Das MERGE-Statement ist ein vielseitiges, leistungsstarkes Werkzeug, mit dem sich Zeilen in einem Rutsch upserten und löschen lassen. Statt Daten-Loading-Pipelines über mehrere voneinander abhängige, aber separate Statements zu steuern, bündeln Sie alles mit MERGE in einem einzigen atomaren Statement – deutlich schlanker und besser kontrollierbar. In diesem Beitrag führen wir Sie durch die Funktionen und die architektonischen Grundlagen von MERGE in Snowflake und zeigen, wie Sie die Performance von MERGE-Queries verbessern.
Was ist MERGE in Snowflake?
Das MERGE-Feature gibt es schon lange – noch aus der Zeit vor der Hochphase spaltenorientierter Datenbanken. Auch bekannt als Upsert (Insert und Update), hilft es uns, Änderungen sauber abzubilden und die Konsistenz von Datenpipelines sicherzustellen. Moderne ETL-Jobs verarbeiten häufig endlose Datenströme inkrementell – MERGE darf hier nicht fehlen. Es deckt nahezu alle Anwendungsfälle ab und führt Delete-, Insert- und Update-Operationen in einer einzigen Transaktion aus. Mehrere Skripte, die parallel auf dieselbe Tabelle schreiben, sind damit kein Problem mehr.
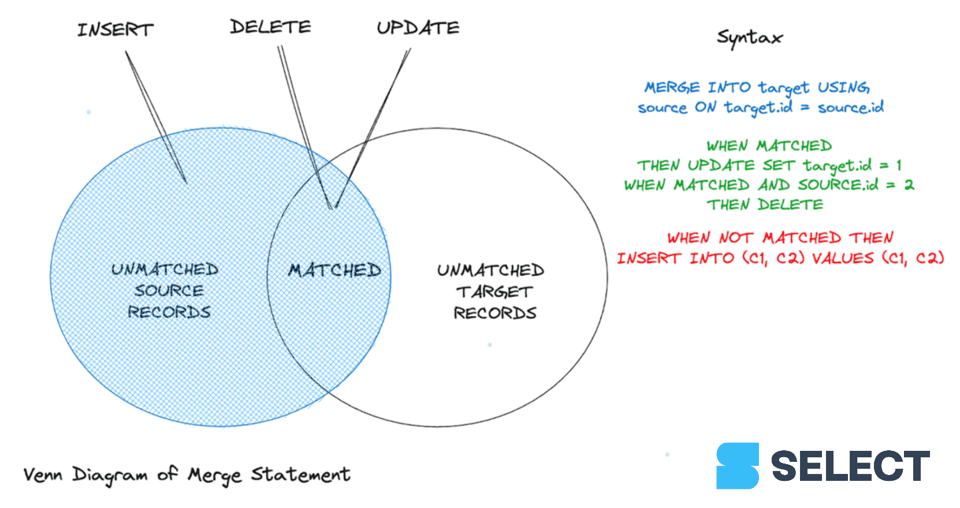
Anders als ein UPDATE-Statement kann MERGE mehrere Match-Bedingungen nacheinander abarbeiten, um Updates oder Deletes durchzuführen. Für nicht übereinstimmende Datensätze lassen sich allerdings nur Daten aus der Quell- in die Zieltabelle einfügen. Anders als bei Databricks 1 und Google BigQuery 2 erlaubt Snowflake derzeit nicht, das Verhalten bei nur teilweise erfüllten Bedingungen zu definieren – insbesondere nicht für nicht übereinstimmende Zeilen in der Quelltabelle.
Werfen wir einen Blick auf die Syntax. Für den MERGE-Befehl müssen Sie folgende Argumente übergeben:
- Quelltabelle: die Tabelle mit den zusammenzuführenden Daten.
- Zieltabelle: die Tabelle, in die die Daten synchronisiert werden sollen.
- Join-Ausdruck: die Schlüsselspalten beider Tabellen, die diese miteinander verknüpfen.
- Matched-Klausel: mindestens eine (Non-)Matched-Klausel, die das gewünschte Ergebnis festlegt.
Aktivitätsstatus von Kunden mit MERGE aktualisieren
Starten wir mit einem Beispiel: einer Kundentabelle, die wir aus einer Quelltabelle mit neuen Kundendaten aktualisieren möchten. Wir nutzen customer_id, um die Datensätze beider Tabellen abzugleichen. Damit deutlich wird, wie MERGE Updates und Inserts gleichermaßen handhabt, überschneiden sich die Testdaten teilweise.
