L'instruction MERGE est un outil polyvalent et puissant qui permet d'effectuer en une seule opération des upserts et des suppressions de lignes. Au lieu de gérer des pipelines de chargement de données via des instructions séparées mais interdépendantes, MERGE permet de les simplifier considérablement et de les piloter avec une seule instruction atomique. Dans cet article, nous passons en revue les fonctionnalités et les fondations architecturales de MERGE dans Snowflake, puis nous voyons comment améliorer les performances des requêtes MERGE.
Qu'est-ce que MERGE dans Snowflake ?
La fonctionnalité MERGE existe depuis longtemps, bien avant l'essor des bases de données en colonnes. Également appelée upsert (insert et update), elle aide à gérer correctement les changements tout en garantissant la cohérence des pipelines de données. Les jobs ETL modernes traitent généralement des flux de données infinis de manière incrémentale, ce qui rend MERGE incontournable. Elle couvre la quasi-totalité des cas d'usage, en permettant d'effectuer des opérations de suppression, d'insertion et de mise à jour dans une seule transaction. Fini les casse-tête quand plusieurs scripts modifient la même table en parallèle.
Contrairement à une instruction UPDATE, MERGE peut traiter plusieurs conditions de correspondance successives pour effectuer des mises à jour ou des suppressions. En revanche, pour les enregistrements non correspondants, l'utilisateur ne peut qu'insérer un bloc de données depuis la source vers la destination. À ce jour, contrairement à Databricks 1 et Google BigQuery 2, Snowflake ne permet pas de définir un comportement lorsque des conditions partielles sont remplies, notamment pour les lignes non correspondantes de la table source.
Passons à la syntaxe. Pour utiliser la commande MERGE, vous devez fournir les arguments suivants :
- Table source : la table contenant les données à fusionner.
- Table cible : la table de destination où les données doivent être synchronisées.
- Expression de jointure : les champs clés des deux tables qui les relient entre elles.
- Clause de correspondance : au moins une clause (non-)matched déterminant le résultat attendu.
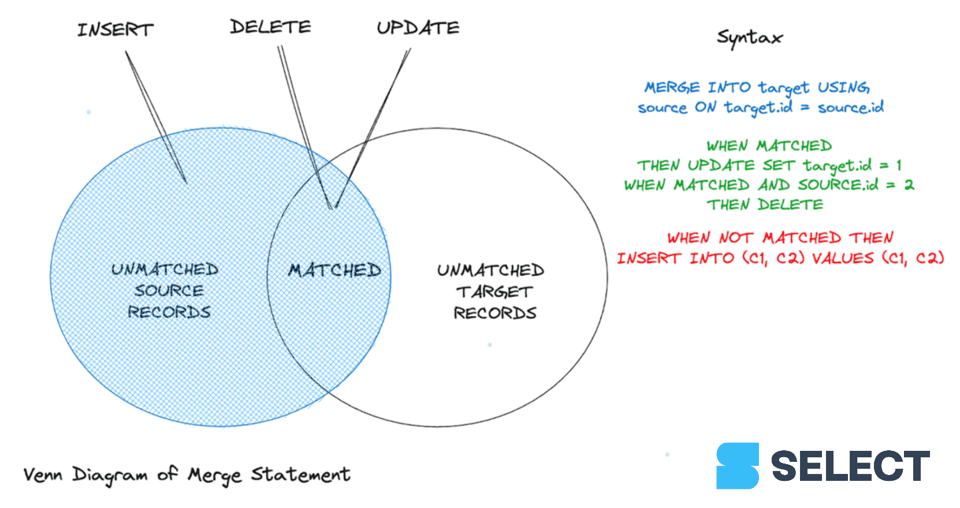
Utiliser MERGE pour mettre à jour le statut actif d'un client
Commençons par un exemple de table clients que nous souhaitons mettre à jour à partir d'une table source contenant de nouvelles données clients. Nous utiliserons customer_id pour faire correspondre les enregistrements de chaque table. Pour illustrer la façon dont MERGE gère à la fois les mises à jour et les insertions, les données générées se chevauchent partiellement.
