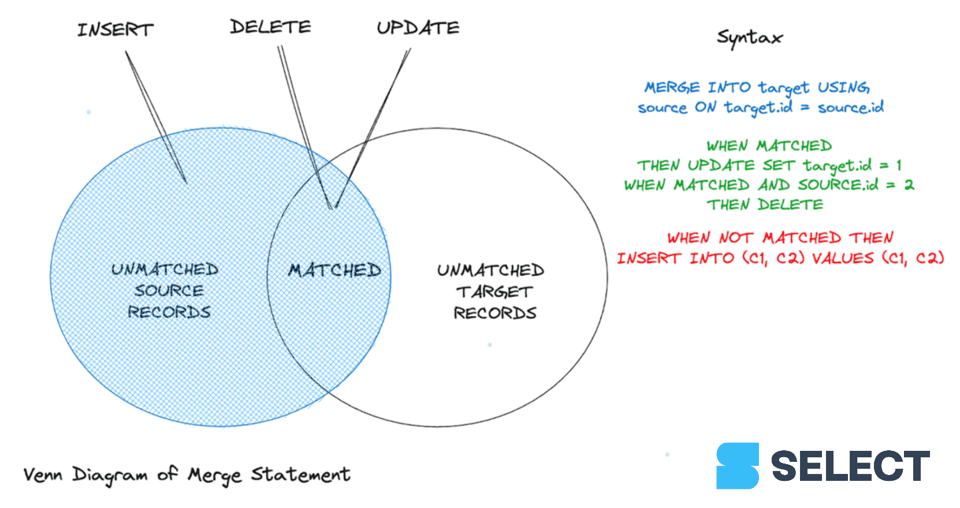
MERGE文は、行のupsertと削除を一度に実行できる強力で多目的なステートメントです。関連し合う複数の個別ステートメントでデータロードパイプラインを管理する代わりに、MERGEを使えば単一のアトミックなステートメントとしてシンプルかつ確実に制御できます。本記事では、SnowflakeにおけるMERGEの機能とアーキテクチャ上の仕組みを解説し、MERGEクエリのパフォーマンスを高める方法を紹介します。
SnowflakeのMERGEとは?
MERGE機能は、カラムナデータベースが普及するはるか以前から使われてきた、歴史ある機能です。upsert(insertとupdateの組み合わせ)とも呼ばれ、データパイプラインの整合性を保ちながら変更を適切に反映するのに役立ちます。今日のETLジョブは絶え間ないデータストリームをインクリメンタルに処理するケースが多く、MERGEはまさに欠かせない存在です。delete、insert、updateを単一トランザクションで実行できるため、ほぼあらゆるユースケースをカバーできます。同じテーブルを並行して書き換える複数スクリプトに頭を悩ませることもなくなります。
UPDATE文とは異なり、MERGEは複数のマッチング条件を順に処理してupdateやdeleteを実行できます。一方、マッチしないレコードについては、ソースからターゲットへデータを挿入することしかできません。現時点では、Databricks 1やGoogle BigQuery 2と異なり、Snowflakeではソーステーブルのマッチしない行に対する条件付きの挙動を指定することはできません。
では、構文を見ていきましょう。MERGEコマンドを使うには、以下の引数を指定する必要があります。
- ソーステーブル:マージするデータを保持するテーブル。
- ターゲットテーブル:データを反映する先のテーブル。
- 結合式:両テーブルを紐づけるキーとなる列。
- Matched句:期待する挙動を定義する、1つ以上の(non-)matched句。
MERGEで顧客のアクティブステータスを更新する
まずは、新しい顧客データを持つソーステーブルからcustomerテーブルを更新する例を見ていきましょう。レコードのマッチングにはcustomer_idを使用します。MERGEがupdateとinsertの両方をどのように処理するかを示すため、テーブルのデータは一部が重なるように作成しています。
-- Creating Tables
CREATE OR REPLACE TABLE target_table (
customer_id NUMBER,
is_active BOOLEAN,
updated_date DATE
)
;
CREATE OR REPLACE TABLE source_table (
customer_id NUMBER,
is_active BOOLEAN
)
;
-- Inserting test values
Expand Code