-- Creating Tables
CREATE OR REPLACE TABLE target_table (
customer_id NUMBER,
is_active BOOLEAN,
updated_date DATE
)
;
CREATE OR REPLACE TABLE source_table (
customer_id NUMBER,
is_active BOOLEAN
)
;
-- Inserting test values
Code anzeigen
Wir haben damit ein Upsert durchgeführt: 2 Zeilen (ID: 1, 2) wurden aktualisiert und 1 neue Zeile (ID: 4) eingefügt. Der verbleibende Kunde (ID: 3) bleibt unberührt, da es in der Quelltabelle keinen passenden Datensatz gibt. Dieses einfache Beispiel zeigt die Grundfunktionen des Operators und wie Sie ihn in Ihrem Projekt einsetzen können.
Gehen wir einen Schritt weiter und schauen, was unter der Haube passiert.
Performance von MERGE-Queries verstehen und verbessern
Das Snowflake Query Profile der oben gezeigten MERGE-Query für "customers" sieht so aus:
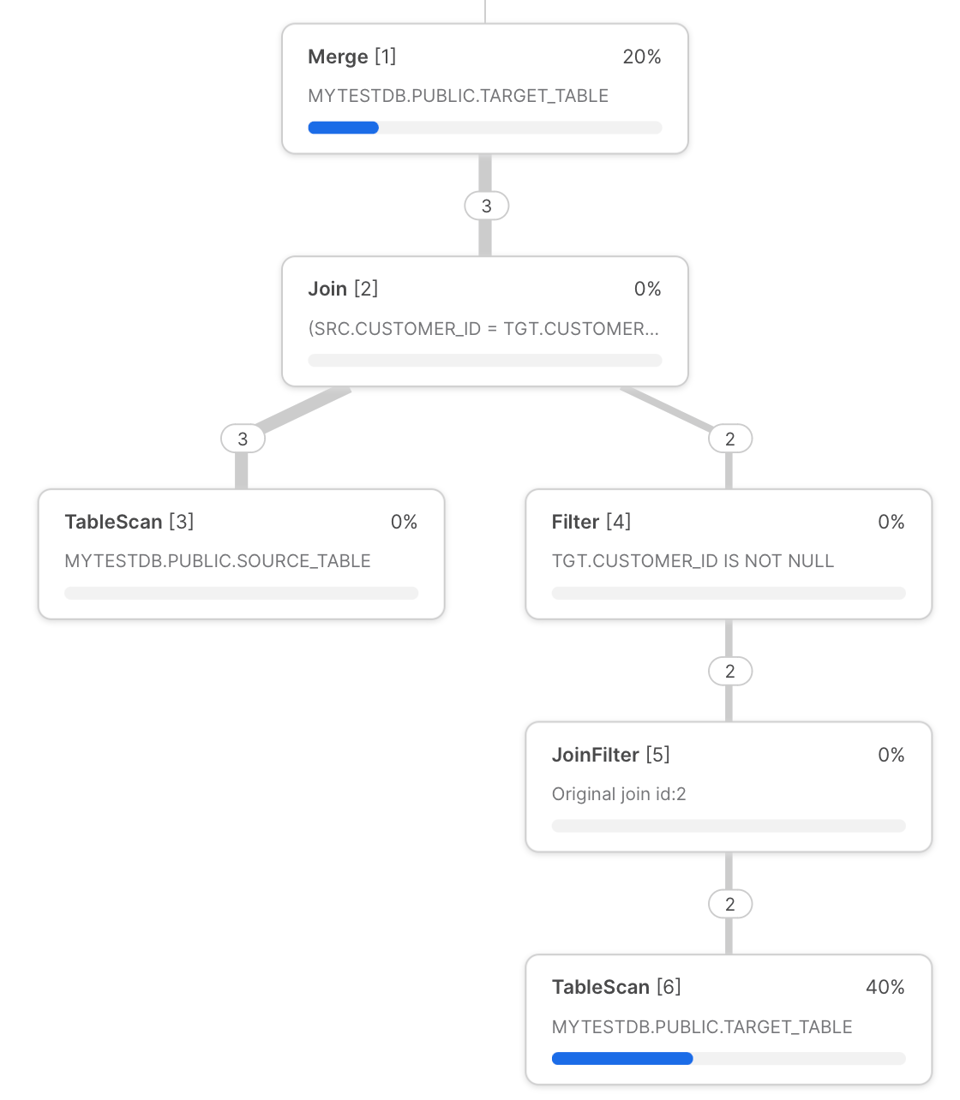
Anhand dieses Profils lassen sich potenzielle Engpässe gut veranschaulichen:
- Jede MERGE-Query beginnt mit einem Scan der Zieltabelle – einer der zeitintensivsten Schritte überhaupt. Um diese Zeit zu reduzieren, sollten Sie die Zieltabelle nach einer Spalte filtern, nach der sie sauber geclustert ist. Damit aktivieren Sie das Query Pruning und verhindern, dass Snowflake unnötige Micro-Partitionen scannt. Weiter unten im Beitrag zeigen wir, wie sich das mit dynamischem Pruning erreichen lässt.