-- Creating Tables
CREATE OR REPLACE TABLE target_table (
customer_id NUMBER,
is_active BOOLEAN,
updated_date DATE
)
;
CREATE OR REPLACE TABLE source_table (
customer_id NUMBER,
is_active BOOLEAN
)
;
-- Inserting test values
Expand Code
Nous avons donc effectué un upsert qui met à jour 2 lignes (ID : 1, 2) et insère 1 nouvelle ligne (ID : 4). Le client restant (ID : 3) n'est pas modifié, faute de ligne correspondante dans la table source. Cet exemple simple illustre les fonctionnalités de base de l'opérateur et la manière de l'utiliser dans votre projet.
Allons plus loin et voyons ce qui se passe sous le capot.
Comprendre et améliorer les performances des requêtes MERGE
Le query profile Snowflake de la requête MERGE customers ci-dessus est présenté ci-dessous.
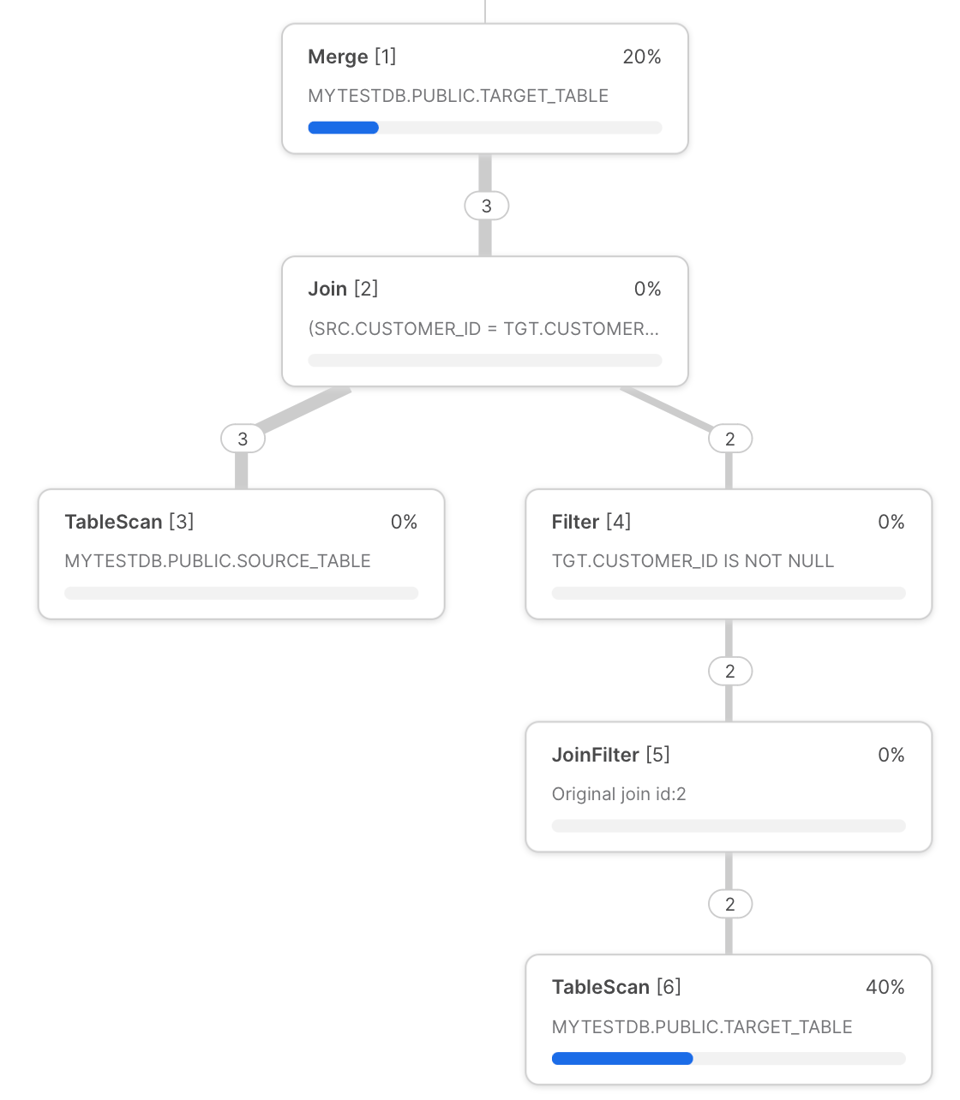
Ce profil permet d'identifier les goulets d'étranglement potentiels :
- Toute exécution d'une requête MERGE commence par un scan de la table cible. C'est l'une des étapes les plus chronophages de la requête. Pour réduire le temps passé à scanner les données, il faut filtrer la table cible sur l'une des colonnes sur lesquelles elle est bien clusterisée. Cela active le query pruning, qui évite au moteur d'exécution Snowflake de scanner des micro-partitions inutiles. Plus loin dans l'article, nous montrerons comment y parvenir grâce au dynamic pruning.
