O comando MERGE é uma ferramenta poderosa e versátil que permite fazer upsert e excluir linhas de uma só vez. Em vez de gerenciar pipelines de carregamento de dados por meio de instruções separadas e interdependentes, o MERGE permite simplificar e controlar tudo em uma única instrução atômica. Neste post, vamos guiar você pelos recursos e pelos fundamentos arquiteturais do MERGE no Snowflake e mostrar como melhorar o desempenho das queries que usam MERGE.
O que é o MERGE no Snowflake?
O recurso MERGE existe há bastante tempo, desde antes do auge dos bancos de dados colunares. Também conhecido como upsert (insert e update), ele ajuda a lidar com mudanças de forma adequada, garantindo a consistência dos pipelines de dados. Jobs de ETL modernos costumam gerenciar fluxos infinitos de dados de forma incremental, então o MERGE não pode ser deixado de lado. Ele cobre quase todos os casos de uso, permitindo executar operações de delete, insert e update em uma única transação. Vários scripts modificando a mesma tabela em paralelo deixam de ser uma dor de cabeça.
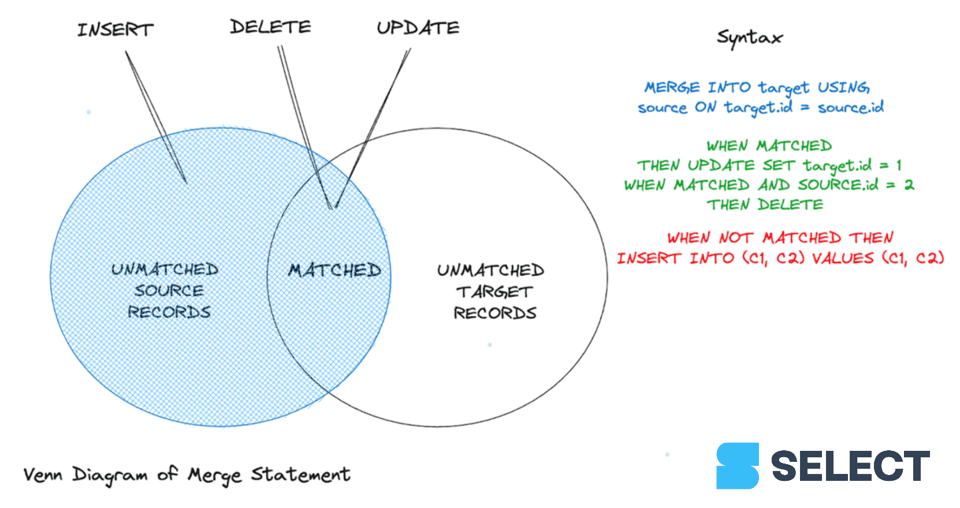
Diferente de um UPDATE, o MERGE consegue processar várias condições de correspondência em sequência para concluir updates ou deletes. Já para registros sem correspondência, o usuário só consegue inserir um bloco de dados da origem no destino. Hoje, ao contrário do Databricks 1 e do Google BigQuery 2, o Snowflake não permite especificar o comportamento quando condições parciais são atendidas, especificamente para linhas sem correspondência na tabela de origem.
Vamos à sintaxe. Para usar o comando MERGE, é preciso passar os seguintes argumentos:
- Tabela de origem: a tabela com os dados a serem mesclados.
- Tabela de destino: a tabela onde os dados serão sincronizados.
- Expressão de join: os campos-chave de ambas as tabelas que fazem a ligação entre elas.
- Cláusula matched: pelo menos uma cláusula matched (ou not matched) que define o resultado esperado.
Usando MERGE para atualizar o status ativo de clientes
Vamos começar com um exemplo de uma tabela de clientes que queremos atualizar a partir de uma tabela de origem com novos dados. Usaremos customer_id para casar os registros entre as tabelas. Para mostrar como o MERGE lida tanto com updates quanto com inserts, os dados gerados têm sobreposição parcial.
