El comando MERGE es una potente herramienta multipropósito que permite hacer upsert y eliminar filas a la vez. En lugar de gestionar pipelines de carga de datos mediante sentencias separadas pero interrelacionadas, con MERGE se logra simplificar y controlar todo a través de una única sentencia atómica. En este post repasamos las características y los fundamentos arquitectónicos de MERGE en Snowflake, y vemos cómo mejorar el rendimiento de las consultas con MERGE.
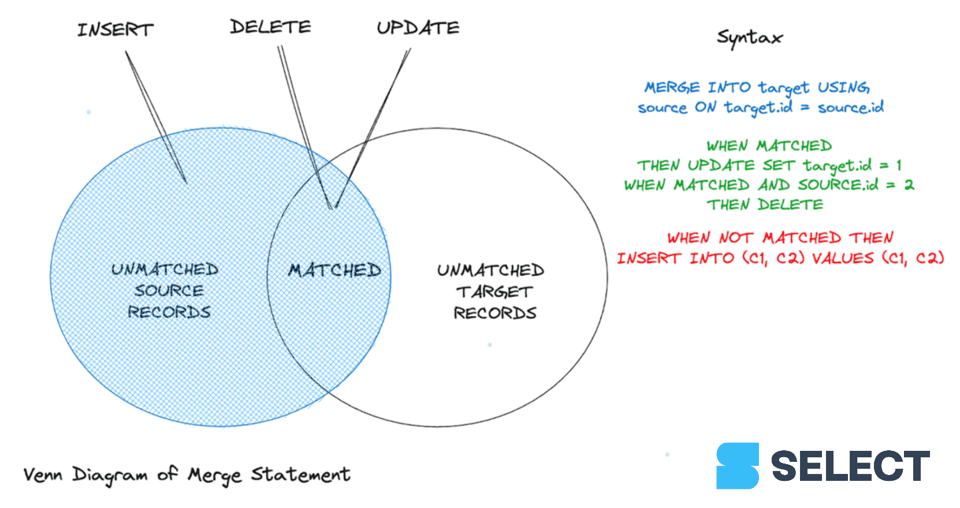
¿Qué es MERGE en Snowflake?
La funcionalidad MERGE existe desde hace mucho tiempo, incluso desde antes de que la era de las bases de datos columnares estuviera en pleno auge. También conocida como upsert (insert y update), ayuda a manejar los cambios de forma correcta y a mantener la consistencia de los pipelines de datos. Los jobs ETL modernos suelen procesar flujos interminables de datos de forma incremental, así que MERGE no se puede pasar por alto. Cubre prácticamente todos los casos de uso y permite ejecutar operaciones de delete, insert y update en una única transacción. Tener varios scripts modificando la misma tabla en paralelo ya no será un dolor de cabeza.
A diferencia de una sentencia UPDATE, MERGE puede procesar varias condiciones de coincidencia, una tras otra, para completar updates o deletes. Sin embargo, para los registros no coincidentes solo se puede insertar una porción de datos desde el origen hacia el destino. Actualmente, a diferencia de Databricks 1 y Google BigQuery 2, Snowflake no permite especificar el comportamiento cuando se cumplen condiciones parciales, en particular para las filas no coincidentes en la tabla de origen.
Veamos la sintaxis en detalle. Para usar el comando MERGE hay que pasar los siguientes argumentos:
- Tabla de origen: la tabla que contiene los datos que se van a fusionar.
- Tabla de destino: la tabla destino donde se deben sincronizar los datos.
- Expresión de join: los campos clave de ambas tablas que las vinculan entre sí.
- Cláusula matched: al menos una cláusula (non-)matched que determine el resultado esperado.
Usar MERGE para actualizar el estado activo de clientes
Veamos primero un ejemplo de una tabla de clientes que queremos actualizar a partir de una tabla de origen con datos nuevos de clientes. Usaremos customer_id para hacer coincidir los registros de cada tabla. Para mostrar cómo MERGE maneja tanto los updates como los inserts, los datos generados en las tablas se superponen parcialmente.