upsertの結果、2行(ID: 1, 2)が更新され、1行(ID: 4)が新たに挿入されました。残りの顧客(ID: 3)はソーステーブルにマッチする行がないため、そのまま維持されています。このシンプルな例から、MERGEの基本機能とプロジェクトでの活用イメージがつかめるはずです。
続いて、内部で何が起きているのかを見ていきましょう。
MERGEクエリのパフォーマンスを理解し、改善する
先ほどの「customers」MERGEクエリのSnowflakeクエリプロファイルは次のとおりです。
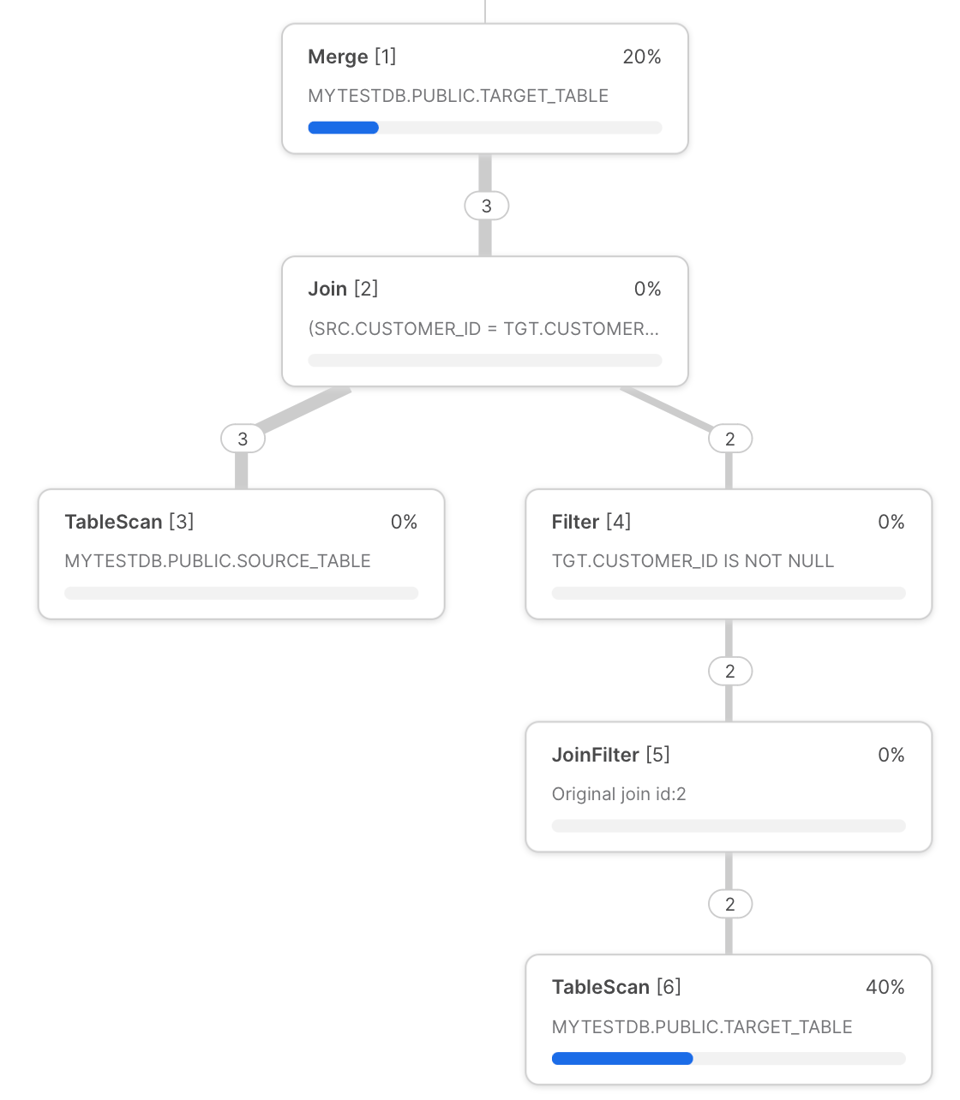
このプロファイルから、潜在的なボトルネックを読み解いていきましょう。
- MERGEクエリは、実行のたびにまずターゲットテーブルのスキャンから始まります。これはクエリ全体で最も時間を要するステップの1つです。スキャン時間を短縮するには、ターゲットテーブルがクラスタリングされている列でフィルタをかける必要があります。これによりクエリプルーニングが働き、不要なマイクロパーティションのスキャンを回避できます。後ほど、動的プルーニングを使った具体的な実現方法を紹介します。
MERGEの直前に、テーブルはLEFT OUTER JOIN(NON MATCHED句がある場合)またはINNER JOIN(MATCHED句のみの場合)で結合されます。通常の結合と同様、行数の爆発はメモリ消費の増大によるディスクスピルを招きやすいため、可能な限り避けるべきです。- JOINの性能が低下する原因の1つに、Snowflakeのオプティマイザが最適でない結合順序を選んでしまうことがあります。手動結合制御オプションを使い、Snowflakeに別の結合順序を指定する方法も検討してみてください。
- 結合条件が非等価結合を含む場合は、レンジ結合の最適化を活用しましょう。
- 結合時はソーステーブルのキー列が一意であることを確認してください。そうでない場合、非決定的な挙動を有効にしない限りエラーが返されます。
- クエリプラン最上部の最終的なMERGE処理については、残念ながらその内部ステップごとの所要時間まで掘り下げることはできません。このステップの所要時間は、書き込まれるファイル数とデータ量に比例します。
SnowflakeアーキテクチャがMERGEに与える影響
以前の記事で取り上げたとおり、Snowflakeのアーキテクチャはストレージ、コンピュート、クラウドサービスの各レイヤーが分離されています。Snowflakeのストレージ層はマイクロパーティションと呼ばれるイミュータブルなファイルで構成されているため、既存ファイルへの部分更新や追記はできません。そのため、insert、update、deleteを含むステートメントは、これらのファイル全体の上書き 3(書き換え)を引き起こします。
テーブルに変更を加えるたびに、2つの処理が同時に発生します。SnowflakeはTime Travelの設定 4に基づき古いデータのコピーを保持し、更新後のテーブルは必要なファイルをすべて書き換えることで保存されます。
