L'istruzione MERGE è un potente strumento multifunzione che consente di eseguire upsert ed eliminare righe in un'unica operazione. Invece di gestire le pipeline di caricamento dati tramite istruzioni separate ma interconnesse, MERGE permette di semplificarle e controllarle in modo significativo con una singola istruzione atomica. In questo articolo vi guidiamo attraverso le funzionalità e i fondamenti architetturali di MERGE in Snowflake e analizziamo come migliorare le prestazioni delle query MERGE.
Cos'è MERGE in Snowflake?
La funzionalità MERGE è disponibile da molto tempo, ben prima che l'era dei database colonnari fosse nel pieno della sua diffusione. Conosciuta anche come upsert (insert e update), ci aiuta a gestire correttamente le modifiche, garantendo la coerenza delle pipeline di dati. I moderni job ETL tendono a gestire flussi continui di dati in modo incrementale, quindi MERGE non può essere trascurato. Copre quasi tutti i casi d'uso, permettendo di eseguire operazioni di delete, insert e update in un'unica transazione. Più script che modificano la stessa tabella in parallelo non saranno più un problema.
A differenza di un'istruzione UPDATE, MERGE può elaborare più condizioni di corrispondenza in sequenza per completare update o delete. Tuttavia, per i record non corrispondenti, è possibile solo inserire un blocco di dati dalla sorgente alla destinazione. Attualmente, a differenza di Databricks 1 e Google BigQuery 2, Snowflake non consente di specificare il comportamento quando vengono soddisfatte condizioni parziali, in particolare per le righe non corrispondenti nella tabella sorgente.
Vediamo la sintassi. Per utilizzare il comando MERGE è necessario fornire i seguenti argomenti:
- Tabella sorgente: la tabella che contiene i dati da unire.
- Tabella di destinazione: la tabella in cui sincronizzare i dati.
- Espressione di join: i campi chiave di entrambe le tabelle che le collegano tra loro.
- Clausola matched: almeno una clausola (non-)matched che determini il risultato atteso.
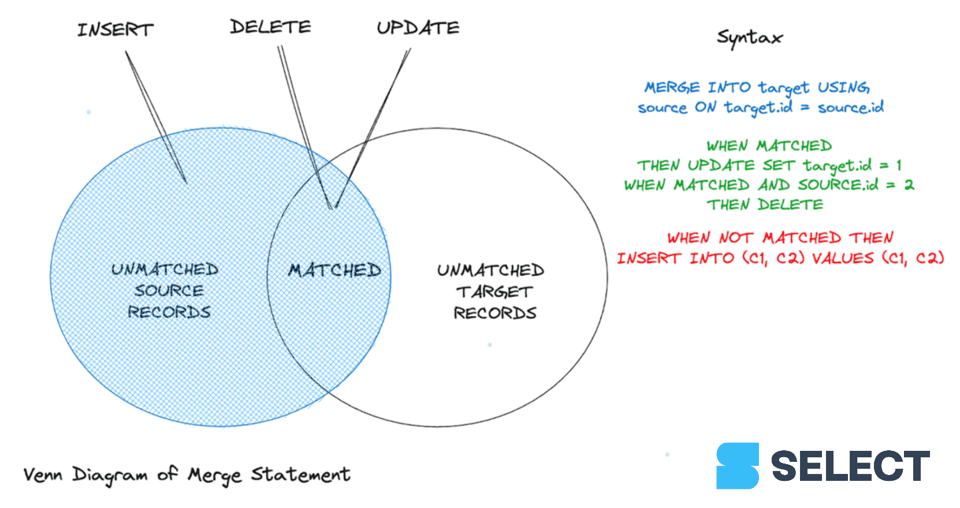
Usare MERGE per aggiornare lo stato attivo dei clienti
Partiamo da un esempio: una tabella clienti che vogliamo aggiornare a partire da una tabella sorgente contenente nuovi dati. Useremo customer_id per far corrispondere i record delle due tabelle. Per mostrare come MERGE gestisce sia gli update sia gli insert, i dati delle tabelle generate si sovrappongono parzialmente.