-- Creating Tables
CREATE OR REPLACE TABLE target_table (
customer_id NUMBER,
is_active BOOLEAN,
updated_date DATE
)
;
CREATE OR REPLACE TABLE source_table (
customer_id NUMBER,
is_active BOOLEAN
)
;
-- Inserting test values
Expand Code
Entonces, hicimos un upsert que actualizó 2 filas (ID: 1, 2) e insertó 1 fila nueva (ID: 4). El cliente restante (ID: 3) queda intacto porque no tiene filas coincidentes en la tabla de origen. Este ejemplo sencillo muestra las características básicas del operador y cómo se puede usar en tu proyecto.
Avancemos y veamos qué ocurre por debajo.
Entender y mejorar el rendimiento de las consultas MERGE
A continuación se muestra el query profile de Snowflake para la consulta MERGE de "customers" del ejemplo anterior.
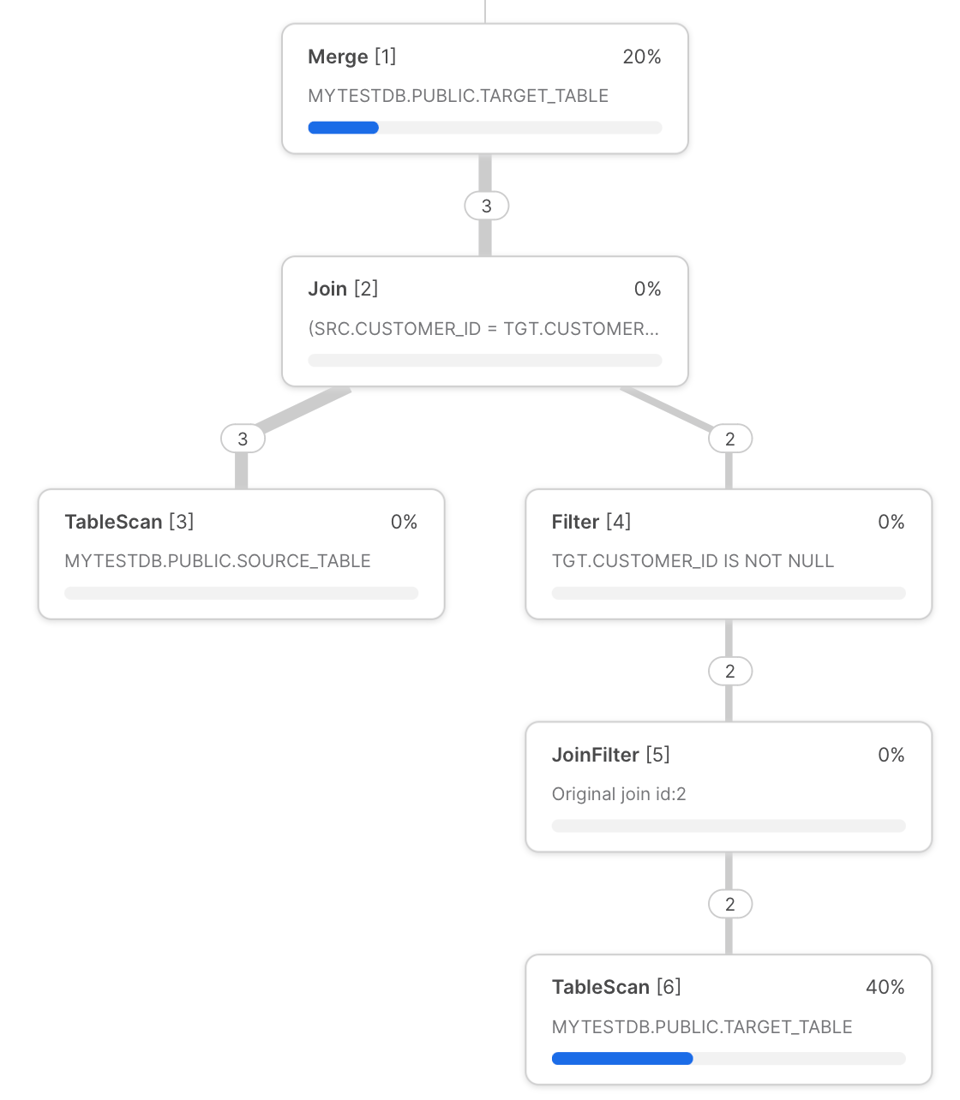
Podemos usar este profile para identificar posibles cuellos de botella:
- Cada vez que se ejecuta una consulta MERGE, lo primero que hace es escanear la tabla de destino. Este es uno de los pasos que más tiempo consume. Para reducir el tiempo de escaneo conviene filtrar la tabla de destino por una de las columnas en las que esté bien clusterizada. Así se habilita el pruning de consultas, que evita que Snowflake escanee micro-partitions innecesarias. Más adelante en el post mostraremos una forma de lograrlo mediante pruning dinámico.