- Juste avant le
MERGE, les tables sont jointes via unLEFT OUTER JOIN(si une clauseNON MATCHEDest présente) ou unINNER JOIN(pour la clauseMATCHEDuniquement). Comme toujours avec les jointures, il faut éviter autant que possible l'explosion de lignes, qui provoque souvent du spillage disque en raison de besoins excessifs en mémoire. - Une cause fréquente de mauvaises performances de JOIN tient à un ordre de jointure sous-optimal choisi par l'optimiseur Snowflake. Vous pouvez explorer l'option de contrôle manuel de l'ordre de jointure pour forcer Snowflake à en utiliser un autre.
- Tirez parti des optimisations de range join si la condition de jointure n'est pas une équi-jointure.
- Vérifiez que la table source possède des champs clés uniques lors de la jointure, faute de quoi vous obtiendrez un message d'erreur, sauf à activer le comportement non déterministe.
- Dans l'opération MERGE finale, en haut du plan de requête, il n'est malheureusement pas possible d'analyser plus en détail le temps alloué aux étapes sous-jacentes. Le temps passé sur cette étape sera proportionnel au volume de fichiers et de données à écrire.
L'impact de l'architecture de Snowflake sur MERGE
Comme évoqué dans un précédent article, l'architecture de Snowflake repose sur des couches distinctes de stockage, de compute et de services cloud. Puisque la couche de stockage de Snowflake utilise des fichiers immuables appelés micro-partitions, ni les mises à jour partielles ni les ajouts aux fichiers existants ne sont possibles. Par conséquent, les instructions insert, update ou delete déclenchent une réécriture complète 3 de ces fichiers.
Chaque fois que vous modifiez une table, deux événements se produisent simultanément : Snowflake conserve une copie des anciennes données selon la configuration Time Travel 4, et la table mise à jour est stockée en réécrivant tous les fichiers nécessaires.
Plus précisément, une table est composée de pointeurs de métadonnées qui déterminent quelles micro-partitions sont valides à un instant donné. Snowflake parle alors de version de table, elle-même composée d'un horodatage système, d'un ensemble de micro-partitions et de statistiques au niveau partition 5.
- INSERT consiste principalement à ajouter de nouvelles micro-partitions. Au-delà des stratégies habituelles — dimensionner correctement le warehouse et éviter d'utiliser Snowflake comme plateforme d'ingestion haute fréquence pour des tâches OLTP — la marge d'amélioration sur cette étape est limitée.
- Les UPDATE sont plus délicats : la première étape consiste à scanner toutes les micro-partitions, ce qui peut devenir très coûteux sur de grandes tables. Idéalement, les données mises à jour correspondent à une plage de dates étroite, ce qui évite de réécrire de nombreux fichiers. Les conseils pour éviter les pièges classiques des jointures, évoqués plus haut, s'appliquent également ici.