-- Creating Tables
CREATE OR REPLACE TABLE target_table (
customer_id NUMBER,
is_active BOOLEAN,
updated_date DATE
)
;
CREATE OR REPLACE TABLE source_table (
customer_id NUMBER,
is_active BOOLEAN
)
;
-- Inserting test values
Expandir código
Pronto: fizemos um upsert que atualizou 2 linhas (ID: 1, 2) e inseriu 1 nova linha (ID: 4). O cliente restante (ID: 3) ficou intacto, já que não havia linha correspondente na tabela de origem. Esse exemplo simples mostra os recursos básicos do operador e como aplicá-lo no seu projeto.
Vamos adiante e ver o que acontece por baixo dos panos.
Entendendo e melhorando o desempenho da query MERGE
Veja abaixo o query profile do Snowflake para a query MERGE de "customers" mostrada acima.
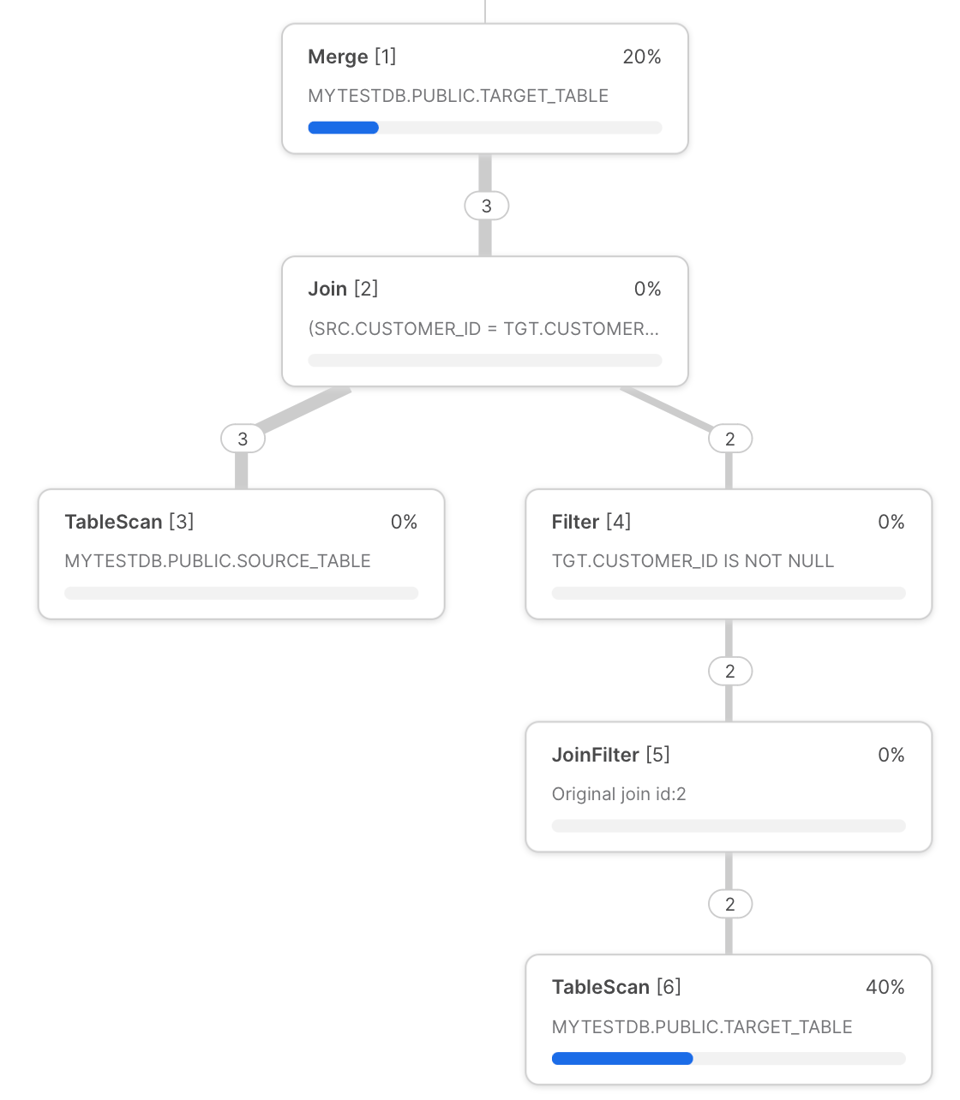
Podemos usar esse profile para ilustrar possíveis gargalos:
- Toda vez que você executa uma query MERGE, ela começa fazendo o scan da tabela de destino. Esse é um dos passos mais demorados da query. Para reduzir o tempo de scan, filtre a tabela de destino por uma das colunas pelas quais ela está bem clusterizada. Isso habilita o query pruning, que evita que a execução escaneie micro-partitions desnecessárias. Mais adiante no post, vamos mostrar uma forma de conseguir isso usando dynamic pruning.