- Justo antes del
MERGE, las tablas se unen medianteLEFT OUTER JOIN(si está presente la cláusulaNON MATCHED) oINNER JOIN(solo para la cláusulaMATCHED). Como suele ocurrir con los joins, conviene evitar la explosión de filas siempre que sea posible, ya que tiende a generar spill a disco por los excesivos requisitos de memoria. - Una causa del bajo rendimiento de un JOIN puede ser que el optimizador de Snowflake elija un orden de join subóptimo. Puedes explorar la opción de control manual del join para forzar a Snowflake a usar un orden distinto.
- Aprovecha las optimizaciones de range join si la condición de join involucra un non-equi join.
- Asegúrate de que la tabla de origen tenga campos clave únicos al hacer el join; de lo contrario, recibirás un mensaje de error, salvo que actives el comportamiento no determinista.
- En la operación final de MERGE, en la parte superior del plan de consulta, lamentablemente no se puede profundizar más en el tiempo asignado a los pasos subyacentes. El tiempo de este paso será proporcional al volumen de archivos y datos que se estén escribiendo.
El impacto de la arquitectura de Snowflake en MERGE
Como vimos en un post anterior, la arquitectura de Snowflake contempla capas separadas de almacenamiento, cómputo y servicios cloud. Dado que la capa de almacenamiento de Snowflake utiliza archivos inmutables llamados micro-partitions, no están disponibles ni las actualizaciones parciales ni los appends a archivos existentes. Por lo tanto, las sentencias de insert, update o delete disparan la sobrescritura 3 (o reescritura) completa de estos archivos.
Cada vez que se modifica una tabla ocurren dos eventos en simultáneo: Snowflake guarda una copia de los datos antiguos y los retiene según la configuración de Time Travel 4, y la tabla actualizada se almacena reescribiendo todos los archivos necesarios.
Para ser más precisos, una tabla está compuesta por punteros de metadatos que determinan qué micro-partitions son válidas en un momento dado. De hecho, Snowflake la denomina table version, que a su vez se compone de un system timestamp, un conjunto de micro-partitions y estadísticas a nivel de partición 5.
- INSERT implica principalmente la adición de nuevas micro-partitions. Más allá de las estrategias habituales —como ajustar el tamaño del warehouse para una configuración óptima y evitar usar Snowflake como plataforma de ingesta de alta frecuencia para tareas OLTP—, es poco probable que quede mucho margen para mejorar este paso.
- Los UPDATE son más complicados, ya que como primer paso requieren escanear todas las micro-partitions, lo cual puede volverse muy costoso en tablas grandes. Lo ideal es que los datos actualizados correspondan a un intervalo de fechas acotado, así no se termina reescribiendo varios archivos. Evitar los errores comunes al hacer join de tablas, comentados antes, también resulta útil aquí.
Alternativas a MERGE
Además de MERGE, hay un par de opciones manuales conocidas en las que puedes apoyarte para tus necesidades de carga de datos. Si no necesitas atomicidad y trabajas con un reemplazo total de datos, DELETE + INSERT es una estrategia viable. El usuario es responsable de encontrar los registros que deben eliminarse y luego insertar los nuevos en dos sentencias separadas. Si la sentencia INSERT falla, la tabla quedará en un estado con registros faltantes. También se pueden ejecutar las sentencias UPDATE e INSERT por separado. Sin embargo, como cada sentencia debe escanear por su cuenta los datos de la tabla de destino, esto terminará consumiendo más créditos de cómputo.