より正確に言えば、テーブルはどのマイクロパーティションがその時点で有効かを示すメタデータポインタで構成されています。Snowflakeはこれをテーブルバージョンと呼び、システムタイムスタンプ、マイクロパーティション群、そしてパーティションレベルの統計情報 5から成り立っています。
- INSERTは主に新しいマイクロパーティションの追加を伴います。最適な構成に合わせてウェアハウスサイズを調整する、OLTP用途の高頻度取り込みプラットフォームとしてSnowflakeを使わない、といった一般的なベストプラクティス以外には、このステップで改善できる余地はあまりありません。
- UPDATEはより厄介です。最初にすべてのマイクロパーティションをスキャンする必要があり、大規模テーブルでは非常にコストが高くなります。理想的には更新データが狭い日付範囲に収まっており、複数ファイルの書き換えを避けられる状況が望ましいといえます。先ほど触れた結合の落とし穴を避けることも、ここでも有効です。
MERGEの代替手段
MERGE以外にも、データロードに使える定番の手動オプションがいくつかあります。アトミック性が不要で、データを丸ごと置き換える場合はDELETE + INSERTが有効な選択肢になります。ただし削除対象のレコードを特定し、別々のステートメントで新しいレコードを挿入する責任はユーザー側にあります。INSERTが失敗すると、テーブルはレコードが欠落した状態のまま残ってしまいます。UPDATEとINSERTを別々に実行することもできますが、その場合は各ステートメントがターゲットテーブルのデータを個別にスキャンするため、コンピュートクレジットを余分に消費することになります。
MERGEの応用例
続いて、MERGEのより応用的な例を見ていきましょう。ここではtpch_sf1000データセットのorderテーブルを使用します。
-- Table Size: 1.6 billion records
CREATE OR REPLACE TABLE mytestdb.public.orders AS
SELECT
o_orderkey,
o_custkey,
o_orderstatus,
o_totalprice,
o_orderdate,
o_orderpriority,
o_clerk,
o_comment,
o_shippriority
FROM
snowflake_sample_data.tpch_sf1000.orders
ORDER BY o_orderdate -- sorting by order
Expand Code
ORDER BY o_orderdateを加えることで、ordersテーブルはこの列で適切にクラスタリングされます。
より現実的なデータロードの状況を再現するため、ほぼ同じ内容のMERGE文を使った2つの例を見ていきます。
MERGE:単一マイクロパーティションの値を更新
1つ目の例では、1日分の62万件のレコードを含むソースデータセットをMERGEします。
-- Case 1
-- Values from a single order date / micro-paritition
-- Output: ~620k rows