- Logo antes do
MERGE, as tabelas são unidas viaLEFT OUTER JOIN(quando há cláusulaNON MATCHED) ouINNER JOIN(somente com cláusulaMATCHED). Como sempre em joins, evite a explosão de linhas sempre que possível, pois ela tende a causar spill em disco por exigir muita memória. - Uma das causas de desempenho ruim em JOINs é o otimizador do Snowflake escolher uma ordem de join subótima. Vale explorar a opção de controle manual de join para forçar o Snowflake a usar outra ordem.
- Aproveite as otimizações de range join quando a condição envolver um non-equi join.
- Garanta que a tabela de origem tenha campos-chave únicos no join; caso contrário, você verá uma mensagem de erro, a não ser que ative o comportamento não determinístico.
- Na operação MERGE final, no topo do plano da query, infelizmente não dá para detalhar o tempo gasto em cada um dos passos subjacentes. O tempo dessa etapa é proporcional ao volume de arquivos e dados gravados.
O impacto da arquitetura do Snowflake no MERGE
Como discutido em um post anterior, a arquitetura do Snowflake tem camadas separadas de storage, compute e serviços de nuvem. Como a camada de armazenamento usa arquivos imutáveis chamados micro-partitions, não existem updates parciais nem appends em arquivos existentes. Por isso, instruções de insert, update ou delete acionam a sobrescrita total 3 (ou reescrita) desses arquivos.
Sempre que você modifica uma tabela, dois eventos acontecem ao mesmo tempo: o Snowflake guarda uma cópia dos dados antigos e a mantém conforme a configuração de Time Travel 4, e a tabela atualizada é armazenada com a reescrita de todos os arquivos necessários.
Sendo mais preciso, uma tabela é composta por ponteiros de metadados que determinam quais micro-partitions são válidas em cada momento. O Snowflake chama isso de table version, que por sua vez é composta por um system timestamp, um conjunto de micro-partitions e estatísticas em nível de partição 5.
- O INSERT envolve basicamente a criação de novas micro-partitions. Além de estratégias comuns como dimensionar bem o warehouse e evitar usar o Snowflake como plataforma de ingestão de alta frequência para cargas OLTP, sobra pouco espaço para otimizações adicionais nessa etapa.
- UPDATEs são mais complicados: como primeiro passo, exigem o scan de todas as micro-partitions, o que pode ficar muito caro em tabelas grandes. O ideal é que os dados atualizados estejam concentrados em um intervalo de datas curto, para evitar a reescrita de vários arquivos. Evitar as armadilhas comuns de joins, discutidas antes, também ajuda bastante aqui.
Alternativas ao MERGE
Além do MERGE, há algumas opções manuais bem conhecidas para o seu carregamento de dados. Se atomicidade não for um requisito e você estiver fazendo substituição total dos dados, DELETE + INSERT é uma estratégia viável. Cabe ao usuário encontrar os registros a excluir e depois inserir os novos em duas instruções separadas. Se o INSERT falhar, a tabela ficará em um estado com registros faltando. Também dá para executar UPDATE e INSERT de forma separada. Mas, como cada instrução precisa escanear os dados da tabela de destino por conta própria, isso acaba consumindo mais créditos de compute.
