada
Mucho cuidado al agregar una vista materializada sobre una tabla con clustering automático: aumentará considerablemente los costos de mantenimiento de esa vista.
Vistas materializadas y operaciones DML
Es importante señalar que los beneficios de rendimiento de las vistas materializadas solo se ven en consultas tipo select. Las operaciones DML como updates y deletes no se benefician. Por ejemplo, si ejecutas:
update orders
set o_clerk='new clerk'
where o_orderkey=5019980134
La consulta hará un full table scan sobre la tabla orders base y no usará la vista materializada.
Notas
- ¿Te fijaste que ordenamos las claves de clustering de menor a mayor cardinalidad? De la documentación de Snowflake sobre cluster keys de varias columnas:
Si vas a definir una clave de clustering de varias columnas para una tabla, el orden en que se especifican las columnas en la cláusula
CLUSTER BYes importante. Como regla general, Snowflake recomienda ordenar las columnas de la cardinalidad más baja a la más alta. Poner una columna de mayor cardinalidad antes que una de menor cardinalidad suele reducir la efectividad del clustering en esta última.
La cardinalidad de una columna es simplemente el número de valores distintos. Lo puedes averiguar con una consulta:
select
count(*), -- 1,500,000,000
count(distinct o_orderdate), -- 2,406
count(distinct o_orderkey), -- 1,500,000,000
count(distinct o_custkey) -- 99,999,998
from public.orders
Por eso hacemos cluster by (o_orderdate, o_custkey, o_orderkey.
Las vistas materializadas solo están disponibles en la edición Enterprise (o superior) de Snowflake.
Puedes monitorear el costo de los refreshes de tus vistas materializadas con la siguiente consulta:
select
date_trunc(day, start_time) as date,
table_name as materialized_view_name,
sum(credits_used) as num_credits_used
from snowflake.account_usage.materialized_view_refresh_history
group by 1,2
order by 1,2
- Puedes monitorear el costo del clustering automático sobre tu vista materializada con la siguiente consulta:
select
date_trunc(day, automatic_clustering_history.start_time) as date,
automatic_clustering_history.database_name || '.' || automatic_clustering_history.schema_name || '.' || automatic_clustering_history.table_name as materialized_view_name,
sum(credits_used) as num_credits_used
from snowflake.account_usage.automatic_clustering_history
inner join snowflake.account_usage.tables
on automatic_clustering_history.table_id=tables.table_id
and tables.table_type='MATERIALIZED VIEW'
group by 1,2
order by 1,2
- La mayoría de los clientes en AWS pagan USD 23/TB/mes. Así que, si tu tabla base es de 10TB, cada vista materializada adicional costará USD 2.760 al año (
10*23*12).
Ian Whitestone·Co-founder & CEO of SELECT
Ian es Co-founder y CEO de SELECT, una plataforma SaaS de gestión y optimización de costos en Snowflake. Antes de fundar SELECT, Ian pasó 6 años liderando equipos full stack de data science y Engineering en Shopify y Capital One. En Shopify, lideró los esfuerzos para optimizar el data warehouse y aumentar la observabilidad de costos.
En este post mostramos cómo aprovechar las vistas materializadas para crear varias versiones de una tabla con distintas cluster keys. Esta práctica puede mejorar de forma notable el rendimiento de las consultas gracias a un mejor pruning, e incluso reducir los costos de virtual warehouse asociados. Como con todo en Snowflake, estos beneficios deben sopesarse con cuidado frente a los costos subyacentes.
En próximos posts vamos a explorar temas importantes como determinar las cluster keys óptimas para tu tabla, estimar los costos del clustering automático en tablas grandes, y cómo monitorear la salud del clustering e implementar un clustering automático más rentable. También profundizaremos en cómo definir varias cluster keys sobre una misma tabla y cuándo tiene sentido hacerlo.
Como siempre, no dudes en escribirnos por Twitter o email: con gusto respondemos preguntas o profundizamos en estos temas. Si quieres que te avisemos cuando publiquemos un nuevo post, suscríbete a nuestro newsletter de Snowflake al final de esta página.