-- Execution time: ~17s to run
CREATE OR REPLACE TEMPORARY TABLE source_table AS
SELECT
-- Primary Keys to Match Both Tables
-- To cover both INSERT and UPDATE cases
IFF(o_orderkey % 2 = 1, o_orderkey, o_orderkey + 99999999999) AS o_orderkey,
o_orderdate,
o_custkey,
o_orderstatus,
o_totalprice,
o_orderpriority,
Expand Code
このクエリの実行時間はわずか15〜17秒です。データの半分が更新され、もう半分が上書きされます。クエリはターゲットテーブルのフルスキャンを行うため、クエリプルーニングは効きません。
1行の更新がマイクロパーティション全体の書き換えを引き起こす
多数のマイクロパーティションが関係する場合に内部で何が起きるかを示すため、同じ約62万行のデータ量を持つ別のソースデータセットを用意します。ただし今回は、1日ではなく1992年内の幅広い日付にデータを散らします。
-- Case 2
-- Values from a single order date / micro-paritition
-- Output: ~630k rows
-- Execution time: ~95s to run
CREATE OR REPLACE TEMPORARY TABLE source_table AS
SELECT
-- Primary Keys to Match Both Tables
IFF(o_orderkey % 2 = 1, o_orderkey, o_orderkey + 99999999999) AS o_orderkey
, o_orderdate
-- Other keys
, o_custkey
, o_orderstatus
, o_totalprice
Expand Code
このクエリは約95秒もかかります。ソーステーブルのサイズは同じなのに、実行時間は4.5倍に膨らんでいます。
2つのMERGE例を比較する
クエリプランの統計を比較し、なぜ2つ目の例がこれほど時間を要するのかを確認しましょう。
| スキャンされたバイト数 | 書き込まれた行数 | 実行時間 | スキャンされたパーティション/全体 | |
|---|---|---|---|---|
| 単一マイクロパーティション | 6.20GB | 42MB | 約17秒 | 1 |
| 均一に分散したパーティション | 約12GB | 5.91GB | 約95秒 | 1 |
先述のとおり、テーブル内のたった1行を変更するだけでも、その行が属するマイクロパーティション全体を書き換える必要があります。今回のソーステーブルは1992年全体に均一に分散したデータを含むため、約6GB、ターゲットテーブルサイズの実に約15%にも及ぶデータを書き換えることになります。