-- Creating Tables
CREATE OR REPLACE TABLE target_table (
customer_id NUMBER,
is_active BOOLEAN,
updated_date DATE
)
;
CREATE OR REPLACE TABLE source_table (
customer_id NUMBER,
is_active BOOLEAN
)
;
-- Inserting test values
Espandi il codice
Abbiamo quindi eseguito un upsert che ha aggiornato 2 righe (ID: 1, 2) e inserito 1 nuova riga (ID: 4). Il cliente rimanente (ID: 3) resta invariato perché non esistono righe corrispondenti nella tabella sorgente. Questo semplice esempio mostra le funzionalità di base dell'operatore e come può essere utilizzato nei vostri progetti.
Andiamo avanti e vediamo cosa succede dietro le quinte.
Comprendere e migliorare le prestazioni delle query MERGE
Di seguito è riportato il query profile di Snowflake per la query MERGE sui "customers" mostrata sopra.
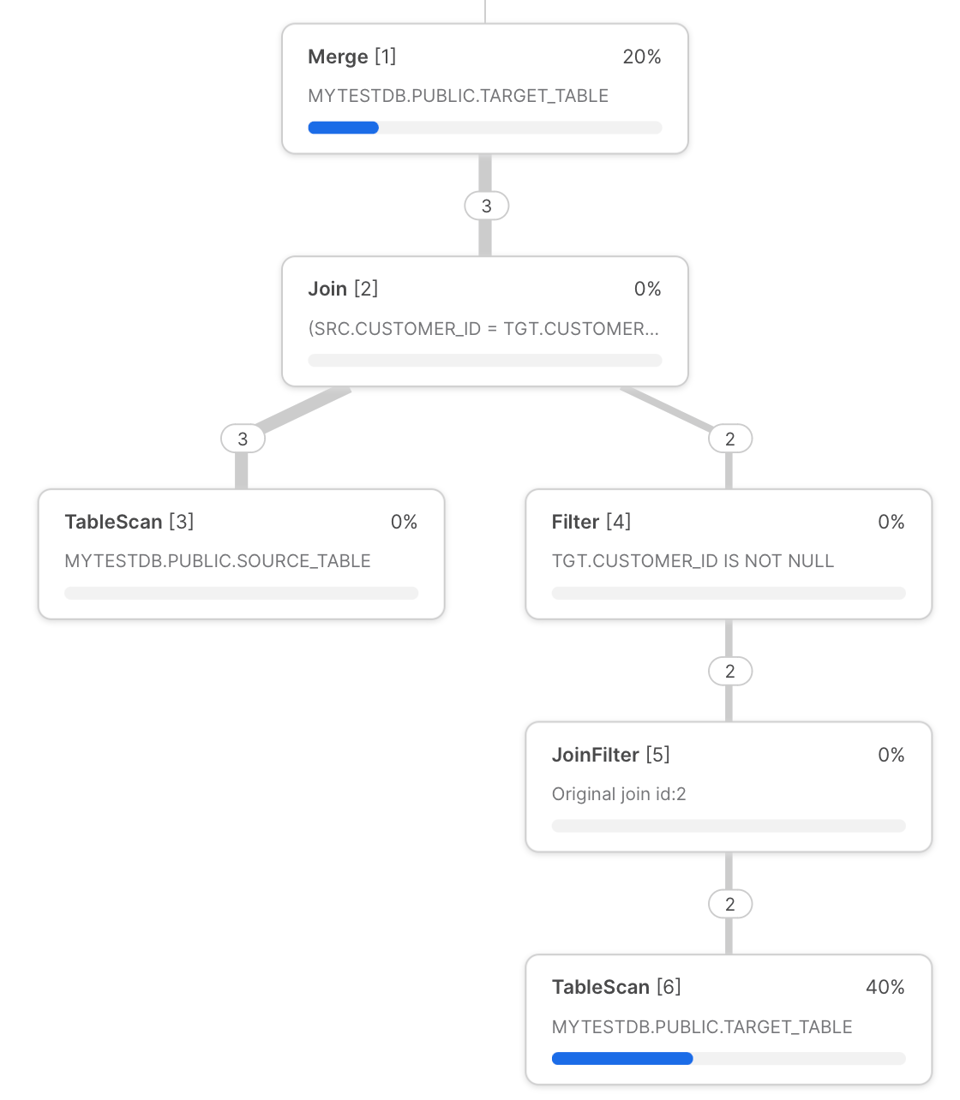
Possiamo usare questo profilo per illustrare i potenziali colli di bottiglia:
- Ogni volta che si esegue una query MERGE, questa parte dalla scansione della tabella di destinazione. È uno dei passaggi più dispendiosi in termini di tempo. Per ridurre il tempo di scansione dei dati, occorre filtrare la tabella di destinazione su una delle colonne in base alle quali è ben clusterizzata. In questo modo si abilita il query pruning, che evita a Snowflake di scansionare micro-partizioni non necessarie. Più avanti nell'articolo mostreremo un modo per ottenere questo risultato tramite il pruning dinamico.