Mais exemplos de uso do MERGE
Vamos continuar explorando o MERGE com alguns exemplos mais avançados. Nesses exemplos, vamos usar a tabela de pedidos do dataset tpch_sf1000.
-- Table Size: 1.6 billion records
CREATE OR REPLACE TABLE mytestdb.public.orders AS
SELECT
o_orderkey,
o_custkey,
o_orderstatus,
o_totalprice,
o_orderdate,
o_orderpriority,
o_clerk,
o_comment,
o_shippriority
FROM
snowflake_sample_data.tpch_sf1000.orders
ORDER BY o_orderdate -- sorting by order
Expandir código
Ao adicionar o ORDER BY o_orderdate, a tabela orders ficará bem clusterizada por essa coluna.
Para simular cenários mais comuns de carregamento de dados, vamos analisar dois exemplos de MERGE quase idênticos.
MERGE com atualização de valores em uma única micro-partition
Neste primeiro exemplo, vamos fazer MERGE em um dataset de origem com 620 mil registros de um único dia.
-- Case 1
-- Values from a single order date / micro-paritition
-- Output: ~620k rows
-- Execution time: ~17s to run
CREATE OR REPLACE TEMPORARY TABLE source_table AS
SELECT
-- Primary Keys to Match Both Tables
-- To cover both INSERT and UPDATE cases
IFF(o_orderkey % 2 = 1, o_orderkey, o_orderkey + 99999999999) AS o_orderkey,
o_orderdate,
o_custkey,
o_orderstatus,
o_totalprice,
o_orderpriority,
Expandir código
A query roda em apenas 15 a 17 segundos. Metade dos dados é atualizada e a outra metade é sobrescrita. Essa query faz full-scan da tabela de destino, ou seja, o query pruning fica inativo.
Uma linha atualizada reescreve a micro-partition inteira
Para mostrar o que acontece por baixo dos panos quando envolvemos um número significativo de micro-partitions, vamos gerar outro dataset de origem com o mesmo volume — cerca de 620 mil linhas —, mas, desta vez, com datas distribuídas ao longo de 1992, em vez de um único dia.
-- Case 2
-- Values from a single order date / micro-paritition
-- Output: ~630k rows
-- Execution time: ~95s to run
CREATE OR REPLACE TEMPORARY TABLE source_table AS
SELECT
-- Primary Keys to Match Both Tables
IFF(o_orderkey % 2 = 1, o_orderkey, o_orderkey + 99999999999) AS o_orderkey
, o_orderdate
-- Other keys
, o_custkey
, o_orderstatus
, o_totalprice
Expandir código
Essa query leva cerca de 95 segundos! Apesar do mesmo tamanho de tabela de origem, ela demora 4,5x mais!
Comparando os dois exemplos de MERGE
Vamos comparar as estatísticas do plano de query para entender por que o segundo exemplo demora tanto.
| Bytes escaneados | Linhas gravadas | Tempo de execução | Partições escaneadas/total | |
|---|---|---|---|---|
| Micro-partition única | 6,20GB | 42MB | ~17s | 1 |
| Partições uniformemente distribuídas | ~12GB | 5,91GB | ~95s | 1 |
Como já comentamos, mesmo que você altere apenas uma linha em uma tabela, é preciso reescrever toda a micro-partition à qual ela pertencia. Como a tabela de origem trazia dados distribuídos uniformemente ao longo de 1992, tivemos que reescrever cerca de 6GB de dados — quase 15% do tamanho da tabela de destino!
Em muitos casos, essa situação foge ao seu controle. Se você precisa atualizar dados de um ano inteiro, não há muitas opções.