Más ejemplos del uso de MERGE
Sigamos explorando el concepto de MERGE con un par de ejemplos avanzados. Para estos ejemplos vamos a aprovechar la tabla de órdenes del dataset tpch_sf1000.
-- Table Size: 1.6 billion records
CREATE OR REPLACE TABLE mytestdb.public.orders AS
SELECT
o_orderkey,
o_custkey,
o_orderstatus,
o_totalprice,
o_orderdate,
o_orderpriority,
o_clerk,
o_comment,
o_shippriority
FROM
snowflake_sample_data.tpch_sf1000.orders
ORDER BY o_orderdate -- sorting by order
Expand Code
Al agregar la sentencia ORDER BY o_orderdate, la tabla orders quedará bien clusterizada por esa columna.
Para simular escenarios más comunes de carga de datos, veremos dos ejemplos de sentencias MERGE casi idénticas.
MERGE, actualización de valores en una sola micro-partition
En este primer ejemplo haremos MERGE sobre un dataset de origen que contiene 620 mil registros de un solo día.
-- Case 1
-- Values from a single order date / micro-paritition
-- Output: ~620k rows
-- Execution time: ~17s to run
CREATE OR REPLACE TEMPORARY TABLE source_table AS
SELECT
-- Primary Keys to Match Both Tables
-- To cover both INSERT and UPDATE cases
IFF(o_orderkey % 2 = 1, o_orderkey, o_orderkey + 99999999999) AS o_orderkey,
o_orderdate,
o_custkey,
o_orderstatus,
o_totalprice,
o_orderpriority,
Expand Code
La consulta tarda apenas 15-17 segundos en ejecutarse. La mitad de los datos se actualiza y la otra mitad se sobrescribe. Esta consulta hace un escaneo completo de la tabla de destino, lo que significa que el pruning de consultas está inactivo.
Una sola fila actualizada reescribe toda la micro-partition
Para ilustrar qué pasa por debajo cuando se involucra una cantidad significativa de micro-partitions, vamos a generar otro dataset de origen con el mismo volumen de datos, alrededor de 620 mil filas, pero esta vez con un rango de fechas dentro del año 1992 en lugar de un solo día.
-- Case 2
-- Values from a single order date / micro-paritition
-- Output: ~630k rows
-- Execution time: ~95s to run
CREATE OR REPLACE TEMPORARY TABLE source_table AS
SELECT
-- Primary Keys to Match Both Tables
IFF(o_orderkey % 2 = 1, o_orderkey, o_orderkey + 99999999999) AS o_orderkey
, o_orderdate
-- Other keys
, o_custkey
, o_orderstatus
, o_totalprice
Expand Code
¡Esta consulta tarda alrededor de 95 segundos en ejecutarse! A pesar de que la tabla de origen tiene el mismo tamaño, ¡esta consulta demora 4,5x más!
Comparación de los dos ejemplos de MERGE
Comparemos las estadísticas del plan de consulta para entender por qué el segundo ejemplo tarda tanto más.
| Bytes escaneados | Filas escritas | Tiempo de ejecución | Partitions escaneadas/total | |
|---|---|---|---|---|
| Una sola micro-partition | 6,20GB | 42MB | ~17s | 1 |
| Partitions distribuidas uniformemente | ~12GB | 5,91GB | ~95s | 1 |
Como ya mencionamos, aun cuando se modifique una sola fila de una tabla, hay que reescribir toda la micro-partition a la que pertenecía esa fila. Como la tabla de origen tenía datos distribuidos uniformemente a lo largo de 1992, tuvimos que reescribir ~6GB de datos, ¡que representan casi el 15% del tamaño de la tabla de destino!
En muchos sentidos, esta situación puede estar fuera de tu control. Si tienes que actualizar datos de un año entero, no quedan demasiadas opciones.