- Direkt vor dem
MERGEwerden die Tabellen perLEFT OUTER JOIN(wenn eineNON MATCHED-Klausel vorhanden ist) oder perINNER JOIN(nur beiMATCHED-Klausel) verknüpft. Wie bei Joins üblich sollten Sie Zeilenexplosionen wo immer möglich vermeiden – sie führen wegen hoher Speicheranforderungen schnell zu Spillage auf die Festplatte. - Eine Ursache schwacher JOIN-Performance kann eine suboptimale Join-Reihenfolge sein, die der Snowflake-Optimizer gewählt hat. Mit der manuellen Join-Steuerung können Sie Snowflake zu einer anderen Reihenfolge zwingen.
- Setzen Sie Range-Join-Optimierungen ein, wenn die Join-Bedingung ein Non-Equi-Join ist.
- Stellen Sie sicher, dass die Quelltabelle eindeutige Schlüsselspalten für den Join hat – sonst erhalten Sie eine Fehlermeldung, es sei denn, Sie aktivieren das non-deterministische Verhalten.
- Bei der finalen MERGE-Operation an der Spitze des Query-Plans lässt sich die Zeitverteilung der zugrunde liegenden Schritte leider nicht weiter aufschlüsseln. Der Zeitaufwand hierfür ist proportional zur Anzahl und zum Volumen der geschriebenen Dateien und Daten.
Wie Snowflakes Architektur MERGE beeinflusst
Wie in einem früheren Beitrag beschrieben, basiert Snowflakes Architektur auf getrennten Schichten für Storage, Compute und Cloud Services. Da der Storage-Layer auf unveränderlichen Dateien – sogenannten Micro-Partitionen – aufsetzt, sind weder partielle Updates noch das Anhängen an bestehende Dateien möglich. Statements wie Insert, Update oder Delete lösen daher ein vollständiges Überschreiben 3 (bzw. Neuschreiben) dieser Dateien aus.
Bei jeder Tabellenänderung passieren zwei Dinge gleichzeitig: Snowflake behält gemäß der Time-Travel-Konfiguration 4 eine Kopie der alten Daten, und die aktualisierte Tabelle wird durch Neuschreiben aller nötigen Dateien gespeichert.
Genauer gesagt besteht eine Tabelle aus Metadaten-Pointern, die festlegen, welche Micro-Partitionen zu einem bestimmten Zeitpunkt gültig sind. Snowflake nennt das eine Table Version, die ihrerseits aus einem System-Timestamp, einer Menge von Micro-Partitionen und Partition-Level-Statistiken 5 besteht.
- INSERT bedeutet im Kern, dass neue Micro-Partitionen hinzukommen. Über die gängigen Strategien hinaus – passendes Warehouse-Sizing und der Verzicht darauf, Snowflake als Hochfrequenz-Ingest-Plattform für OLTP-Aufgaben zu nutzen – gibt es hier kaum Spielraum für weitere Optimierungen.
- UPDATEs sind kniffliger: Im ersten Schritt müssen alle Micro-Partitionen gescannt werden, was bei großen Tabellen sehr teuer werden kann. Idealerweise betreffen die Änderungen ein schmales Datumsintervall, sodass nicht zahlreiche Dateien neu geschrieben werden müssen. Die zuvor besprochenen Stolperfallen beim Joinen von Tabellen sind auch hier hilfreich.