Les alternatives à MERGE
En dehors de MERGE, il existe quelques options manuelles bien connues pour vos besoins de chargement de données. Si l'atomicité n'est pas requise et que vous procédez à un remplacement complet des données, DELETE + INSERT est une stratégie viable. C'est à l'utilisateur d'identifier les enregistrements à supprimer, puis d'insérer les nouveaux via deux instructions distinctes. Si l'instruction INSERT échoue, la table se retrouvera dans un état où des enregistrements manquent. Il est également possible d'exécuter les instructions UPDATE et INSERT séparément. Mais comme chaque instruction doit scanner indépendamment les données de la table cible, vous consommerez davantage de crédits de compute.
D'autres exemples d'utilisation de MERGE
Poursuivons l'exploration de MERGE avec deux exemples avancés. Nous utiliserons la table orders du dataset tpch_sf1000.
-- Table Size: 1.6 billion records
CREATE OR REPLACE TABLE mytestdb.public.orders AS
SELECT
o_orderkey,
o_custkey,
o_orderstatus,
o_totalprice,
o_orderdate,
o_orderpriority,
o_clerk,
o_comment,
o_shippriority
FROM
snowflake_sample_data.tpch_sf1000.orders
ORDER BY o_orderdate -- sorting by order
Expand Code
Grâce à l'instruction ORDER BY o_orderdate, la table orders sera bien clusterisée sur cette colonne.
Pour simuler des scénarios de chargement de données plus courants, examinons deux exemples d'instructions MERGE quasi identiques.
MERGE, mise à jour de valeurs sur une seule micro-partition
Dans ce premier exemple, nous allons exécuter un MERGE avec un dataset source contenant 620 000 enregistrements provenant d'une seule journée.
-- Case 1
-- Values from a single order date / micro-paritition
-- Output: ~620k rows
-- Execution time: ~17s to run
CREATE OR REPLACE TEMPORARY TABLE source_table AS
SELECT
-- Primary Keys to Match Both Tables
-- To cover both INSERT and UPDATE cases
IFF(o_orderkey % 2 = 1, o_orderkey, o_orderkey + 99999999999) AS o_orderkey,
o_orderdate,
o_custkey,
o_orderstatus,
o_totalprice,
o_orderpriority,
Expand Code
La requête ne prend que 15 à 17 secondes. La moitié des données est mise à jour, l'autre moitié est réécrite. Cette requête effectue un scan complet de la table cible, ce qui signifie que le query pruning est inactif.
Une seule ligne mise à jour réécrit entièrement la micro-partition
Pour illustrer ce qui se passe sous le capot lorsqu'un grand nombre de micro-partitions est concerné, nous allons générer un autre dataset source du même volume, environ 620 000 lignes, mais cette fois les données couvriront une plage de dates de l'année 1992 au lieu d'une seule journée.
-- Case 2
-- Values from a single order date / micro-paritition
-- Output: ~630k rows
-- Execution time: ~95s to run
CREATE OR REPLACE TEMPORARY TABLE source_table AS
SELECT
-- Primary Keys to Match Both Tables
IFF(o_orderkey % 2 = 1, o_orderkey, o_orderkey + 99999999999) AS o_orderkey
, o_orderdate
-- Other keys
, o_custkey
, o_orderstatus
, o_totalprice
Expand Code
Cette requête met environ 95 secondes à s'exécuter ! À tailles de table source identiques, elle est 4,5 fois plus lente !
Comparaison des deux exemples MERGE
Comparons les statistiques des plans de requête pour comprendre pourquoi le second exemple est nettement plus long.
| Octets scannés | Lignes écrites | Temps d'exécution | Partitions scannées/total | |
|---|---|---|---|---|
| Micro-partition unique | 6,20 Go | 42 Mo | ~17 s | 1 |
| Partitions uniformément distribuées | ~12 Go | 5,91 Go | ~95 s | 1 |
Comme évoqué plus haut, même en ne modifiant qu'une seule ligne d'une table, il faut réécrire l'intégralité de la micro-partition à laquelle elle appartient. Comme la table source contient des données réparties uniformément sur l'année 1992, nous devons réécrire environ 6 Go de données, soit près de 15 % de la taille de la table cible !
À bien des égards, cette situation peut échapper totalement à votre contrôle. S'il faut mettre à jour les données d'une année entière, les options sont limitées.