Los dos ejemplos anteriores requieren un escaneo completo de la tabla de destino para determinar qué micro-partitions hay que actualizar. Veamos una técnica de optimización conocida como pruning dinámico de consultas, que puede ayudar a mejorar el rendimiento en este caso.
Mejorar el rendimiento de MERGE con pruning dinámico
Si tu consulta MERGE pasa mucho tiempo escaneando la tabla de destino, es posible que puedas mejorar su rendimiento forzando el pruning de consultas, para evitar escanear datos innecesarios de la tabla de destino.
Consideremos un ejemplo en el que solo necesitamos actualizar 3 registros distintos, que ocurren en dos días diferentes: 1998-01-01 y 1998-02-25.
-- Source table
CREATE OR REPLACE TEMPORARY TABLE orders_to_update AS (
SELECT
2606029510 AS o_orderkey
, 0 AS o_totalprice
, DATE '1998-02-25' AS o_orderdate
UNION ALL
SELECT
3135064003 AS o_orderkey
, 0 AS o_totalprice
, DATE '1998-02-25' AS o_orderdate
UNION ALL
SELECT
5602847265 AS o_orderkey
Expand Code
Como vimos antes, un MERGE normal solo hará coincidir los registros por o_orderkey. Como o_orderkey es una clave aleatoria, la tabla de destino orders no estará clusterizada por esa columna y, por lo tanto, la operación MERGE tendrá que escanear toda la tabla de destino para encontrar las micro-partitions que contienen los tres valores de o_orderkey que queremos actualizar.
-- REGULAR MERGE
CREATE OR REPLACE TABLE orders_merge CLONE orders;
MERGE INTO orders_merge AS target
USING orders_to_update AS source
ON
target.o_orderkey = source.o_orderkey
WHEN MATCHED THEN
UPDATE SET
target.o_totalprice = source.o_totalprice
;
Para evitar tener que escanear todas las micro-partitions de la tabla de destino, podemos aprovechar que la tabla destino orders está clusterizada por o_orderdate. Esto significa que todas las órdenes con la misma fecha se almacenan en las mismas micro-partitions. Podemos modificar la sentencia MERGE para agregar una cláusula de join adicional sobre la columna o_orderdate. Durante la ejecución, ¡Snowflake solo necesita buscar en las micro-partitions que contienen órdenes de las fechas 1998-01-01 y 1998-02-25!