こうした状況は、必ずしも自分の裁量でコントロールできるものではありません。1年分のデータを更新しなければならないのであれば、選択肢はおのずと限られてきます。
上記の2例はいずれも、更新対象のマイクロパーティションを特定するためにターゲットテーブルのフルスキャンを伴います。次に、ここでのパフォーマンスを改善できる動的クエリプルーニングという最適化手法を見ていきましょう。
動的プルーニングでMERGEのパフォーマンスを高める
MERGEクエリがターゲットテーブルのスキャンに多くの時間を費やしている場合、クエリプルーニングを強制的に効かせることで不要なデータスキャンを抑え、パフォーマンスを改善できる可能性があります。
例として、1998-01-01と1998-02-25という2つの異なる日付に属する3件のレコードだけを更新するケースを考えてみましょう。
-- Source table
CREATE OR REPLACE TEMPORARY TABLE orders_to_update AS (
SELECT
2606029510 AS o_orderkey
, 0 AS o_totalprice
, DATE '1998-02-25' AS o_orderdate
UNION ALL
SELECT
3135064003 AS o_orderkey
, 0 AS o_totalprice
, DATE '1998-02-25' AS o_orderdate
UNION ALL
SELECT
5602847265 AS o_orderkey
Expand Code
先ほど見たように、通常のMERGEはo_orderkeyのみでレコードをマッチさせます。o_orderkeyはランダムなキーなので、ターゲットのordersテーブルはこの列ではクラスタリングされておらず、結果として更新対象の3つのo_orderkeyを含むマイクロパーティションを探すために、ターゲットテーブル全体をスキャンせざるを得ません。
-- REGULAR MERGE
CREATE OR REPLACE TABLE orders_merge CLONE orders;
MERGE INTO orders_merge AS target
USING orders_to_update AS source
ON
target.o_orderkey = source.o_orderkey
WHEN MATCHED THEN
UPDATE SET
target.o_totalprice = source.o_totalprice
;
ターゲットテーブルの全マイクロパーティションをスキャンしなくて済むようにするには、ordersテーブルがo_orderdateでクラスタリングされている点を活用できます。つまり、同じ日付のオーダーは同じマイクロパーティションに格納されているということです。MERGE文にo_orderdate列の結合条件を追加しましょう。これにより、クエリ実行時にSnowflakeは1998-01-01と1998-02-25のオーダーを含むマイクロパーティションだけを検索すればよくなります。