Les deux exemples ci-dessus impliquent un scan complet de la table cible pour déterminer quelles micro-partitions doivent être mises à jour. Explorons maintenant une technique d'optimisation appelée dynamic query pruning, qui peut améliorer les performances dans ce cas.
Améliorer les performances de MERGE avec le dynamic pruning
Si votre requête MERGE passe beaucoup de temps à scanner la table cible, vous pouvez probablement en améliorer les performances en forçant le query pruning, qui évitera de scanner des données inutiles dans la table cible.
Prenons un exemple où nous ne devons mettre à jour que 3 enregistrements distincts, répartis sur deux journées : le 1er janvier 1998 et le 25 février 1998.
-- Source table
CREATE OR REPLACE TEMPORARY TABLE orders_to_update AS (
SELECT
2606029510 AS o_orderkey
, 0 AS o_totalprice
, DATE '1998-02-25' AS o_orderdate
UNION ALL
SELECT
3135064003 AS o_orderkey
, 0 AS o_totalprice
, DATE '1998-02-25' AS o_orderdate
UNION ALL
SELECT
5602847265 AS o_orderkey
Expand Code
Comme on l'a vu, un MERGE classique se contente de faire correspondre les enregistrements sur o_orderkey. Comme o_orderkey est une clé aléatoire, la table cible orders ne sera pas clusterisée sur cette colonne, et l'opération MERGE devra donc scanner l'intégralité de la table cible pour trouver les micro-partitions contenant les trois valeurs o_orderkey à mettre à jour.
-- REGULAR MERGE
CREATE OR REPLACE TABLE orders_merge CLONE orders;
MERGE INTO orders_merge AS target
USING orders_to_update AS source
ON
target.o_orderkey = source.o_orderkey
WHEN MATCHED THEN
UPDATE SET
target.o_totalprice = source.o_totalprice
;
Pour éviter de scanner toutes les micro-partitions de la table cible, on peut tirer parti du fait que la table cible orders est clusterisée sur o_orderdate. Toutes les commandes d'une même date sont donc stockées dans les mêmes micro-partitions. Il suffit de modifier notre instruction MERGE pour ajouter une condition de jointure supplémentaire sur la colonne o_orderdate. Lors de l'exécution, Snowflake n'a plus qu'à parcourir les micro-partitions contenant les commandes des dates 1998-01-01 et 1998-02-25 !