Os dois exemplos acima envolvem um full scan da tabela de destino para identificar quais micro-partitions precisam ser atualizadas. Vamos explorar uma técnica de otimização chamada dynamic query pruning, que pode ajudar a melhorar o desempenho aqui.
Melhorando o desempenho do merge com dynamic pruning
Se a sua query MERGE estiver gastando muito tempo escaneando a tabela de destino, talvez seja possível melhorar o desempenho forçando o query pruning, que evita o scan de dados desnecessários da tabela de destino.
Imagine um caso em que precisamos atualizar apenas 3 registros, ocorridos em dois dias diferentes: 01/01/1998 e 25/02/1998.
-- Source table
CREATE OR REPLACE TEMPORARY TABLE orders_to_update AS (
SELECT
2606029510 AS o_orderkey
, 0 AS o_totalprice
, DATE '1998-02-25' AS o_orderdate
UNION ALL
SELECT
3135064003 AS o_orderkey
, 0 AS o_totalprice
, DATE '1998-02-25' AS o_orderdate
UNION ALL
SELECT
5602847265 AS o_orderkey
Expandir código
Como vimos antes, um MERGE comum só casa os registros por o_orderkey. Como o_orderkey é uma chave aleatória, a tabela de destino orders não estará clusterizada por essa coluna e, portanto, a operação MERGE terá que escanear a tabela inteira para encontrar as micro-partitions com os três valores de o_orderkey que queremos atualizar.
-- REGULAR MERGE
CREATE OR REPLACE TABLE orders_merge CLONE orders;
MERGE INTO orders_merge AS target
USING orders_to_update AS source
ON
target.o_orderkey = source.o_orderkey
WHEN MATCHED THEN
UPDATE SET
target.o_totalprice = source.o_totalprice
;
Para não precisar escanear todas as micro-partitions da tabela de destino, podemos aproveitar o fato de que a tabela orders está clusterizada por o_orderdate. Ou seja, todos os pedidos com a mesma data ficam armazenados nas mesmas micro-partitions. Podemos modificar a instrução MERGE para incluir uma cláusula de join extra na coluna o_orderdate. Durante a execução, o Snowflake só precisa buscar nas micro-partitions com pedidos das datas 01/01/1998 e 25/02/1998!