Esto se conoce como pruning dinámico, porque Snowflake decide qué micro-partitions descartar (no escanear) durante la ejecución de la consulta, después de leer los valores en la tabla de origen.
-- PRUNED MERGE
CREATE OR REPLACE TABLE orders_merge CLONE orders;
MERGE INTO orders_merge AS target
USING orders_to_update AS source
ON
target.o_orderkey = source.o_orderkey AND
target.o_orderdate = source.o_orderdate -- PRUNING COLUMN
WHEN MATCHED THEN
UPDATE SET
target.o_totalprice = source.o_totalprice
;
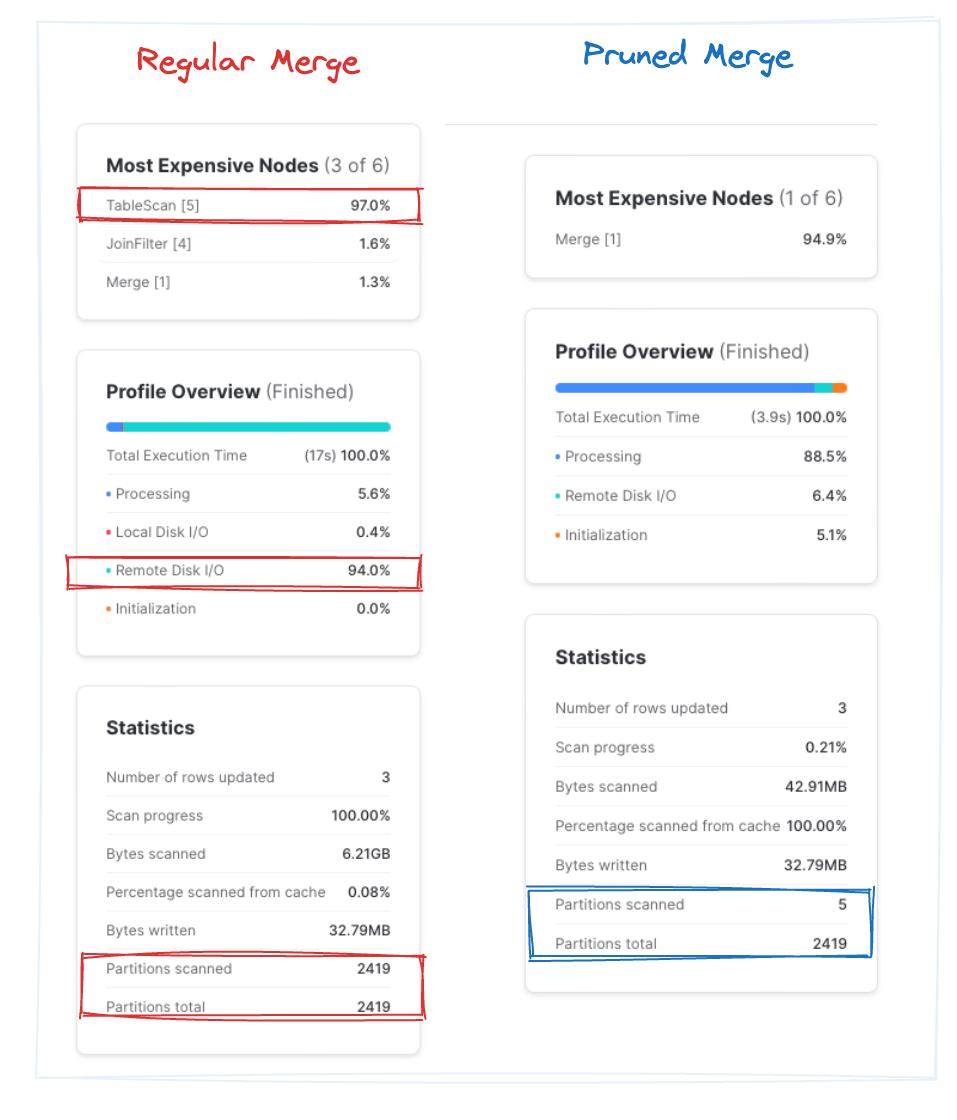
Mientras que la consulta del "merge normal" tarda ~9,5s en promedio sobre tres ejecuciones, el "merge con pruning" termina en ~4s. Observa que, en la consulta con pruning, Snowflake escaneó rápidamente ~0,2% del total de partitions. Eso equivale a una mejora aproximada de 2x al saltar bloques de archivos innecesarios. ¡Bingo!
Reflexiones finales
MERGE es una excelente manera de gestionar con elegancia la actualización y la inserción de datos en Snowflake. Al entender la arquitectura de Snowflake y sus archivos inmutables de micro-partitions, se comprende por qué ciertas operaciones MERGE pueden demorar tanto a pesar de actualizar solo unos pocos registros. También vimos cómo se puede mejorar el rendimiento de MERGE minimizando la cantidad de micro-partitions de la tabla de destino que deben escanearse.
¡Esperamos que el post te haya resultado útil, gracias por leernos!
Notas
2 Sintaxis de la sentencia MERGE en BigQuery
3 The Snowflake Elastic Data Warehouse
4 What's the Difference? Incremental Processing with Change Queries in Snowflake
5 Zero-Copy Cloning in Snowflake and Other Database Systems
Andrey Bystrov·Analytics Engineer en Deliveroo
Andrey es un profesional de datos con amplia experiencia y actualmente se desempeña como Analytics Engineer en Deliveroo. Le apasiona el modelado de datos y la optimización de SQL. Cuenta con un profundo conocimiento de la plataforma Snowflake y usa ese expertise para ayudar a su equipo a construir pipelines de datos performantes y costo-eficientes. Es un apasionado del tema y comparte regularmente sus aprendizajes con la comunidad.