C'est ce que l'on appelle le dynamic pruning : Snowflake détermine quelles micro-partitions élaguer (donc ne pas scanner) pendant l'exécution de la requête, après avoir lu les valeurs de la table source.
-- PRUNED MERGE
CREATE OR REPLACE TABLE orders_merge CLONE orders;
MERGE INTO orders_merge AS target
USING orders_to_update AS source
ON
target.o_orderkey = source.o_orderkey AND
target.o_orderdate = source.o_orderdate -- PRUNING COLUMN
WHEN MATCHED THEN
UPDATE SET
target.o_totalprice = source.o_totalprice
;
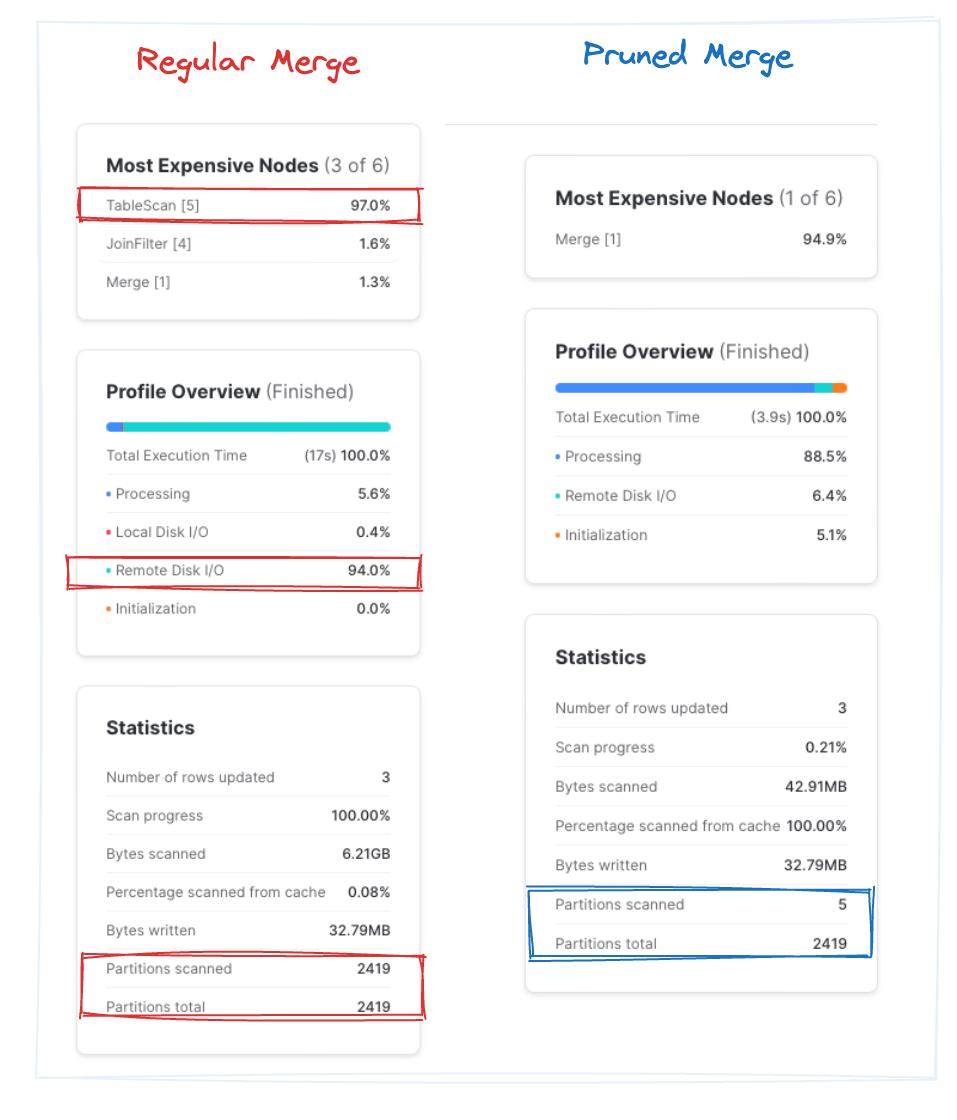
Alors que la requête regular merge prend en moyenne ~9,5 s sur trois exécutions, le pruned merge se termine en ~4 s. Notez que dans la requête optimisée, Snowflake n'a scanné que ~0,2 % du total des partitions. Soit un gain d'environ 2x en évitant les blocs de fichiers inutiles. Bingo !
Pour conclure
MERGE est un excellent moyen de gérer élégamment les mises à jour et les insertions de données dans Snowflake. En comprenant l'architecture de Snowflake et ses fichiers de micro-partitions immuables, on saisit pourquoi certaines opérations MERGE peuvent être longues alors qu'elles ne mettent à jour que quelques enregistrements. Nous avons également vu comment améliorer les performances de MERGE en minimisant le nombre de micro-partitions à scanner dans la table cible.
Nous espérons que cet article vous a été utile, merci de votre lecture !
Notes
2 Syntaxe de l'instruction merge BigQuery
3 The Snowflake Elastic Data Warehouse
4 What's the Difference? Incremental Processing with Change Queries in Snowflake
5 Zero-Copy Cloning in Snowflake and Other Database Systems
Andrey Bystrov·Analytics Engineer chez Deliveroo
Andrey est un praticien de la donnée expérimenté, actuellement Analytics Engineer chez Deliveroo. Passionné par la modélisation des données et l'optimisation SQL, il maîtrise en profondeur la plateforme Snowflake et met cette expertise au service de son équipe pour construire des pipelines de données performants et rentables. Andrey partage régulièrement ses apprentissages avec la communauté.