Alternativen zu MERGE
Neben MERGE gibt es einige bekannte manuelle Optionen für das Laden von Daten. Wenn Atomarität nicht erforderlich ist und Sie Daten komplett ersetzen, ist DELETE + INSERT eine sinnvolle Strategie. Sie müssen dabei selbst die zu löschenden Datensätze identifizieren und anschließend die neuen Datensätze in zwei separaten Statements einfügen. Schlägt das INSERT-Statement fehl, bleibt die Tabelle in einem Zustand mit fehlenden Datensätzen zurück. Alternativ lassen sich UPDATE und INSERT getrennt ausführen. Da aber jedes Statement die Daten der Zieltabelle separat scannen muss, verbraucht das am Ende mehr Compute-Credits.
Weitere MERGE-Beispiele
Schauen wir uns das MERGE-Konzept anhand einiger fortgeschrittener Beispiele genauer an. Dafür verwenden wir die Orders-Tabelle aus dem Dataset tpch_sf1000.
-- Table Size: 1.6 billion records
CREATE OR REPLACE TABLE mytestdb.public.orders AS
SELECT
o_orderkey,
o_custkey,
o_orderstatus,
o_totalprice,
o_orderdate,
o_orderpriority,
o_clerk,
o_comment,
o_shippriority
FROM
snowflake_sample_data.tpch_sf1000.orders
ORDER BY o_orderdate -- sorting by order
Code anzeigen
Durch das ORDER BY o_orderdate wird die orders-Tabelle nach dieser Spalte sauber geclustert.
Um typische Szenarien beim Datenladen zu simulieren, betrachten wir zwei Beispiele mit nahezu identischen MERGE-Statements.
MERGE: Update-Werte aus einer einzelnen Micro-Partition
Im ersten Beispiel führen wir per MERGE einen Quelldatensatz mit 620.000 Einträgen aus einem einzigen Tag zusammen.
-- Case 1
-- Values from a single order date / micro-paritition
-- Output: ~620k rows
-- Execution time: ~17s to run
CREATE OR REPLACE TEMPORARY TABLE source_table AS
SELECT
-- Primary Keys to Match Both Tables
-- To cover both INSERT and UPDATE cases
IFF(o_orderkey % 2 = 1, o_orderkey, o_orderkey + 99999999999) AS o_orderkey,
o_orderdate,
o_custkey,
o_orderstatus,
o_totalprice,
o_orderpriority,
Code anzeigen
Die Query läuft in nur 15–17 Sekunden durch. Die Hälfte der Daten wird aktualisiert, die andere überschrieben. Dabei führt die Query einen Full Scan der Zieltabelle aus – das Query Pruning ist also inaktiv.
Eine aktualisierte Zeile schreibt die komplette Micro-Partition neu
Um zu zeigen, was unter der Haube passiert, wenn viele Micro-Partitionen betroffen sind, erzeugen wir einen weiteren Quelldatensatz mit demselben Datenvolumen – rund 620.000 Zeilen –, diesmal aber verteilt über das gesamte Jahr 1992 statt nur an einem einzigen Tag.
-- Case 2
-- Values from a single order date / micro-paritition
-- Output: ~630k rows
-- Execution time: ~95s to run
CREATE OR REPLACE TEMPORARY TABLE source_table AS
SELECT
-- Primary Keys to Match Both Tables
IFF(o_orderkey % 2 = 1, o_orderkey, o_orderkey + 99999999999) AS o_orderkey
, o_orderdate
-- Other keys
, o_custkey
, o_orderstatus
, o_totalprice
Code anzeigen
Diese Query benötigt rund 95 Sekunden! Trotz gleicher Quelltabellengröße läuft sie 4,5-mal länger.
Vergleich der beiden MERGE-Beispiele
Schauen wir uns die Statistiken aus dem Query-Plan an, um zu verstehen, warum das zweite Beispiel so viel länger braucht.
| Gescannte Bytes | Geschriebene Zeilen | Ausführungszeit | Gescannte Partitionen/gesamt | |
|---|---|---|---|---|
| Einzelne Micro-Partition | 6,20 GB | 42 MB | ~17s | 1 |
| Gleichmäßig verteilte Partitionen | ~12 GB | 5,91 GB | ~95s | 1 |
Wie eingangs erwähnt: Selbst wenn Sie nur eine einzige Zeile ändern, muss die gesamte Micro-Partition, zu der die Zeile gehört, neu geschrieben werden. Da die Quelltabelle Daten gleichmäßig über das Jahr 1992 verteilt enthielt, müssen wir rund 6 GB Daten neu schreiben – fast 15 % der Zieltabellengröße!