- Subito prima di
MERGE, le tabelle vengono unite tramiteLEFT OUTER JOIN(se è presente la clausolaNON MATCHED) oINNER JOIN(solo per la clausolaMATCHED). Come sempre con i join, è bene evitare la cosiddetta row explosion ove possibile, poiché tende a causare disk spillage a causa degli eccessivi requisiti di memoria. - Una delle cause di scarse prestazioni del JOIN può essere la scelta di un ordine di join subottimale da parte dell'optimizer di Snowflake. È possibile valutare l'opzione di controllo manuale del join per forzare Snowflake a utilizzare un ordine diverso.
- Sfruttate le ottimizzazioni dei range join se la condizione di join comporta un non-equi join.
- Assicuratevi che la tabella sorgente abbia campi chiave univoci al momento del join, altrimenti riceverete un messaggio di errore, a meno che non attiviate il comportamento non deterministico.
- Nell'operazione MERGE finale, in cima al query plan, purtroppo non è possibile approfondire il tempo di allocazione dei singoli passaggi sottostanti. Il tempo dedicato a questo step sarà proporzionale al numero e al volume di file e dati scritti.
L'impatto dell'architettura di Snowflake su MERGE
Come discusso in un articolo precedente, l'architettura di Snowflake prevede livelli separati di storage, compute e cloud services. Poiché il livello di storage di Snowflake utilizza file immutabili chiamati micro-partizioni, non sono possibili né aggiornamenti parziali né append ai file esistenti. Di conseguenza, istruzioni come insert, update o delete innescano la riscrittura completa 3 di questi file.
Ogni volta che si modificano i dati di una tabella, accadono due cose contemporaneamente: Snowflake mantiene una copia dei dati precedenti e la conserva in base alla configurazione di Time Travel 4, mentre la tabella aggiornata viene salvata riscrivendo tutti i file necessari.
Più precisamente, una tabella è costituita da puntatori ai metadati che determinano quali micro-partizioni sono valide in un dato momento. Snowflake la chiama infatti table version, che a sua volta è composta da un system timestamp, un insieme di micro-partizioni e statistiche a livello di partizione 5.
- INSERT comporta principalmente l'aggiunta di nuove micro-partizioni. Oltre alle strategie comunemente adottate, come dimensionare correttamente il warehouse per una configurazione ottimale ed evitare di utilizzare Snowflake come piattaforma di ingest ad alta frequenza per carichi OLTP, è improbabile che ci sia molto margine per ulteriori miglioramenti in questo step.
- Gli UPDATE sono più complessi: come primo passo richiedono la scansione di tutte le micro-partizioni, operazione che può diventare molto costosa per tabelle di grandi dimensioni. L'ideale è che i dati aggiornati ricadano in un intervallo di date ristretto, così da non dover riscrivere più file. Evitare le insidie comuni dei join tra tabelle, di cui abbiamo parlato in precedenza, è utile anche in questo caso.
Alternative a MERGE
Oltre a MERGE, esistono un paio di noti approcci manuali a cui ricorrere per le proprie esigenze di caricamento dati. Se l'atomicità non è un requisito e si tratta di una sostituzione completa dei dati, DELETE + INSERT è una strategia praticabile. Spetta all'utente individuare i record da eliminare e poi inserire i nuovi record in due istruzioni separate. Se l'istruzione INSERT fallisce, la tabella resterà in uno stato in cui mancano dei record. È anche possibile eseguire le istruzioni UPDATE e INSERT separatamente. Tuttavia, poiché ciascuna istruzione deve eseguire una scansione a sé dei dati nella tabella di destinazione, il risultato sarà un maggior consumo di compute credits.