Isso é o chamado dynamic pruning: o Snowflake decide quais micro-partitions descartar (evitar escanear) durante a execução da query, depois de ler os valores na tabela de origem.
-- PRUNED MERGE
CREATE OR REPLACE TABLE orders_merge CLONE orders;
MERGE INTO orders_merge AS target
USING orders_to_update AS source
ON
target.o_orderkey = source.o_orderkey AND
target.o_orderdate = source.o_orderdate -- PRUNING COLUMN
WHEN MATCHED THEN
UPDATE SET
target.o_totalprice = source.o_totalprice
;
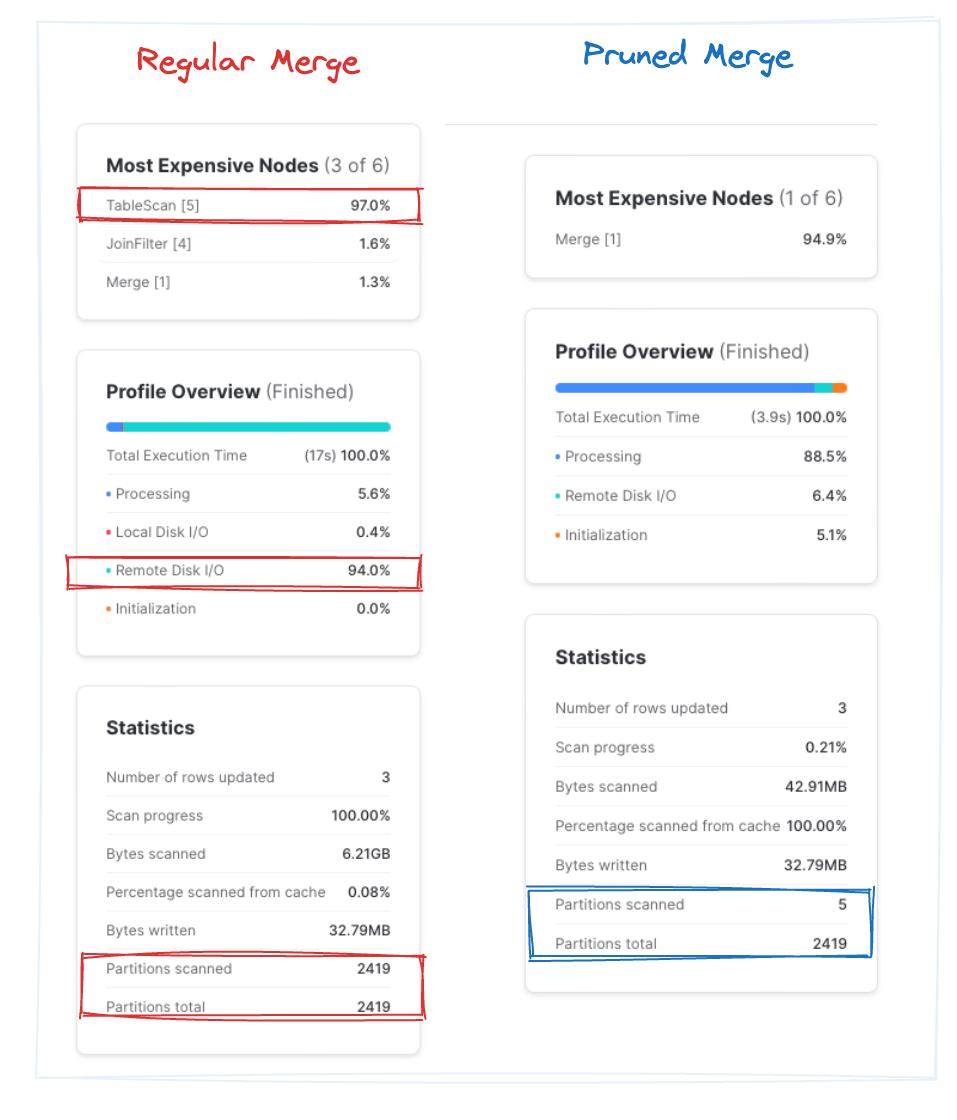
Enquanto a query do "merge comum" leva cerca de 9,5s em média ao longo de três execuções, o "merge com pruning" termina em cerca de 4s. Repare que, na query com pruning, o Snowflake escaneou rapidamente cerca de 0,2% do total de partições. É uma melhoria de aproximadamente 2x, simplesmente por pular blocos de arquivos desnecessários. Bingo!
Considerações finais
O MERGE é uma ótima forma de lidar elegantemente com atualizações e inserções de dados no Snowflake. Ao entender a arquitetura do Snowflake e seus arquivos imutáveis de micro-partitions, fica claro por que algumas operações MERGE podem demorar bastante mesmo atualizando poucos registros. Também vimos como melhorar o desempenho do MERGE minimizando o número de micro-partitions da tabela de destino que precisam ser escaneadas.
Esperamos que o post tenha sido útil. Obrigado pela leitura!
Notas
2 Sintaxe da instrução merge do BigQuery
3 The Snowflake Elastic Data Warehouse
4 What's the Difference? Incremental Processing with Change Queries in Snowflake
5 Zero-Copy Cloning in Snowflake and Other Database Systems
Andrey Bystrov·Analytics Engineer na Deliveroo
Andrey é um profissional experiente em dados e atualmente trabalha como Analytics Engineer na Deliveroo. Ele é apaixonado por modelagem de dados e otimização de SQL, tem profundo conhecimento da plataforma Snowflake e usa essa bagagem para ajudar seu time a construir pipelines de dados performáticos e com bom custo-benefício. Andrey adora o assunto e compartilha seus aprendizados com a comunidade regularmente.