これは動的プルーニングと呼ばれる仕組みで、Snowflakeがクエリ実行中にソーステーブルの値を読み取った後、どのマイクロパーティションをプルーニング(スキャン回避)するかを決定するためです。
-- PRUNED MERGE
CREATE OR REPLACE TABLE orders_merge CLONE orders;
MERGE INTO orders_merge AS target
USING orders_to_update AS source
ON
target.o_orderkey = source.o_orderkey AND
target.o_orderdate = source.o_orderdate -- PRUNING COLUMN
WHEN MATCHED THEN
UPDATE SET
target.o_totalprice = source.o_totalprice
;
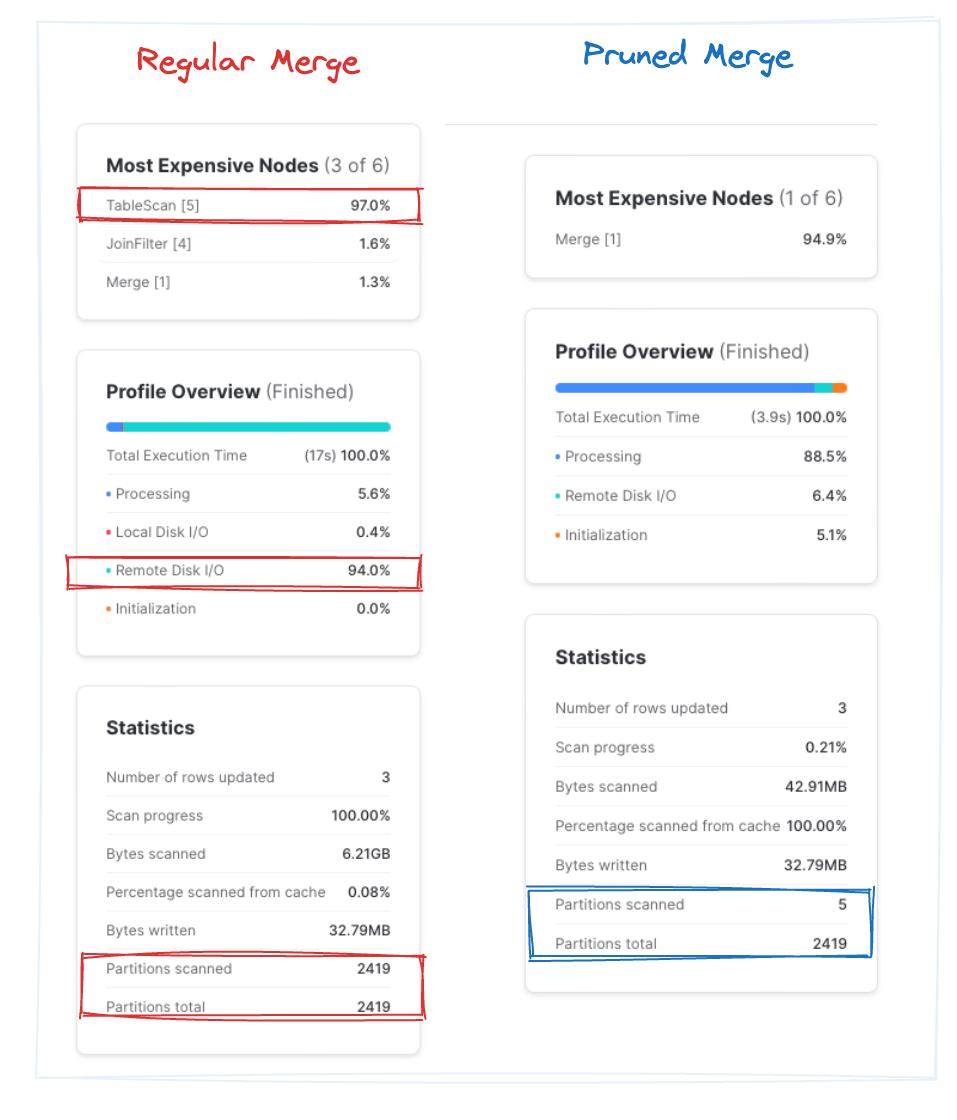
「regular merge」クエリは3回の実行平均で約9.5秒かかるのに対し、「pruned merge」は約4秒で完了します。プルーニング適用後のクエリでは、Snowflakeが全パーティションのわずか約0.2%のみを高速にスキャンしている点に注目してください。不要なファイルブロックをスキップした結果、約2倍のパフォーマンス改善が得られました。見事な成果です。
まとめ
MERGEは、Snowflakeでデータの更新と挿入をスマートにこなすための強力な手段です。Snowflakeのアーキテクチャとイミュータブルなマイクロパーティションファイルの仕組みを理解すれば、わずか数件の更新でも特定のMERGE操作に時間がかかる理由が見えてきます。また、ターゲットテーブルでスキャンが必要なマイクロパーティションを最小限に抑えることで、MERGEのパフォーマンスを改善できることもお分かりいただけたかと思います。
本記事が皆様のお役に立てば幸いです。最後までお読みいただきありがとうございました。
注釈
2 BigQuery merge statement syntax
3 The Snowflake Elastic Data Warehouse
4 What's the Difference? Incremental Processing with Change Queries in Snowflake
5 Zero-Copy Cloning in Snowflake and Other Database Systems
Andrey Bystrov·Analytics Engineer at Deliveroo
Andreyは経験豊富なデータ実務者で、現在はDeliverooでAnalytics Engineerとして活躍しています。データモデリングとSQLの最適化に強い情熱を持ち、Snowflakeプラットフォームへの深い理解を活かして、チームが高性能かつコスト効率の高いデータパイプラインを構築できるよう支援しています。この分野への思いは強く、得られた知見をコミュニティへ定期的に発信しています。