Altri esempi di utilizzo di MERGE
Continuiamo a esplorare il concetto di MERGE con un paio di esempi più avanzati. Per questi esempi useremo la tabella degli ordini del dataset tpch_sf1000.
-- Table Size: 1.6 billion records
CREATE OR REPLACE TABLE mytestdb.public.orders AS
SELECT
o_orderkey,
o_custkey,
o_orderstatus,
o_totalprice,
o_orderdate,
o_orderpriority,
o_clerk,
o_comment,
o_shippriority
FROM
snowflake_sample_data.tpch_sf1000.orders
ORDER BY o_orderdate -- sorting by order
Espandi il codice
Aggiungendo l'istruzione ORDER BY o_orderdate, la tabella orders risulterà ben clusterizzata rispetto a questa colonna.
Per simulare scenari di caricamento dati più realistici, analizziamo due esempi di istruzioni MERGE quasi identiche.
MERGE, aggiornamento di valori in una singola micro-partizione
In questo primo esempio eseguiremo un MERGE con un dataset sorgente contenente 620.000 record relativi a un singolo giorno.
-- Case 1
-- Values from a single order date / micro-paritition
-- Output: ~620k rows
-- Execution time: ~17s to run
CREATE OR REPLACE TEMPORARY TABLE source_table AS
SELECT
-- Primary Keys to Match Both Tables
-- To cover both INSERT and UPDATE cases
IFF(o_orderkey % 2 = 1, o_orderkey, o_orderkey + 99999999999) AS o_orderkey,
o_orderdate,
o_custkey,
o_orderstatus,
o_totalprice,
o_orderpriority,
Espandi il codice
La query impiega solo 15-17 secondi. Metà dei dati viene aggiornata, l'altra metà sovrascritta. Questa query esegue una scansione completa della tabella di destinazione, il che significa che il query pruning non è attivo.
Una sola riga aggiornata riscrive completamente la micro-partizione
Per mostrare cosa accade dietro le quinte quando entrano in gioco un numero significativo di micro-partizioni, generiamo un altro dataset sorgente con lo stesso volume di dati, circa 620.000 righe, ma questa volta i dati copriranno un intervallo di date dell'anno 1992 anziché un singolo giorno.
-- Case 2
-- Values from a single order date / micro-paritition
-- Output: ~630k rows
-- Execution time: ~95s to run
CREATE OR REPLACE TEMPORARY TABLE source_table AS
SELECT
-- Primary Keys to Match Both Tables
IFF(o_orderkey % 2 = 1, o_orderkey, o_orderkey + 99999999999) AS o_orderkey
, o_orderdate
-- Other keys
, o_custkey
, o_orderstatus
, o_totalprice
Espandi il codice
Questa query impiega circa 95 secondi! A parità di dimensioni della tabella sorgente, richiede 4,5 volte più tempo!
Confronto tra i due esempi di MERGE
Confrontiamo le statistiche del query plan per capire perché il secondo esempio impiega molto più tempo.
| Byte scansionati | Righe scritte | Tempo di esecuzione | Partizioni scansionate/totale | |
|---|---|---|---|---|
| Singola micro-partizione | 6,20 GB | 42 MB | ~17s | 1 |
| Partizioni distribuite uniformemente | ~12 GB | 5,91 GB | ~95s | 1 |
Come detto, anche modificando una sola riga in una tabella, è necessario riscrivere per intero la micro-partizione a cui apparteneva. Poiché la tabella sorgente conteneva dati distribuiti uniformemente nell'anno 1992, dobbiamo riscrivere circa 6 GB di dati, pari quasi al 15% della dimensione della tabella di destinazione!
Per molti aspetti, questa situazione può sfuggire al vostro pieno controllo. Se dovete aggiornare i dati di un anno intero, le alternative non sono molte.