In vielerlei Hinsicht haben Sie diese Situation kaum in der Hand. Müssen Sie Daten über ein ganzes Jahr aktualisieren, bleiben Ihnen wenig Optionen.
Beide oben gezeigten Beispiele erfordern einen Full Scan der Zieltabelle, um zu ermitteln, welche Micro-Partitionen aktualisiert werden müssen. Sehen wir uns eine Optimierungstechnik namens dynamisches Query Pruning an, die hier die Performance verbessern kann.
Bessere MERGE-Performance durch dynamisches Pruning
Verbringt Ihre MERGE-Query viel Zeit mit dem Scannen der Zieltabelle, lässt sich die Performance häufig verbessern, indem Sie Query Pruning erzwingen – damit verhindern Sie, dass unnötige Daten aus der Zieltabelle gescannt werden.
Betrachten wir ein Beispiel, in dem nur 3 Datensätze aktualisiert werden müssen, die auf zwei verschiedene Tage fallen: 1998-01-01 und 1998-02-25.
-- Source table
CREATE OR REPLACE TEMPORARY TABLE orders_to_update AS (
SELECT
2606029510 AS o_orderkey
, 0 AS o_totalprice
, DATE '1998-02-25' AS o_orderdate
UNION ALL
SELECT
3135064003 AS o_orderkey
, 0 AS o_totalprice
, DATE '1998-02-25' AS o_orderdate
UNION ALL
SELECT
5602847265 AS o_orderkey
Code anzeigen
Wie oben gesehen, gleicht ein normaler MERGE die Datensätze einfach über o_orderkey ab. Da o_orderkey ein zufälliger Schlüssel ist, ist die Ziel-Orders-Tabelle nicht nach dieser Spalte geclustert – der MERGE muss also die gesamte Zieltabelle scannen, um die Micro-Partitionen mit den drei zu aktualisierenden o_orderkey-Werten zu finden.
-- REGULAR MERGE
CREATE OR REPLACE TABLE orders_merge CLONE orders;
MERGE INTO orders_merge AS target
USING orders_to_update AS source
ON
target.o_orderkey = source.o_orderkey
WHEN MATCHED THEN
UPDATE SET
target.o_totalprice = source.o_totalprice
;
Um den Scan aller Micro-Partitionen in der Zieltabelle zu vermeiden, können wir uns zunutze machen, dass die orders-Zieltabelle nach o_orderdate geclustert ist. Damit liegen alle Bestellungen mit demselben Datum in denselben Micro-Partitionen. Wir erweitern unser MERGE-Statement um eine zusätzliche Join-Klausel auf die Spalte o_orderdate. Bei der Ausführung muss Snowflake dann nur noch die Micro-Partitionen mit Bestellungen der Daten 1998-01-01 und 1998-02-25 durchsuchen.