Entrambi gli esempi visti sopra comportano una scansione completa della tabella di destinazione per determinare quali micro-partizioni aggiornare. Vediamo una tecnica di ottimizzazione nota come dynamic query pruning, che può aiutare a migliorare le prestazioni in questi casi.
Migliorare le prestazioni di MERGE con il pruning dinamico
Se la vostra query MERGE dedica molto tempo alla scansione della tabella di destinazione, è possibile migliorarne le prestazioni forzando il query pruning, che impedirà di scansionare dati non necessari nella tabella di destinazione.
Consideriamo un caso in cui dobbiamo aggiornare solo 3 record diversi, relativi a due giorni distinti: 1998-01-01 e 1998-02-25.
-- Source table
CREATE OR REPLACE TEMPORARY TABLE orders_to_update AS (
SELECT
2606029510 AS o_orderkey
, 0 AS o_totalprice
, DATE '1998-02-25' AS o_orderdate
UNION ALL
SELECT
3135064003 AS o_orderkey
, 0 AS o_totalprice
, DATE '1998-02-25' AS o_orderdate
UNION ALL
SELECT
5602847265 AS o_orderkey
Espandi il codice
Come abbiamo visto, un MERGE standard farà semplicemente corrispondere i record su o_orderkey. Dato che o_orderkey è una chiave casuale, la tabella di destinazione orders non sarà clusterizzata su questa colonna e quindi l'operazione MERGE dovrà scansionare l'intera tabella di destinazione per trovare le micro-partizioni che contengono i tre valori di o_orderkey che vogliamo aggiornare.
-- REGULAR MERGE
CREATE OR REPLACE TABLE orders_merge CLONE orders;
MERGE INTO orders_merge AS target
USING orders_to_update AS source
ON
target.o_orderkey = source.o_orderkey
WHEN MATCHED THEN
UPDATE SET
target.o_totalprice = source.o_totalprice
;
Per evitare di scansionare tutte le micro-partizioni nella tabella di destinazione, possiamo sfruttare il fatto che la tabella di destinazione orders è clusterizzata su o_orderdate. Questo significa che tutti gli ordini con la stessa data saranno memorizzati nelle stesse micro-partizioni. Possiamo modificare la nostra istruzione MERGE aggiungendo un'ulteriore clausola di join sulla colonna o_orderdate. Durante l'esecuzione della query, Snowflake dovrà ora cercare solo nelle micro-partizioni contenenti ordini con date 1998-01-01 e 1998-02-25!
Questo è noto come pruning dinamico, perché Snowflake determina quali micro-partizioni escludere (per evitare di scansionarle) durante l'esecuzione della query, dopo aver letto i valori nella tabella sorgente.
-- PRUNED MERGE
CREATE OR REPLACE TABLE orders_merge CLONE orders;
MERGE INTO orders_merge AS target
USING orders_to_update AS source
ON
target.o_orderkey = source.o_orderkey AND
target.o_orderdate = source.o_orderdate -- PRUNING COLUMN
WHEN MATCHED THEN
UPDATE SET
target.o_totalprice = source.o_totalprice
;
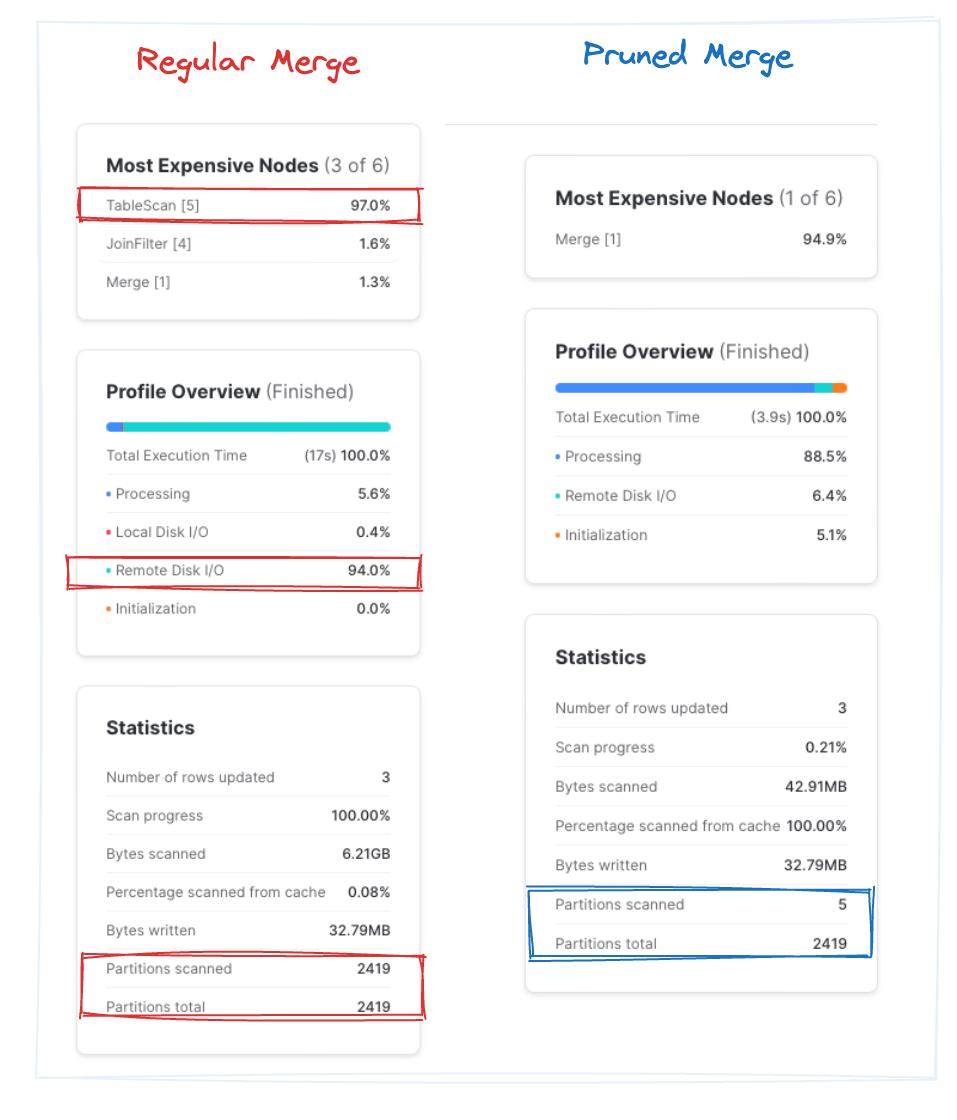
Mentre la query "regular merge" impiega in media circa 9,5 secondi su tre esecuzioni, la "pruned merge" si completa in circa 4 secondi. Da notare che, nella query con pruning, Snowflake ha scansionato rapidamente circa lo 0,2% delle partizioni totali. Si tratta di un miglioramento di circa 2x, ottenuto saltando blocchi di file non necessari. Bingo!
Considerazioni finali
MERGE è un ottimo modo per gestire con eleganza l'aggiornamento e l'inserimento di dati in Snowflake. Comprendendo l'architettura di Snowflake e i suoi file di micro-partizioni immutabili, si capisce perché alcune operazioni MERGE possano richiedere molto tempo pur aggiornando solo pochi record. Abbiamo inoltre visto come le prestazioni di MERGE possano essere migliorate riducendo al minimo il numero di micro-partizioni da scansionare nella tabella di destinazione.
Speriamo che l'articolo vi sia stato utile, grazie per la lettura!
Note
2 Sintassi dell'istruzione merge di BigQuery
3 The Snowflake Elastic Data Warehouse
4 What's the Difference? Incremental Processing with Change Queries in Snowflake
5 Zero-Copy Cloning in Snowflake and Other Database Systems
Andrey Bystrov·Analytics Engineer presso Deliveroo
Andrey è un professionista dei dati con grande esperienza, attualmente Analytics Engineer presso Deliveroo. Coltiva una forte passione per il data modelling e l'ottimizzazione SQL. Ha una conoscenza approfondita della piattaforma Snowflake e mette questa competenza al servizio del suo team per costruire pipeline di dati performanti e cost-effective. Appassionato della materia, condivide regolarmente con la community quello che impara.