Das nennt man dynamisches Pruning, weil Snowflake während der Query-Ausführung – nachdem die Werte aus der Quelltabelle gelesen wurden – entscheidet, welche Micro-Partitionen geprunt (also vom Scan ausgeschlossen) werden.
-- PRUNED MERGE
CREATE OR REPLACE TABLE orders_merge CLONE orders;
MERGE INTO orders_merge AS target
USING orders_to_update AS source
ON
target.o_orderkey = source.o_orderkey AND
target.o_orderdate = source.o_orderdate -- PRUNING COLUMN
WHEN MATCHED THEN
UPDATE SET
target.o_totalprice = source.o_totalprice
;
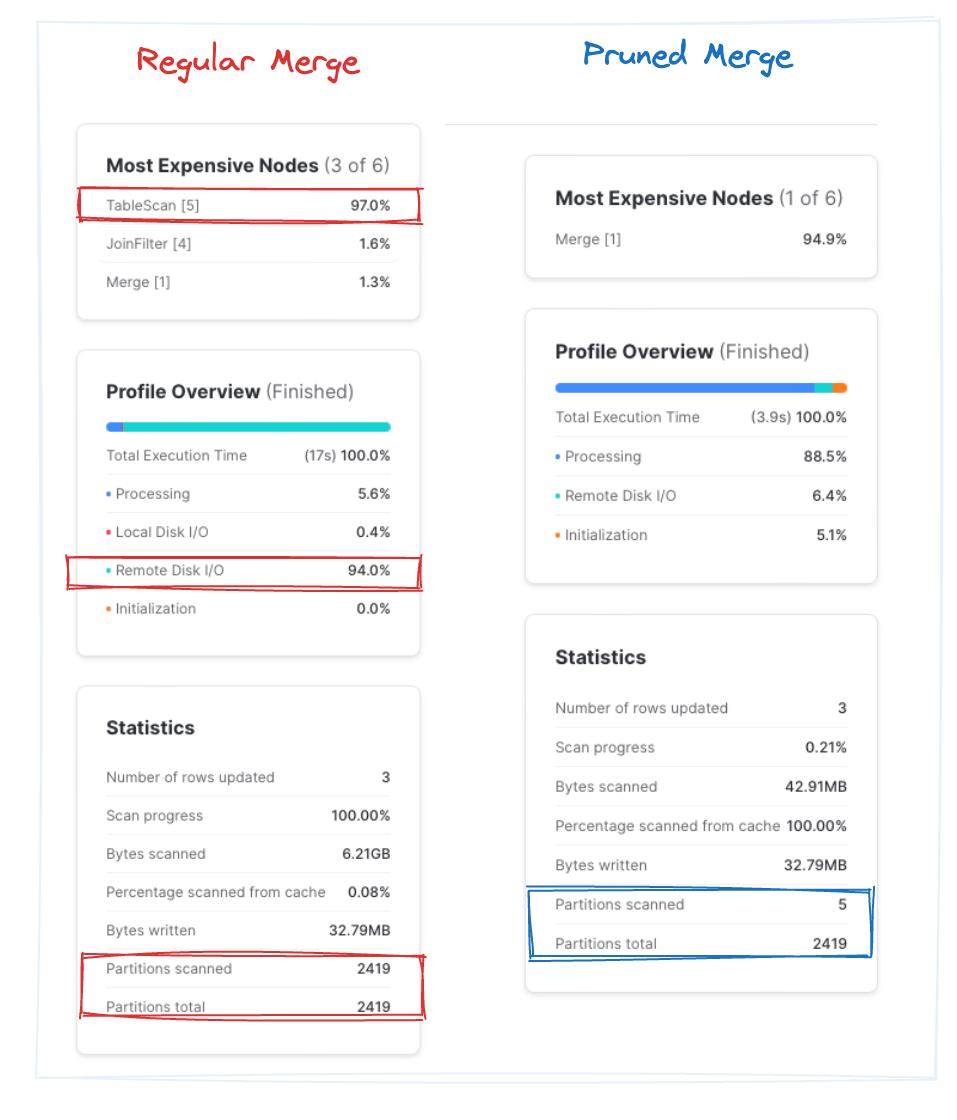
Während der "reguläre Merge" über drei Durchläufe im Schnitt rund 9,5 Sekunden braucht, ist der "geprunte Merge" in rund 4 Sekunden fertig. Beachten Sie: In der geprunten Query scannt Snowflake nur etwa 0,2 % der Gesamtpartitionen. Das entspricht rund einer 2-fachen Verbesserung – allein dadurch, dass unnötige Dateiblöcke übersprungen werden. Bingo!
Abschließende Gedanken
MERGE ist ein eleganter Weg, um Daten in Snowflake zu aktualisieren und einzufügen. Wer Snowflakes Architektur mit ihren unveränderlichen Micro-Partition-Dateien versteht, weiß auch, warum manche MERGE-Operationen lange dauern können, obwohl nur wenige Datensätze geändert werden. Wir haben außerdem gesehen, wie sich die MERGE-Performance verbessern lässt, indem die Anzahl der in der Zieltabelle zu scannenden Micro-Partitionen minimiert wird.
Wir hoffen, der Beitrag war hilfreich – danke fürs Lesen!
Anmerkungen
2 BigQuery merge statement syntax
3 The Snowflake Elastic Data Warehouse
4 What's the Difference? Incremental Processing with Change Queries in Snowflake
5 Zero-Copy Cloning in Snowflake and Other Database Systems
Andrey Bystrov · Analytics Engineer bei Deliveroo
Andrey ist ein erfahrener Datenpraktiker und arbeitet derzeit als Analytics Engineer bei Deliveroo. Datenmodellierung und SQL-Optimierung sind seine Leidenschaft. Mit seinem tiefen Verständnis der Snowflake-Plattform hilft er seinem Team, performante und kosteneffiziente Datenpipelines zu bauen. Seine Erkenntnisse teilt Andrey regelmäßig mit der Community.